Bounded Deep Unfolding for Joint Beamforming and Scheduling in Multi-Cell MIMO Networks
Pith reviewed 2026-06-28 04:17 UTC · model grok-4.3
The pith
A joint deep unfolding framework with P-Net and K-Net solves beamforming and RBG scheduling for higher weighted sum-rate in multi-cell MIMO networks while retaining convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
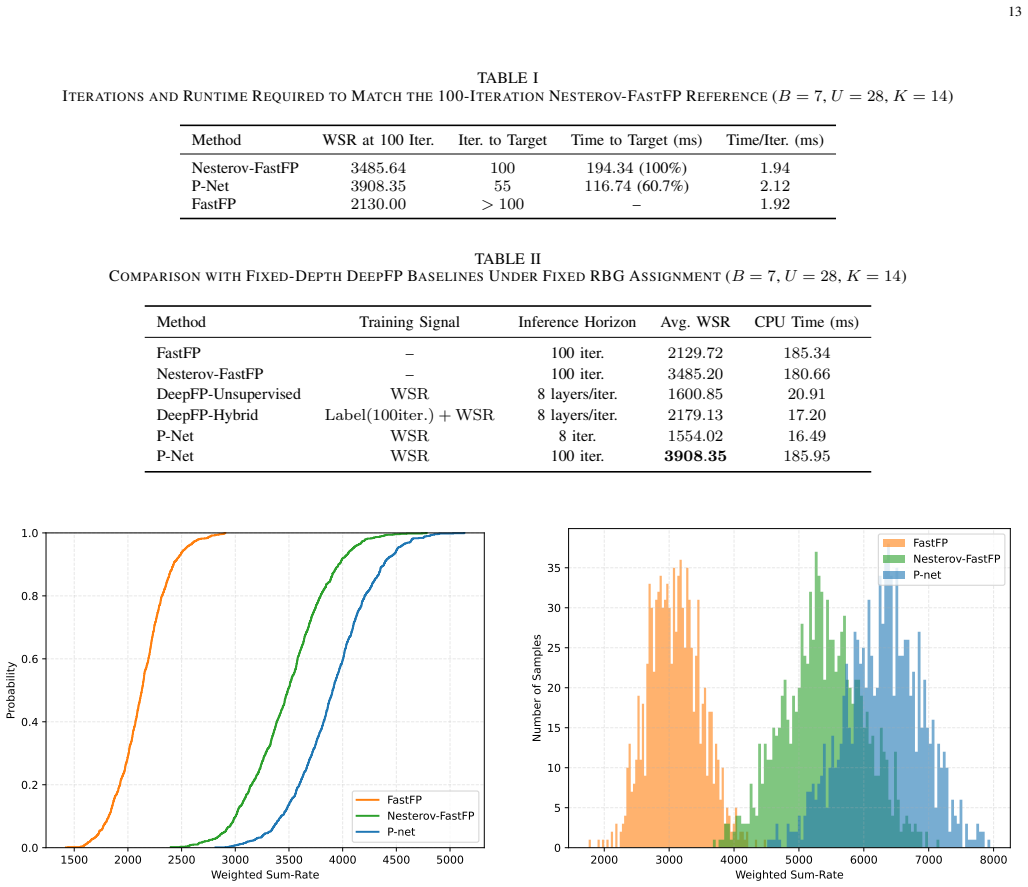
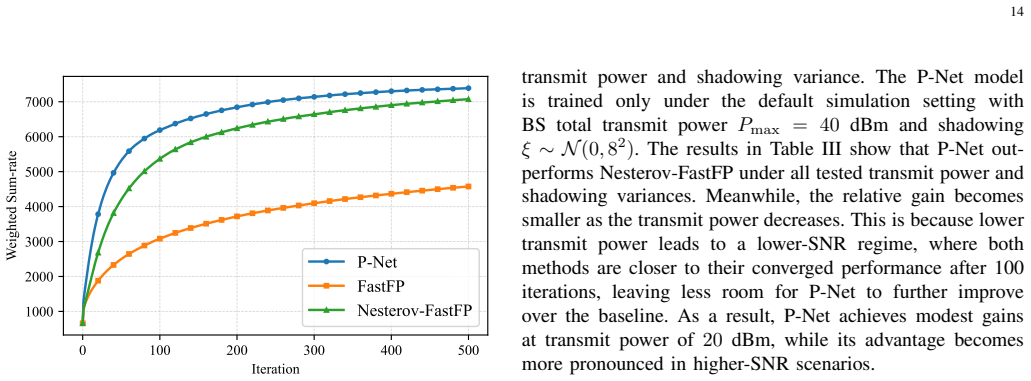
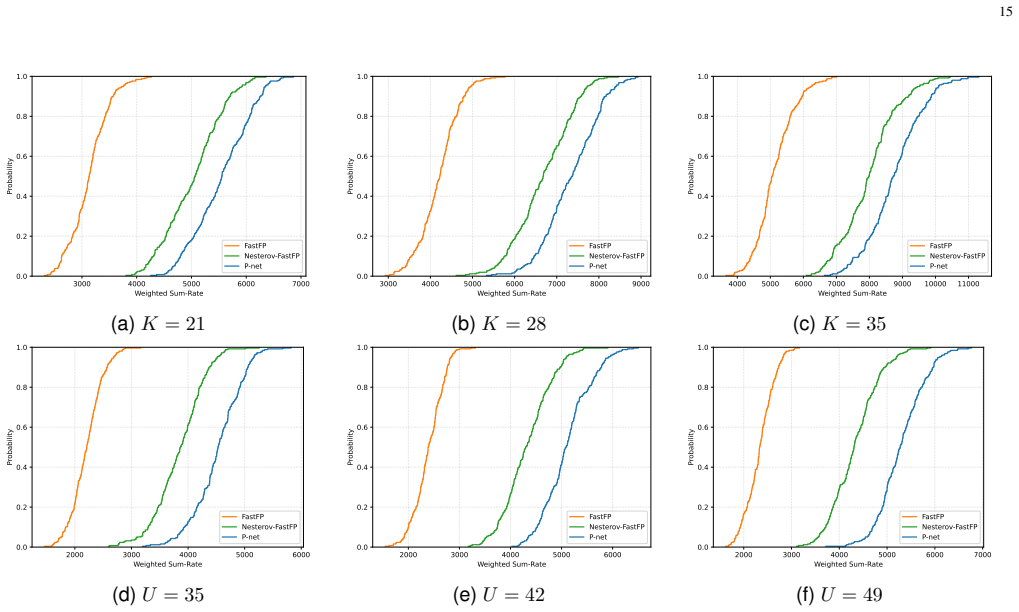
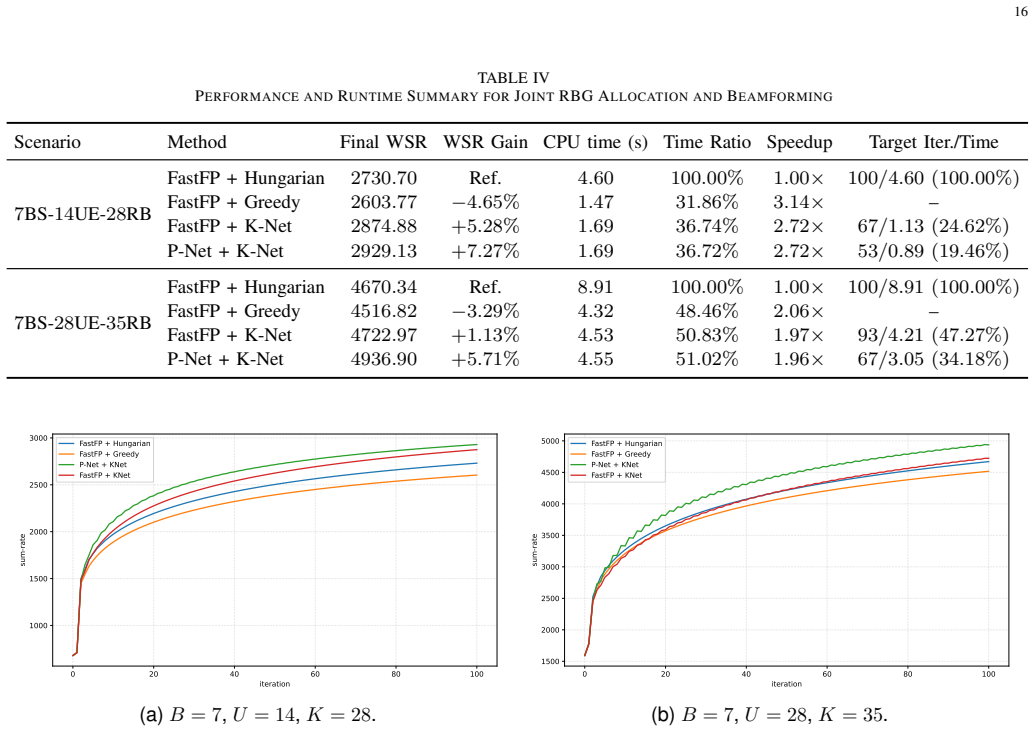
The paper claims that the proposed P-Net and K-Net modules, when inserted into the FastFP iteration, produce higher weighted sum-rate values and lower run times than the pure model-driven baseline, while the learned relaxation factor stays inside an ascent-preserving interval that guarantees monotonic improvement and stationary-point convergence, the learned priority policy matches the assignment quality of optimal matching, and the resulting networks generalize across unseen network scales, antenna numbers, and channel statistics without retraining.
