ComplexityMT: Benchmarking the Interaction Between Text Complexity and Machine Translation
Pith reviewed 2026-06-28 05:52 UTC · model grok-4.3
The pith
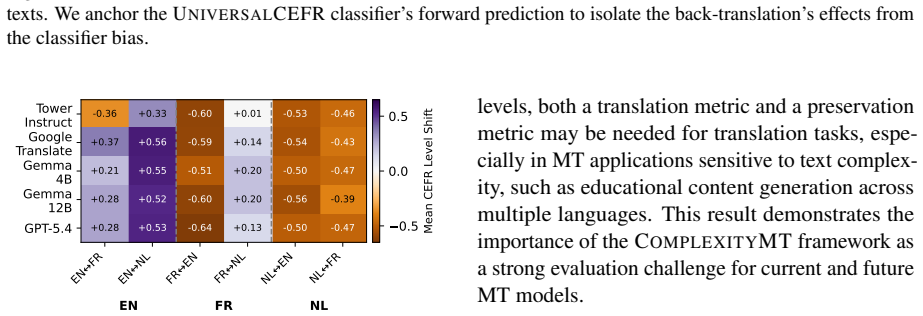
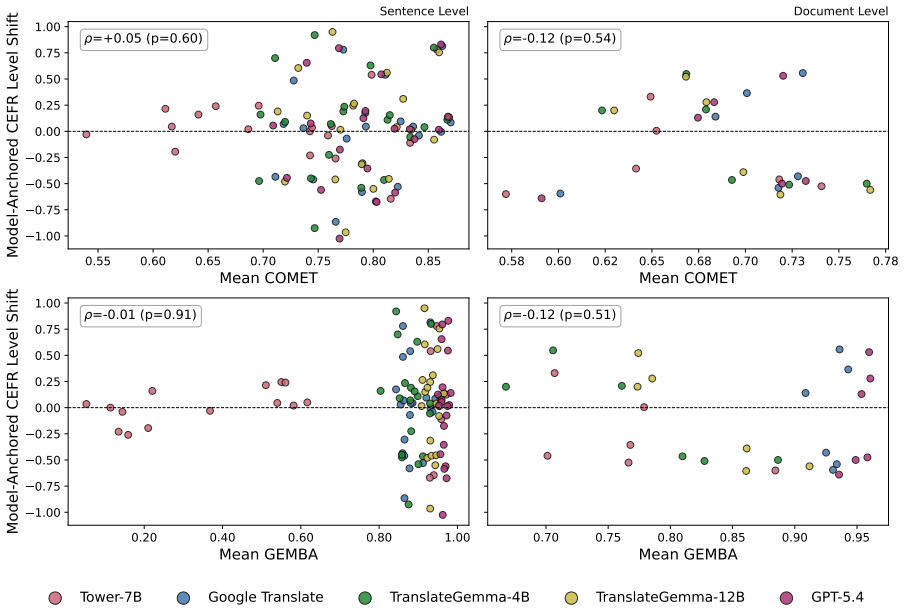
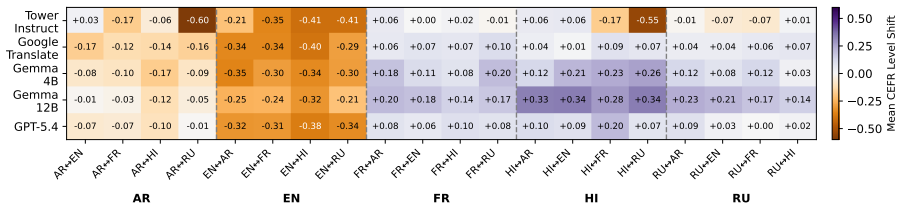
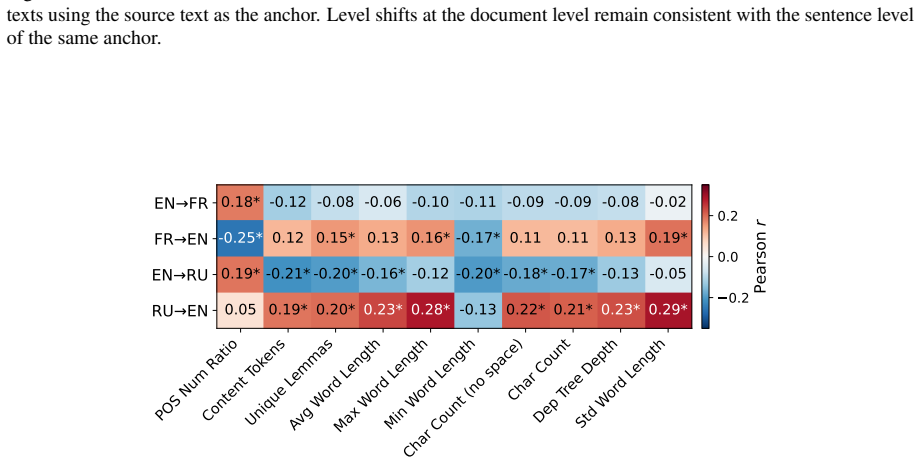
Machine translation shifts the CEFR complexity level of target texts compared to sources for most languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
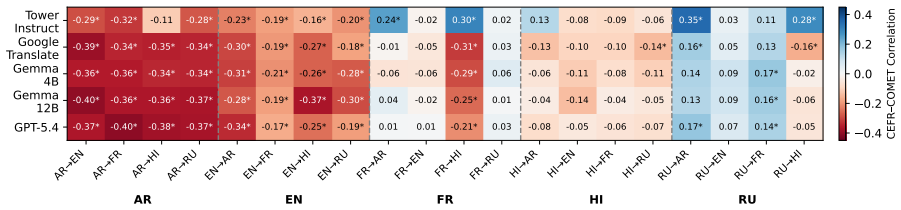
