I Know What You Meme, Even If it Emerged Today: Understanding Evolving Memes through Open-World Knowledge Acquisition
Pith reviewed 2026-06-28 06:17 UTC · model grok-4.3
The pith
Zero-shot framework retrieves open-web evidence to interpret emerging memes that pretrained models miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
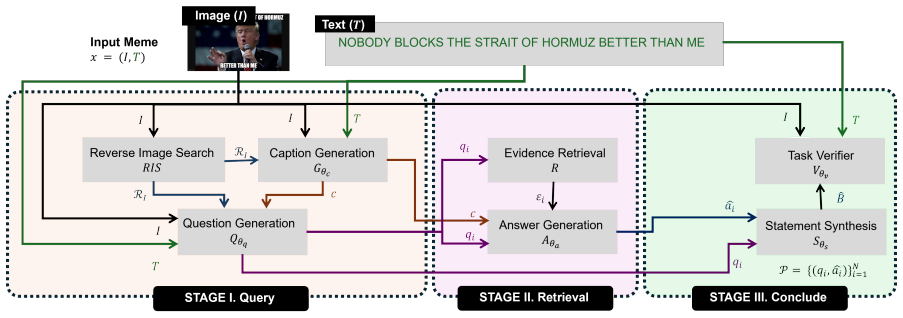
Query Retrieve Conclude identifies missing knowledge, retrieves open-web evidence, and synthesizes evidence-grounded background knowledge, thereby improving meme understanding and detection over zero-shot baselines on three understanding datasets and five detection tasks.
What carries the argument
Query Retrieve Conclude: a three-step loop that locates knowledge gaps, fetches web evidence, and concludes with synthesized interpretations.
If this is right
- Knowledge recovery improves on the three meme understanding datasets.
- Detection accuracy increases across the five downstream tasks.
- The method handles memes created after typical model training cutoffs.
- The new benchmark supplies external knowledge annotations for future work on evolving content.
Where Pith is reading between the lines
- The same gap-identify-and-retrieve loop could extend to other fast-changing multimodal domains such as current-event images or social video.
- Retrieval grounding may reduce the need for periodic full-model retraining when new cultural references appear.
- Adversarial tests that inject conflicting web results would clarify how robust the synthesis step remains.
Load-bearing premise
Open-web retrieval will reliably return accurate, relevant evidence without noise or misleading content that harms interpretation.
What would settle it
Measure whether performance on the 2024-2026 benchmark drops below zero-shot baselines when retrieval is limited to deliberately noisy or outdated sources.
Figures


read the original abstract
Multimodal memes are dynamic and often require up to date background knowledge for interpretation. Existing methods often overlook such knowledge or rely on fixed parametric knowledge of pretrained models that may be incomplete, outdated, or unavailable for emerging memes. We introduce Query Retrieve Conclude, a zero shot framework that identifies missing knowledge, retrieves open web evidence, and synthesizes evidence grounded background knowledge for meme understanding and detection. We also introduce a curated meme understanding benchmark of recent memes from 2024 to 2026 with external background knowledge annotations. Experiments on three meme understanding datasets and five meme detection tasks show that our framework improves knowledge recovery, meme understanding and downstream detection over zero shot baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Query-Retrieve-Conclude (QRC) zero-shot framework for multimodal meme understanding and detection. QRC identifies missing knowledge in a meme, retrieves open-web evidence, and synthesizes it into grounded background knowledge to handle evolving memes whose interpretation requires up-to-date external information beyond pretrained model parameters. The authors also release a new curated benchmark of 2024–2026 memes annotated with external background knowledge. Experiments are reported on three meme-understanding datasets and five detection tasks, claiming improvements over zero-shot baselines in knowledge recovery, understanding, and downstream detection.
