Mamba-Assisted Non-Markovian Closure for Reduced-Order Modeling
Pith reviewed 2026-06-28 07:14 UTC · model grok-4.3
The pith
Mamba sequence models learn non-Markovian closure terms to stabilize reduced-order simulations of chaotic systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
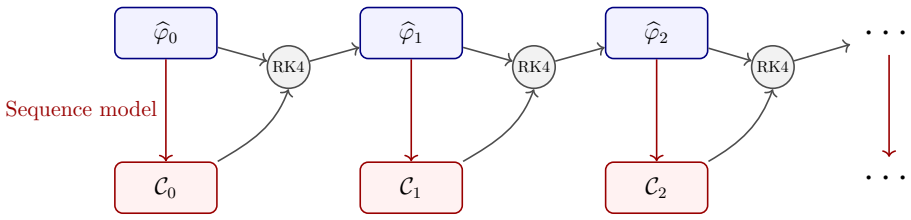
The Mamba-Assisted Closure framework trains a Mamba model on resolved trajectories to predict the non-Markovian closure term, then couples those predictions into the reduced-order equations via numerical integration; the convolutional form enables efficient long-trajectory training while the recurrent form supports stable autoregressive rollout.
What carries the argument
Mamba state-space model that maps resolved trajectories to the closure term, using its convolutional representation for training and recurrent representation for inference.
If this is right
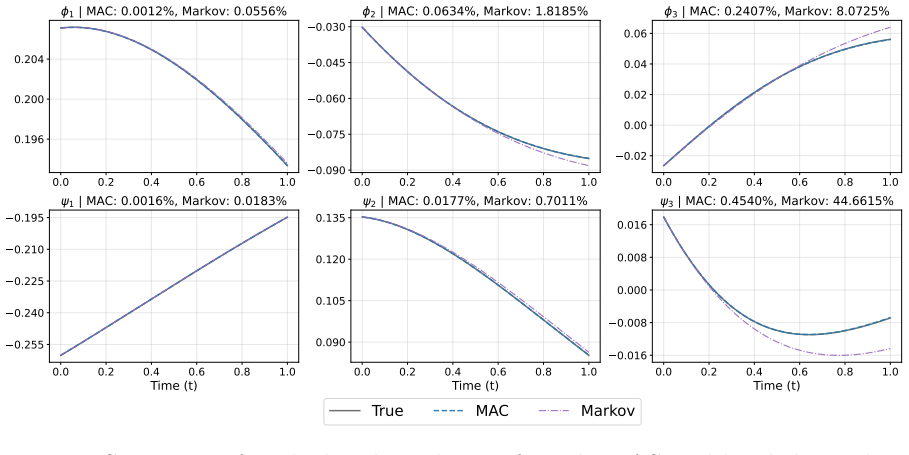
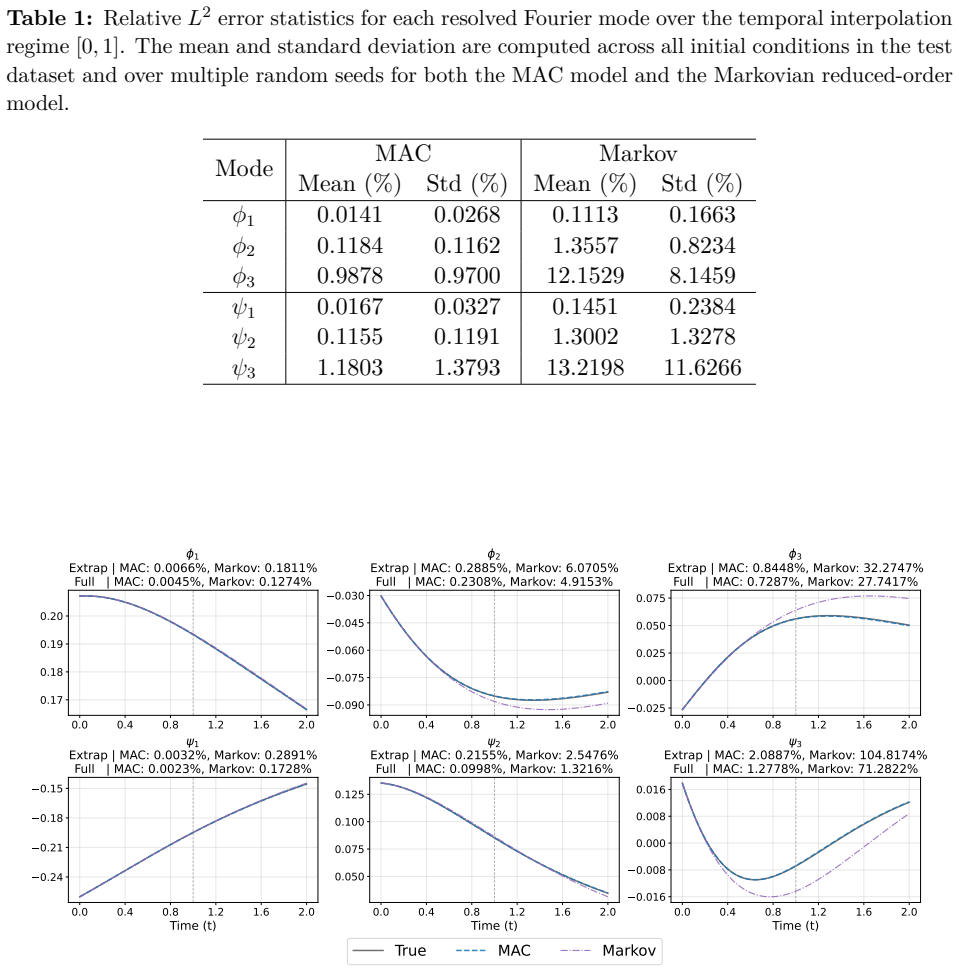
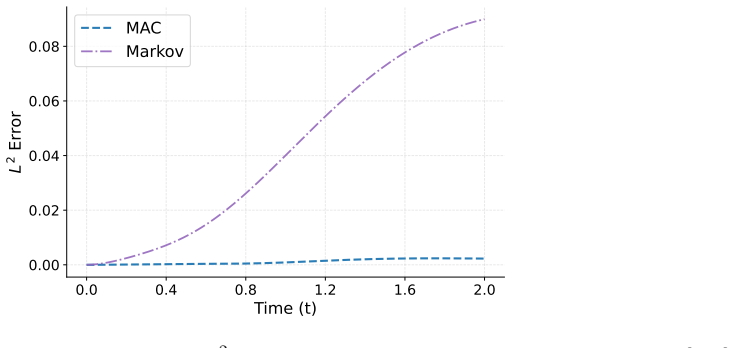
- Higher predictive accuracy than Markovian reduced-order models on both Burgers and Lorenz 96 test cases.
