HORIZON: Recoverability-Governed Curriculum for Physical-Domain Scaling
Pith reviewed 2026-06-28 05:46 UTC · model grok-4.3
The pith
Recoverability governs physical-domain expansion in on-policy robot training
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In on-policy training, new dynamics are useful only insofar as they remain close enough to the current policy to generate corrective on-policy data, rather than collapsing rollouts into unrecoverable failures. Recoverability is therefore the central constraint that should govern physical-domain expansion.
What carries the argument
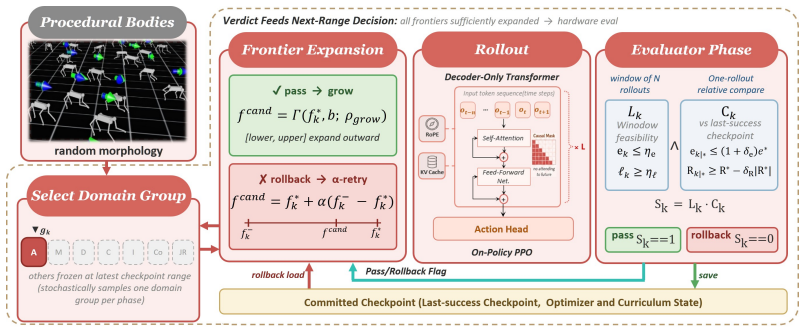
HORIZON checkpointed frontier curriculum that expands physical domains only within the current policy's recoverable boundary using rollback and boundary refinement
If this is right
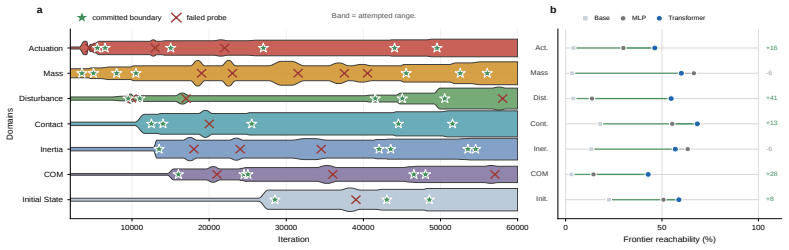
- Direct domain widening is uneven across physical axes and often unlearnable without staged ordering.
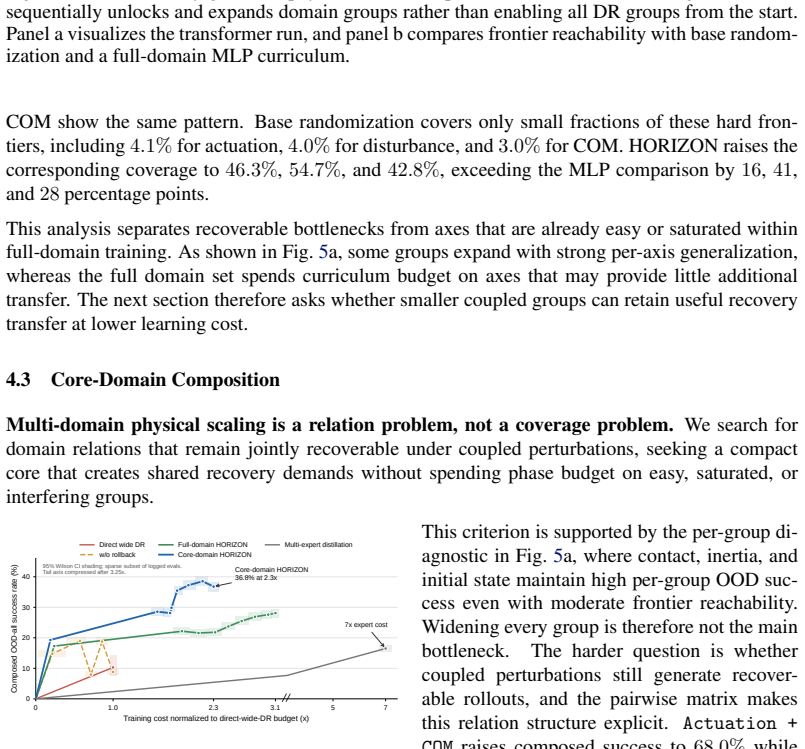
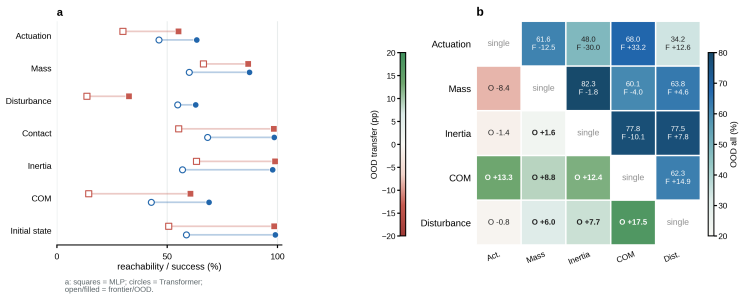
- Domain composition is non-monotonic, and adding more domains beyond a compact core can dilute recoverable joint samples and reduce overall robustness.
