Where Do Large Language Models Fail on Competitive Programming? A Taxonomy of Failures by Algorithm Type and Difficulty Rating
Pith reviewed 2026-06-28 08:35 UTC · model grok-4.3
The pith
Chain-of-thought prompting lowers GPT-4o's competitive programming pass rate from 46% to 36.8% while tripling Claude's compile errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
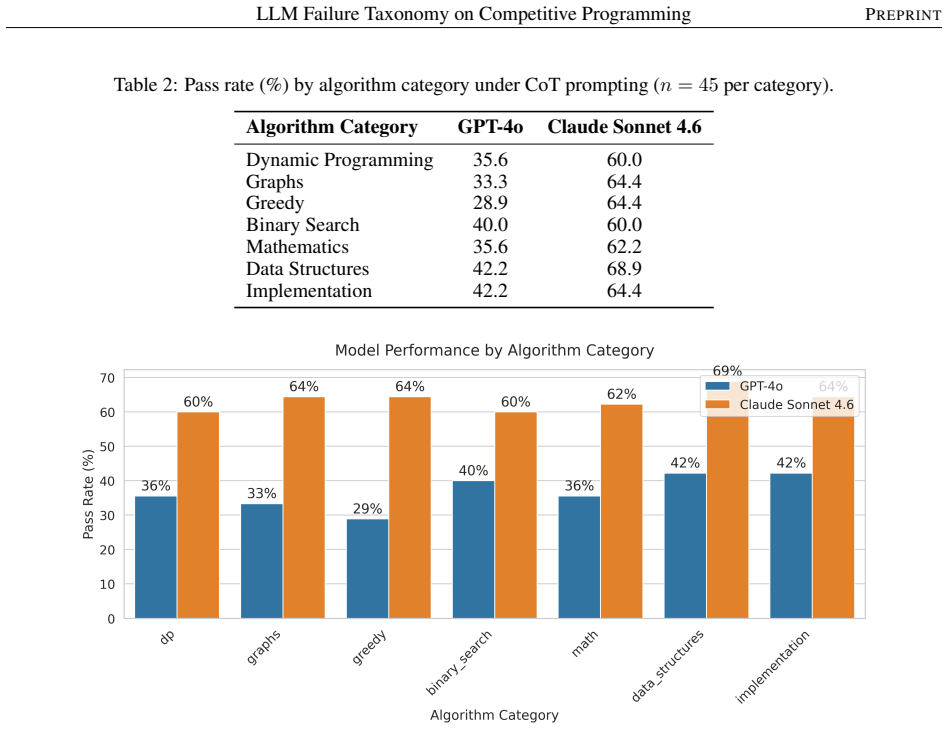
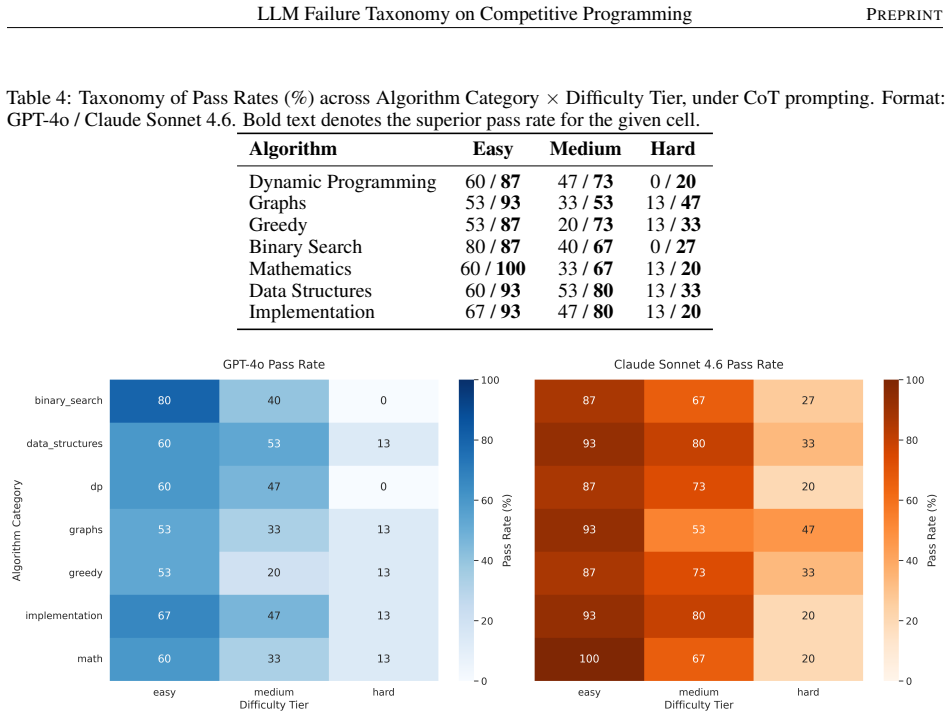
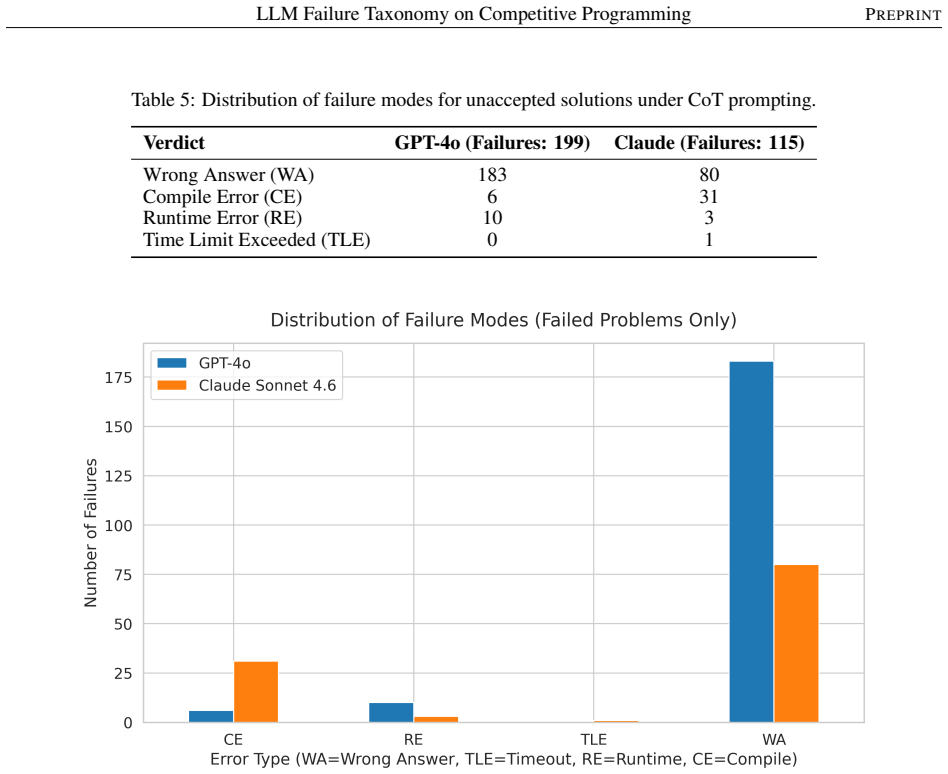
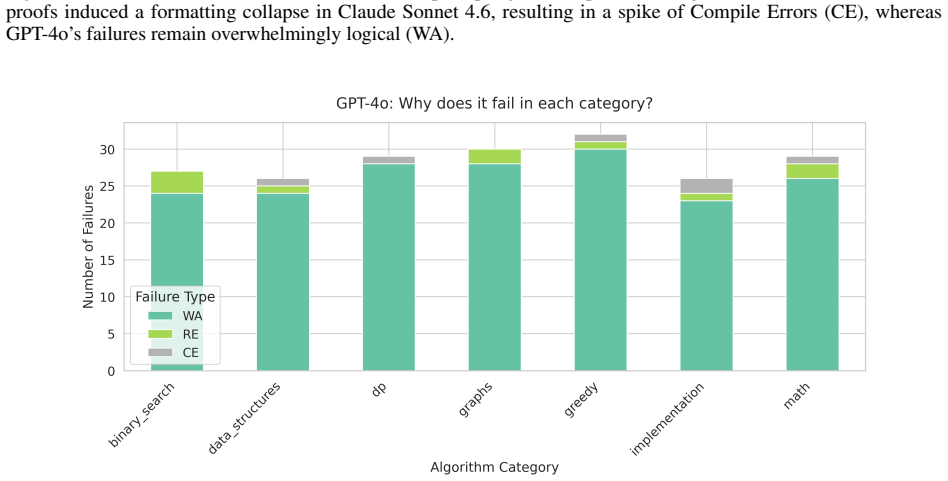
The ablation study shows a severe divergence from standard NLP benchmarks: forcing CoT aggressively penalizes GPT-4o, dropping its pass rate from 46.0% to 36.8% and exacerbating a critical weakness in Greedy logic. Conversely, while Claude maintains a higher logical baseline (63.5% under CoT), the expanded text generation severely degrades its markdown instruction adherence, causing its Compile Errors to more than triple (from 9 to 31, a 244% increase). Wrong Answer is the dominant verdict for both models, accounting for over 90% of GPT-4o's and roughly 70% of Claude's unaccepted solutions.