What carries the argument
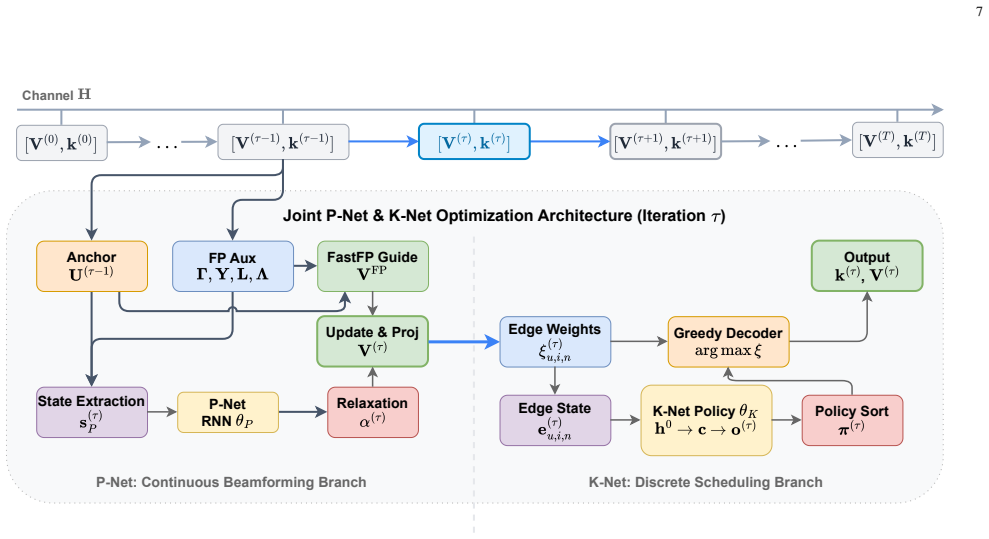
P-Net and K-Net, two recurrent deep-unfolding modules that learn an adaptive relaxation factor for beamforming and a priority policy for greedy scheduling, respectively, while staying inside the analytical structure of FastFP.
If this is right
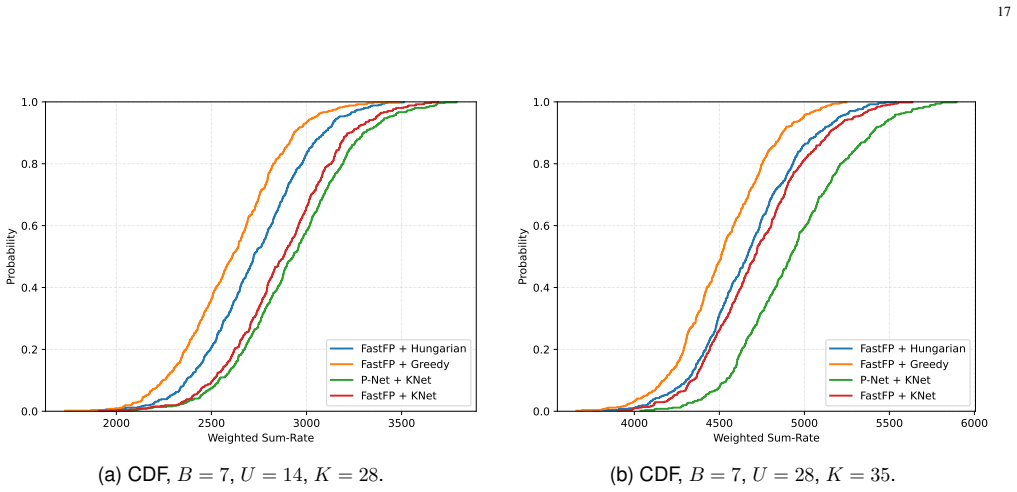
- The joint framework returns higher weighted sum-rate than conventional FastFP at every tested network scale.
- Execution time drops because the learned priority policy replaces the Hungarian matching step.
- Monotonic improvement and stationary-point convergence are retained by the constrained relaxation factor.
- The same trained networks operate on network sizes, antenna configurations, and channel distributions different from the training set.
- Recurrent parameter sharing removes the need to retrain when the optimization horizon changes.
Where Pith is reading between the lines
- The same unfolding pattern could be applied to other iterative resource-allocation algorithms that alternate between continuous updates and discrete assignment.
- Because the networks stay inside the original convergence envelope, they could serve as warm-starts for larger-scale or time-varying problems where full re-optimization is too slow.
- If the priority policy generalizes, similar learned greedy rules might replace combinatorial solvers in related matching problems such as user pairing or subcarrier allocation.
