Step-by-Step Optimization-like Reasoning in LLMs over Expanding Search Spaces
Pith reviewed 2026-06-28 05:44 UTC · model grok-4.3
The pith
Training LLMs on optimization-style tasks with expanding search spaces improves their step-by-step reasoning for high-value feasible plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
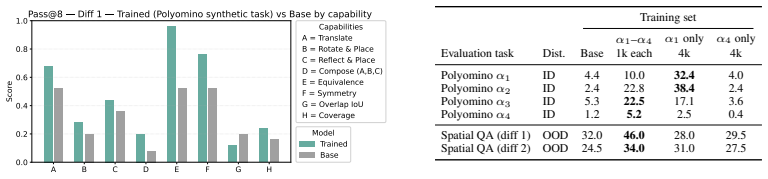
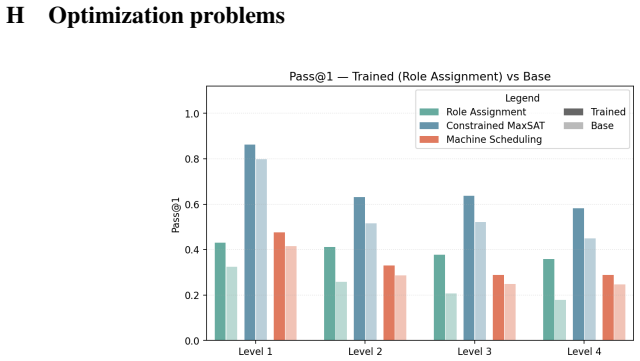
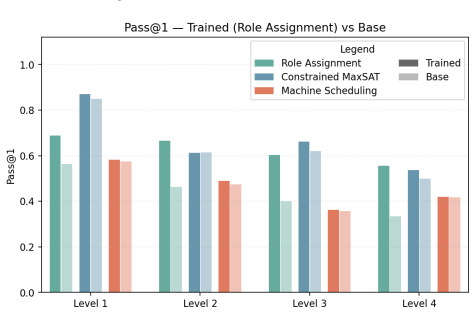
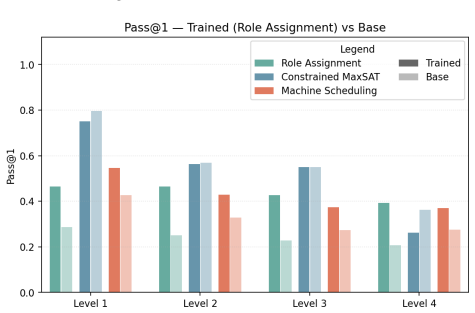
Training on OPT* improves step-by-step optimization-like reasoning, as shown by ablations of search-efficiency ingredients and results from the two regimes.
What carries the argument
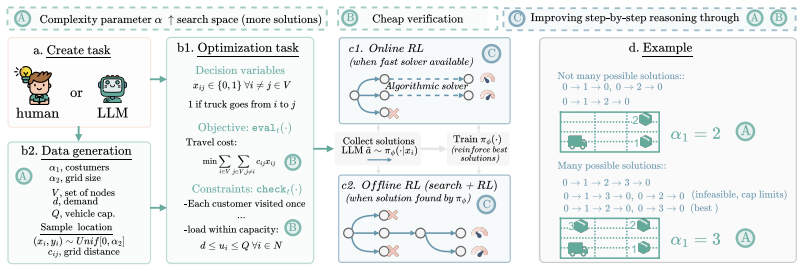
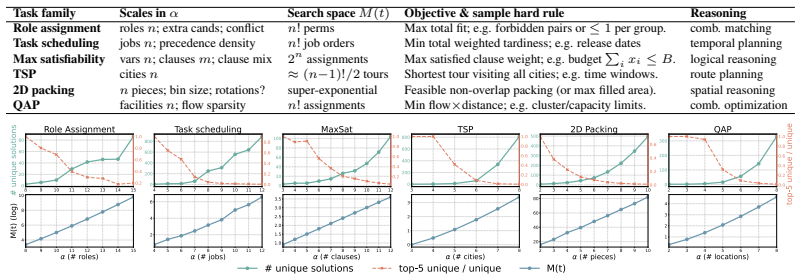
OPT*, a scalable family of optimization-style tasks that supplies a feasibility checker and evaluator while a complexity parameter expands the search space.