What carries the argument
A balanced taxonomy of 315 Codeforces problems across seven algorithm categories and three difficulty tiers, used to compare direct zero-shot generation against zero-shot Chain-of-Thought under controlled execution-based scoring.
If this is right
- Wrong Answer remains the dominant failure mode, exceeding 90 percent for GPT-4o and 70 percent for Claude.
- Chain-of-thought exacerbates GPT-4o's weakness on greedy algorithms.
- Chain-of-thought triples Claude's compile errors by degrading markdown format adherence.
- Standard prompt-engineering techniques do not bridge the algorithmic reasoning gap in competitive programming.
Where Pith is reading between the lines
- Model-specific prompting strategies may be needed rather than a single CoT template for algorithmic tasks.
- The category-level failure data could be used to prioritize training data for greedy or other weak algorithm types.
- The same taxonomy could serve as a diagnostic benchmark when new models or prompting methods are introduced.
- Real-world coding assistants that default to chain-of-thought may inherit the same format and logic weaknesses observed here.
Load-bearing premise
The 315 Codeforces problems form a balanced and representative taxonomy across seven algorithm categories and three difficulty tiers that allows reliable generalization of observed failure patterns.
What would settle it
Re-running the identical evaluation protocol on a fresh collection of at least 300 Codeforces problems drawn from the same seven algorithm categories and three difficulty tiers and obtaining materially different pass-rate changes or error distributions under CoT.
Figures
read the original abstract
Large language models (LLMs) demonstrate increasing proficiency on competitive programming benchmarks, yet technical reports predominantly publish aggregate pass rates, obscuring domain-specific vulnerabilities. We present a systematic empirical study of LLM failure patterns using a balanced taxonomy of 315 Codeforces problems across seven algorithm categories and three difficulty tiers. We evaluate GPT-4o and Claude Sonnet 4.6 under strict execution-based conditions, controlling for temperature (T = 0.2). To isolate the impact of reasoning frameworks on algorithmic correctness, we conduct an ablation study comparing direct zero-shot generation against zero-shot Chain-of-Thought (CoT). Our findings reveal a severe divergence from standard NLP benchmarks: forcing CoT aggressively penalizes GPT-4o, dropping its pass rate from 46.0% to 36.8% and exacerbating a critical weakness in Greedy logic. Conversely, while Claude maintains a higher logical baseline (63.5% under CoT), the expanded text generation severely degrades its markdown instruction adherence, causing its Compile Errors to more than triple (from 9 to 31, a 244% increase). Furthermore, failure-mode analysis indicates that Wrong Answer (WA) is the dominant verdict for both models--accounting for over 90% of GPT-4o's and roughly 70% of Claude's unaccepted solutions. These findings empirically demonstrate that standard prompt engineering techniques fail to bridge the algorithmic reasoning gap in competitive programming environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical study of LLM failures on competitive programming tasks. It evaluates GPT-4o and Claude Sonnet 4.6 on a set of 315 Codeforces problems organized into a taxonomy of seven algorithm categories and three difficulty tiers. The study compares zero-shot direct generation against zero-shot Chain-of-Thought prompting under fixed temperature (T=0.2), reports pass rates (e.g., GPT-4o drops from 46.0% to 36.8% with CoT), and analyzes dominant failure modes such as Wrong Answer (>90% for GPT-4o) and increased Compile Errors for Claude under CoT.