- Longer stable rollouts than GRU-based sequence models and the Wilks method.
- Constant per-step cost during deployment because of the recurrent inference mode.
- Efficient training on extended trajectories via the convolutional training mode.
Where Pith is reading between the lines
- The framework could be applied to other systems with strong memory effects such as turbulent flows or climate models.
- Coarser spatial discretizations might become viable if the learned closure compensates for the missing scales.
- Hybrid models combining Mamba closures with existing physics-based reduced equations could be tested on real observational data.
Load-bearing premise
A Mamba model trained on resolved trajectories can accurately predict the non-Markovian closure term when its outputs are fed into the numerical integration of the reduced equations.
What would settle it
Integrate the MAC closure into the two-scale Lorenz 96 reduced equations and check whether the long-time error or statistical divergence exceeds that of the GRU baseline after the reported stable horizons.
Figures
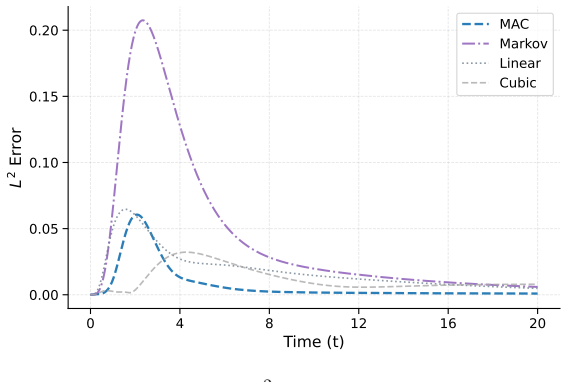
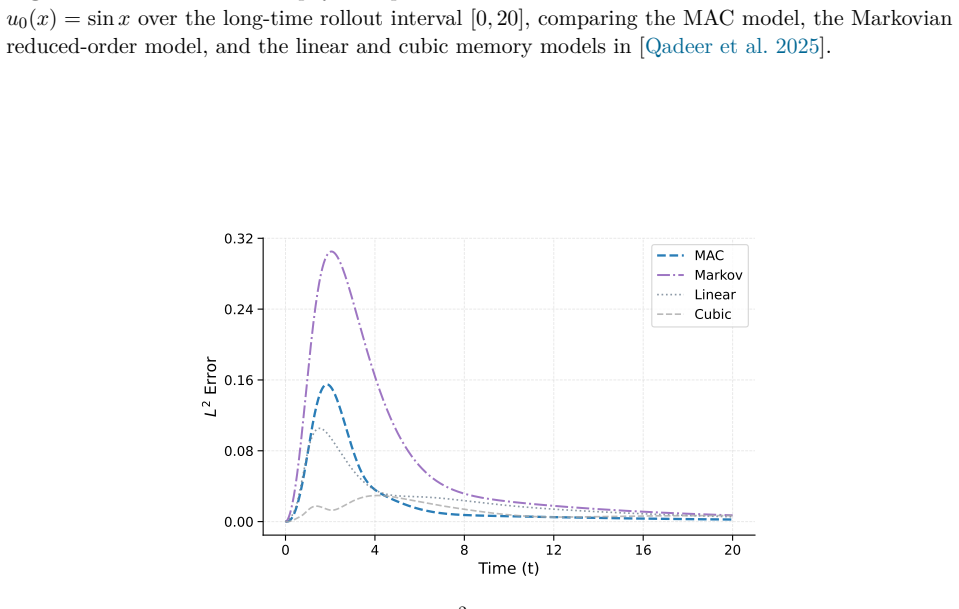
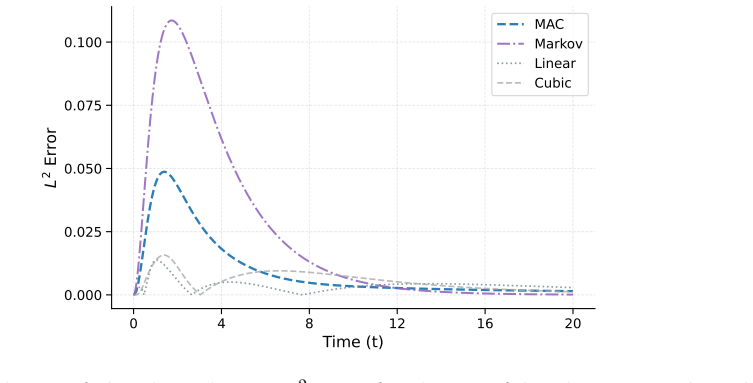
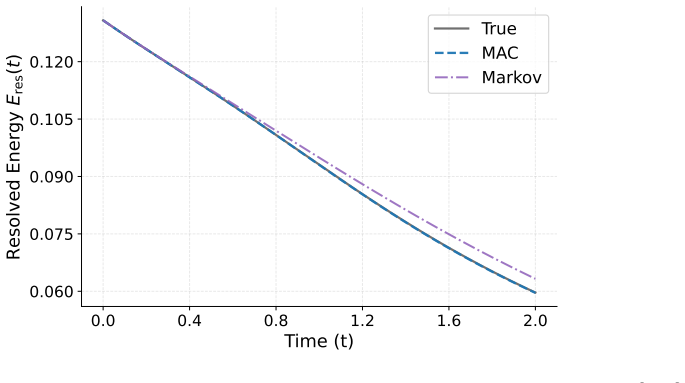
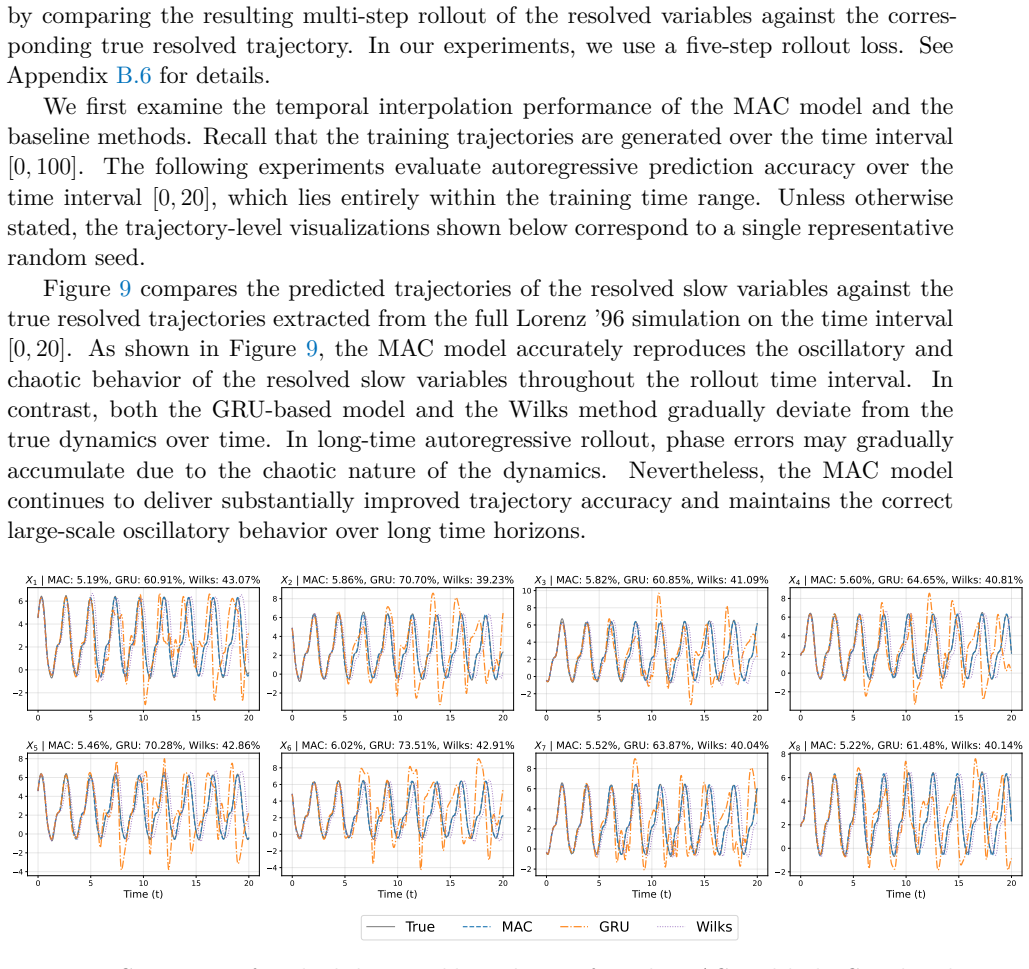
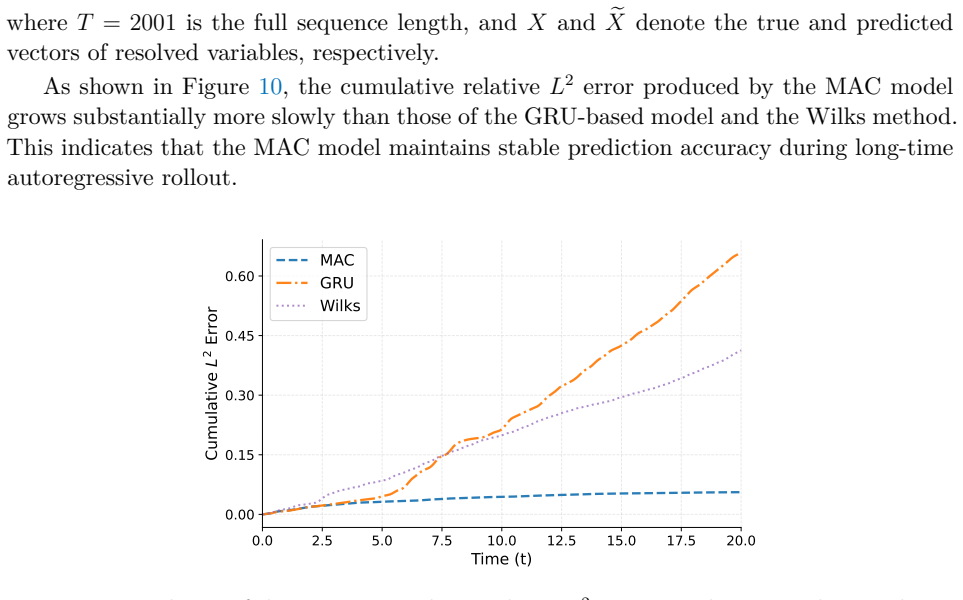
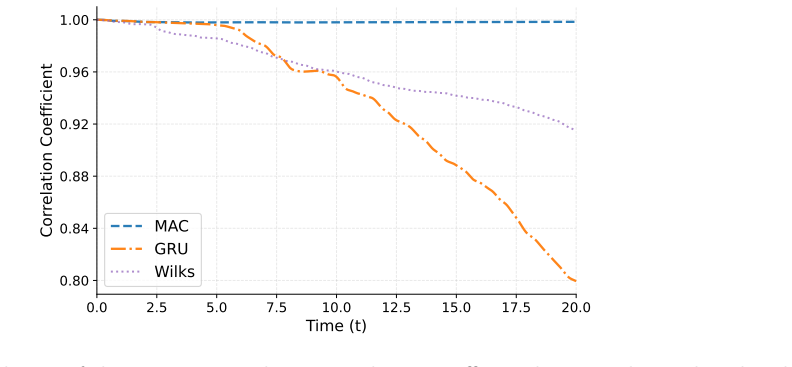