Load-bearing premise
Constraining the relaxation factor learned by P-Net to an ascent-preserving interval is enough to keep the monotonic improvement and stationary-point convergence of FastFP, and the priority policy learned by K-Net produces assignments whose quality is equivalent to Hungarian matching.
What would settle it
An experiment in which the WSR trajectory produced by the learned relaxation factor decreases on some iteration or the greedy assignment selected by the learned priorities yields a noticeably lower WSR than the Hungarian solution on the same channel realization.
Figures

read the original abstract
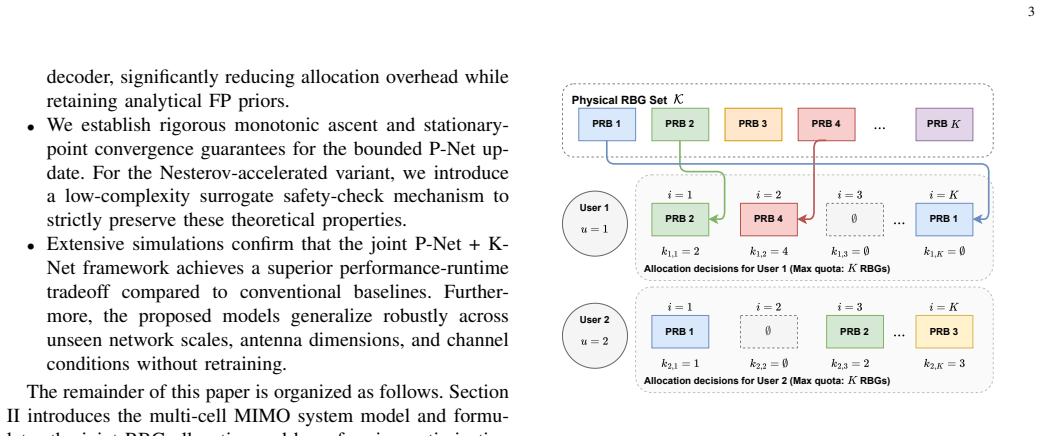
This paper investigates the joint resource block group (RBG) scheduling and beamforming optimization problem for weighted sum-rate (WSR) maximization in multi-cell multiple-input multiple-output (MIMO) downlink networks. While the Fast Fractional Programming (FastFP) framework provides a reliable model-driven solution, it suffers from conservative continuous beamforming updates and prohibitive computational overhead during the discrete RBG matching phase. To address these bottlenecks, we propose a joint deep unfolding framework comprising two core modules: P-Net and K-Net. For continuous beamforming, P-Net learns an adaptive relaxation factor along the analytical FastFP update direction. By strictly constraining this factor within an ascent-preserving interval, P-Net accelerates the optimization trajectory while rigorously retaining monotonic improvement and stationary-point convergence guarantees. For discrete RBG scheduling, K-Net learns a long-horizon priority policy that guides a low-complexity greedy assignment, effectively preserving the assignment quality while bypassing the high complexity of Hungarian matching. Both networks leverage analytical algorithmic priors and utilize recurrent parameter sharing, enabling flexible inference beyond the training horizon. Extensive simulations demonstrate that the proposed joint framework achieves higher WSR and faster execution times than conventional model-driven baselines, while generalizing robustly across unseen network scales, antenna configurations, and channel conditions without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a joint deep unfolding framework with P-Net (learning an adaptive relaxation factor for continuous beamforming, strictly constrained to an ascent-preserving interval to retain FastFP monotonicity and stationary-point convergence) and K-Net (learning a long-horizon priority policy for low-complexity greedy RBG scheduling that preserves Hungarian-level assignment quality) solves the joint scheduling and beamforming problem for WSR maximization in multi-cell MIMO networks. It asserts higher WSR, faster execution than model-driven baselines, and robust generalization to unseen scales/configurations without retraining, via recurrent parameter sharing and analytical priors.
Significance. If the retention of FastFP guarantees and assignment equivalence hold, the work offers a principled way to accelerate model-driven wireless optimization with learned components while preserving key analytical properties, which could enable practical real-time deployment in dense MIMO networks. The explicit use of recurrent sharing for flexible horizons and analytical priors for generalization are notable strengths.