- Offline distillation of isolated experts cannot substitute for the joint interaction generated by on-policy curriculum.
Where Pith is reading between the lines
- The recoverability principle could be tested on other continuous-control tasks such as manipulation to check whether it remains the dominant constraint.
- Automated estimation of recoverability boundaries might allow the curriculum to scale without manual tuning.
- The finding that extra domains can dilute performance suggests future work on identifying minimal sufficient domain cores rather than maximizing count.
Load-bearing premise
Recoverability boundaries can be reliably measured and used to decide safe domain expansions without introducing new assumptions about policy stability or environment dynamics.
What would settle it
An experiment in which policies trained by expanding domains beyond measured recoverability boundaries achieve higher robustness than those kept inside the boundaries would falsify the claim.
Figures




read the original abstract
Scaling robust robot policies requires more than broader randomization, because physical-domain experience must remain organized and learnable throughout training. We study when a policy can benefit from harder physics and identify recoverability as a central constraint in on-policy physical-domain scaling. In on-policy training, new dynamics are useful only insofar as they remain close enough to the current policy to generate corrective on-policy data, rather than collapsing rollouts into unrecoverable failures. Using quadruped locomotion as a physically demanding benchmark for embodied generalization, we introduce HORIZON, a checkpointed frontier curriculum that expands physical domains only within the current policy's recoverable boundary. HORIZON uses rollback and boundary refinement to govern each expansion step, turning fixed randomization into a continual process of physical-domain growth. Experiments reveal three regularities of physical-domain expansion. First, direct domain widening is uneven across physical axes and often unlearnable without staged ordering. Second, domain composition is non-monotonic, and adding more domains beyond a compact core can dilute recoverable joint samples and reduce overall robustness. Third, offline distillation of isolated experts cannot substitute for the joint interaction generated by on-policy curriculum. Together, these results frame physical-domain generalization as a continual growth problem for embodied control, with recoverability as the organizing principle for on-policy expansion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HORIZON, a checkpointed frontier curriculum for on-policy physical-domain scaling in robot policy training. It argues that recoverability is the central constraint: new dynamics are introduced only if they remain within the current policy's recoverable boundary (allowing corrective on-policy data rather than unrecoverable failures), with rollback and boundary refinement governing expansions. Using quadruped locomotion as the benchmark, the work reports three regularities: (1) direct domain widening is uneven across physical axes and often unlearnable without staged ordering; (2) domain composition is non-monotonic, with additions beyond a compact core diluting recoverable joint samples; (3) offline distillation of isolated experts cannot substitute for joint on-policy interaction.