Significance. If the problem taxonomy is representative, the results would usefully document model-specific divergences from NLP benchmarks, including the counter-intuitive penalty from CoT on GPT-4o for Greedy problems and the markdown adherence degradation in Claude. The work supplies concrete numerical contrasts and failure-mode breakdowns that could guide targeted improvements in algorithmic reasoning for LLMs.
major comments (1)
- [Abstract / §3] Abstract and §3 (Problem Selection / Taxonomy Construction): the central claims about generalizable failure patterns (CoT penalizing GPT-4o by 9.2 pp, tripling Claude compile errors, WA dominating 70-90% of failures) rest on the assertion of a 'balanced taxonomy' across seven categories and three tiers. No sampling frame, inclusion/exclusion criteria, stratification procedure, or post-selection balance statistics (e.g., problem counts per cell) are supplied, so it is impossible to determine whether observed patterns reflect intrinsic algorithmic weaknesses or artifacts of the chosen 315 problems.
minor comments (1)
- [Abstract] The abstract reports exact percentages and error counts but does not indicate whether statistical significance tests or confidence intervals accompany the pass-rate differences.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological point. The concern about transparency in problem selection is valid, and we will strengthen the manuscript accordingly while preserving the core empirical findings on failure modes.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Problem Selection / Taxonomy Construction): the central claims about generalizable failure patterns (CoT penalizing GPT-4o by 9.2 pp, tripling Claude compile errors, WA dominating 70-90% of failures) rest on the assertion of a 'balanced taxonomy' across seven categories and three tiers. No sampling frame, inclusion/exclusion criteria, stratification procedure, or post-selection balance statistics (e.g., problem counts per cell) are supplied, so it is impossible to determine whether observed patterns reflect intrinsic algorithmic weaknesses or artifacts of the chosen 315 problems.
Authors: We agree that explicit documentation of the selection process is necessary for readers to evaluate potential selection artifacts. The 315 problems were manually curated from Codeforces to achieve coverage across the seven algorithm categories (e.g., Greedy, Dynamic Programming) and three difficulty tiers while ensuring each problem had publicly available test cases and a unique primary algorithm tag. In the revised manuscript we will add to §3: (1) the precise inclusion criteria (problems from contests 800–2000 rating, English statements, non-interactive, with at least 10 test cases), (2) the stratification procedure (target minimum of 10–15 problems per category-tier cell, with oversampling in underrepresented cells such as high-difficulty Graph problems), and (3) a new table reporting the final cell counts. We will also clarify that the taxonomy is a curated, balanced sample rather than a random or exhaustive draw from all Codeforces problems; the observed patterns (e.g., CoT penalty on GPT-4o) are therefore best interpreted as applying to this representative coverage of algorithmic types rather than as population estimates. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper reports pass rates, failure-mode counts, and ablation results from direct evaluation of GPT-4o and Claude on a fixed set of 315 Codeforces problems under controlled prompting conditions. No equations, fitted parameters, predictions derived from prior inputs, uniqueness theorems, or ansatzes appear anywhere in the text. All reported quantities (e.g., 46.0% to 36.8% pass-rate drop, 9-to-31 compile-error increase, WA dominance percentages) are direct empirical measurements, not reductions of the input data by construction. The representativeness claim is an unverified assumption about external validity rather than a circular step inside the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 315 Codeforces problems constitute a balanced taxonomy across seven algorithm categories and three difficulty tiers.
Reference graph
Works this paper leans on
-
[1]
The Claude 3 model family: Opus, sonnet, haiku
Anthropic. The Claude 3 model family: Opus, sonnet, haiku. Technical report, Anthropic, 2024
2024
-
[2]
Claude Sonnet 4.6
Anthropic. Claude Sonnet 4.6. Anthropic model announcement, 2026. Released February 2026. https: //www.anthropic.com/news
2026
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
CodeContests: A competitive programming dataset
DeepMind. CodeContests: A competitive programming dataset. HuggingFace Datasets, 2022. https:// huggingface.co/datasets/deepmind/code_contests
2022
-
[5]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, et al. DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks), 2021. arXiv:2105.09938
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
LiveCodeBench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[8]
Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
2022
-
[9]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, et al. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[10]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama
Theo X. Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama. Is self-repair a silver bullet for code generation? InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[11]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[14]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824–24837, 2022. 11 LLM Failure Taxonomy on Competitive ProgrammingPREPRINT Appendices A Prompt Templa...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.