If this is right
- Solver-guided online policy optimization with rank-based reward shaping reinforces better next steps using the solver as value oracle.
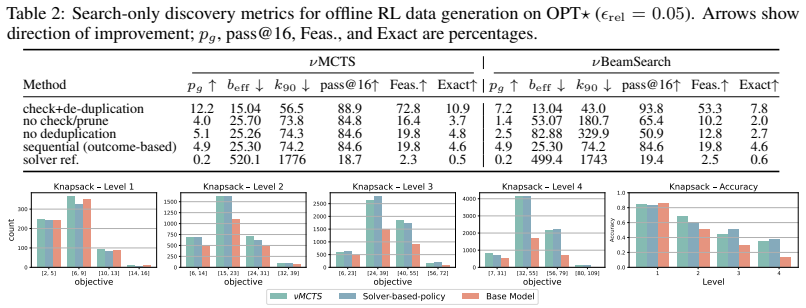
- Search-based offline RL enables training when solvers are unavailable.
- Ablations identify the specific ingredients required for efficient search over expanding spaces.
- Success scales with the information a reasoner extracts per unit of search budget.
Where Pith is reading between the lines
- The OPT* construction could be adapted to generate synthetic data for domains where real labels are scarce but feasibility and value can be checked programmatically.
- The per-budget information extraction relation suggests a way to allocate compute between model size and search depth during inference.
- Hybrid training that alternates between the two regimes might reduce dependence on external solvers while retaining their guidance.
Load-bearing premise
The feasibility checker and evaluator supplied by each OPT* task sufficiently capture the structure of real-world tasks that require selecting high-value feasible plans among many valid alternatives.
What would settle it
A controlled test in which models trained on OPT* show no gain over baselines when evaluated on a new planning domain whose checker and evaluator encode different structural constraints.
Figures
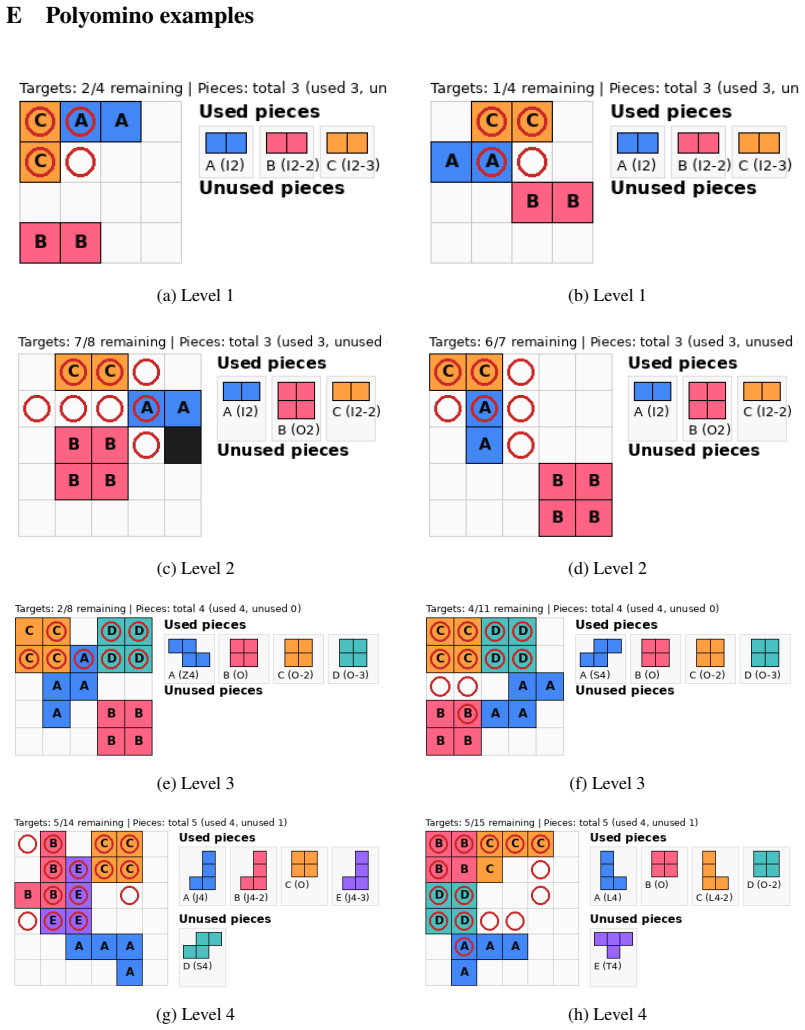
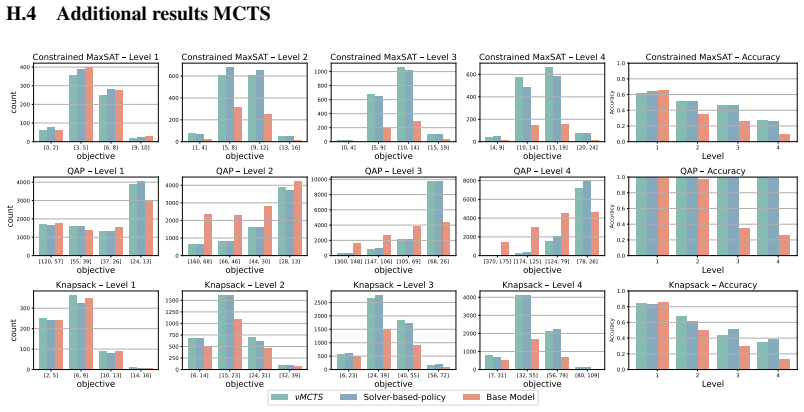
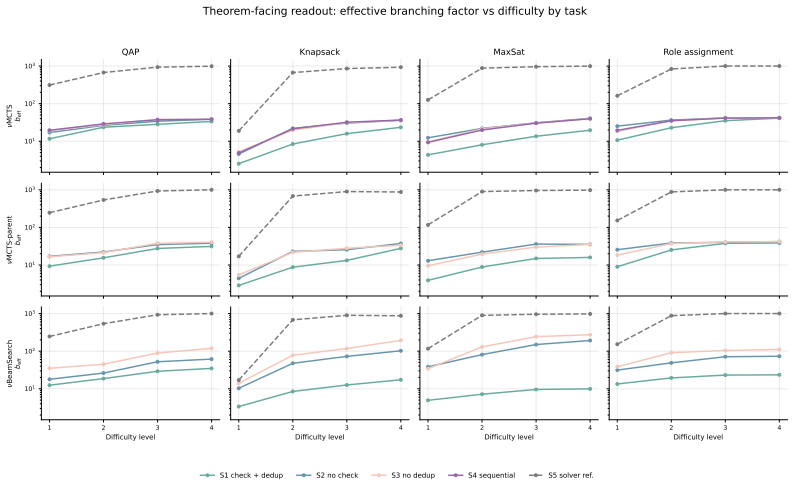
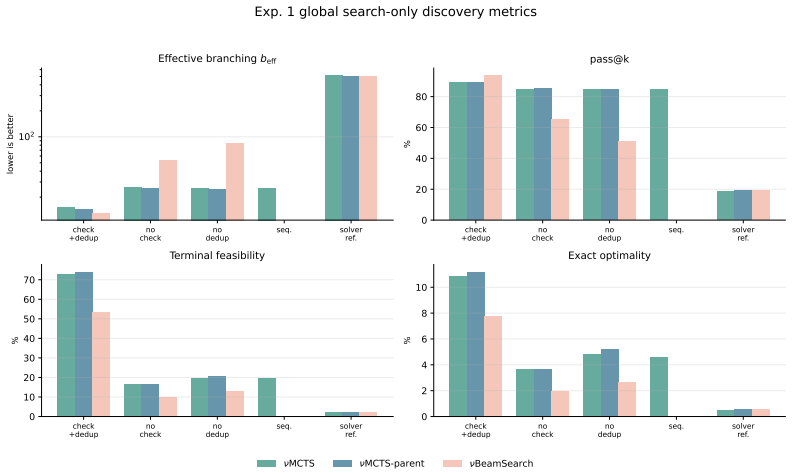
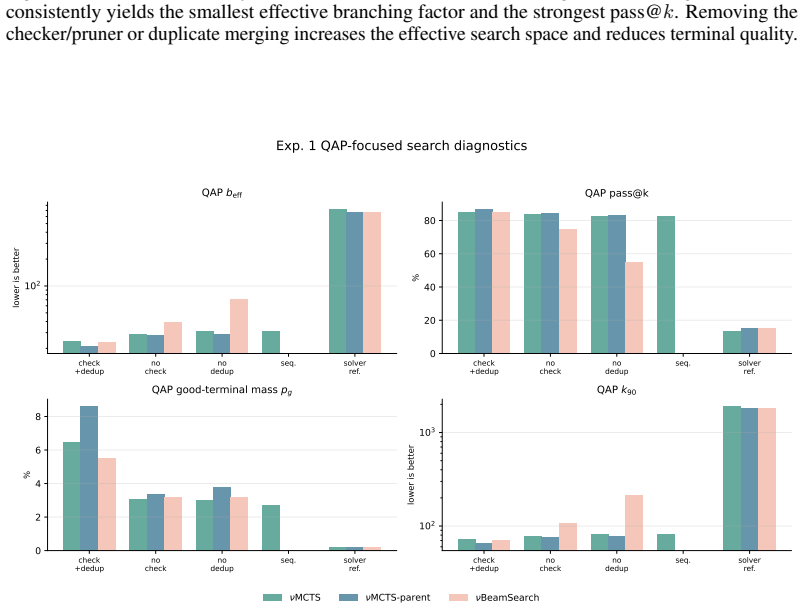
read the original abstract
Verifiable reward training has improved mathematical and coding reasoning, but these domains capture only part of step-by-step decision making. Many real-world tasks require finding a high-value feasible plan among many valid alternatives. We introduce OPT*, a scalable family of optimization-style tasks for training and evaluating LLM step-by-step optimization-like reasoning along a complexity axis: each task provides a feasibility checker and evaluator, while a complexity parameter expands the search space without requiring new human labels. This