Environment-Robust Representation Learning with Empirical Bayes
Pith reviewed 2026-06-28 03:48 UTC · model grok-4.3
The pith
A Bayesian model using empirical Bayes and variational inference learns latent representations that support prediction in new environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
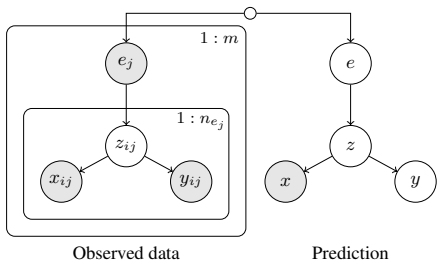
We consider multi-environment prediction problems where environments change the distribution of a latent variable but the mechanisms generating observed covariates and targets remain stable conditional on that variable. We formulate a Bayesian model, derive a variational objective that decomposes into per-environment terms and a cross-environment balancing term, use empirical Bayes to set the prior, and develop an amortized variational algorithm whose learned latents enable predictions in new environments, outperforming previous approaches in astronomical, microbiome, and ICU prediction tasks.
What carries the argument
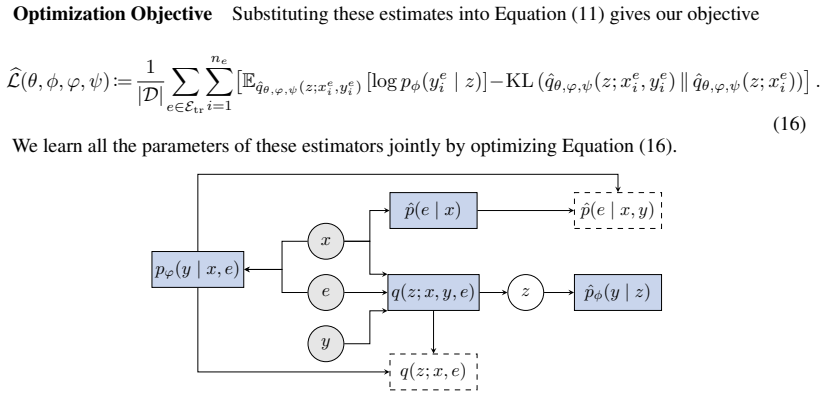
The decomposed variational objective with its cross-environment balancing term, combined with an empirical Bayes prior and amortized variational inference for the latent posterior.
If this is right
- The learned latent representations can be used directly for prediction in unseen environments.
- The method applies to settings like hospital cohorts with varying disease prevalence but stable physiological relationships.
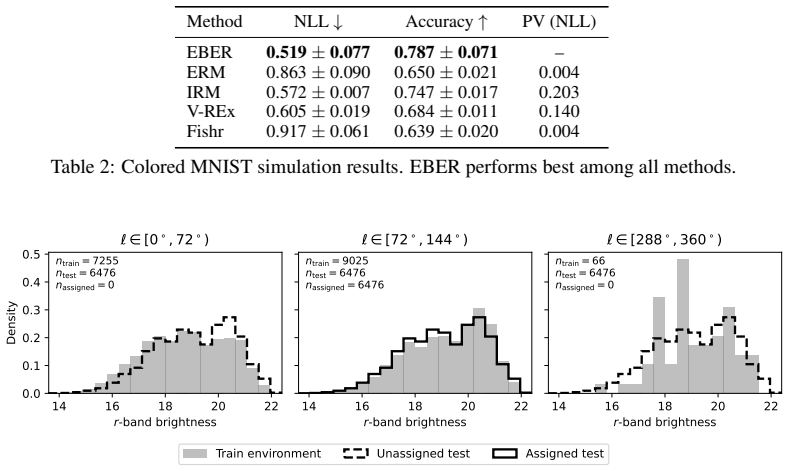
- Performance gains are shown in source identification, disease detection, and sepsis prediction tasks.