Significance. If the empirical regularities hold under rigorous controls, the paper supplies a principled organizing principle for physical-domain generalization in embodied control, reframing randomization as a continual, recoverability-governed growth process rather than fixed broadening. This could inform curriculum design for robust locomotion and related tasks where unrecoverable states collapse learning.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method): The recoverable boundary is invoked as the governing constraint for all expansions and rollback decisions, yet no operational definition is supplied (e.g., failure threshold, recovery horizon length, statistical test for unrecoverability, or explicit dependence on policy stability). This is load-bearing for the central claim that the three regularities demonstrate recoverability as the organizing principle rather than an artifact of unstated heuristics.
- [§4] §4 (Experiments): The three reported regularities are asserted without reference to concrete metrics, baselines, number of seeds, statistical tests, or ablation controls that isolate recoverability from other factors (e.g., reward shaping or environment-specific stability). Without these, it is impossible to verify whether the data support the recoverability-governed curriculum over alternative explanations.
- [§3.2] §3.2 (Boundary refinement): The description of rollback and boundary refinement does not specify how the boundary is measured or updated without circular dependence on the policy being trained, nor how environment dynamics assumptions are avoided. This directly affects whether the curriculum steps are justified by the recoverability principle alone.
minor comments (2)
- Notation for physical axes and domain composition should be defined explicitly with symbols or a table to improve clarity when discussing non-monotonic effects.
- [Abstract] The abstract would benefit from a single sentence summarizing the quantitative evidence (e.g., success rates or robustness metrics) supporting each regularity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): The recoverable boundary is invoked as the governing constraint for all expansions and rollback decisions, yet no operational definition is supplied (e.g., failure threshold, recovery horizon length, statistical test for unrecoverability, or explicit dependence on policy stability). This is load-bearing for the central claim that the three regularities demonstrate recoverability as the organizing principle rather than an artifact of unstated heuristics.
Authors: We agree that an explicit operational definition is required to support the central claim. In the revised manuscript we will insert a dedicated paragraph in §3 defining the recoverable boundary via a failure threshold (rollout termination when torso height falls below a fixed value), a recovery horizon of 200 steps for corrective action assessment, and a statistical test (two-tailed t-test on success rate over 100 evaluation episodes, p < 0.05) that determines whether a new domain remains recoverable. This definition will be referenced in the abstract and used to justify all expansion and rollback decisions. revision: yes
-
Referee: [§4] §4 (Experiments): The three reported regularities are asserted without reference to concrete metrics, baselines, number of seeds, statistical tests, or ablation controls that isolate recoverability from other factors (e.g., reward shaping or environment-specific stability). Without these, it is impossible to verify whether the data support the recoverability-governed curriculum over alternative explanations.
Authors: The referee is correct that the current presentation lacks explicit reporting of these elements. We will add a new subsection 4.1 that specifies: (i) primary metrics (success rate, mean episode return, and robustness score under domain perturbation), (ii) baselines (fixed uniform randomization, staged curriculum without rollback, and offline expert distillation), (iii) 5 independent seeds with reported means and standard errors, and (iv) ablation controls that vary only the recoverability threshold while holding reward shaping and environment parameters fixed. Statistical significance will be assessed via paired t-tests. These additions will allow direct verification of the three regularities. revision: yes
-
Referee: [§3.2] §3.2 (Boundary refinement): The description of rollback and boundary refinement does not specify how the boundary is measured or updated without circular dependence on the policy being trained, nor how environment dynamics assumptions are avoided. This directly affects whether the curriculum steps are justified by the recoverability principle alone.