major comments (3)
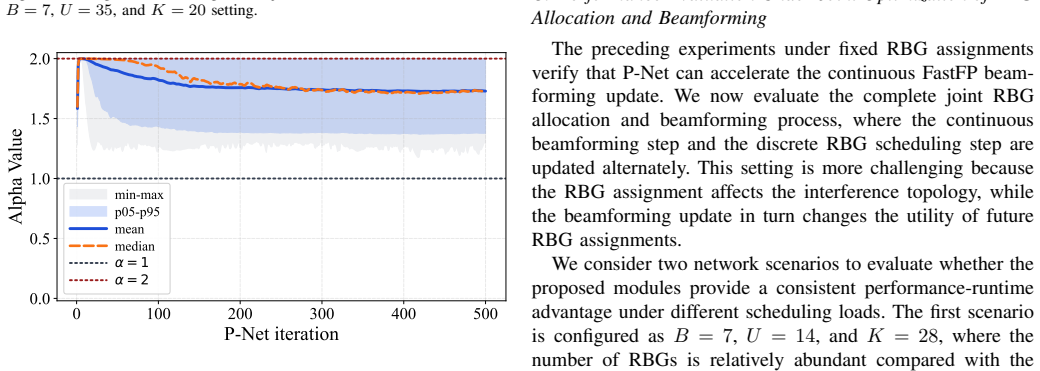
- [Abstract / P-Net description] Abstract and P-Net section: The central claim that 'strictly constraining this factor within an ascent-preserving interval' rigorously retains 'monotonic improvement and stationary-point convergence guarantees' of FastFP requires an explicit re-derivation or verification of the monotonicity step for the adaptive (learned) case, as the original FastFP proof may not directly extend when the factor varies per iteration or trajectory; without this, the model-driven foundation for reported WSR gains is load-bearing but unverified.
- [K-Net / Simulation results] K-Net and results sections: The assertion that the learned priority policy 'effectively preserving the assignment quality' equivalent to Hungarian matching is load-bearing for the joint performance claims, yet the manuscript provides no quantitative bound, worst-case analysis, or ablation showing equivalence across the tested channel conditions and network scales.
- [P-Net training and constraint enforcement] Methods and training description: The enforcement of the ascent-preserving interval constraint (via recurrent sharing) during training and inference is described at a high level, but lacks detail on how the interval is defined/computed from FastFP analysis and verified to hold for all trajectories, which is needed to substantiate the 'rigorously retaining' guarantee.
minor comments (2)
- [P-Net] Notation for the relaxation factor and interval bounds should be introduced with explicit equations early in the P-Net section to avoid ambiguity when discussing the constraint.
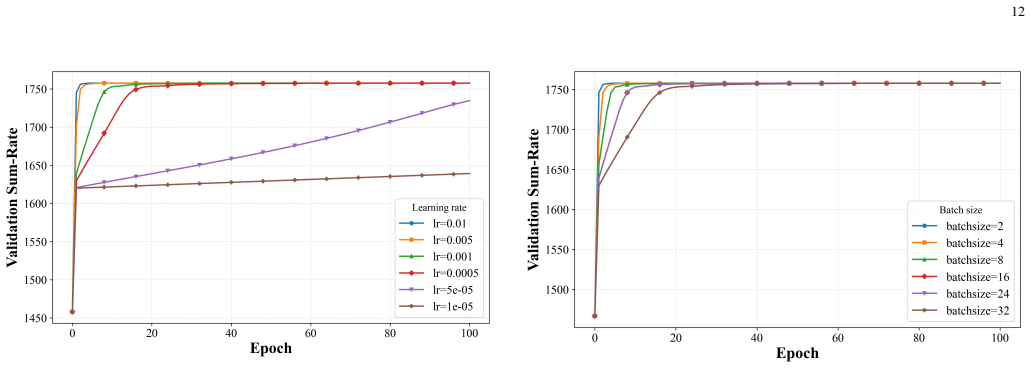
- [Simulation results] Figure captions and simulation tables should explicitly state the number of Monte Carlo trials and channel realizations used to support the generalization claims across unseen configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help strengthen the rigor of our claims. We address each major point below and will incorporate revisions to provide the requested derivations, details, and analyses.
read point-by-point responses
-
Referee: [Abstract / P-Net description] Abstract and P-Net section: The central claim that 'strictly constraining this factor within an ascent-preserving interval' rigorously retains 'monotonic improvement and stationary-point convergence guarantees' of FastFP requires an explicit re-derivation or verification of the monotonicity step for the adaptive (learned) case, as the original FastFP proof may not directly extend when the factor varies per iteration or trajectory; without this, the model-driven foundation for reported WSR gains is load-bearing but unverified.
Authors: We acknowledge that the original FastFP proof assumes a fixed factor and that an explicit extension is needed for the per-iteration adaptive case. The interval is chosen such that each update satisfies the same ascent inequality used in the original analysis, ensuring monotonicity holds trajectory-wise. We will add a dedicated lemma in the revised P-Net section deriving the interval bounds from the FastFP objective and verifying convergence for variable factors. revision: yes
-
Referee: [K-Net / Simulation results] K-Net and results sections: The assertion that the learned priority policy 'effectively preserving the assignment quality' equivalent to Hungarian matching is load-bearing for the joint performance claims, yet the manuscript provides no quantitative bound, worst-case analysis, or ablation showing equivalence across the tested channel conditions and network scales.