- The balancing term induced by the model structure supports robustness across environments.
Where Pith is reading between the lines
- If the assumption holds, the method provides a way to handle prevalence shifts without retraining on new data.
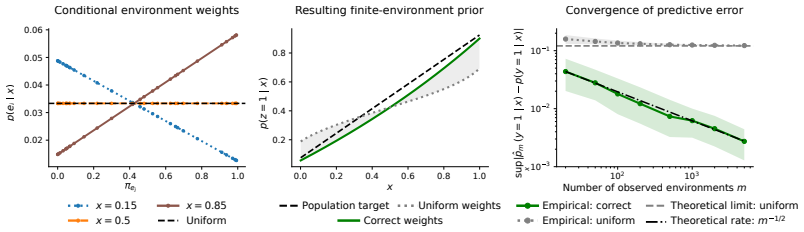
- The empirical Bayes prior choice may affect performance when data per environment is limited.
- The balancing term may implicitly encourage some invariance in the learned representations.
Load-bearing premise
Environments change only the distribution of the latent variable, while the conditional mechanisms for covariates and targets remain stable.
What would settle it
Collecting data from an additional environment with shifted latent distribution but unchanged mechanisms and finding no accuracy gain over baselines would falsify the performance advantage.
Figures
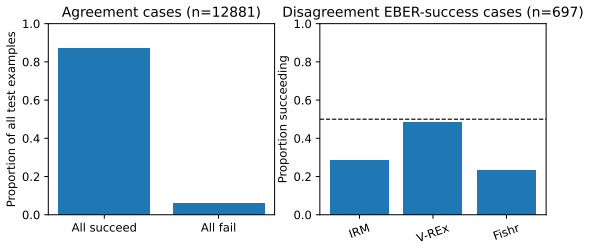
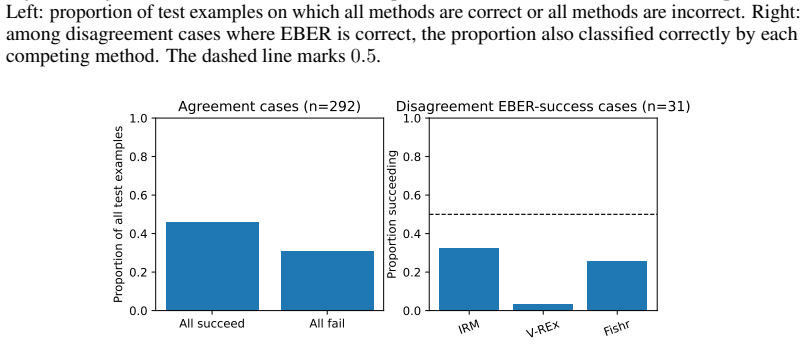
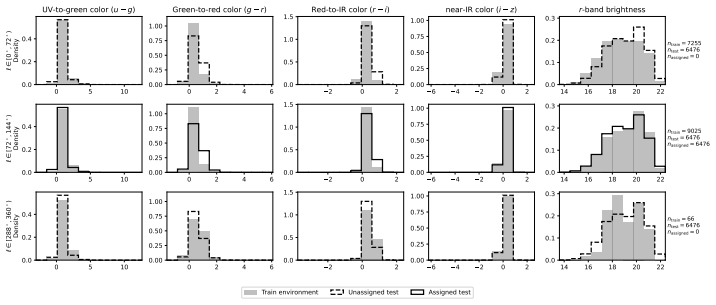
read the original abstract
We consider multi-environment prediction problems. We assume the environments change the distribution of a latent variable, while the mechanisms generating observed covariates and targets remain stable conditional on that variable. For example, hospitals or clinical cohorts may differ in the prevalence of latent patient states, even though the relationships between those states, physiological measurements, and outcomes remain unchanged. Given a dataset from multiple environments, we formulate a Bayesian model for such problems and derive the corresponding variational objective. We show that this objective decomposes into per-environment terms and an additional cross-environment balancing term induced by the model's structure. We use an empirical Bayes method to set the prior and incorporate it into the objective. Based on this objective, we develop an amortized variational algorithm for posterior approximation, and use the resulting learned latent variables to form predictions in new environments.We study our approach through simulations and real-world studies of astronomical source identification, microbiome-based disease detection, and ICU sepsis prediction. Across these settings, our method outperforms previous approaches for prediction in new environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses multi-environment prediction under the assumption that environments shift only the distribution of a latent variable while the conditional mechanisms generating covariates and targets remain invariant. It formulates a Bayesian model, derives a variational objective that decomposes into per-environment terms plus a cross-environment balancing term, sets the prior via empirical Bayes, develops an amortized variational inference algorithm, and uses the learned latents for prediction in new environments. Empirical evaluation on simulations plus three real-world tasks (astronomical source identification, microbiome disease detection, ICU sepsis prediction) reports outperformance over prior methods.