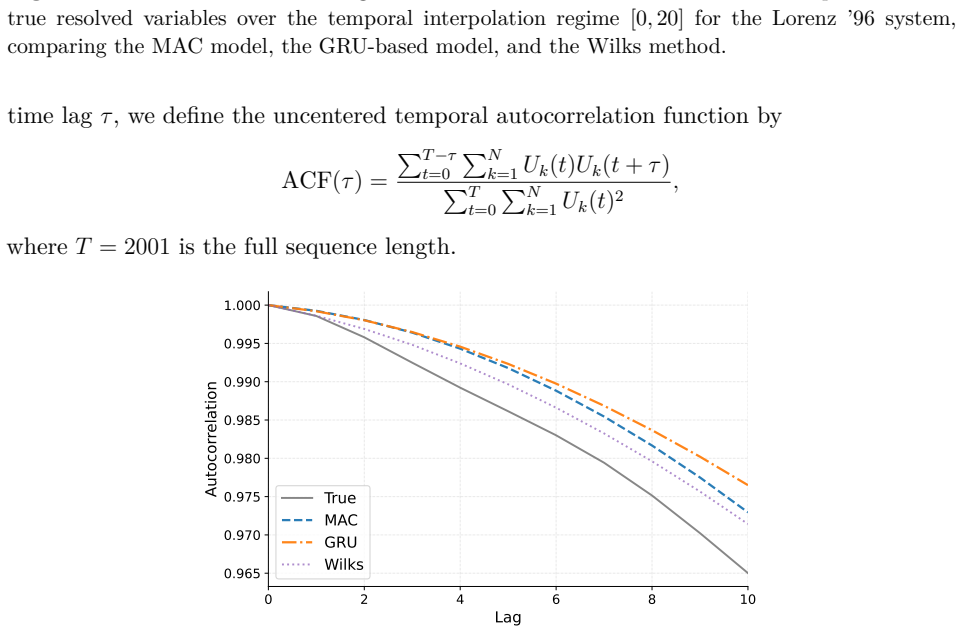
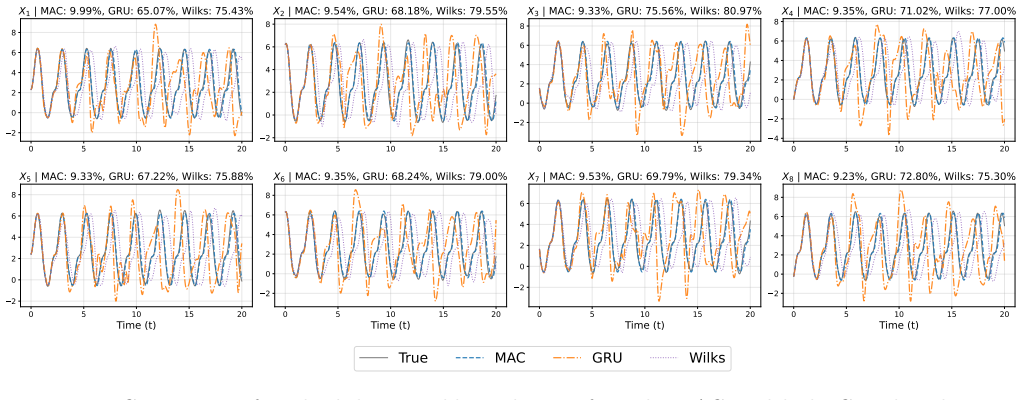
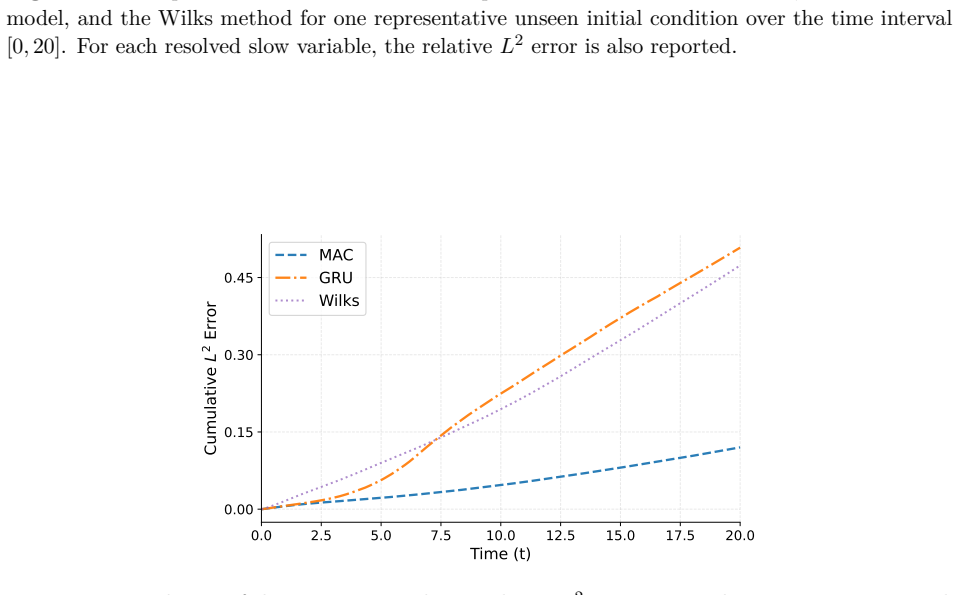
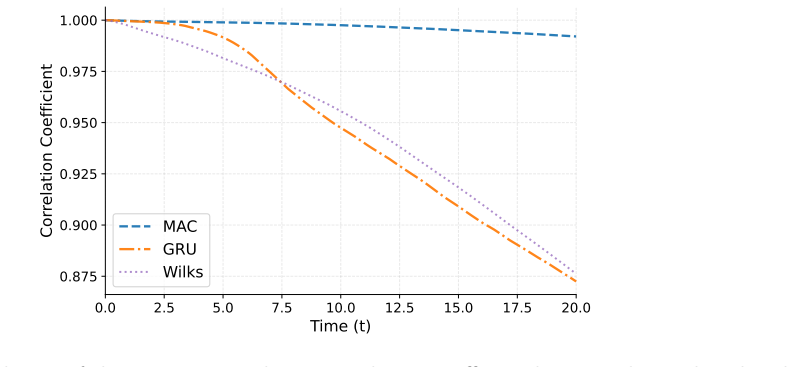
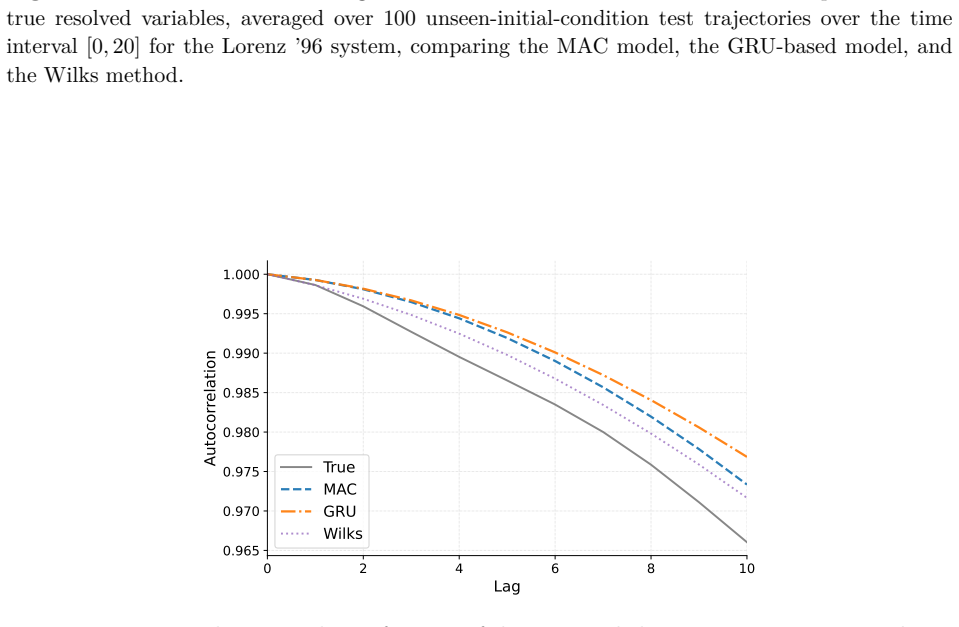
read the original abstract
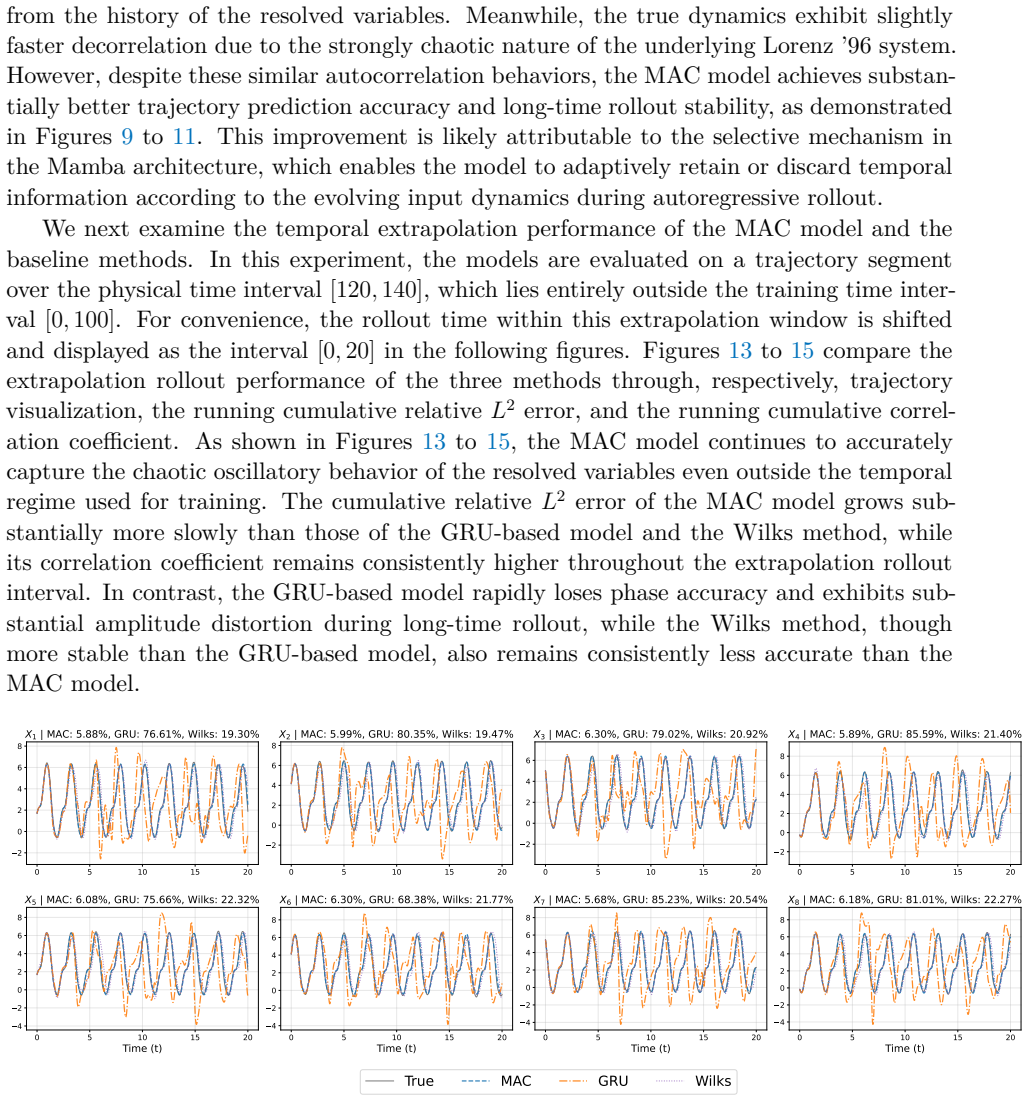
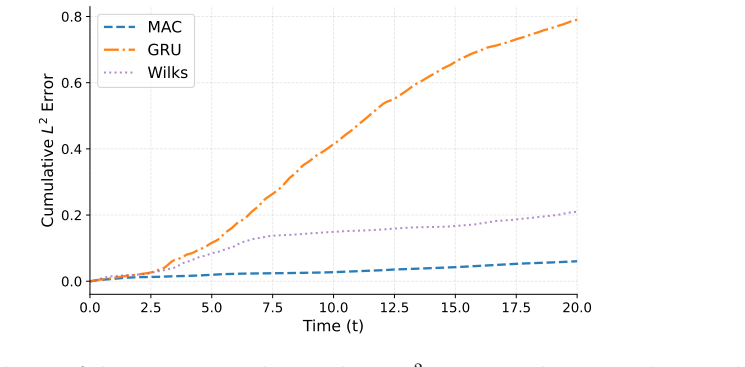
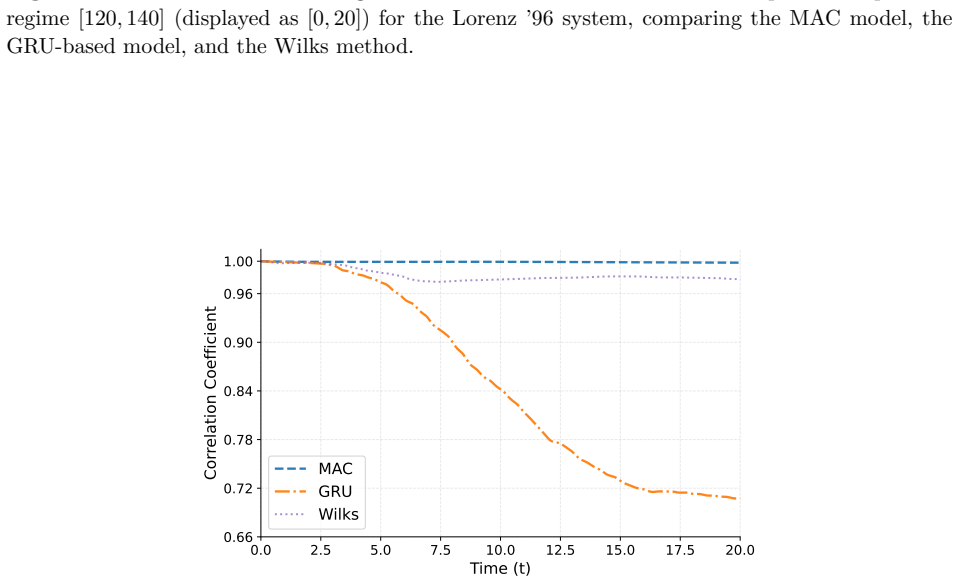
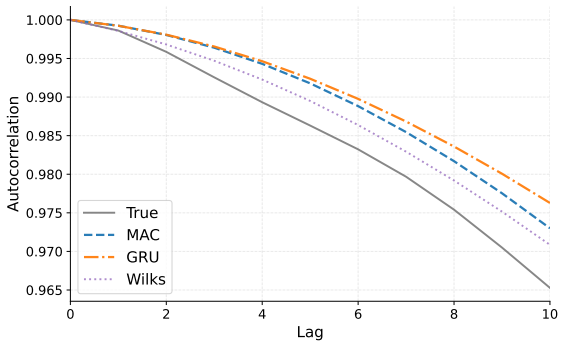
Reduced-order modeling of high-dimensional dynamical systems is often hindered by the non-Markovian closure term that represents the effect of unresolved variables on the resolved dynamics. Inspired by the Mori--Zwanzig formalism, in which the closure takes the form of a memory functional of the resolved trajectory, we recast closure modeling as a sequence modeling problem and propose the Mamba-Assisted Closure (MAC) framework: a Mamba-based sequence model, trained to predict the closure from the resolved trajectory, is coupled with the reduced-order governing equations through a numerical integrator to advance the resolved variables in time. A key feature of the framework is its exploitation of the dual representation of state-space models -- the model is trained in a sequence-to-sequence fashion via the convolutional form, and deployed for step-by-step autoregressive rollout via the recurrent form, yielding both efficient long-trajectory training and constant per-step inference cost. On the viscous