Mutation Without Variation: Convergence Dynamics in LLM-Driven Program Evolution
Pith reviewed 2026-06-28 05:40 UTC · model grok-4.3
The pith
LLM-driven program mutation converges to restricted structural forms instead of exploring new ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
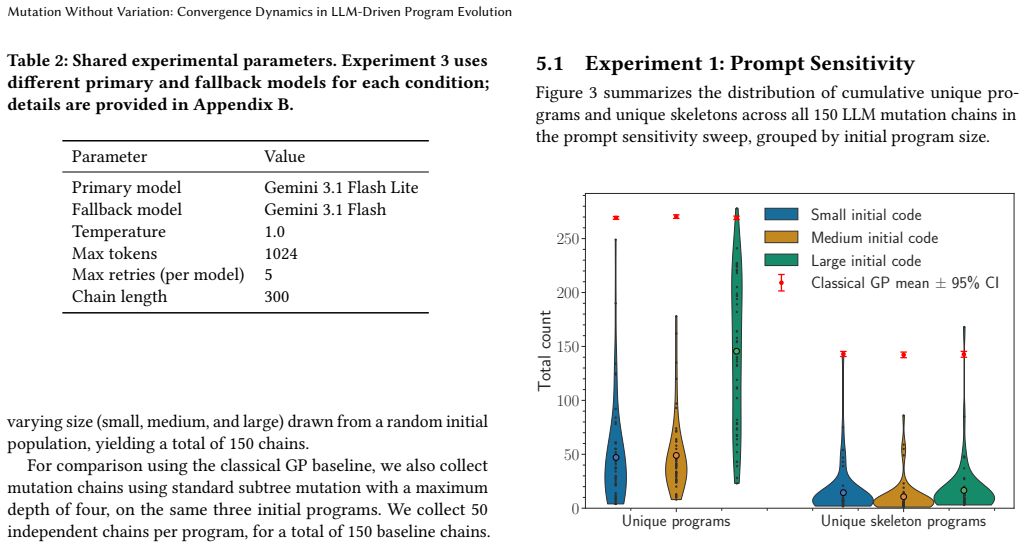
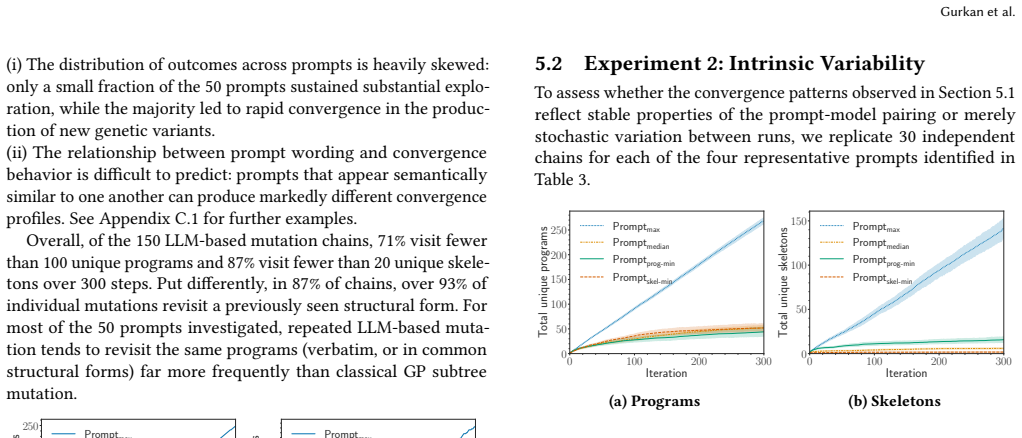
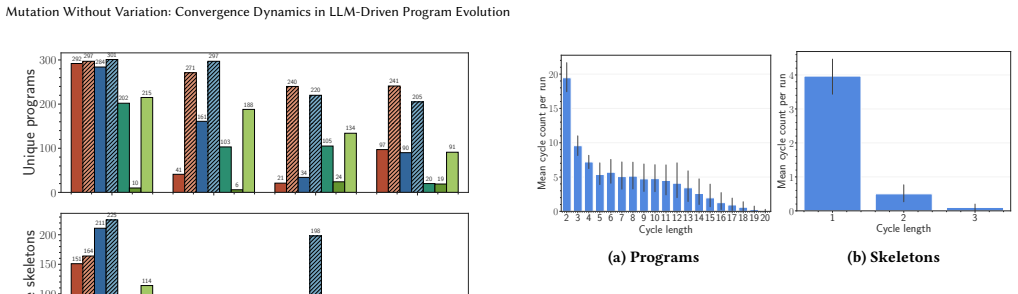
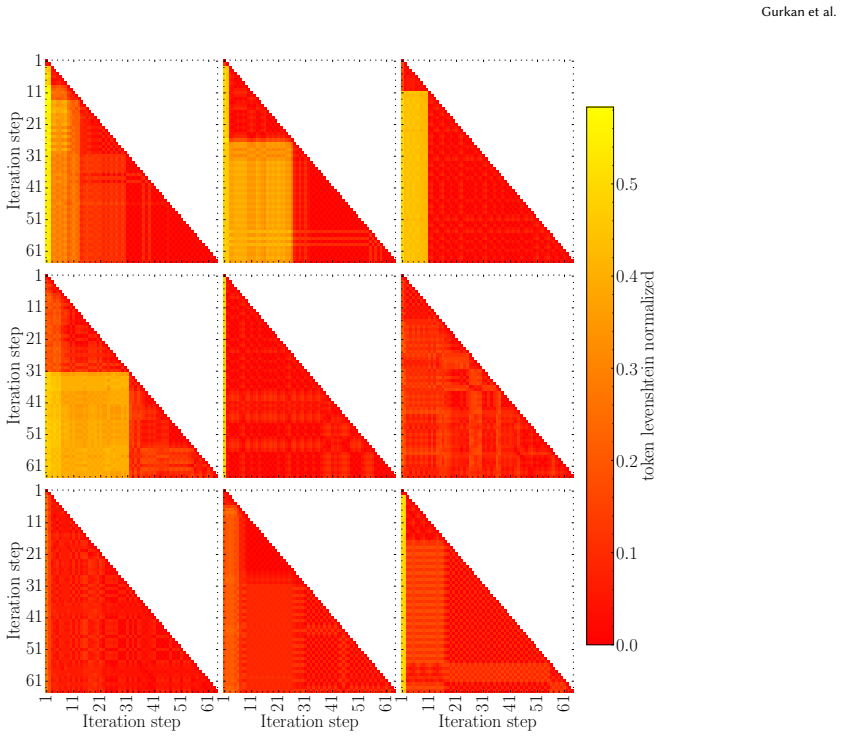
LLM-based mutation consistently converges toward restricted attractor regions in program space. Convergence is especially severe at the structural level: in 87% of chains, over 93% of mutations revisit a previously seen structural form, with most variation confined to terminal substitutions within recurring templates. Cycle analysis reveals short cycles and self-loops dominating the transition structure. The rate of convergence varies with prompt wording and model choice, but the phenomenon is robust across conditions. A classical GP subtree mutation operator does not exhibit comparable convergence, suggesting that the effect is intrinsic to the LLM mutation pipeline.
What carries the argument
LLM mutation chains run without selection pressure in a domain-specific language, tracked for structural repetition and cycle formation.
If this is right
- LLM-only mutation pipelines will tend to produce populations whose structural variety collapses after a modest number of steps.
- Any system that relies on LLM mutation for open-ended program search must add mechanisms that counteract the observed structural locking.
- Prompt engineering and model selection can slow but do not eliminate the convergence effect.
- Hybrid pipelines that mix LLM mutation with classical operators can avoid the homogeneity bias shown for pure LLM mutation.
Where Pith is reading between the lines
- Designers of evolutionary code tools may need explicit diversity-preserving operators that operate at the structural level rather than relying on the LLM alone.
- The same semantic awareness that lets LLMs make targeted edits may also make them sensitive to statistical patterns that favor reuse of common templates.
- Testing the same mutation process on larger or more open-ended program spaces would reveal whether the attractor effect scales or remains tied to the size of the observed DSL.
Load-bearing premise
The specific language, prompt formats, and model choices used in the tests expose a general property of LLM mutation rather than an artifact of those exact settings.
What would settle it
Finding long chains in which most mutations produce previously unseen structural forms when the same models are applied to a different language or with selection pressure present would falsify the convergence claim.