Significance. If the claimed outperformance and robustness hold under the stated invariance assumption, the approach supplies a structured variational framework that explicitly separates environment-specific latent shifts from stable mechanisms. The explicit decomposition of the objective and the use of empirical Bayes for the prior are technically natural extensions of standard amortized inference; reproducible code or machine-checked derivations would further strengthen the contribution for applications in clinical and scientific domains with batch effects.
minor comments (3)
- [§3] The abstract and introduction state the invariance assumption clearly, but §3 (model and objective) should include an explicit statement of the conditional independence assumptions (e.g., p(X,Y|Z,env) = p(X,Y|Z)) to make the balancing term derivation fully self-contained.
- [Table 2] Table 2 (real-world results) reports performance metrics but omits standard errors or the number of random seeds; adding these would allow readers to assess whether the reported gains are statistically distinguishable from the baselines.
- [§4.2] The empirical Bayes step for the prior is described in §4.2; a short paragraph comparing the chosen hyperprior to a fully Bayesian alternative (or justifying the point estimate) would clarify the modeling choice.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the paper and for the positive recommendation of minor revision. The significance assessment correctly identifies the technical contributions of the variational decomposition and empirical Bayes prior. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The derivation begins from an explicitly stated modeling assumption (environments affect only the latent distribution; conditional mechanisms are invariant). The variational objective and its per-environment plus balancing-term decomposition follow directly from the Bayesian model structure without reducing to fitted quantities by construction. Empirical Bayes is invoked as a standard prior-setting technique, not as a renamed fit. Performance results are presented as external empirical evaluations across simulations and real datasets rather than internal predictions forced by the fitting procedure. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work appear in the derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- prior parameters
axioms (1)
- domain assumption Environments alter only the marginal distribution of the latent variable; conditional mechanisms for covariates and targets are invariant across environments.
Reference graph
Works this paper leans on
-
[1]
Invariant risk minimization games
Kartik Ahuja, Karthikeyan Shanmugam, Kush Varshney, and Amit Dhurandhar. Invariant risk minimization games. InInternational Conference on Machine Learning, pages 145–155. PMLR, 2020
2020
-
[2]
Romina Ahumada, Carlos Allende Prieto, Andrés Almeida, Friedrich Anders, Scott F Anderson, Brett H Andrews, Borja Anguiano, Riccardo Arcodia, Eric Armengaud, Marie Aubert, et al. The 16th data release of the sloan digital sky surveys: first release from the apogee-2 southern survey and full release of eboss spectra.The Astrophysical Journal Supplement Ser...