Authors: We will revise §3.2 to clarify the measurement protocol: boundary assessment is performed on a frozen checkpoint of the current policy using a separate set of 50 held-out evaluation episodes that are never used for training updates, thereby eliminating circular dependence. Boundary refinement then occurs by shrinking the frontier only when the statistical test on these held-out episodes indicates unrecoverability. No parametric assumptions on environment dynamics are introduced; the procedure relies solely on observed policy-environment interaction statistics. revision: yes
Circularity Check
No circularity: algorithmic construction presented without self-referential reductions or fitted predictions
full rationale
The paper describes HORIZON as an independent curriculum algorithm that expands domains using rollback and boundary refinement within a recoverable boundary, with three experimental regularities reported as outcomes. No equations, derivations, or parameter-fitting steps are referenced that would reduce a claimed prediction back to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and recoverability is positioned as an organizing principle rather than a quantity defined in terms of the method's outputs. The chain is therefore self-contained as a proposed method evaluated empirically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. doi:10.48550/arXiv.2001.08361. URLhttps://arxiv.org/abs/ 2001.08361
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[2]
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation. InInternational Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=pISLZG7ktL. ICLR 2025 Oral
2025
-
[3]
J. Long, W. Yu, Q. Li, Z. Wang, D. Lin, and J. Pang. Learning h-infinity locomotion control. InProceedings of Machine Learning Research, 2024
2024
-
[4]
Jiang, M
M. Jiang, M. Dennis, J. Parker-Holder, J. Foerster, E. Grefenstette, and T. Rockt¨aschel. Replay- guided adversarial environment design. InAdvances in Neural Information Processing Sys- tems, volume 34, 2021. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2021/hash/0e915db6326b6fb6a3c56546980a8c93-Abstract.html
2021
-
[5]
Bronars, Y
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning. InIEEE International Conference on Robotics and Automation, 2026. URLhttps: //openreview.net/forum?id=jWl03w0NfH
2026
-
[6]
Domain randomization for transferring deep neural networks from simulation to the real world
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017. doi: 10.1109/IROS.2017.8202133
-
[7]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 3803–3810, 2018. doi:10.1109/ICRA.2018.8460528
-
[8]
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke. Sim- to-real: Learning agile locomotion for quadruped robots. InRobotics: Science and Systems,
-
[9]
doi:10.15607/RSS.2018.XIV .010
-
[10]
Y . Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. In2019 International Conference on Robotics and Automation (ICRA), pages 8973–8979, 2019. doi: 10.1109/ICRA.2019.8793789
-
[11]
F. Ramos, R. C. Possas, and D. Fox. BayesSim: Adaptive domain randomization via prob- abilistic inference for robotics simulators. InRobotics: Science and Systems, 2019. doi: 10.15607/RSS.2019.XV .029
-
[12]
Muratore, T
F. Muratore, T. Gruner, F. Wiese, B. Belousov, M. Gienger, and J. Peters. Neural poste- rior domain randomization. InProceedings of Machine Learning Research, volume 164 of Proceedings of Machine Learning Research, pages 1532–1542. PMLR, 2022. URLhttps: //proceedings.mlr.press/v164/muratore22a.html
2022
-
[13]
Mehta, M
B. Mehta, M. Diaz, F. Golemo, C. J. Pal, and L. Paull. Active domain randomization. In Proceedings of Machine Learning Research, volume 100 ofProceedings of Machine Learn- ing Research, pages 1162–1176. PMLR, 2020. URLhttps://proceedings.mlr.press/ v100/mehta20a.html
2020
-
[14]
Z. Xie, X. Da, M. van de Panne, B. Babich, and A. Garg. Dynamics randomization revisited: A case study for quadrupedal locomotion. In2021 IEEE International Conference on Robotics and Automation (ICRA), 2021. doi:10.1109/ICRA48506.2021.9560837. 9
-
[15]
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, pages 41–48. ACM, 2009. doi:10.1145/1553374.1553380. URLhttps://doi.org/10.1145/1553374.1553380
-
[16]
Narvekar, B
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21(181):1–50, 2020. URLhttps://www.jmlr.org/papers/v21/20-212.html
