RePercENT: Scaling Disentangled Representation Learning Beyond Two Modalities
Pith reviewed 2026-06-28 07:08 UTC · model grok-4.3
The pith
RePercENT enables scalable disentangled representations for any number of modalities by operating on pre-extracted embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
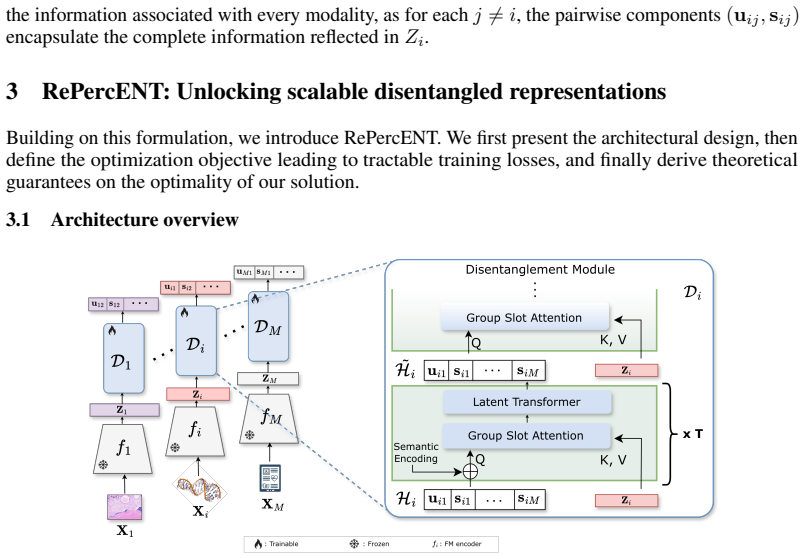
RePercENT is a self-supervised framework that unlocks scalable pairwise disentanglement beyond two modalities through a multimodal plug-and-play architecture that operates directly on pre-extracted embeddings, introduces a joint optimization objective for simultaneously deriving the shared and unique components, and provides formal theoretical guarantees that characterize the optimality of the solution.
What carries the argument
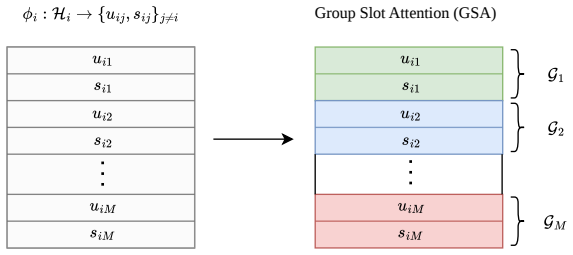
The multimodal plug-and-play architecture that jointly optimizes shared and unique components directly from pre-extracted embeddings without modality-specific assumptions.
If this is right
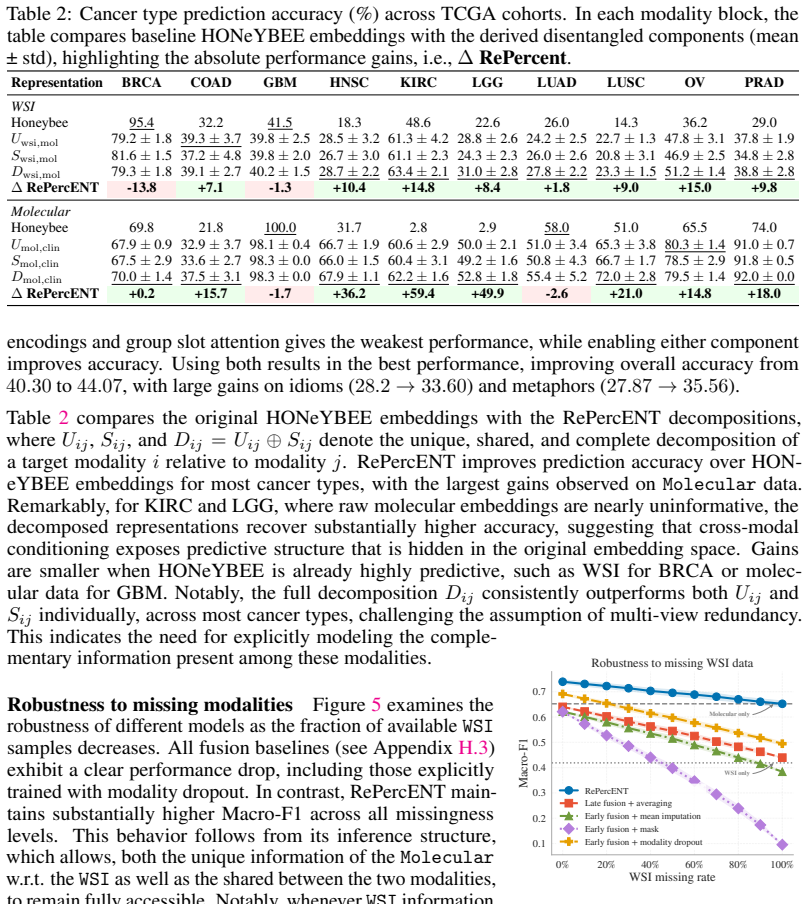
- Disentangled components are recovered across diverse modalities and tasks while maintaining competitive performance.