Figures





read the original abstract
When an LLM repeatedly mutates a program, does it explore new forms or circle back to the same ones? We study this question by analyzing LLM-driven mutation chains in the absence of selection pressure within a domain-specific language, varying prompt design, model family, and stochastic replication. We find that LLM-based mutation consistently converges toward restricted attractor regions in program space. Convergence is especially severe at the structural level: in 87% of chains, over 93% of mutations revisit a previously seen structural form, with most variation confined to terminal substitutions within recurring templates. Cycle analysis reveals short cycles and self-loops dominating the transition structure. The rate of convergence varies with prompt wording and model choice, but the phenomenon is robust across conditions. A classical GP subtree mutation operator does not exhibit comparable convergence, suggesting that the effect is intrinsic to the LLM mutation pipeline. These findings reveal a tension at the heart of LLM-driven program evolution: the same capabilities that enable semantics-aware program transformation also carry a systematic bias toward structural homogeneity that must be accounted for if such systems are to sustain open-ended exploration. Source code is available at https://github.com/can-gurkan/lmca.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines LLM-driven program mutation chains in a DSL without selection pressure, varying prompts, models, and replication. It reports that mutations converge to restricted attractor regions, with structural convergence especially pronounced: 87% of chains exhibit over 93% of mutations revisiting previously seen structural forms, mostly via terminal substitutions in recurring templates. Short cycles dominate transitions. The effect varies with prompt and model but is claimed robust, and contrasts with classical GP subtree mutation, implying an intrinsic bias in LLM pipelines that limits open-ended exploration. Source code is provided.
Significance. If the reported convergence holds as an intrinsic property rather than an experimental artifact, the result identifies a systematic limitation in LLM-based program evolution that must be mitigated for sustained diversity. The availability of source code supports reproducibility and allows direct verification of the empirical measurements.
major comments (3)
- [§4, §5] §4 (Experimental Setup) and §5 (Results): the definition and canonicalization procedure for 'structural form' used to compute the 87%/93% figures is not specified. Without this, it is impossible to determine whether the reported structural revisits reflect LLM behavior or the particular representation and equivalence relation chosen for the DSL.
- [§3, §6] §3 (DSL and Program Space) and §6 (Discussion): no quantitative characterization is given of the DSL's structural expressiveness, total number of distinct structural forms, or size of the program space. This information is load-bearing for the claim that convergence is intrinsic to the LLM rather than a consequence of a small or low-diversity space induced by the chosen DSL and mutation prompts.
- [§5.2] §5.2 (Comparison with GP): the classical GP subtree mutation baseline is described only at high level; the precise operator definition, application rate, and whether it operates on the same DSL representation are not detailed enough to support the contrast that the convergence effect is absent in non-LLM mutation.
minor comments (2)
- [Abstract, §1] Abstract and §1: the phrase 'robust across conditions' is used without quantifying the range of prompt variations or model families tested; a table summarizing the exact conditions would improve clarity.
- [§5] Figure captions and §5: axis labels and legends for cycle-length and revisit histograms are not fully described, making it difficult to interpret the exact percentages without consulting the source code.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight areas where additional clarity will strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [§4, §5] §4 (Experimental Setup) and §5 (Results): the definition and canonicalization procedure for 'structural form' used to compute the 87%/93% figures is not specified. Without this, it is impossible to determine whether the reported structural revisits reflect LLM behavior or the particular representation and equivalence relation chosen for the DSL.