motivates studying these tasks in two regimes: (i) solver-guided online policy optimization, which uses a solver as a value oracle for partial states and applies rank-based reward shaping to reinforce better next steps, and (ii) search-based offline RL when such solvers are unavailable. Theoretically, we relate success in large search spaces to the information a reasoner extracts per unit of search budget. Empirically, we ablate the ingredients that make search efficient on OPT* and show that training on OPT* improves step-by-step optimization-like reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OPT*, a scalable family of optimization-style tasks for LLMs that supply explicit feasibility checkers and evaluators along with a tunable complexity parameter to expand search spaces without new human labels. It examines two regimes—solver-guided online policy optimization with rank-based reward shaping and search-based offline RL—provides a theoretical relation linking success in large spaces to information extracted per search budget, and reports empirical ablations showing that training on OPT* improves step-by-step optimization-like reasoning.
Significance. If the empirical results and ablations hold under scrutiny, the work supplies a new, controllable benchmark family for optimization-like reasoning that extends beyond math and coding domains, together with a theoretical framing of search efficiency. The ablations on search-efficiency ingredients and the two-regime design are concrete strengths that could support follow-on work on plan selection.
major comments (1)
- [Abstract and OPT* task definition] The central motivation—that improvements on OPT* will transfer to real-world tasks requiring selection of high-value feasible plans among many valid alternatives—rests on the assumption that the supplied feasibility checkers and evaluators induce the same reasoning demands as tasks lacking such oracles. This assumption is load-bearing for the broader claim yet is not tested; all reported regimes and ablations operate inside the oracle-provided setting (Abstract; description of the two regimes).