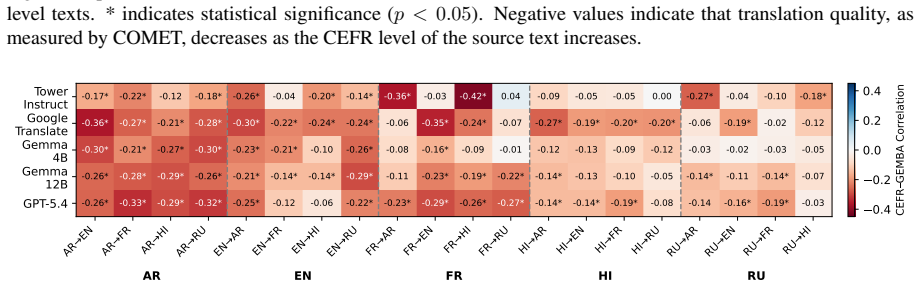
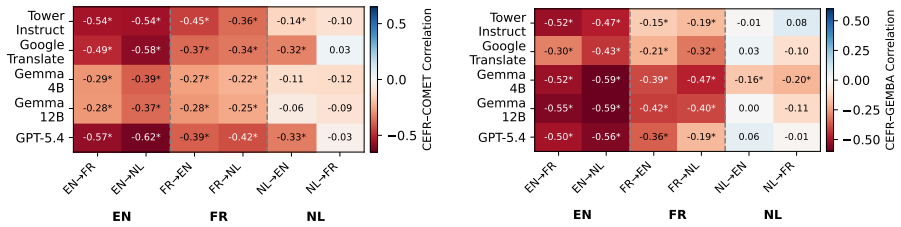
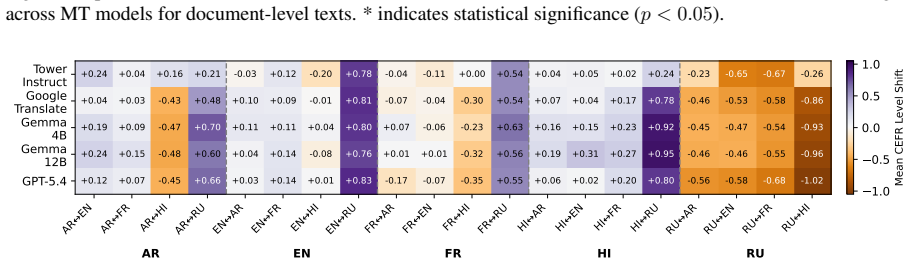
Higher CEFR levels make texts more difficult to translate, and machine translation shifts the CEFR level of the target text compared to the original source for most languages, demonstrated through correlation and shift analyses on the ComplexityMT benchmark with Arabic, Dutch, English, French, Hindi, and Russian using three open-weight models, one closed model, and a commercial system.