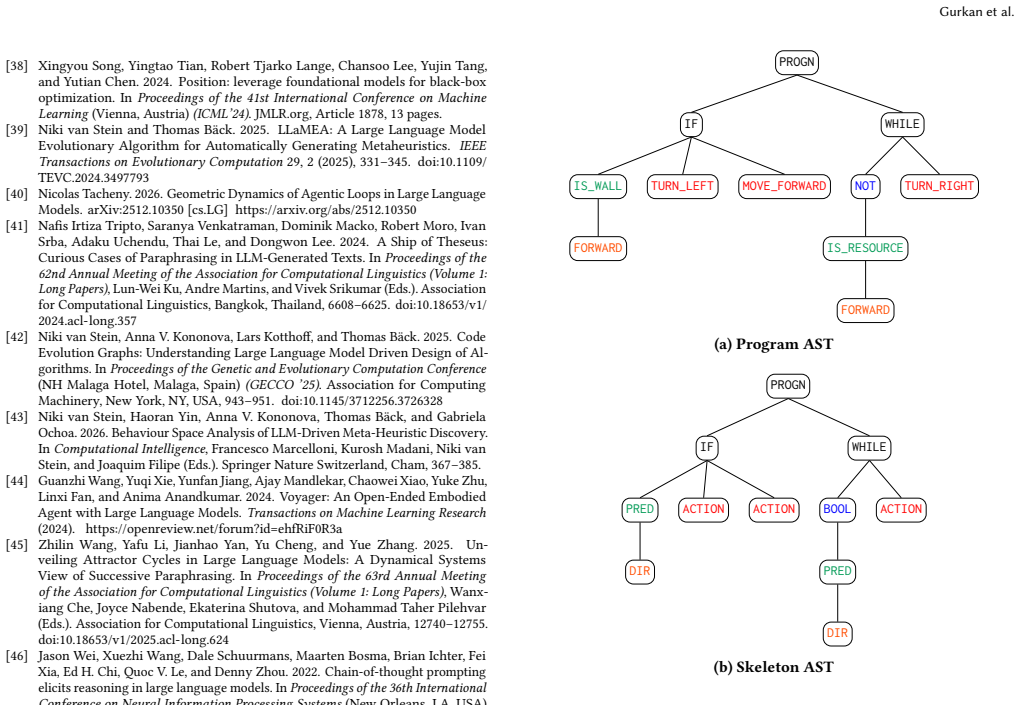
Authors: We agree that the canonicalization procedure must be stated explicitly. In the revised manuscript we will add a dedicated paragraph (and pseudocode) in §4 defining structural form as the AST obtained after removing all terminal leaves and normalizing operator nodes up to the DSL's syntactic equivalence; two programs share a structural form if and only if their normalized operator trees are identical. This definition will be used to recompute and report the 87 % / 93 % statistics. revision: yes
-
Referee: [§3, §6] §3 (DSL and Program Space) and §6 (Discussion): no quantitative characterization is given of the DSL's structural expressiveness, total number of distinct structural forms, or size of the program space. This information is load-bearing for the claim that convergence is intrinsic to the LLM rather than a consequence of a small or low-diversity space induced by the chosen DSL and mutation prompts.
Authors: We will augment §3 with a quantitative characterization: the grammar yields 2,147 distinct structural forms at depth ≤ 6 (enumerated exhaustively via the provided source code) and an estimated total program space exceeding 10^8 distinct expressions when terminals are included. These figures will be cited in the Discussion to support that the observed convergence occurs inside a combinatorially large space. revision: yes
-
Referee: [§5.2] §5.2 (Comparison with GP): the classical GP subtree mutation baseline is described only at high level; the precise operator definition, application rate, and whether it operates on the same DSL representation are not detailed enough to support the contrast that the convergence effect is absent in non-LLM mutation.
Authors: We will expand §5.2 with the exact GP operator definition: at each step a subtree is chosen uniformly at random and replaced by a new subtree sampled from the identical DSL grammar (application probability 0.9, maximum depth 6). The operator is applied to the same concrete representation used by the LLM pipeline, and the same structural-form metric is computed, confirming the absence of comparable convergence. revision: yes
Circularity Check
No circularity; empirical measurements of observed mutation chains
full rationale
The paper reports direct empirical counts (e.g., 87% of chains with >93% structural revisits) from LLM mutation experiments in a DSL, with no equations, fitted parameters, or derivations that reduce any result to its inputs by construction. Convergence statistics are computed from the generated sequences themselves rather than being defined in terms of the measured quantity. No self-citations are invoked as load-bearing support for the central claim, and the GP baseline is an external comparator. The findings are therefore self-contained observational results rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Timothy Atkinson, Detlef Plump, and Susan Stepney. 2018. Evolving Graphs by Graph Programming. InGenetic Programming, Mauro Castelli, Lukas Sekanina, Mengjie Zhang, Stefano Cagnoni, and Pablo García-Sánchez (Eds.). Springer International Publishing, Cham, 35–51
2018
-
[2]
Foster, François Képès, Virginie Lefort, Julian F
Wolfgang Banzhaf, Guillaume Beslon, Steffen Christensen, James A. Foster, François Képès, Virginie Lefort, Julian F. Miller, Miroslav Radman, and Jeremy J. Ramsden. 2006. Guidelines: From artificial evolution to computational evolution: A research agenda.Nature Reviews Genetics7 (2006). Issue 9. doi:10.1038/nrg1921
-
[3]
2024.The OpenELM Library: Leveraging Progress in Language Models for Novel Evolutionary Algorithms
Herbie Bradley, Honglu Fan, Theodoros Galanos, Ryan Zhou, Daniel Scott, and Joel Lehman. 2024.The OpenELM Library: Leveraging Progress in Language Models for Novel Evolutionary Algorithms. Springer Nature Singapore, Singapore, 177–201. doi:10.1007/978-981-99-8413-8_10
-
[4]
Leonardo Lucio Custode, Fabio Caraffini, Anil Yaman, and Giovanni Iacca. 2024. An investigation on the use of Large Language Models for hyperparameter tuning in Evolutionary Algorithms. InProceedings of the Genetic and Evolution- ary Computation Conference Companion(Melbourne, VIC, Australia)(GECCO ’24 Companion). Association for Computing Machinery, New ...