2020
-
[3]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[4]
Robust solutions of optimization problems affected by uncertain probabilities.Management Science, 59(2):341–357, 2013
Aharon Ben-Tal, Dick Den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities.Management Science, 59(2):341–357, 2013
2013
-
[5]
A framework for human microbiome research
The Human Microbiome Project Consortium. A framework for human microbiome research. Nature, 486(7402):215–221, 2012
2012
-
[6]
Learning models with uniform performance via distributionally robust optimization.The Annals of Statistics, 49(3):1378–1406, 2021
John C Duchi and Hongseok Namkoong. Learning models with uniform performance via distributionally robust optimization.The Annals of Statistics, 49(3):1378–1406, 2021
2021
-
[7]
Statistics of robust optimization: A generalized empirical likelihood approach.Mathematics of Operations Research, 46(3): 946–969, 2021
John C Duchi, Peter W Glynn, and Hongseok Namkoong. Statistics of robust optimization: A generalized empirical likelihood approach.Mathematics of Operations Research, 46(3): 946–969, 2021
2021
-
[8]
Meta- analysis of gut microbiome studies identifies disease-specific and shared responses.Nature communications, 8(1):1784, 2017
Claire Duvallet, Sean M Gibbons, Thomas Gurry, Rafael A Irizarry, and Eric J Alm. Meta- analysis of gut microbiome studies identifies disease-specific and shared responses.Nature communications, 8(1):1784, 2017
2017
-
[9]
Cambridge University Press, 2012
Bradley Efron.Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction. Cambridge University Press, 2012. ISBN 9780511761362. doi: 10.1017/ CBO9780511761362
2012
-
[10]
A Humphrey, W Kuberski, J Bialek, N Perrakis, W Cools, N Nuyttens, H Elakhrass, and PAC Cunha. Machine-learning classification of astronomical sources: estimating f1-score in the absence of ground truth.Monthly Notices of the Royal Astronomical Society: Letters, 517(1): L116–L120, 2022
2022
-
[11]
Capturing label characteristics in vaes.arXiv preprint arXiv:2006.10102, 2020
Tom Joy, Sebastian M Schmon, Philip HS Torr, N Siddharth, and Tom Rainforth. Capturing label characteristics in vaes.arXiv preprint arXiv:2006.10102, 2020
-
[12]
Auto-encoding variational bayes.International Confer- ence on Learning Representations, 2014
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.International Confer- ence on Learning Representations, 2014
2014
-
[13]
Learning latent subspaces in variational autoencoders
Jack Klys, Jake Snell, and Richard Zemel. Learning latent subspaces in variational autoencoders. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[14]
Out-of-distribution generalization via risk extrap- olation (rex)
David Krueger, Ethan Caballero, Joern-Henrik Jacobsen, Amy Zhang, Jonathan Binas, Dinghuai Zhang, Remi Le Priol, and Aaron Courville. Out-of-distribution generalization via risk extrap- olation (rex). InInternational Conference on Machine Learning, pages 5815–5826. PMLR, 2021
2021
-
[15]
Nonparametric maximum likelihood estimation of a mixing distribution.Journal of the American Statistical Association, 73(364):805–811, 1978
Nan Laird. Nonparametric maximum likelihood estimation of a mixing distribution.Journal of the American Statistical Association, 73(364):805–811, 1978
1978
-
[16]
Bayesian invariant risk minimization
Yong Lin, Hanze Dong, Hao Wang, and Tong Zhang. Bayesian invariant risk minimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16021–16030, 2022
2022
-
[17]
Deep generative modeling for single-cell transcriptomics.Nature Methods, 15(12):1053–1058, 2018
Romain Lopez, Jeffrey Regier, Michael B Cole, Michael I Jordan, and Nir Yosef. Deep generative modeling for single-cell transcriptomics.Nature Methods, 15(12):1053–1058, 2018. 12
2018
-
[18]
Invariant causal representation learning for out-of-distribution generalization
Chaochao Lu, Yuhuai Wu, José Miguel Hernández-Lobato, and Bernhard Schölkopf. Invariant causal representation learning for out-of-distribution generalization. InInternational Conference on Learning Representations, 2021