Authors: We agree that the current simulations, while showing close WSR performance, do not include explicit quantitative bounds or ablations. We will add a new ablation subsection in the results comparing the learned greedy policy against Hungarian matching on assignment accuracy and WSR gap across all tested scales and channel conditions. revision: yes
-
Referee: [P-Net training and constraint enforcement] Methods and training description: The enforcement of the ascent-preserving interval constraint (via recurrent sharing) during training and inference is described at a high level, but lacks detail on how the interval is defined/computed from FastFP analysis and verified to hold for all trajectories, which is needed to substantiate the 'rigorously retaining' guarantee.
Authors: We will expand the training and P-Net sections with explicit formulas for computing the ascent-preserving interval from the FastFP analysis, including the mathematical derivation of its bounds, and describe the verification procedure (via gradient projection and trajectory sampling) that ensures the constraint holds under recurrent sharing for all training and inference trajectories. revision: yes
Circularity Check
No significant circularity; claims rest on empirical validation and analytical constraints rather than self-referential reduction.
full rationale
The paper's core contribution is a deep-unfolding architecture (P-Net, K-Net) that inserts learned parameters inside intervals and policies whose ascent/quality properties are asserted to follow from the original FastFP analysis and Hungarian matching. Performance numbers (higher WSR, faster runtime, generalization) are obtained from simulation experiments on held-out channel realizations, not from any equation that equates the learned output to a fitted input by algebraic identity. No load-bearing step reduces a claimed guarantee to a self-citation or to a parameter that was itself optimized on the target metric; the constraint interval is presented as derived from the prior FastFP monotonicity proof, and the empirical gains are externally falsifiable. This places the work in the normal non-circular category for model-based learning papers.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive relaxation factor
axioms (2)
- domain assumption FastFP provides monotonic improvement and stationary-point convergence under its updates.
- domain assumption Recurrent parameter sharing allows generalization beyond training horizon.
invented entities (2)
-
P-Net
no independent evidence
-
K-Net
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Rethinking Fractional Programming for Joint Uplink Scheduling and Power Control in Multicell Wireless Networks
Proposes SEFP algorithm using a new reciprocal-inversion transform for improved weighted sum-rate maximization via joint uplink scheduling and power control in multicell networks.
Reference graph
Works this paper leans on
-
[1]
Framework and overall objectives of the future development of imt for 2030 and beyond,
ITU Radiocommunication Sector, “Framework and overall objectives of the future development of imt for 2030 and beyond,” International Telecommunication Union, Recommendation ITU-R M.2160-0, November 2023. [Online]. Available: https://itu.int
2030
-
[2]
Ericsson mobility report june 2024,
Ericsson, “Ericsson mobility report june 2024,” Ericsson, Tech. Rep., Jun. 2024. [Online]. Available: https://www.ericsson.com/en/ reports-and-papers/mobility-report
2024
-
[3]
6G wireless systems: Vision, requirements, challenges, insights, and opportunities,
H. Tataria, M. Shafi, A. F. Molisch, M. Dohler, H. Sj ¨oland, and F. Tufvesson, “6G wireless systems: Vision, requirements, challenges, insights, and opportunities,”Proceedings of the IEEE, vol. 109, no. 7, pp. 1166–1199, 2021
2021
-
[4]
The roadmap to 6g: Ai empowered wireless networks,
K. B. Letaief, W. Chen, Y . Shi, J. Zhang, and Y .-J. A. Zhang, “The roadmap to 6g: Ai empowered wireless networks,”IEEE communica- tions magazine, vol. 57, no. 8, pp. 84–90, 2019
2019
-
[5]
Multi-cell MIMO cooperative networks: A new look at interference,
D. Gesbert, S. Hanly, H. Huang, S. Shamai, O. Simeone, and W. Yu, “Multi-cell MIMO cooperative networks: A new look at interference,” IEEE Journal on Selected Areas in Communications, vol. 28, no. 9, pp. 1380–1408, 2010
2010
-
[6]
Optimal resource allocation in coordi- nated multi-cell systems,
E. Bj ¨ornson and E. Jorswieck, “Optimal resource allocation in coordi- nated multi-cell systems,”Foundations and Trends in Communications and Information Theory, vol. 9, no. 2–3, pp. 113–381, 2013