-
[5]
1859.On the Origin of Species by Means of Natural Selection
Charles Darwin. 1859.On the Origin of Species by Means of Natural Selection. Murray, London. or the Preservation of Favored Races in the Struggle for Life
-
[6]
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2024. Promptbreeder: Self-Referential Self- Improvement via Prompt Evolution. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Ad...
2024
-
[7]
Ping Guo, Chao Li, Yinglan Feng, and Chaoning Zhang. 2026. Code Evolu- tion for Control: Synthesizing Policies via LLM-Driven Evolutionary Search. arXiv:2601.06845 [cs.AI] https://arxiv.org/abs/2601.06845
arXiv 2026
-
[8]
Can Gurkan, Narasimha Karthik Jwalapuram, Kevin Wang, Rudy Danda, Leif Rasmussen, John Chen, and Uri Wilensky. 2025. LEAR: LLM-Driven Evolution of Agent-Based Rules. InProceedings of the Genetic and Evolutionary Computation Conference Companion(NH Malaga Hotel, Malaga, Spain)(GECCO ’25 Compan- ion). Association for Computing Machinery, New York, NY, USA, ...
-
[9]
Desta Haileselassie Hagos, Rick Battle, and Danda B. Rawat. 2024. Recent Ad- vances in Generative AI and Large Language Models: Current Status, Challenges, and Perspectives.IEEE Transactions on Artificial Intelligence5, 12 (2024), 5873–
2024
-
[10]
doi:10.1109/TAI.2024.3444742
-
[11]
2025.Survey of Genetic Programming and Large Language Models
Erik Hemberg, Steven Jorgensen, and Una-May O’Reilly. 2025.Survey of Genetic Programming and Large Language Models. Springer Nature Singapore, Singapore, 67–86. doi:10.1007/978-981-96-0077-9_4
-
[12]
Erik Hemberg, Stephen Moskal, and Una-May O’Reilly. 2024. Evolving code with a large language model.Genetic Programming and Evolvable Machines25, 2 (12 Sep 2024), 21. doi:10.1007/s10710-024-09494-2
-
[13]
Arend Hintze, Frida Proschinger Åström, and Jory Schossau. 2026. Autonomous language-image generation loops converge to generic visual motifs.Patterns7, 1 (09 Jan 2026). doi:10.1016/j.patter.2025.101451
-
[14]
Qinglong Hu and Qingfu Zhang. 2025. Partition to Evolve: Niching-enhanced Evolution with LLMs for Automated Algorithm Discovery. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview. net/forum?id=OEawM2coNT
2025
-
[15]
Shengran Hu, Cong Lu, and Jeff Clune. 2025. Automated Design of Agentic Systems. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=t9U3LW7JVX
2025
-
[16]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation. arXiv:2406.00515 [cs.CL] https://arxiv.org/abs/2406.00515
Pith/arXiv arXiv 2024
-
[17]
John R. Koza. 1992.Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, Cambridge, MA, USA. http://mitpress. mit.edu/books/genetic-programming
1992
-
[18]
Akarsh Kumar, Ryan Bahlous-Boldi, Prafull Sharma, Phillip Isola, Sebastian Risi, Yujin Tang, and David Ha. 2026. Digital Red Queen: Adversarial Program Evolution in Core War with LLMs. arXiv:2601.03335 [cs.AI] https://arxiv.org/ abs/2601.03335
arXiv 2026
-
[19]
Robert Lange, Yingtao Tian, and Yujin Tang. 2024. Large Language Models As Evolution Strategies. InProceedings of the Genetic and Evolutionary Computation Conference Companion(Melbourne, VIC, Australia)(GECCO ’24 Companion). Association for Computing Machinery, New York, NY, USA, 579–582. doi:10. 1145/3638530.3654238
arXiv 2024
-
[20]
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. 2026. ShinkaEvolve: Towards Open-Ended and Sample-Efficient Program Evolution. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/ forum?id=lKEdGCoDNC
2026
-
[21]
Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O. Stanley. 2024.Evolution Through Large Models. Springer Nature Singapore, Singapore, 331–366. doi:10.1007/978-981-99-3814-8_11
-
[22]
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. 2024. Evolution of heuristics: towards efficient automatic algorithm design using large language model. InProceedings of the 41st Interna- tional Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1304, 23 pages
2024
-
[23]
Chan, Jakob Foerster, Mihaela van der Schaar, and Robert Tjarko Lange
Chris Lu, Samuel Holt, Claudio Fanconi, Alex J. Chan, Jakob Foerster, Mihaela van der Schaar, and Robert Tjarko Lange. 2024. Discovering Preference Op- timization Algorithms with and for Large Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol....