What carries the argument
The ComplexityMT benchmark, which applies CEFR levels as the measure of text complexity to quantify both translation difficulty and post-translation complexity shifts.
If this is right
- Translation systems must account for input complexity to maintain intended difficulty in outputs.
- Pedagogical content generation requires explicit checks for complexity drift after translation.
- Difficulty estimation models should incorporate CEFR as a predictor variable.
- Multilingual MT evaluation needs separate metrics for complexity preservation.
Where Pith is reading between the lines
- Language-learning platforms could add post-translation CEFR checks to flag altered reading levels.
- Extending the benchmark to additional language pairs would test whether the observed shifts generalize beyond the six tested languages.
- If shifts prove systematic, training objectives could penalize complexity changes directly.
Load-bearing premise
That CEFR level assignments remain reliable and comparable when applied to machine-translated outputs across languages.
What would settle it
Observing no correlation between source CEFR level and translation error rates, or no consistent CEFR shifts in MT outputs across the six languages when using the same evaluation protocol.
Figures


read the original abstract
When a text is translated, does the translation retain the complexity of the original? We introduce ComplexityMT, a new challenge for assessing how text complexity and machine translation interact with and influence each other, using the Common European Framework of Reference for Languages (CEFR) levels as the measure of text complexity. Across six languages, including Arabic, Dutch, English, French, Hindi, and Russian, we evaluate three open-weight models, one closed model, and a commercial machine translation system on two tasks: i) correlation of CEFR with translation difficulty, and ii) shifts in CEFR levels of the source texts. Our experiments show that higher CEFR levels make texts more difficult to translate, and that machine translation shifts the CEFR level of the target text compared to the original source, for most languages. These findings provide new insights for researchers and practitioners working on multilingual pedagogical content generation and machine translation difficulty estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ComplexityMT, a new benchmark using CEFR levels to assess interactions between text complexity and machine translation across six languages (Arabic, Dutch, English, French, Hindi, Russian). It evaluates three open-weight models, one closed model, and a commercial MT system on two tasks: correlation of source CEFR level with translation difficulty, and shifts in CEFR levels between source and target texts. The main empirical claims are that higher CEFR levels increase translation difficulty and that MT induces CEFR level shifts in the target for most languages.
Significance. If the results hold after validation, the benchmark could offer useful data for estimating MT difficulty in pedagogical settings and for generating multilingual educational content. The work is a purely empirical evaluation on a new test set with no free parameters or self-referential derivations, which is a modest but clear contribution to the literature on MT evaluation.
major comments (2)
- [Abstract] Abstract: the claims that 'higher CEFR levels make texts more difficult to translate' and that 'machine translation shifts the CEFR level' are stated without any reported sample sizes, statistical tests, annotation procedures, or error analysis, so the degree to which the data support the conclusions cannot be assessed.
- [Abstract / experimental setup] The two headline results both require that CEFR level assignments remain valid and comparable when applied to MT outputs; however, no human validation, cross-domain accuracy checks, or analysis of classifier behavior on MT artifacts (repetitions, unnatural collocations) is described, leaving open the possibility that reported correlations and shifts are partly classifier artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, with planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that 'higher CEFR levels make texts more difficult to translate' and that 'machine translation shifts the CEFR level' are stated without any reported sample sizes, statistical tests, annotation procedures, or error analysis, so the degree to which the data support the conclusions cannot be assessed.
Authors: The abstract is intentionally concise as a summary. The full manuscript reports the benchmark composition (texts per CEFR level and language), statistical procedures (e.g., correlation coefficients with significance testing), CEFR classifier details, and error analysis in the results and experimental sections. We will revise the abstract to include brief references to sample sizes and statistical significance so that support for the claims is clearer from the abstract alone. revision: yes
-
Referee: [Abstract / experimental setup] The two headline results both require that CEFR level assignments remain valid and comparable when applied to MT outputs; however, no human validation, cross-domain accuracy checks, or analysis of classifier behavior on MT artifacts (repetitions, unnatural collocations) is described, leaving open the possibility that reported correlations and shifts are partly classifier artifacts.