2013
-
[7]
Downlink scheduling and resource allocation for ofdm systems,
J. Huang, V . G. Subramanian, R. Agrawal, and R. A. Berry, “Downlink scheduling and resource allocation for ofdm systems,”IEEE Transac- tions on Wireless Communications, vol. 8, no. 1, pp. 288–296, 2009
2009
-
[8]
On the complexity of joint subcarrier and power allocation for multi-user ofdma systems,
Y .-F. Liu and Y .-H. Dai, “On the complexity of joint subcarrier and power allocation for multi-user ofdma systems,”IEEE Transactions on Signal Processing, vol. 62, no. 3, pp. 583–596, 2014
2014
-
[9]
Weighted max-min fair beam- forming, power control, and scheduling for a miso downlink,
B. Song, Y .-H. Lin, and R. L. Cruz, “Weighted max-min fair beam- forming, power control, and scheduling for a miso downlink,”IEEE Transactions on Wireless Communications, vol. 7, no. 2, pp. 464–469, 2008
2008
-
[10]
Multicell coordination via joint schedul- ing, beamforming, and power spectrum adaptation,
W. Yu, T. Kwon, and C. Shin, “Multicell coordination via joint schedul- ing, beamforming, and power spectrum adaptation,” inProceedings IEEE INFOCOM, 2011, pp. 2570–2578
2011
-
[11]
Downlink beamforming and resource al- location in multicell MISO-OFDMA systems,
N. U. Hassan and M. Assaad, “Downlink beamforming and resource al- location in multicell MISO-OFDMA systems,”Transactions on Emerg- ing Telecommunications Technologies, vol. 25, no. 2, pp. 173–182, 2014
2014
-
[12]
MIMO-OFDMA rate allocation and beamformer design using a multi-access channel framework,
A. Khanafer, T. J. Lim, R. Doostnejad, and T. Tang, “MIMO-OFDMA rate allocation and beamformer design using a multi-access channel framework,” inIEEE International Conference on Communications, 2012, pp. 2553–2558
2012
-
[13]
Weighted sum-rate maximization using weighted mmse for mimo-bc beamforming design,
S. S. Christensen, R. Agarwal, E. De Carvalho, and J. M. Cioffi, “Weighted sum-rate maximization using weighted mmse for mimo-bc beamforming design,”IEEE Transactions on Wireless Communications, vol. 7, no. 12, pp. 4792–4799, 2008
2008
-
[14]
An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,
Q. Shi, M. Razaviyayn, Z.-Q. Luo, and C. He, “An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,”IEEE Transactions on Signal Processing, vol. 59, no. 9, pp. 4331–4340, 2011
2011
-
[15]
Fractional programming for communication systems—part I: Power control and beamforming,
K. Shen and W. Yu, “Fractional programming for communication systems—part I: Power control and beamforming,”IEEE Transactions on Signal Processing, vol. 66, no. 10, pp. 2616–2630, 2018
2018
-
[16]
Rethinking WMMSE: Can its complexity scale linearly with the number of BS antennas?
X. Zhao, S. Lu, Q. Shi, and Z.-Q. Luo, “Rethinking WMMSE: Can its complexity scale linearly with the number of BS antennas?”IEEE Transactions on Signal Processing, vol. 71, pp. 433–446, 2023
2023
-
[17]
Fractional Programming for Communication Systems--Part II: Uplink Scheduling via Matching
K. Shen and W. Yu, “Fractional programming for communication systems—part II: Uplink scheduling via matching,”IEEE Transactions on Signal Processing, vol. 66, no. 10, pp. 2631–2644, 2018. [Online]. Available: https://arxiv.org/abs/1802.10197
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Optimizing downlink resource al- location in multiuser mimo networks via fractional programming and the hungarian algorithm,
A. A. Khan, R. S. Adve, and W. Yu, “Optimizing downlink resource al- location in multiuser mimo networks via fractional programming and the hungarian algorithm,”IEEE Transactions on Wireless Communications, vol. 19, no. 8, pp. 5162–5175, 2020
2020
-
[19]
Learning to optimize: Training deep neural networks for wireless re- source management,
H. Sun, X. Chen, Q. Shi, M. Hong, X. Fu, and N. D. Sidiropoulos, “Learning to optimize: Training deep neural networks for wireless re- source management,”IEEE Transactions on Signal Processing, vol. 66, no. 20, pp. 5438–5453, 2018
2018
-
[20]
Deep-learning-based wireless resource allocation with application to vehicular networks,
L. Liang, H. Ye, G. Yu, and G. Y . Li, “Deep-learning-based wireless resource allocation with application to vehicular networks,”Proceedings of the IEEE, vol. 108, no. 2, pp. 341–356, 2019
2019
-
[21]
A. Alwarafy, M. Abdallah, B. S. Ciftler, A. Al-Fuqaha, and M. Hamdi, “Deep reinforcement learning for radio resource allocation and management in next generation heterogeneous wireless networks: A survey,”arXiv preprint arXiv:2106.00574, 2021. [Online]. Available: https://arxiv.org/abs/2106.00574