Significance. If the empirical claims hold after proper validation, the work targets a genuine and practically relevant gap: parametric knowledge in current multimodal models is static and insufficient for rapidly evolving cultural artifacts such as memes. The release of a temporally recent, externally annotated benchmark is a concrete positive contribution that could support reproducible research on open-world knowledge acquisition.
major comments (2)
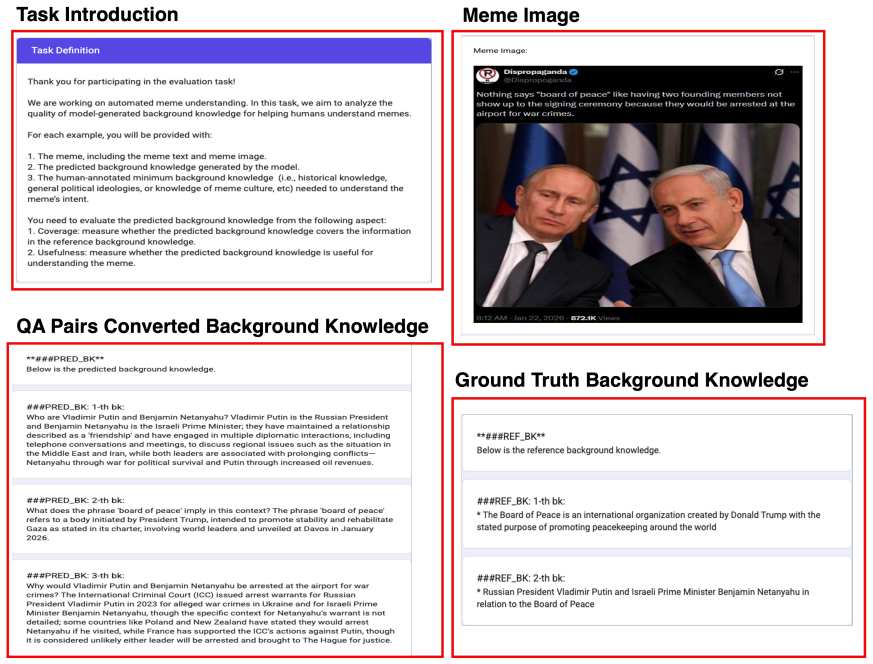
- [Experiments] Experiments section: the headline claim of consistent gains on three understanding datasets and five detection tasks rests on the unvalidated assumption that open-web retrieval returns accurate, relevant, and non-misleading evidence for 2024–2026 memes. No retrieval metrics (precision@K, relevance judgments, or error analysis of returned documents) or ablations that degrade retrieval quality are provided, leaving open the possibility that reported improvements are artifacts of the particular test set or post-hoc filtering.
- [Method] Method (Query-Retrieve-Conclude pipeline): the synthesis step that produces “evidence-grounded background knowledge” is described at a high level but supplies no concrete procedure for handling contradictory, outdated, or irrelevant retrieved pages. Because this step is load-bearing for the framework’s correctness on emerging memes, the absence of implementation details or robustness checks weakens the central empirical claim.
minor comments (2)
- [Abstract / Introduction] The abstract states that experiments cover “five meme detection tasks” yet does not enumerate them; the introduction or experimental setup should list the tasks and the exact evaluation metrics used.
- [Dataset] The new benchmark is introduced with “external background knowledge annotations,” but no information is given on annotation protocol, number of annotators, or inter-annotator agreement; these details belong in the dataset section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below and commit to revisions that strengthen the empirical validation and methodological transparency.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim of consistent gains on three understanding datasets and five detection tasks rests on the unvalidated assumption that open-web retrieval returns accurate, relevant, and non-misleading evidence for 2024–2026 memes. No retrieval metrics (precision@K, relevance judgments, or error analysis of returned documents) or ablations that degrade retrieval quality are provided, leaving open the possibility that reported improvements are artifacts of the particular test set or post-hoc filtering.
Authors: We agree this is a substantive gap. The current manuscript reports only end-to-end task performance and does not include retrieval-specific metrics or quality ablations. In the revision we will add (i) human-annotated precision@K and relevance scores on a sample of retrieved documents for the 2024–2026 memes, (ii) an error analysis of misleading or outdated pages, and (iii) an ablation that replaces the retriever with random or low-quality documents to quantify sensitivity to retrieval noise. These additions will directly test the assumption underlying the headline claims. revision: yes
-
Referee: [Method] Method (Query-Retrieve-Conclude pipeline): the synthesis step that produces “evidence-grounded background knowledge” is described at a high level but supplies no concrete procedure for handling contradictory, outdated, or irrelevant retrieved pages. Because this step is load-bearing for the framework’s correctness on emerging memes, the absence of implementation details or robustness checks weakens the central empirical claim.