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and OPT* task definition] The central motivation—that improvements on OPT* will transfer to real-world tasks requiring selection of high-value feasible plans among many valid alternatives—rests on the assumption that the supplied feasibility checkers and evaluators induce the same reasoning demands as tasks lacking such oracles. This assumption is load-bearing for the broader claim yet is not tested; all reported regimes and ablations operate inside the oracle-provided setting (Abstract; description of the two regimes).
Authors: We acknowledge that the empirical regimes operate with provided feasibility checkers and evaluators (enabling verifiable rewards) and that the solver-guided regime additionally uses a solver oracle. The search-based offline RL regime removes the solver but retains the checkers/evaluators. We agree that direct empirical testing of transfer to settings with no oracles at all is absent and constitutes a limitation for the broader transfer claim. The OPT* design isolates optimization-like reasoning under verifiable signals, analogous to math/coding benchmarks; we will revise the abstract and regime descriptions to explicitly scope the claims, clarify oracle dependence, and flag oracle-free transfer as future work. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines OPT* tasks independently via explicit feasibility checkers, evaluators, and a tunable complexity parameter that expands search space without new labels. It then evaluates two regimes (solver-guided online policy optimization and search-based offline RL) and reports ablations showing performance gains on these tasks. The theoretical relation between search budget and extracted information is stated as a relation rather than derived from fitted parameters or self-citations. No equations or claims reduce the reported improvements to the task definitions by construction, and no self-citation chains or ansatzes are invoked as load-bearing for the central empirical result. The derivation is therefore self-contained against the introduced benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associ...