2024
-
[24]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292 [cs.AI] https://arxiv.org/abs/2408.06292
Pith/arXiv arXiv 2024
-
[25]
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2024. Eureka: Human-Level Reward Design via Coding Large Language Models. InThe Twelfth International Conference on Learning Representations. https://openreview.net/ forum?id=IEduRUO55F
2024
-
[26]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self-Feedback. InThirty-seventh Conference on Neural Inf...
2023
-
[27]
Nelson, Herbie Bradley, Adam Gaier, Arash Moradi, Amy K
Elliot Meyerson, Mark J. Nelson, Herbie Bradley, Adam Gaier, Arash Moradi, Amy K. Hoover, and Joel Lehman. 2024. Language Model Crossover: Variation through Few-Shot Prompting.ACM Trans. Evol. Learn. Optim.4, 4, Article 27 (Nov. 2024), 40 pages. doi:10.1145/3694791
-
[28]
Amr Mohamed, Mingmeng Geng, Michalis Vazirgiannis, and Guokan Shang
-
[29]
LLM as a Broken Telephone: Iterative Generation Distorts Information. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 7493–7509. doi:10.18653/v1/2...
-
[30]
Sabbir Mollah, Rohit Gupta, Sirnam Swetha, Qingyang Liu, Ahnaf Munir, and Mubarak Shah. 2025. The Telephone Game: Evaluating Semantic Drift in Unified Models. arXiv:2509.04438 [cs.CV] https://arxiv.org/abs/2509.04438
arXiv 2025
-
[31]
Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. 2025. AlphaEvolve: A coding agent for scientific and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13131 2025
-
[32]
U.-M. O’Reilly. 1997. Using a distance metric on genetic programs to understand genetic operators. In1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Vol. 5. 4092–4097 vol.5. doi:10.1109/ICSMC.1997.637337
-
[33]
Norman Peitek, Julia Hess, and Sven Apel. 2026. From Restructuring to Stabi- lization: A Large-Scale Experiment on Iterative Code Readability Refactoring with Large Language Models. arXiv:2602.21833 [cs.SE] https://arxiv.org/abs/ 2602.21833
arXiv 2026
-
[34]
Jeremy Perez, Corentin Leger, Marcela Ovando-Tellez, Chris Foulon, Joan Dus- sauld, Pierre-Yves Oudeyer, and Clement Moulin-Frier. 2024. Cultural evo- lution in populations of Large Language Models. arXiv:2403.08882 [cs.MA] https://arxiv.org/abs/2403.08882
arXiv 2024
-
[35]
Langdon, and Nicholas Freitag McPhee
Riccardo Poli, William B. Langdon, and Nicholas Freitag McPhee. 2008.A Field Guide to Genetic Programming. Lulu Press. http://www.gp-field-guide.org.uk With contributions by John R. Koza
2008
-
[36]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi
-
[37]
doi: 10.1038/s41586-023-06924-6
Mathematical discoveries from program search with large language models. Nature625, 7995 (01 Jan 2024), 468–475. doi:10.1038/s41586-023-06924-6
-
[38]
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2024. Can AI-Generated Text be Reliably Detected? https://openreview.net/forum?id=NvSwR4IvLO
2024
-
[39]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. 2024. The Curse of Recursion: Training on Generated Data Makes Models Forget. arXiv:2305.17493 [cs.LG] https://arxiv.org/abs/2305.17493
Pith/arXiv arXiv 2024
-
[40]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. AI models collapse when trained on recursively generated data.Nature631, 8022 (01 Jul 2024), 755–759. doi:10.1038/s41586-024-07566-y Gurkan et al
-
[41]
Xingyou Song, Yingtao Tian, Robert Tjarko Lange, Chansoo Lee, Yujin Tang, and Yutian Chen. 2024. Position: leverage foundational models for black-box optimization. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1878, 13 pages
2024
-
[42]