Authors: The synthesis (Conclude) component is currently presented at a high level. We will expand the method section with an explicit algorithm that details (a) filtering of irrelevant pages via embedding similarity thresholds, (b) resolution of contradictions by recency-weighted majority and source reliability scoring, and (c) discarding of clearly outdated content using publication-date heuristics. We will also report a controlled robustness experiment that injects contradictory or irrelevant documents into the retrieval set. These procedures were used in our implementation but were not fully documented; the revision will make them reproducible. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks and retrieval pipeline
full rationale
The paper presents a zero-shot Query-Retrieve-Conclude framework and evaluates it on three understanding datasets plus five detection tasks against zero-shot baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim is an empirical performance delta; it does not reduce to any input by construction. Retrieval quality is an unvalidated modeling assumption, but that is a correctness or robustness concern, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems , year =
Douwe Kiela and Hamed Firooz and Aravind Mohan and Vedanuj Goswami and Amanpreet Singh and Pratik Ringshia and Davide Testuggine , title =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems , year =
-
[2]
ACM Transactions on Intelligent Systems and Technology , year=
Goat-bench: Safety insights to large multimodal models through meme-based social abuse , author=. ACM Transactions on Intelligent Systems and Technology , year=
-
[3]
Transactions of the Association for Computational Linguistics , volume=
Ev2r: Evaluating evidence retrieval in automated fact-checking , author=. Transactions of the Association for Computational Linguistics , volume=. 2026 , publisher=
2026
-
[4]
arXiv preprint arXiv:2505.17978 , year=
AVerImaTeC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the Web , author=. arXiv preprint arXiv:2505.17978 , year=
-
[5]
2018 , publisher=
The world made meme: Public conversations and participatory media , author=. 2018 , publisher=
2018
-
[6]
Companion Proceedings of the ACM Web Conference 2024 , pages=
Contextualizing internet memes across social media platforms , author=. Companion Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[7]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Prompting for multimodal hateful meme classification , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[8]
Proceedings of the 31st ACM international conference on multimedia , pages=
Pro-cap: Leveraging a frozen vision-language model for hateful meme detection , author=. Proceedings of the 31st ACM international conference on multimedia , pages=
-
[9]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Recent advances in online hate speech moderation: Multimodality and the role of large models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
AdamMeme: Adaptively probe the reasoning capacity of multimodal large language models on harmfulness , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
arXiv preprint arXiv:2601.07232 , year=
Yes FLoReNce, I Will Do Better Next Time! Agentic Feedback Reasoning for Humorous Meme Detection , author=. arXiv preprint arXiv:2601.07232 , year=
-
[12]
Proceedings of the
Hongzhan Lin and Ziyang Luo and Wei Gao and Jing Ma and Bo Wang and Ruichao Yang , title =. Proceedings of the
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
MemeInterpret: Towards an All-in-One Dataset for Meme Understanding , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[14]
IEEE Transactions on Knowledge and Data Engineering , year=
ExplainHM++: Explainable Harmful Meme Detection With Retrieval-Augmented Debate Between Large Multimodal Models , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[15]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Demystifying hateful content: Leveraging large multimodal models for hateful meme detection with explainable decisions , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[16]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Computational meme understanding: a survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[17]
Proceedings of the ACM Web Conference 2024 , pages=
Modularized networks for few-shot hateful meme detection , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[18]
Proceedings of the 29th ACM international conference on multimedia , pages=
Disentangling hate in online memes , author=. Proceedings of the 29th ACM international conference on multimedia , pages=
-
[19]
Findings of the association for computational linguistics: EMNLP 2021 , pages=
MOMENTA: A multimodal framework for detecting harmful memes and their targets , author=. Findings of the association for computational linguistics: EMNLP 2021 , pages=
2021
-
[20]
MemeCLIP: Leveraging CLIP Representations for Multimodal Meme Classification