- Computational complexity is significantly reduced compared with methods that require joint pre-training.
- No assumptions are needed on the underlying modalities or the foundation model backbones used to produce the embeddings.
- The optimality of the recovered solution is characterized by formal theoretical guarantees.
Where Pith is reading between the lines
- The same plug-and-play structure could allow new modalities to be added after initial training without retraining the full model.
- Downstream multimodal fusion or generation tasks might benefit from using the recovered shared and unique factors as cleaner inputs.
- The joint optimization could be combined with existing contrastive losses to handle cases where some modalities are missing at test time.
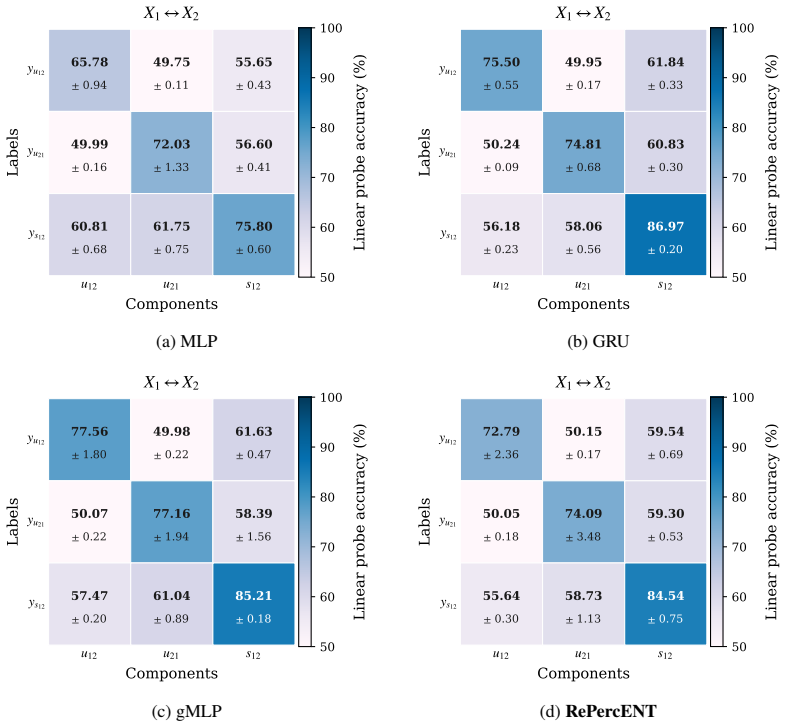
Load-bearing premise
Pre-extracted embeddings from arbitrary foundation models already contain enough information for the joint optimization to recover both shared and unique factors.
What would settle it
A synthetic three-modality dataset with known ground-truth shared and unique factors on which the method fails to recover the correct disentangled components.