2020
-
[17]
Portelas, C
R. Portelas, C. Colas, K. Hofmann, and P.-Y . Oudeyer. Teacher algorithms for curriculum learning of deep RL in continuously parameterized environments. InProceedings of Machine Learning Research, volume 100 ofProceedings of Machine Learning Research, pages 835–
-
[18]
URLhttps://proceedings.mlr.press/v100/portelas20a.html
PMLR, 2020. URLhttps://proceedings.mlr.press/v100/portelas20a.html
2020
-
[19]
Florensa, D
C. Florensa, D. Held, M. Wulfmeier, M. Zhang, and P. Abbeel. Reverse curriculum generation for reinforcement learning. InProceedings of Machine Learning Research, volume 78 of Proceedings of Machine Learning Research, pages 482–495. PMLR, 2017
2017
-
[20]
Khetarpal, M
K. Khetarpal, M. Riemer, I. Rish, and D. Precup. Towards continual reinforcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75:1401–1476, 2022. URLhttps://www.jair.org/index.php/jair/article/view/13673
2022
-
[21]
Shenfeld, J
I. Shenfeld, J. Pari, and P. Agrawal. RL’s razor: Why online reinforcement learning for- gets less. InInternational Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=7HNRYT4V44
2026
-
[22]
Hwangbo, J
J. Hwangbo, J. Lee, A. Dosovitskiy, C. D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872,
-
[23]
doi:10.1126/scirobotics.aau5872
-
[24]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InProceedings of Machine Learning Research, volume 164 ofProceedings of Machine Learning Research, pages 91–100. PMLR, 2022
2022
-
[25]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. In Robotics: Science and Systems, 2021
2021
-
[26]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal lo- comotion over challenging terrain.Science Robotics, 5(47):eabc5986, 2020. doi:10.1126/ scirobotics.abc5986
2020
-
[27]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust percep- tive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022. doi:10.1126/scirobotics.abk2822
-
[28]
M. Liu, D. Pathak, and A. Agarwal. Locoformer: Generalist locomotion via long-context adap- tation. InProceedings of Machine Learning Research, 2025. URLhttps://openreview. net/forum?id=VqmAvBkFhw
2025
-
[29]
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal. Rapid locomotion via rein- forcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024. doi:10.1177/02783649231224053
-
[30]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. InProceedings of Machine Learning Research, volume 229 ofProceedings of Machine Learning Research. PMLR, 2023
2023
-
[31]
K. Wang, L. Lu, M. Liu, J. Jiang, Z. Li, B. Zhang, W. Zheng, X. Yu, H. Chen, and C. Shen. ODYSSEY: Open-world quadrupeds exploration and manipulation for long-horizon tasks.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22):18602–18610, 10
-
[32]
URLhttps://ojs.aaai.org/index.php/AAAI/ article/view/38927
doi:10.1609/aaai.v40i22.38927. URLhttps://ojs.aaai.org/index.php/AAAI/ article/view/38927
-
[33]
J. Long, Z. Wang, Q. Li, L. Cao, J. Gao, and J. Pang. Hybrid internal model: Learning agile legged locomotion with simulated robot response. InInternational Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=93LoCyww8o
2024
-
[34]
A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V . Mnih, K. Kavukcuoglu, and R. Hadsell. Policy distillation. InInternational Confer- ence on Learning Representations, 2016. URLhttps://mlanthology.org/iclr/2016/ rusu2016iclr-policy/
2016
-
[35]
Queeney, X
J. Queeney, X. Cai, A. Schperberg, R. Corcodel, M. Benosman, and J. P. How. GRAM: Gener- alization in deep RL with a robust adaptation module.IEEE Robotics and Automation Letters,
-
[36]
URLhttps://www.merl.com/publications/ TR2026-057
doi:10.1109/LRA.2025.3641155. URLhttps://www.merl.com/publications/ TR2026-057
-
[37]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, H...
Pith/arXiv arXiv 2025
-
[38]
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
arXiv 2025
-
[39]
a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \
D. Zhu, C. Zhu, Z. Zhang, S. Xin, and Y . Liu. Learning safe locomotion for quadrupedal robots by derived-action optimization. In2024 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 6870–6876, 2024. doi:10.1109/IROS58592.2024. 10802725. URLhttps://ieeexplore.ieee.org/document/10802725. 11 A Recoverability Diagnostic The...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.