Niki van Stein and Thomas Bäck. 2025. LLaMEA: A Large Language Model Evolutionary Algorithm for Automatically Generating Metaheuristics.IEEE Transactions on Evolutionary Computation29, 2 (2025), 331–345. doi:10.1109/ TEVC.2024.3497793
arXiv 2025
-
[43]
Nicolas Tacheny. 2026. Geometric Dynamics of Agentic Loops in Large Language Models. arXiv:2512.10350 [cs.LG] https://arxiv.org/abs/2512.10350
arXiv 2026
-
[44]
Nafis Irtiza Tripto, Saranya Venkatraman, Dominik Macko, Robert Moro, Ivan Srba, Adaku Uchendu, Thai Le, and Dongwon Lee. 2024. A Ship of Theseus: Curious Cases of Paraphrasing in LLM-Generated Texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srik...
-
[45]
Kononova, Lars Kotthoff, and Thomas Bäck
Niki van Stein, Anna V. Kononova, Lars Kotthoff, and Thomas Bäck. 2025. Code Evolution Graphs: Understanding Large Language Model Driven Design of Al- gorithms. InProceedings of the Genetic and Evolutionary Computation Conference (NH Malaga Hotel, Malaga, Spain)(GECCO ’25). Association for Computing Machinery, New York, NY, USA, 943–951. doi:10.1145/37122...
-
[46]
Kononova, Thomas Bäck, and Gabriela Ochoa
Niki van Stein, Haoran Yin, Anna V. Kononova, Thomas Bäck, and Gabriela Ochoa. 2026. Behaviour Space Analysis of LLM-Driven Meta-Heuristic Discovery. InComputational Intelligence, Francesco Marcelloni, Kurosh Madani, Niki van Stein, and Joaquim Filipe (Eds.). Springer Nature Switzerland, Cham, 367–385
2026
-
[47]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2024. Voyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Research (2024). https://openreview.net/forum?id=ehfRiF0R3a
2024
-
[48]
Zhilin Wang, Yafu Li, Jianhao Yan, Yu Cheng, and Yue Zhang. 2025. Un- veiling Attractor Cycles in Large Language Models: A Dynamical Systems View of Successive Paraphrasing. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanx- iang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher...
-
[49]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Hook, NY...
2022
-
[50]
Xingyu Wu, Sheng-Hao Wu, Jibin Wu, Liang Feng, and Kay Chen Tan. 2024. Evolutionary Computation in the Era of Large Language Model: Survey and Roadmap.IEEE Transactions on Evolutionary Computation(2024), 1–1. doi:10. 1109/TEVC.2024.3506731
arXiv 2024
-
[51]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[52]
Haoran Ye, Jiarui Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. 2024. ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Assoc...
-
[53]
Tina Yu and Julian F. Miller. 2001. Neutrality and the Evolvability of Boolean Function Landscape. InGenetic Programming, 4th European Conference, EuroGP 2001, Lake Como, Italy, April 18-20, 2001, Proceedings (Lecture Notes in Computer Science), Julian F. Miller, Marco Tomassini, Pier Luca Lanzi, Conor Ryan, Andrea Tettamanzi, and William B. Langdon (Eds....
work page doi:10.1007/3- 2001
-
[54]
Each variation must convey the same fundamental meaning and instruction as the original line
-
[55]
Each variation must use different wording and phrasing from the original and from other variations
-
[56]
Each variation must maintain a clear, instructional tone appropriate for prompting an LLM
-
[57]
Each variation must be suitable for use in genetic programming mutation contexts
-
[58]
mutation,
Each variation should be a complete, standalone instruction that could directly replace the original line **Vocabulary and Terminology:** - Vary the terminology you use across variations. Instead of always using "mutation," consider alternatives such as: - "change" - "variation" - "modification" Gurkan et al. - "improvement" - "alteration" - "transformati...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.