Figures








read the original abstract
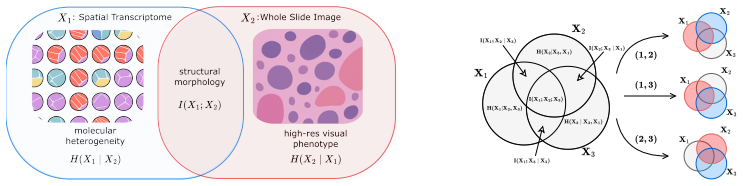
To leverage the full potential of multimodal data, we need representations that go beyond the state-of-the-art alignment and fusion approaches and exploit all cross-modal interactions without sacrificing modality-specific information. Learning disentangled representations is a principled way to identify these underlying shared and unique factors that are hidden in observational data. However, while multimodal disentanglement is a compelling paradigm, existing methods are largely confined to the two-modality regime due to its inherent scalability bottleneck. To address this, we propose RePercENT, a self-supervised framework designed to surpass these limitations and unlocks scalable pairwise disentanglement beyond two modalities. Through a multimodal `plug-and-play' architecture, our approach operates directly on pre-extracted embeddings, eliminating the need for extensive joint pre-training while making no assumptions regarding the underlying modalities or foundation model backbones. Moreover, we introduce a joint optimization objective for simultaneously deriving the shared and unique components, and provide formal theoretical guarantees that characterize the optimality of our solution. Across diverse modalities and tasks, RePercENT successfully recovers disentangled components while maintaining competitive performance and significantly reducing computational complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RePercENT, a self-supervised multimodal framework for disentangled representation learning that scales pairwise disentanglement beyond two modalities. It introduces a plug-and-play architecture operating directly on pre-extracted embeddings from arbitrary foundation models (with no modality or backbone assumptions), a joint optimization objective to derive shared and unique components, and formal theoretical guarantees characterizing solution optimality. Experiments claim successful recovery of disentangled factors across diverse modalities and tasks while maintaining competitive performance and lowering computational cost relative to prior methods.
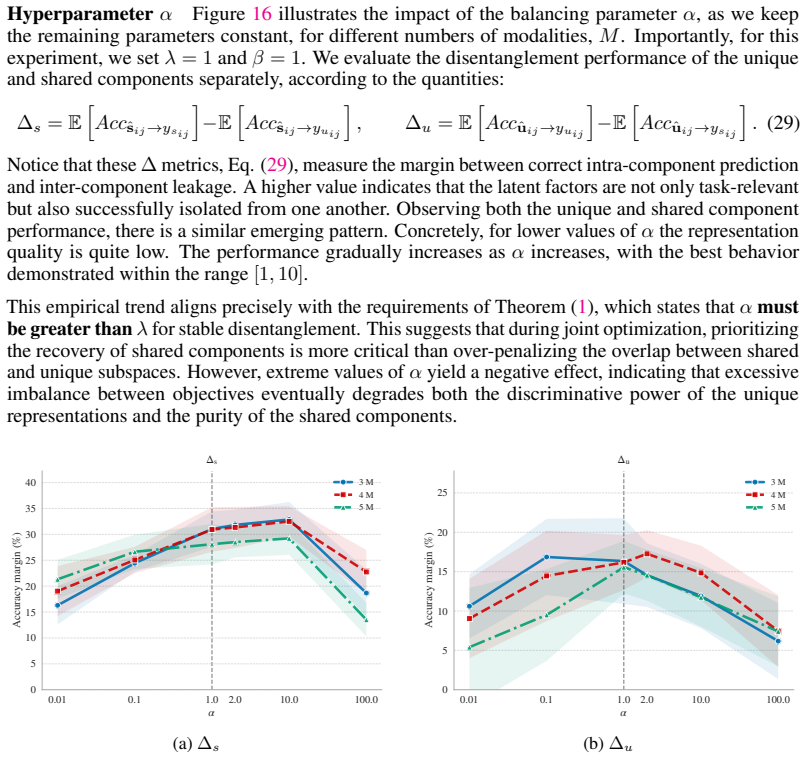
Significance. If the optimality guarantees are non-circular and the method recovers factors from frozen embeddings without hidden modality-specific assumptions, the result would be significant for enabling scalable multimodal disentanglement in a practical, foundation-model-compatible setting. The plug-and-play design and reduction in joint pre-training are practical strengths; however, the load-bearing premise that pre-extracted embeddings already encode recoverable shared/unique factors remains unverified in the provided description.
major comments (2)
- [Abstract] Abstract (and architecture description): the claim of 'formal theoretical guarantees that characterize the optimality of our solution' and 'no assumptions regarding the underlying modalities or foundation model backbones' is load-bearing for the central contribution, yet the abstract supplies no equations, proof sketches, or recovery conditions; without these it is impossible to assess whether the guarantees are non-circular or whether the joint objective reduces to a self-referential definition of shared/unique factors.