-
[22]
Lorm: Learning to optimize for resource management in wireless networks with few training sam- ples,
Y . Shen, Y . Shi, J. Zhang, and K. B. Letaief, “Lorm: Learning to optimize for resource management in wireless networks with few training sam- ples,”IEEE Transactions on Wireless Communications, vol. 19, no. 1, pp. 665–679, 2020
2020
-
[23]
Spatial deep learning for wireless schedul- ing,
W. Cui, K. Shen, and W. Yu, “Spatial deep learning for wireless schedul- ing,”IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1248–1261, 2019
2019
-
[24]
Graph neural networks for scalable radio resource management: Architecture design and theoretical analysis,
Y . Shen, Y . Shi, J. Zhang, and K. B. Letaief, “Graph neural networks for scalable radio resource management: Architecture design and theoretical analysis,”IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 101–115, 2021
2021
-
[25]
Learning decentralized wireless resource allocations with graph neural networks,
Z. Wang, M. Eisen, and A. Ribeiro, “Learning decentralized wireless resource allocations with graph neural networks,”IEEE Transactions on Signal Processing, vol. 70, pp. 1850–1863, 2022
2022
-
[26]
Learning-based massive beamforming,
S. Lu, S. Zhao, and Q. Shi, “Learning-based massive beamforming,” inGLOBECOM 2020-2020 IEEE Global Communications Conference. IEEE, 2020, pp. 1–6
2020
-
[27]
Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,
V . Monga, Y . Li, and Y . C. Eldar, “Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,”IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 18–44, 2021
2021
-
[28]
Iterative algorithm induced deep-unfolding neural networks: Precoding design for mul- tiuser MIMO systems,
Q. Hu, Y . Cai, Q. Shi, K. Xu, G. Yu, and Z. Ding, “Iterative algorithm induced deep-unfolding neural networks: Precoding design for mul- tiuser MIMO systems,”IEEE Transactions on Wireless Communications, vol. 20, no. 2, pp. 1394–1410, 2021
2021
-
[29]
Matrix-inverse-free deep unfolding of the weighted mmse beamforming algorithm,
L. Pellaco, M. Bengtsson, and J. Jald ´en, “Matrix-inverse-free deep unfolding of the weighted mmse beamforming algorithm,”IEEE Open Journal of the Communications Society, vol. 3, pp. 65–81, 2021
2021
-
[30]
Deep graph unfolding for beamforming in MU-MIMO interference networks,
A. Chowdhury, G. Verma, A. Swami, and S. Segarra, “Deep graph unfolding for beamforming in MU-MIMO interference networks,”IEEE Transactions on Wireless Communications, vol. 23, no. 5, pp. 4889– 4903, 2024
2024
-
[31]
Deepfp: Deep-unfolded fractional programming for mimo beamforming,
J. Zhu, T.-H. Chang, L. Xiang, and K. Shen, “Deepfp: Deep-unfolded fractional programming for mimo beamforming,”IEEE Transactions on Communications, 2026
2026
-
[32]
Majorization-minimization algo- rithms in signal processing, communications, and machine learning,
Y . Sun, P. Babu, and D. P. Palomar, “Majorization-minimization algo- rithms in signal processing, communications, and machine learning,” IEEE Transactions on Signal Processing, vol. 65, no. 3, pp. 794–816, 2017
2017
-
[33]
Accelerating quadratic transform and WMMSE,
K. Shen, Z. Zhao, Y . Chen, Z. Zhang, and H. V . Cheng, “Accelerating quadratic transform and WMMSE,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 11, pp. 3110–3124, 2024
2024
-
[34]
Alista: Analytic weights are as good as learned weights in lista,
J. Liu, X. Chen, Z. Wang, and W. Yin, “Alista: Analytic weights are as good as learned weights in lista,” inInternational conference on learning representations, 2019
2019
-
[35]
Deep unfolding of a proximal interior point method for image restoration,
C. Bertocchi, E. Chouzenoux, M.-C. Corbineau, J.-C. Pesquet, and M. Prato, “Deep unfolding of a proximal interior point method for image restoration,”Inverse Problems, vol. 36, no. 3, p. 034005, 2020
2020
-
[36]
Learned reconstruction methods with convergence guaran- tees: A survey of concepts and applications,
S. Mukherjee, A. Hauptmann, O. ¨Oktem, M. Pereyra, and C.-B. Sch¨onlieb, “Learned reconstruction methods with convergence guaran- tees: A survey of concepts and applications,”IEEE Signal Processing Magazine, vol. 40, no. 1, pp. 164–182, 2023
2023
-
[37]
Policy gradi- ent methods for reinforcement learning with function approximation,
R. S. Sutton, D. McAllester, S. Singh, and Y . Mansour, “Policy gradi- ent methods for reinforcement learning with function approximation,” Advances in neural information processing systems, vol. 12, 1999
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.