Authors: This is a valid concern. The CEFR classifier was validated on human text, but the manuscript does not include targeted validation or artifact analysis on MT outputs. In revision we will add an explicit discussion of this limitation and, to the extent feasible with existing resources, a small-scale analysis of classifier behavior on MT-generated text to check for systematic effects from repetitions or unnatural phrasing. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper introduces ComplexityMT as a new test set and reports direct experimental results on CEFR-MT correlations and level shifts using off-the-shelf models. No derivations, fitted parameters renamed as predictions, self-citation chains, or ansatzes are present in the described methodology or claims. All findings rest on external data and standard evaluation metrics without any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sweta Agrawal and Marine Carpuat. 2019. https://doi.org/10.18653/v1/D19-1166 Controlling text complexity in neural machine translation . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1549--1564, Hong Kong, China. Asso...
-
[2]
Sandra Aluisio, Lucia Specia, Caroline Gasperin, and Carolina Scarton. 2010. https://aclanthology.org/W10-1001/ Readability assessment for text simplification . In Proceedings of the NAACL HLT 2010 Fifth Workshop on Innovative Use of NLP for Building Educational Applications , pages 1--9, Los Angeles, California. Association for Computational Linguistics
2010
-
[3]
Fernando Alva-Manchego, Carolina Scarton, and Lucia Specia. 2020. https://doi.org/10.1162/coli_a_00370 Data-driven sentence simplification: Survey and benchmark . Computational Linguistics, 46(1):135--187
-
[4]
Fernando Alva-Manchego and Matthew Shardlow. 2022. https://aclanthology.org/2022.eamt-1.33/ Towards readability-controlled machine translation of COVID -19 texts . In Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, pages 287--288, Ghent, Belgium. European Association for Machine Translation
2022
-
[5]
Fernando Alva-Manchego, Regina Stodden, Joseph Marvin Imperial, Abdullah Barayan, Kai North, and Harish Tayyar Madabushi. 2025. https://doi.org/10.18653/v1/2025.tsar-1.8 Findings of the TSAR 2025 shared task on readability-controlled text simplification . In Proceedings of the Fourth Workshop on Text Simplification, Accessibility and Readability (TSAR 202...
-
[6]
Duarte Miguel Alves, Jos \'e Pombal, Nuno M Guerreiro, Pedro Henrique Martins, Jo \ a o Alves, Amin Farajian, Ben Peters, Ricardo Rei, Patrick Fernandes, Sweta Agrawal, Pierre Colombo, Jos \'e G. C. de Souza, and Andre Martins. 2024. https://openreview.net/forum?id=EHPns3hVkj Tower: An Open Multilingual Large Language Model for Translation-Related Tasks ....
2024
-
[7]
Sahar Araghi and Alfons Palangkaraya. 2024. https://doi.org/10.1007/s10579-024-09735-x The link between translation difficulty and the quality of machine translation: a literature review and empirical investigation . Language Resources and Evaluation, 58(4):1093--1114
-
[8]
Yuki Arase, Satoru Uchida, and Tomoyuki Kajiwara. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.416 CEFR -based sentence difficulty annotation and assessment . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6206--6219, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[9]
Abdullah Barayan, Jose Camacho-Collados, and Fernando Alva-Manchego. 2025. https://aclanthology.org/2025.coling-main.452/ Analysing zero-shot readability-controlled sentence simplification . In Proceedings of the 31st International Conference on Computational Linguistics, pages 6762--6781, Abu Dhabi, UAE. Association for Computational Linguistics
2025
-
[10]
Mark Breuker. 2022. https://library.oapen.org/bitstream/handle/20.500.12657/59316/1/978-3-031-17258-8.pdf#page=297 CEFR Labelling and Assessment Services . In European Language Grid: A Language Technology Platform for Multilingual Europe, pages 277--282. Springer International Publishing Cham
2022
-
[11]
Mielke, Antonios Anastasopoulos, Ryan Cotterell, and Naoaki Okazaki
Emanuele Bugliarello, Sabrina J. Mielke, Antonios Anastasopoulos, Ryan Cotterell, and Naoaki Okazaki. 2020. https://doi.org/10.18653/v1/2020.acl-main.149 It ' s easier to translate out of E nglish than into it: M easuring neural translation difficulty by cross-mutual information . In Proceedings of the 58th Annual Meeting of the Association for Computatio...