- [Architecture] Architecture and weakest-assumption paragraph: the premise that pre-extracted embeddings from arbitrary foundation models already contain linearly or nonlinearly separable information about shared and unique factors (without modality-specific assumptions or joint pre-training) is the least secured element; foundation-model embeddings are optimized for their original objectives and may discard or entangle cross-modal factors in ways the downstream objective cannot recover. The manuscript should supply a concrete test or counter-example showing when this premise holds.
minor comments (2)
- Provide the explicit form of the joint optimization objective (including any regularization or orthogonality terms) and contrast it with existing two-modality disentanglement losses.
- Clarify the precise notion of 'pairwise disentanglement' when extending beyond two modalities and how the method avoids combinatorial explosion in the number of modality pairs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the placement of theoretical details and the empirical support for the embedding premise.
read point-by-point responses
-
Referee: [Abstract] Abstract (and architecture description): the claim of 'formal theoretical guarantees that characterize the optimality of our solution' and 'no assumptions regarding the underlying modalities or foundation model backbones' is load-bearing for the central contribution, yet the abstract supplies no equations, proof sketches, or recovery conditions; without these it is impossible to assess whether the guarantees are non-circular or whether the joint objective reduces to a self-referential definition of shared/unique factors.
Authors: The abstract is space-constrained and omits equations and proof sketches, which appear in Section 3 (Theoretical Analysis). The guarantees characterize optimality of the joint objective via identifiability results derived from the pairwise contrastive formulation; they are non-circular because the shared/unique decomposition is uniquely determined by the fixed-point conditions of the optimization rather than by definition. A reference to Section 3 can be added to the abstract. revision: partial
-
Referee: [Architecture] Architecture and weakest-assumption paragraph: the premise that pre-extracted embeddings from arbitrary foundation models already contain linearly or nonlinearly separable information about shared and unique factors (without modality-specific assumptions or joint pre-training) is the least secured element; foundation-model embeddings are optimized for their original objectives and may discard or entangle cross-modal factors in ways the downstream objective cannot recover. The manuscript should supply a concrete test or counter-example showing when this premise holds.
Authors: Section 4 reports experiments on frozen embeddings from multiple foundation models across vision, language, and audio modalities, showing consistent recovery of shared and unique factors without joint pre-training or modality-specific tuning. These results serve as empirical validation of the premise under the tested conditions. An explicit counter-example is not provided, but the breadth of successful cases indicates the premise holds for standard foundation-model embeddings; we can add a limitations paragraph if requested. revision: no
Circularity Check
No circularity: derivation self-contained on pre-extracted embeddings and joint objective
full rationale
The provided abstract and context describe a plug-and-play architecture on frozen embeddings, a joint optimization for shared/unique factors, and optimality guarantees, but contain no equations, self-citations, or fitted-parameter renamings that reduce the claimed results to inputs by construction. The central premise (recoverability from arbitrary foundation-model embeddings) is an assumption rather than a derived claim that loops back on itself. No load-bearing step matches any enumerated circularity pattern; the framework is presented as independent of modality-specific pre-training.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal machine learning: A survey and taxonomy
doi: 10.1109/TPAMI.2018.2798607. Felix Krones, Umar Marikkar, Guy Parsons, Adam Szmul, and Adam Mahdi. Review of multimodal machine learning approaches in healthcare.An International Journal on Information Fusion, 114,
-
[2]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.ArXiv, abs/1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hanxiao Liu, Zihang Dai, David So, and Quoc V Le
doi: 10.1038/s41746-025-02003-4. Hanxiao Liu, Zihang Dai, David So, and Quoc V Le. Pay attention to MLPs. InAdvances in Neural Information Processing Systems,
-
[4]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
arXiv:1412.3555 [cs]. Paul Pu Liang, Amir Zadeh, and Louis philippe Morency. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions.ACM Computing Surveys, 56:1 – 42, 2022a. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie M...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Flava: A foundational language and vision alignment model.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