Shah, Siddhant Bikram and Shiwakoti, Shuvam and Chaudhary, Maheep and Wang, Haohan. MemeCLIP: Leveraging CLIP Representations for Multimodal Meme Classification. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.959
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
Eunjeong Hwang and Vered Shwartz , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. 2023 , url =
2023
-
[22]
Shad Akhtar and Tanmoy Chakraborty , title =
Shivam Sharma and Siddhant Agarwal and Tharun Suresh and Preslav Nakov and Md. Shad Akhtar and Tanmoy Chakraborty , title =. Thirty-Seventh
-
[23]
Proceedings of the Second Workshop on NLP for Positive Impact (NLP4PI) , pages=
Hate-clipper: Multimodal hateful meme classification based on cross-modal interaction of clip features , author=. Proceedings of the Second Workshop on NLP for Positive Impact (NLP4PI) , pages=
-
[24]
arXiv preprint arXiv:2305.17678 , year=
Decoding the underlying meaning of multimodal hateful memes , author=. arXiv preprint arXiv:2305.17678 , year=
-
[25]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mind: A multi-agent framework for zero-shot harmful meme detection , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
arXiv preprint arXiv:2601.04692 , year=
See, Explain, and Intervene: A Few-Shot Multimodal Agent Framework for Hateful Meme Moderation , author=. arXiv preprint arXiv:2601.04692 , year=
-
[27]
CoRR , volume =
Jingbiao Mei and Mingsheng Sun and Jinghong Chen and Pengda Qin and Yuhong Li and Da Chen and Bill Byrne , title =. CoRR , volume =
-
[28]
CoRR , volume =
Fengjun Pan and Anh Tuan Luu and Xiaobao Wu , title =. CoRR , volume =
-
[29]
Proceedings of the ACM Web Conference 2026 , pages=
They Said Memes Were Harmless---We Found the Ones That Hurt: Decoding Jokes, Symbols, and Cultural References , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[30]
Proceedings of the ACM web conference 2023 , pages=
Identifying creative harmful memes via prompt based approach , author=. Proceedings of the ACM web conference 2023 , pages=
2023
-
[31]
Proceedings of the ACM web conference 2022 , pages=
On explaining multimodal hateful meme detection models , author=. Proceedings of the ACM web conference 2022 , pages=
2022
-
[32]
arXiv preprint arXiv:2012.07788 , year=
Vilio: State-of-the-art visio-linguistic models applied to hateful memes , author=. arXiv preprint arXiv:2012.07788 , year=
-
[33]
Language models as knowledge bases? , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[34]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Mememqa: Multimodal question answering for memes via rationale-based inferencing , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[35]
Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022) , pages=
SemEval-2022 task 5: Multimedia automatic misogyny identification , author=. Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022) , pages=
2022
-
[36]
Proceedings of the WILDRE5--5th workshop on indian language data: resources and evaluation , pages=
A dataset for troll classification of TamilMemes , author=. Proceedings of the WILDRE5--5th workshop on indian language data: resources and evaluation , pages=
-
[37]
All-in-one: A deep attentive multi-task learning framework for humour, sarcasm, offensive, motivation, and sentiment on memes , author=. Proceedings of the 1st conference of the Asia-Pacific chapter of the association for computational linguistics and the 10th international joint conference on natural language processing , pages=
-
[38]
arXiv preprint arXiv:2205.04274 , year=
Detecting and understanding harmful memes: A survey , author=. arXiv preprint arXiv:2205.04274 , year=
-
[39]
Proceedings of the ACM on Web Conference 2025 , pages=
Ask, acquire, understand: A multimodal agent-based framework for social abuse detection in memes , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[40]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Gemma 3. 2025 , keywords =. doi:10.48550/ARXIV.2503.19786 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[42]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[43]
Gemma 3 technical report. CoRR abs/2503.19786 (2025) , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Scientific Reports , volume=
Entropy and complexity unveil the landscape of memes evolution , author=. Scientific Reports , volume=. 2021 , publisher=
2021
-
[45]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MemeQA: Holistic evaluation for meme understanding , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
MemeIntent: Benchmarking intent description generation for memes , author=. Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
-
[47]
, author=
The proof and measurement of association between two things. , author=. 1961 , publisher=
1961
-
[48]
Mathematical contributions to the theory of evolution.—III
VII. Mathematical contributions to the theory of evolution.—III. Regression, heredity, and panmixia , author=. Philosophical Transactions of the Royal Society of London. Series A, containing papers of a mathematical or physical character , number=. 1896 , publisher=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.