2022
-
[2]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=WZH7099tgfM
2023
-
[3]
Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
2017
-
[4]
Re- act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Star: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022
2022
-
[6]
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models.arXiv preprint arXiv:2308.01825, 2023. URLhttps://arxiv.org/abs/2308.01825
Pith/arXiv arXiv 2023
-
[7]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri...
arXiv 2023
-
[8]
Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
Pith/arXiv arXiv 2023
-
[9]
Eric Zelikman, Georges Raif Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D. Goodman. Quiet-STaR: Language models can teach themselves to think before speaking. InConference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=oRXPiSOGH9
2024
-
[10]
V-STaR: Training verifiers for self-taught reasoners
Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-STaR: Training verifiers for self-taught reasoners. InConference on Language Modeling, 2024. URL https://openreview.net/forum?id=stmqBSW2dV
2024
-
[11]
Symbolic chain-of-thought distillation: Small models can also “think” step-by-step
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi. Symbolic chain-of-thought distillation: Small models can also “think” step-by-step. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2665–
-
[12]
doi: 10.18653/v1/2023.acl-long.150
Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.150. URL https://aclanthology.org/2023.acl-long.150/
-
[13]
Bridging offline and online reinforcement learning for llms.arXiv preprint arXiv:2506.21495, 2025
Jack Lanchantin, Angelica Chen, Janice Lan, Xian Li, Swarnadeep Saha, Tianlu Wang, Jing Xu, Ping Yu, Weizhe Yuan, Jason E Weston, et al. Bridging offline and online reinforcement learning for llms.arXiv preprint arXiv:2506.21495, 2025
arXiv 2025
-
[14]
Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
2016
-
[15]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
2017
-
[16]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 10
Pith/arXiv arXiv 2024
-
[17]
Group sequence policy optimization, 2025
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. URL https://arxiv.org/abs/2507.18071
Pith/arXiv arXiv 2025
-
[18]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[19]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[20]
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, et al. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles.arXiv preprint arXiv:2505.19914, 2025
arXiv 2025
-
[21]
Zhen Hao Wong, Jingwen Deng, Runming He, Zirong Chen, Qijie You, Hejun Dong, Hao Liang, Chengyu Shen, Bin Cui, and Wentao Zhang. Logicpuzzlerl: Cultivating robust mathematical reasoning in llms via reinforcement learning.arXiv preprint arXiv:2506.04821, 2025
arXiv 2025
-
[22]
Anjiang Wei, Yuheng Wu, Yingjia Wan, Tarun Suresh, Huanmi Tan, Zhanke Zhou, Sanmi Koyejo, Ke Wang, and Alex Aiken. Satbench: Benchmarking llms’ logical reasoning via automated puzzle generation from sat formulas.arXiv preprint arXiv:2505.14615, 2025
arXiv 2025
-
[23]
Qin Zhu, Fei Huang, Runyu Peng, Keming Lu, Bowen Yu, Qinyuan Cheng, Xipeng Qiu, Xuanjing Huang, and Junyang Lin. Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models.arXiv preprint arXiv:2502.16906, 2025
arXiv 2025
-
[24]
Nature625, 476–482 (2024).https://doi.org/ 10.1038/s41586-023-06747-5
Trieu Trinh, Yuhuai Wu, Quoc Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations.Nature, 2024. doi: 10.1038/s41586-023-06747-5
-
[25]
Ai achieves silver-medal standard solving in- ternational mathematical olympiad problems
AlphaProof and AlphaGeometry teams. Ai achieves silver-medal standard solving in- ternational mathematical olympiad problems. https://deepmind.google/discover/blog/ ai-solves-imo-problems-at-silver-medal-level/, July 2024. Accessed 2025-09-25
2024
-
[26]
Arkil Patel, Siva Reddy, and Dzmitry Bahdanau. How to get your llm to generate challenging problems for evaluation.arXiv preprint arXiv:2502.14678, 2025
arXiv 2025
-
[27]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[28]
Measuring coding challenge competence with APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InAdvances in Neural Information Processing Systems, 2021. arXiv:2105.09938
Pith/arXiv arXiv 2021
-