Burgers' equation and the chaotic two-scale Lorenz '96 system, the MAC model substantially outperforms the Markovian reduced-order model, the GRU-based sequence model, and the Wilks method in predictive accuracy and long-time rollout stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Mamba-Assisted Closure (MAC) framework, which recasts the non-Markovian closure term from the Mori-Zwanzig formalism as a sequence modeling task. A Mamba state-space model is trained in sequence-to-sequence (convolutional) mode on resolved trajectories and corresponding closure terms extracted from full-order simulations, then deployed autoregressively (recurrent form) inside a numerical integrator to advance the reduced-order equations. The central empirical claim is that MAC substantially outperforms a Markovian ROM, a GRU-based sequence model, and the Wilks method in predictive accuracy and long-time stability on the viscous Burgers equation and the chaotic two-scale Lorenz '96 system.
Significance. If the performance claims survive rigorous controls for distribution shift and hyperparameter variation, the work would demonstrate a practical way to exploit Mamba's dual convolutional/recurrent representation for efficient, stable non-Markovian closure modeling, addressing a long-standing challenge in reduced-order modeling of high-dimensional chaotic systems.
major comments (2)
- [§3.2 and §4] §4 (deployment) and §3.2 (training): the framework trains the Mamba model exclusively on clean full-order trajectories, yet deploys it inside an error-accumulating ROM integration; no analysis or experiments quantify the resulting distribution shift, which directly threatens the claimed long-time rollout stability advantage on the chaotic Lorenz '96 system.
- [Results section] Results section (implicitly Tables/Figures reporting Burgers and Lorenz '96 rollouts): the abstract and reader's summary assert outperformance without reported error bars, ablation studies on sequence length or Mamba hyperparameters, or cross-validation across data splits, leaving the quantitative strength of the central claim unverifiable.
minor comments (2)
- [§2] Notation for the memory kernel and closure term is introduced without an explicit equation reference tying it back to the Mori-Zwanzig projection; a single clarifying equation would improve readability.
- [§3] The description of the dual convolutional/recurrent deployment is clear in principle but would benefit from a small schematic or pseudocode block showing the exact interface between the Mamba output and the numerical integrator.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of the Mamba-Assisted Closure framework. We address each major comment below and commit to revisions that improve rigor without altering the core claims.
read point-by-point responses
-
Referee: [§3.2 and §4] §4 (deployment) and §3.2 (training): the framework trains the Mamba model exclusively on clean full-order trajectories, yet deploys it inside an error-accumulating ROM integration; no analysis or experiments quantify the resulting distribution shift, which directly threatens the claimed long-time rollout stability advantage on the chaotic Lorenz '96 system.
Authors: We agree this is a substantive point. The manuscript reports empirical long-time stability on Lorenz '96 but does not explicitly quantify the train-deployment distribution shift. In revision we will add a dedicated analysis (new subsection in §4) that compares input statistics (means, variances, autocorrelation) between training trajectories and those encountered during ROM rollout, together with a controlled experiment injecting small perturbations to the resolved state to measure sensitivity. This directly addresses the concern while preserving the existing results. revision: yes
-
Referee: [Results section] Results section (implicitly Tables/Figures reporting Burgers and Lorenz '96 rollouts): the abstract and reader's summary assert outperformance without reported error bars, ablation studies on sequence length or Mamba hyperparameters, or cross-validation across data splits, leaving the quantitative strength of the central claim unverifiable.