-
[12]
Chandrasekar, Christine Doran, and B
R. Chandrasekar, Christine Doran, and B. Srinivas. 1996. https://aclanthology.org/C96-2183/ Motivations and methods for text simplification . In COLING 1996 Volume 2: The 16th International Conference on Computational Linguistics
1996
-
[13]
Dinu, and Flaviu Pepelea
Alina Maria Ciobanu, Liviu P. Dinu, and Flaviu Pepelea. 2015. https://aclanthology.org/R15-1014/ Readability assessment of translated texts . In Proceedings of the International Conference Recent Advances in Natural Language Processing, pages 97--103, Hissar, Bulgaria. INCOMA Ltd. Shoumen, BULGARIA
2015
-
[14]
Gloria Corpas Pastor, Ruslan Mitkov, Naveed Afzal, and Viktor Pekar. 2008. https://aclanthology.org/2008.amta-papers.5/ Translation universals: do they exist? a corpus-based NLP study of convergence and simplification . In Proceedings of the 8th Conference of the Association for Machine Translation in the Americas: Research Papers, pages 75--81, Waikiki, ...
2008
-
[15]
Council of Europe . 2001. https://rm.coe.int/1680459f97 Common European Framework of Reference for Languages: Learning, Teaching, Assessment . Cambridge University Press
arXiv 2001
-
[16]
Crossley, Stephen Skalicky, Mihai Dascalu, Danielle S
Scott A. Crossley, Stephen Skalicky, Mihai Dascalu, Danielle S. McNamara, and Kristopher Kyle. 2017. https://doi.org/10.1080/0163853x.2017.1296264 Predicting Text Comprehension, Processing, and Familiarity in Adult Readers: New Approaches to Readability Formulas . Discourse Processes, 54(5-6):340--359
-
[17]
Tovly Deutsch, Masoud Jasbi, and Stuart Shieber. 2020. https://doi.org/10.18653/v1/2020.bea-1.1 Linguistic features for readability assessment . In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 1--17, Seattle, WA, USA Online. Association for Computational Linguistics
-
[18]
William H. DuBay. 2004. https://files.eric.ed.gov/fulltext/ED490073.pdf The Principles of Readability . Impact Information
2004
-
[19]
Google Translate Research Team , Mara Finkelstein, Isaac Caswell, Tobias Domhan, Jan-Thorsten Peter, Juraj Juraska, Parker Riley, Daniel Deutsch, Cole Dilanni, Colin Cherry, Eleftheria Briakou, Elizabeth Nielsen, Jiaming Luo, Sweta Agrawal, Wenda Xu, Erin Kats, Stephane Jaskiewicz, Markus Freitag, and David Vilar. 2026. https://doi.org/10.48550/arXiv.2601...
-
[20]
Sandra Hale and Stuart Campbell. 2002. https://doi.org/10.1075/babel.48.1.02hal The interaction between text difficulty and translation accuracy . Babel, 48(1):14--33
-
[21]
Joseph Marvin Imperial, Abdullah Barayan, Regina Stodden, Rodrigo Wilkens, Ricardo Mu \ n oz S \'a nchez, Lingyun Gao, Melissa Torgbi, Dawn Knight, Gail Forey, Reka R. Jablonkai, Ekaterina Kochmar, Robert Joshua Reynolds, Eug \'e nio Ribeiro, Horacio Saggion, Elena Volodina, Sowmya Vajjala, Thomas Fran c ois, Fernando Alva-Manchego, and Harish Tayyar Mada...
-
[22]
J. Peter Kincaid, Robert P. Fishburne Jr, Richard L. Rogers, and Brad S. Chissom. 1975. https://doi.org/10.21236/ada006655 Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel . Technical report, Institute for Simulation and Training, University of Central Florida
-
[23]
Tom Kocmi and Christian Federmann. 2023. https://aclanthology.org/2023.eamt-1.19/ Large language models are state-of-the-art evaluators of translation quality . In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 193--203, Tampere, Finland. European Association for Machine Translation
2023
-
[24]
Colleen Lennon and Hal Burdick. 2004. https://cdn.lexile.com/m/resources/materials/Lennon__Burdick_2004.pdf The lexile framework as an approach for reading measurement and success . Electronic Publication on www.lexile.com
2004
-
[25]
Junyi Jessy Li, Marine Carpuat, and Ani Nenkova. 2014. https://doi.org/10.3115/v1/P14-2047 Assessing the discourse factors that influence the quality of machine translation . In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 283--288, Baltimore, Maryland. Association for Computationa...