2022
-
[6]
Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, and Maksims V olkovs
Noël V ouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, and Maksims V olkovs. Data-efficient multimodal fusion on a single gpu.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
2024
-
[7]
Towards a General-Purpose Foundation Model for Computational Pathology,
doi: 10.1038/s41591-024-02857-3. Yingxue Xu and Hao Chen. Multimodal optimal transport-based co-attention transformer with global structure consistency for survival prediction.2023 IEEE/CVF International Conference on Computer Vision (ICCV),
-
[8]
Imagebind one embedding space to bind them all.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind one embedding space to bind them all.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
2023
-
[9]
doi: 10.1109/TPAMI.2024.3420937. Aniek Eijpe, Soufyan Lakbir, Melis Erdal Cesur, Sara Pires de Oliveira, Sanne Abeln, and Wilson Silva. Disentangled and interpretable multimodal attention fusion for cancer survival prediction. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention,
-
[10]
Lucas Robinet, Ahmad Berjaoui, Ziad Kheil, and Elizabeth Cohen-Jonathan Moyal
doi: 10.1609/aaai.v38i15.29578. Lucas Robinet, Ahmad Berjaoui, Ziad Kheil, and Elizabeth Cohen-Jonathan Moyal. Drim: Learn- ing disentangled representations from incomplete multimodal healthcare data. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer,
-
[11]
Alessandro Achille and Stefano Soatto
doi: 10.48550/arXiv.physics/ 0004057. Alessandro Achille and Stefano Soatto. Information dropout: Learning optimal representations through noisy computation.IEEE Transactions on Pattern Analysis and Machine Intelligence, page 2897–2905, December
-
[12]
Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola
doi: 10.1109/TPAMI.2017.2784440. Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning? InAdvances in Neural Information Processing Systems,
-
[13]
Asim Waqas, Aakash Tripathi, Sabeen Ahmed, Ashwin Mukund, Hamza Farooq, Matthew B Scha- bath, Paul Stewart, Mia Naeini, and Ghulam Rasool. Senmo: A self-normalizing deep learning model for enhanced multi-omics data analysis in oncology.arXiv preprint arXiv:2405.08226,
-
[14]
15 E.2 Multi-view redundancy
12 Appendix Contents A Useful Notation 14 B Supplementary Related Work 14 C Limitations and future directions 15 D Impact Statement 15 E Information Theory Background 15 E.1 Basic quantities and identities . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 E.2 Multi-view redundancy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16...
2024
-
[15]
propose information-theoretic criteria for controlled two-modality disentanglement. C Limitations and future directions Although RePercENT provides a scalable and theoretically grounded framework for high-modality disentanglement, it also reveals several promising directions for future extensions. Our formulation focuses on pairwise unique and shared comp...
2001
-
[16]
(9) Minimizing I(s ij;X i |X j) penalizes information retained by sij about Xi that is not explained by Xj
propose the following definition for extracting the optimal shared representations sij ands ji: s∗ ij ∈arg min sij I(s ij;X i |X j),s.t.I(X i;X j)−I(s ij;X j)≤δ c, s∗ ji ∈arg min sji I(s ji;X j |X i),s.t.I(X i;X j)−I(s ji;X i)≤δ c. (9) Minimizing I(s ij;X i |X j) penalizes information retained by sij about Xi that is not explained by Xj. The constraint, o...
2018
-
[17]
It follows that all inequalities above become equalities when(s ij, sji) = (s∗ ij, s∗ ji)
implies that, in the attainable-MNI regime, I(u ij, s∗ ji;X i) =I(u ij, Xj;X i), I(u ji, s∗ ij;X j) =I(u ji, Xi;X j). It follows that all inequalities above become equalities when(s ij, sji) = (s∗ ij, s∗ ji). Hence J= 2(α−λ)I(X i;X j) +B ui +B uj + 2c = 2αI(X i;X j) +B ui +B uj , c=λI(X i;X j).(22) Since the term 2αI(X i;X j) is constant with respect to u...
2025
-
[18]
All models are trained with five independent random seeds, and we report detection accuracy as the mean±standard deviation across runs
Note that the two text modalities, Caption and Definition, share the same encoder architecture but are encoded by separate encoder instances with independent parameters. All models are trained with five independent random seeds, and we report detection accuracy as the mean±standard deviation across runs. Table 5: Architecture and training specifications u...
2013
-
[19]
Modality Dim
Table 6: HONeYBEE TCGA modality embeddings used in the oncology experiments. Modality Dim. Encoder Description Clinical1024Qwen3 [Yang et al., 2025] Patient-level clinical information, including structured and unstructured records such as demographics, laboratory values, medications, and clinical narratives. Pathology1024Qwen3 [Yang et al., 2025] Free-tex...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.