Authors: We accept that the current results section lacks these elements. In the revised manuscript we will (i) report means and standard deviations over at least five independent training runs with different random seeds, (ii) include ablations on sequence length and Mamba state dimension, and (iii) add results across two distinct data splits (temporal and initial-condition based). These additions will appear as new tables/figures in the Results section and will be summarized in the abstract. revision: yes
Circularity Check
No significant circularity; empirical framework is self-contained
full rationale
The paper recasts closure modeling as a sequence-to-sequence task and trains a Mamba model on resolved trajectories extracted from full-order simulations, then couples the trained model into the reduced-order equations for rollout. This is a standard data-driven modeling pipeline with no load-bearing derivation that reduces to its own inputs by construction. The dual convolutional/recurrent deployment is a known property of state-space models and does not create self-definition or fitted-input-as-prediction circularity. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are invoked as the central justification. Claims rest on comparative numerical experiments rather than algebraic equivalence to the training procedure.
Axiom & Free-Parameter Ledger
free parameters (1)
- Mamba model weights
axioms (1)
- domain assumption The effect of unresolved variables on resolved dynamics can be expressed as a memory functional of the resolved trajectory (Mori-Zwanzig).
Reference graph
Works this paper leans on
-
[1]
On closures for reduced order models ia spectrum of first-principle to machine- learned avenues
Ahmed, Shady E., Suraj Pawar, Omer San, Adil Rasheed, Traian Iliescu and Bernd R. Noack 2021 “On closures for reduced order models ia spectrum of first-principle to machine- learned avenues”, Physics of Fluids , vol. 33, issue 9, article 091301, doi : 10.1063/5.0061577
-
[2]
Benettin, Giancarlo, Luigi Galgani, Antonio Giorgilli and Jean-Marie Strelcyn 1980 “Lyapunov characteristic exponents for smooth dynamical systems and for hamiltonian systems; a method for computing all of them. part 1: theory”, Meccanica, vol. 15, issue 1, pp. 9–20, doi : 10.1007/BF02128236
-
[3]
Learning long-term dependencies with gradient descent is difficult
Bengio, Yoshua, Patrice Simard and Paolo Frasconi 1994 “Learning long-term dependencies with gradient descent is difficult”, IEEE Transactions on Neural Networks , vol. 5, issue 2, pp. 157–166, doi : 10.1109/72.279181
-
[4]
Memory-based parameterization with differentiable solver: application to Lorenz ’96
Bhouri, Mohamed Aziz and Pierre Gentine 2023 “Memory-based parameterization with differentiable solver: application to Lorenz ’96”, Chaos: An Interdisciplinary Journal of Nonlinear Science , vol. 33, issue 7, article 073116, doi : 10.1063/5.0131929
-
[5]
Learning phrase representations using RNN encoder ⚶decoder for statistical machine translation
Cho, Kyunghyun, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bou- gares, Holger Schwenk and Yoshua Bengio 2014 “Learning phrase representations using RNN encoder ⚶decoder for statistical machine translation”, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , Association for Compu- tationa...
-
[6]
Optimal prediction and the Mori ⚶Zwanzig representation of irreversible pro- cesses
Chorin, Alexandre J., Ole H. Hald and Raz Kupferman 2000 “Optimal prediction and the Mori ⚶Zwanzig representation of irreversible pro- cesses”, Proceedings of the National Academy of Sciences , vol. 97, issue 7, pp. 2968–2973, doi : 10.1073/pnas.97.7.2968
-
[7]
Christensen, Hannah and Laure Zanna 2022 “Parametrization in weather and climate models”, in, Oxford research encyc- lopedia of climate science , ed. by Hans von Storch, Oxford University Press, doi : 10.1093/acrefore/9780190228620.013.826. Page 53 of 57
-
[8]
Demaeyer, Jonathan and Stéphane Vannitsem 2017 “Stochastic parameterization of subgrid-scale processes: a review of recent physically based approaches”, in, Advances in nonlinear geosciences , ed. by Anastasios A. Tsonis, Springer International Publishing, Cham, pp. 55–85, doi : 10.1007/978-3-319-58895-7_3
-
[9]
Some recent developments in turbulence closure modeling
Durbin, Paul A. 2018 “Some recent developments in turbulence closure modeling”, Annual Review of Fluid Mechanics , vol. 50, issue 1, pp. 77–103, doi : 10.1146/annurev-fluid-122316-045020
-
[10]
A computational strategy for multiscale systems with applications to Lorenz 96 model
Fatkullin, Ibrahim and Eric Vanden-Eijnden 2004 “A computational strategy for multiscale systems with applications to Lorenz 96 model”, Journal of Computational Physics , vol. 200, issue 2, pp. 605–638, doi : 10.1016/j.jcp.2004.04.013
-
[11]
Frezat, Hugo, Ronan Fablet, Guillaume Balarac and Julien Le Sommer 2023 Gradient-free online learning of subgrid-scale dynamics with neural emulators, arxiv : 2310.19385
arXiv 2023
-
[12]
Gu, Albert and Tri Dao 2023 Mamba: linear-time sequence modeling with selective state spaces, arxiv : 2312.00752
Pith/arXiv arXiv 2023
-
[13]
Gu, Albert, Karan Goel and Christopher Ré 2021 Efficiently modeling long sequences with structured state spaces, arxiv : 2111.00396
Pith/arXiv arXiv 2021
-
[14]
Combining recurrent, convolutional, and continuous-time models with linear state-space layers
Gu, Albert, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra and Christopher Ré 2021 “Combining recurrent, convolutional, and continuous-time models with linear state-space layers”, in Proceedings of the 35th International Conference on Neural Information Processing Systems , Curran Associates Inc., pp. 572–585, url : https://dl.acm.org/doi/10.5...