-
[26]
Xinyu Lu, Jipeng Qiang, Yun Li, Yunhao Yuan, and Yi Zhu. 2021. https://doi.org/10.18653/v1/2021.findings-emnlp.22 An unsupervised method for building sentence simplification corpora in multiple languages . In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 227--237, Punta Cana, Dominican Republic. Association for Computational...
-
[27]
Mounica Maddela, Fernando Alva-Manchego, and Wei Xu. 2021. https://doi.org/10.18653/v1/2021.naacl-main.277 Controllable text simplification with explicit paraphrasing . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3536--3553, Online. Association for...
-
[28]
Mounica Maddela and Wei Xu. 2018. https://doi.org/10.18653/v1/D18-1410 A word-complexity lexicon and a neural readability ranking model for lexical simplification . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3749--3760, Brussels, Belgium. Association for Computational Linguistics
-
[29]
Kelly Marchisio, Jialiang Guo, Cheng-I Lai, and Philipp Koehn. 2019. https://aclanthology.org/W19-6619/ Controlling the reading level of machine translation output . In Proceedings of Machine Translation Summit XVII: Research Track, pages 193--203, Dublin, Ireland. European Association for Machine Translation
2019
-
[30]
Sneha Mehta, Bahareh Azarnoush, Boris Chen, Avneesh Saluja, Vinith Misra, Ballav Bihani, and Ritwik Kumar. 2020. https://doi.org/10.1609/aaai.v34i05.6369 Simplify-then-translate: Automatic preprocessing for black-box translation . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8488--8495
-
[31]
Shachar Mirkin and Jean-Luc Meunier. 2015. https://doi.org/10.18653/v1/D15-1238 Personalized machine translation: Predicting translational preferences . In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 2019--2025, Lisbon, Portugal. Association for Computational Linguistics
-
[32]
Abhijit Mishra, Pushpak Bhattacharyya, and Michael Carl. 2013. https://aclanthology.org/P13-2062/ Automatically predicting sentence translation difficulty . In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346--351, Sofia, Bulgaria. Association for Computational Linguistics
2013
-
[33]
Maria Nadejde, Anna Currey, Benjamin Hsu, Xing Niu, Marcello Federico, and Georgiana Dinu. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.47 C o C o A - MT : A dataset and benchmark for contrastive controlled MT with application to formality . In Findings of the Association for Computational Linguistics: NAACL 2022, pages 616--632, Seattle, United ...
-
[34]
Tarek Naous, Michael J Ryan, Anton Lavrouk, Mohit Chandra, and Wei Xu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.682 R ead M e++: Benchmarking multilingual language models for multi-domain readability assessment . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12230--12266, Miami, Florida, USA. Ass...
-
[35]
Daiki Nishihara, Tomoyuki Kajiwara, and Yuki Arase. 2019. https://doi.org/10.18653/v1/P19-2036 Controllable text simplification with lexical constraint loss . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, pages 260--266, Florence, Italy. Association for Computational Linguistics
-
[36]
OpenAI . 2025. https://doi.org/10.48550/arXiv.2601.03267 GPT-5 System Card . Computing Research Repository, arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267 2025
-
[37]
Lorenzo Proietti, Stefano Perrella, Vil \'e m Zouhar, Roberto Navigli, and Tom Kocmi. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1317 Estimating machine translation difficulty . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 24261--24285, Suzhou, China. Association for Computational Linguistics
-
[38]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.213 COMET : A neural framework for MT evaluation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685--2702, Online. Association for Computational Linguistics
-
[39]
Carolina Scarton and Lucia Specia. 2018. https://doi.org/10.18653/v1/P18-2113 Learning simplifications for specific target audiences . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 712--718, Melbourne, Australia. Association for Computational Linguistics
-
[40]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. https://doi.org/10.18653/v1/N16-1005 Controlling politeness in neural machine translation via side constraints . In Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 35--40, San Diego, California. As...
-
[41]
Matthew Shardlow and Fernando Alva-Manchego. 2022. https://aclanthology.org/2022.lrec-1.331/ Simple TICO -19: A dataset for joint translation and simplification of COVID -19 texts . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 3093--3102, Marseille, France. European Language Resources Association
2022
-
[42]
Kim Cheng Sheang and Horacio Saggion. 2021. https://doi.org/10.18653/v1/2021.inlg-1.38 Controllable sentence simplification with a unified text-to-text transfer transformer . In Proceedings of the 14th International Conference on Natural Language Generation, pages 341--352, Aberdeen, Scotland, UK. Association for Computational Linguistics
-
[43]
Kazuki Tani, Ryoya Yuasa, Kazuki Takikawa, Akihiro Tamura, Tomoyuki Kajiwara, Takashi Ninomiya, and Tsuneo Kato. 2022. https://aclanthology.org/2022.lrec-1.726/ A benchmark dataset for multi-level complexity-controllable machine translation . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 6744--6752, Marseille, France...