2021
-
[19]
Jonas Peters, Peter Bühlmann, and Nicolai Meinshausen. Causal inference by using invariant prediction: identification and confidence intervals.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):947–1012, 2016
2016
-
[20]
Focus on the common good: Group distributional robustness follows
Vihari Piratla, Praneeth Netrapalli, and Sunita Sarawagi. Focus on the common good: Group distributional robustness follows. InInternational Conference on Learning Representations, 2021
2021
-
[21]
Fishr: Invariant gradient variances for out-of-distribution generalization
Alexandre Rame, Corentin Dancette, and Matthieu Cord. Fishr: Invariant gradient variances for out-of-distribution generalization. InInternational Conference on Machine Learning, pages 18347–18377. PMLR, 2022
2022
-
[22]
Early prediction of sepsis from clinical data: the physionet/computing in cardiology challenge 2019.Critical care medicine, 48 (2):210–217, 2020
Matthew A Reyna, Christopher S Josef, Russell Jeter, Supreeth P Shashikumar, M Brandon Westover, Shamim Nemati, Gari D Clifford, and Ashish Sharma. Early prediction of sepsis from clinical data: the physionet/computing in cardiology challenge 2019.Critical care medicine, 48 (2):210–217, 2020
2019
-
[23]
Invariant models for causal transfer learning.Journal of Machine Learning Research, 19(36):1–34, 2018
Mateo Rojas-Carulla, Bernhard Schölkopf, Richard Turner, and Jonas Peters. Invariant models for causal transfer learning.Journal of Machine Learning Research, 19(36):1–34, 2018
2018
-
[24]
Distributionally robust neural networks
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks. InInternational Conference on Learning Representations, 2019
2019
-
[25]
Xinwei Shen, Peter Bühlmann, and Armeen Taeb. Causality-oriented robustness: exploiting general additive interventions.arXiv preprint arXiv:2307.10299, 2023
-
[26]
Gradient matching for domain generalization.arXiv preprint arXiv:2104.09937, 2021
Yuge Shi, Jeffrey Seely, Philip HS Torr, Narayanaswamy Siddharth, Awni Hannun, Nicolas Usunier, and Gabriel Synnaeve. Gradient matching for domain generalization.arXiv preprint arXiv:2104.09937, 2021
-
[27]
Robust Representation Learning through Explicit Environment Modeling
Yuli Slavutsky and David Blei. Robust representation learning through explicit environment modeling.https://arxiv.org/abs/2604.26128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Learning structured output representation using deep conditional generative models.Advances in Neural Information Processing Systems, 28, 2015
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[29]
Vae with a vampprior
Jakub Tomczak and Max Welling. Vae with a vampprior. InInternational conference on artificial intelligence and statistics, pages 1214–1223. PMLR, 2018
2018
-
[30]
On calibration and out-of-domain generalization.Advances in neural information processing systems, 34:2215–2227, 2021
Yoav Wald, Amir Feder, Daniel Greenfeld, and Uri Shalit. On calibration and out-of-domain generalization.Advances in neural information processing systems, 34:2215–2227, 2021
2021
-
[31]
Distributionally robust post-hoc classifiers under prior shifts
Jiaheng Wei, Harikrishna Narasimhan, Ehsan Amid, Wen-Sheng Chu, Yang Liu, and Ab- hishek Kumar. Distributionally robust post-hoc classifiers under prior shifts. InInternational Conference on Learning Representations, 2023
2023
-
[32]
Multi-domain empirical bayes for linearly- mixed causal representations.arXiv e-prints, pages arXiv–2603, 2026
Bohan Wu, Julius von Kügelgen, and David M Blei. Multi-domain empirical bayes for linearly- mixed causal representations.arXiv e-prints, pages arXiv–2603, 2026. 13 A Formal Analysis of the Motivating Example Here we provide the formal statements for the motivating example in Section 3. Recall the setting in Section 3: e∼p(e) , where πe ∈[0,1] are environm...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.