-
[15]
Neural closure models for dynamical systems
Gupta, Abhinav and Pierre F. J. Lermusiaux 2021 “Neural closure models for dynamical systems”, Proceedings of the Royal Soci- ety A: Mathematical, Physical and Engineering Sciences , vol. 477, issue 2252, article 20201004, doi : 10.1098/rspa.2020.1004. Page 54 of 57
-
[16]
Deepomamba: state-space model for spatio-temporal PDE neural operator learning
Hu, Zheyuan, Qianying Cao, Kenji Kawaguchi and George Em Karniadakis 2025 “Deepomamba: state-space model for spatio-temporal PDE neural operator learning”, Journal of Computational Physics , vol. 540, article 114272, doi : https://doi.org/10.1016/j.jcp.2025.114272
-
[17]
State-space models are accurate and efficient neural operators for dynamical systems
Hu, Zheyuan, Nazanin Ahmadi Daryakenari, Qianli Shen, Kenji Kawaguchi and George Em Karniadakis 2026 “State-space models are accurate and efficient neural operators for dynamical systems”, Neural Networks , vol. 197, article 108496, doi : https://doi.org/10.1016/j.neunet.2025.108496
-
[18]
Machine learning ⚶accelerated computational fluid dynamics
Kochkov, Dmitrii, Jamie A. Smith, Ayya Alieva, Qing Wang, Michael P. Brenner and Stephan Hoyer 2021 “Machine learning ⚶accelerated computational fluid dynamics”, Proceedings of the National Academy of Sciences , vol. 118, issue 21, article e2101784118, doi : 10.1073/pnas.2101784118
-
[19]
Predictability: a problem partly solved
Lorenz, Edward N 1996 “Predictability: a problem partly solved”, in Proc. Seminar on Predictability , Reading, pp. 1–18, url : https : / / www . ecmwf . int / en / elibrary / 75462 - predictability - problem-partly-solved
1996
-
[20]
Model reduction with memory and the machine learning of dynamical sys- tems
Ma, Chao, Jianchun Wang null and Weinan E 2019 “Model reduction with memory and the machine learning of dynamical sys- tems”, Communications in Computational Physics , vol. 25, issue 4, pp. 947– 962, doi : 10.4208/cicp.OA-2018-0269
-
[21]
Time-series learning of latent-space dynamics for reduced-order model clos- ure
Maulik, Romit, Arvind Mohan, Bethany Lusch, Sandeep Madireddy, Prasanna Balaprakash and Daniel Livescu 2020 “Time-series learning of latent-space dynamics for reduced-order model clos- ure”, Physica D: Nonlinear Phenomena , vol. 405, article 132368, doi : https://doi.org/10.1016/j.physd.2020.132368
-
[22]
Transport, collective motion, and Brownian motion
Mori, Hazime 1965 “Transport, collective motion, and Brownian motion”, Progress of Theoretical Physics, vol. 33, issue 3, pp. 423–455, doi : 10.1143/ptp.33.423
-
[23]
Non-markovian closure models for large eddy simulations using the Mori- Zwanzig formalism
Parish, Eric J. and Karthik Duraisamy 2017 “Non-markovian closure models for large eddy simulations using the Mori- Zwanzig formalism”, Physical Review Fluids , vol. 2, issue 1, article 014604, doi : 10.1103/PhysRevFluids.2.014604. Page 55 of 57
-
[24]
On the difficulty of training recurrent neural networks
Pascanu, Razvan, Tomas Mikolov and Yoshua Bengio 2013 “On the difficulty of training recurrent neural networks”, in Proceedings of the 30th International Conference on Machine Learning , JMLR.org, pp. III- 1310–III-1318, url : https://dl.acm.org/doi/10.5555/3042817.3043083
-
[25]
Qadeer, Saad, Panos Stinis and Hui Wan 2025 Stabilizing PDE–ML coupled systems, arxiv : 2506.19274
arXiv 2025
-
[26]
Scientific machine learning for closure models in multiscale problems: a re- view
Sanderse, Benjamin, Panos Stinis, Romit Maulik and Shady E. Ahmed 2025 “Scientific machine learning for closure models in multiscale problems: a re- view”, Foundations of Data Science , vol. 7, issue 1, pp. 298–337, doi : 10.3934/fods.2024043
-
[27]
Coarse-graining methods for computational biology
Saunders, Marissa G. and Gregory A. Voth 2013 “Coarse-graining methods for computational biology”, Annual Review Bio- physics, vol. 42, pp. 73–93, doi : 10.1146/annurev-biophys-083012-130348
-
[28]
Solver-in-the-loop: learning from differentiable physics to interact with it- erative PDE-solvers
Um, Kiwon, Robert Brand, Yun Fei, Philipp Holl and Nils Thuerey 2020 “Solver-in-the-loop: learning from differentiable physics to interact with it- erative PDE-solvers”, in Proceedings of the 34th International Conference on Neural Information Processing Systems , Curran Associates Inc., pp. 6111– 6122, url : https://dl.acm.org/doi/10.5555/3495724.3496237...
-
[29]
Roadmap on multiscale materials modeling
Rottler, Alexander Shluger, Ryan B. Sills, Ingo Steinbach, Alejandro Strachan and Ellad B. Tadmor 2020 “Roadmap on multiscale materials modeling”, Modelling and Simulation in Materials Science and Engineering , vol. 28, issue 4, article 043001, doi : 10.1088/1361-651X/ab7150
-
[30]
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser and Illia Polosukhin 2017 “Attention is all you need”, in Proceedings of the 31st International Confer- ence on Neural Information Processing Systems , NIPS’17, Curran Associates, Inc., pp. 6000–6010, url : https://dl.acm.org/doi/10.5555/3295222.3295349...
-
[31]
Wang, Qian, Nicolò Ripamonti and Jan S. Hesthaven 2020 “Recurrent neural network closure of parametric pod-Galerkin reduced-order models based on the Mori-Zwanzig formalism”, Journal of Computational Physics, vol. 410, article 109402, doi : https://doi.org/10.1016/j.jcp.2020.109402
-
[32]
Effects of stochastic parametrizations in the Lorenz ’96 system
Wilks, Daniel S. 2005 “Effects of stochastic parametrizations in the Lorenz ’96 system”, Quarterly Journal of the Royal Meteorological Society , vol. 131, issue 606, pp. 389–407, doi : 10.1256/qj.04.03
-
[33]
Modelling climate change: the role of unresolved processes
Williams, Paul D 2005 “Modelling climate change: the role of unresolved processes”, Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 363, issue 1837, pp. 2931–2946, doi : 10.1098/rsta.2005.1676
-
[34]
Xue, Tingkai, Chin Chun Ooi, Zhengwei Ge, Fong Yew Leong, Hongying Li and Chang Wei Kang 2025 Differentiable physics-neural models enable learning of non-Markovian clos- ures for accelerated coarse-grained physics simulations, arxiv : 2511.21369
arXiv 2025
-
[35]
On the estimation of the Mori-Zwanzig memory integral
Zhu, Yuanran, Jason M. Dominy and Daniele Venturi 2018 “On the estimation of the Mori-Zwanzig memory integral”, Journal of Math- ematical Physics , vol. 59, issue 10, article 103501, doi : 10.1063/1.5003467
-
[36]
Nonlinear generalized Langevin equations
Zwanzig, Robert 1973 “Nonlinear generalized Langevin equations”, Journal of Statistical Physics , vol. 9, issue 3, pp. 215–220, doi : 10.1007/bf01008729. Page 57 of 57
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.