2022
-
[44]
Sowmya Vajjala. 2022. https://aclanthology.org/2022.lrec-1.574/ Trends, limitations and open challenges in automatic readability assessment research . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 5366--5377, Marseille, France. European Language Resources Association
2022
-
[45]
Laura V \'a squez-Rodr \'i guez, Pedro-Manuel Cuenca-Jim \'e nez, Sergio Morales-Esquivel, and Fernando Alva-Manchego. 2022. https://doi.org/10.18653/v1/2022.tsar-1.18 A benchmark for neural readability assessment of texts in S panish . In Proceedings of the Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), pages 188--198, Abu D...
-
[46]
Benjamin Warner, Antoine Chaffin, Benjamin Clavi \'e , Orion Weller, Oskar Hallstr \"o m, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli. 2025. https://doi.org/10.18653/v1/2025.acl-long.127 Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory effi...
-
[47]
Michelle Wastl, Jannis Vamvas, and Rico Sennrich. 2025. https://doi.org/10.18653/v1/2025.findings-acl.59 Machine translation models are zero-shot detectors of translation direction . In Findings of the Association for Computational Linguistics: ACL 2025, pages 1054--1074, Vienna, Austria. Association for Computational Linguistics
-
[48]
Menglin Xia, Ekaterina Kochmar, and Ted Briscoe. 2016. https://doi.org/10.18653/v1/W16-0502 Text readability assessment for second language learners . In Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications , pages 12--22, San Diego, CA. Association for Computational Linguistics
-
[49]
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze Chen, and Chris Callison-Burch. 2016. https://doi.org/10.1162/tacl_a_00107 Optimizing statistical machine translation for text simplification . Transactions of the Association for Computational Linguistics, 4:401--415
-
[50]
Vil \'e m Zouhar, Wenda Xu, Parker Riley, Juraj Juraska, Mara Finkelstein, Markus Freitag, and Daniel Deutsch. 2026. https://doi.org/10.18653/v1/2026.mme-main.14 Generating difficult-to-translate texts . In Proceedings of the First Workshop on Multilingual Multicultural Evaluation, pages 204--219, Rabat, Morocco. Association for Computational Linguistics
-
[51]
2024 , publisher=
Araghi, Sahar and Palangkaraya, Alfons , journal=. 2024 , publisher=
2024
-
[52]
Smith, Dean R and others , year=
-
[53]
2004 , url=
Lennon, Colleen and Burdick, Hal , journal=. 2004 , url=
2004
-
[54]
2002 , publisher=
Hale, Sandra and Campbell, Stuart , journal=. 2002 , publisher=
2002
-
[55]
2020 , doi =
Mehta, Sneha and Azarnoush, Bahareh and Chen, Boris and Saluja, Avneesh and Misra, Vinith and Bihani, Ballav and Kumar, Ritwik , booktitle=. 2020 , doi =
2020
-
[56]
Dai, Guangrong and Liu, Siqi , journal=
-
[57]
and Skalicky, Stephen and Dascalu, Mihai and McNamara, Danielle S
Crossley, Scott A. and Skalicky, Stephen and Dascalu, Mihai and McNamara, Danielle S. and Kyle, Kristopher , journal =. 2017 , doi =
2017
-
[58]
DuBay , publisher =
William H. DuBay , publisher =. 2004 , url =
2004
-
[59]
Peter and Fishburne Jr, Robert P
Kincaid, J. Peter and Fishburne Jr, Robert P. and Rogers, Richard L. and Chissom, Brad S. , year =
-
[60]
2022 , URL =
Breuker, Mark , booktitle=. 2022 , URL =
2022
-
[61]
2025 , doi =
Computing Research Repository , volume =. 2025 , doi =
2025
-
[62]
First Conference on Language Modeling , year =
Duarte Miguel Alves and Jos. First Conference on Language Modeling , year =
-
[63]
2026 , doi =
Computing Research Repository , volume =. 2026 , doi =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.