[29]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[30]
Competition-Level Code Generation with AlphaCode
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Ec- cles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Mas- son d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, P...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1126/science.abq1158 2022
-
[31]
REASONING GYM: Reasoning environments for reinforcement learning with verifiable rewards, 2025
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, and Andreas Köpf. REASONING GYM: Reasoning environments for reinforcement learning with verifiable rewards, 2025. URLhttps://arxiv.org/abs/2505.24760. 11
arXiv 2025
-
[32]
Peiji Li, Jiasheng Ye, Yongkang Chen, Yichuan Ma, Zijie Yu, Kedi Chen, Xiaozhe Li, Ganqu Cui, Haozhan Li, Jiacheng Chen, Chengqi Lyu, Wenwei Zhang, Linyang Li, Qipeng Guo, Dahua Lin, Bowen Zhou, and Kai Chen. InternBootcamp technical report: Boosting LLM reasoning with verifiable task scaling.arXiv preprint arXiv:2508.08636, 2025. URLhttps://arxiv.org/abs...
Pith/arXiv arXiv 2025
-
[33]
Analysing mathematical reasoning abilities of neural models
David Saxton, Edward Grefenstette, Felix Hill, and Pushmeet Kohli. Analysing mathematical reasoning abilities of neural models. InInternational Conference on Learning Representations (ICLR), 2019. arXiv:1904.01557
Pith/arXiv arXiv 2019
-
[34]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[35]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[36]
Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training.arXiv preprint arXiv:2309.17179, 2023. URLhttps://arxiv.org/abs/2309.17179
arXiv 2023
-
[37]
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning.arXiv preprint arXiv:2405.00451, 2024
arXiv 2024
-
[38]
Alphamath almost zero: process supervision without process, 2024
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Alphamath almost zero: process supervision without process, 2024. URLhttps://arxiv.org/abs/2405.03553
arXiv 2024
-
[39]
Step-level value preference optimization for mathematical reasoning
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Step-level value preference optimization for mathematical reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7889–7903, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.463. URL https://aclanthology....
-
[40]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
Pith/arXiv arXiv 2024
-
[41]
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search.arXiv preprint arXiv:2406.03816, 2024
arXiv 2024
-
[42]
Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b.arXiv preprint arXiv:2406.07394, 2024
arXiv 2024
-
[43]
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519, 2025
Pith/arXiv arXiv 2025
-
[44]
Graph of thoughts: Solving elaborate problems with large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690, 2024
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690, 2024
2024
-
[45]
Bandit Based Monte-Carlo Planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InMachine Learning: ECML 2006, pages 282–293. Springer, 2006. doi: 10.1007/11871842_29
-
[46]
Efficient selectivity and backup operators in Monte-Carlo tree search
Rémi Coulom. Efficient selectivity and backup operators in Monte-Carlo tree search. In H. Jaap van den Herik, Paolo Ciancarini, and H. H. L. M. Donkers, editors,Computers and Games: CG 2006, volume 4630 ofLecture Notes in Computer Science, pages 72–83. Springer, 2007. doi: 10.1007/978-3-540-75538-8_7
-
[47]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in Games, 4(1):1–43,
-
[48]
doi: 10.1109/TCIAIG.2012.2186810. 12
-
[49]
Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models, 2025
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, and Nick Haber. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models, 2025. URL https://arxiv.org/abs/2502. 17387
2025
-
[50]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework. InProceedings of the Twentieth European Conference on Computer Systems. ACM, 2025. doi: 10.1145/3689031.3696075
-
[51]
Qwen2.5 technical report, 2024
Qwen Team. Qwen2.5 technical report, 2024. URLhttps://arxiv.org/abs/2412.15115
Pith/arXiv arXiv 2024
-
[52]
Llama 3.2 3b instruct model card
Meta. Llama 3.2 3b instruct model card. Hugging Face model card, 2024. URL https://huggingface. co/meta-llama/Llama-3.2-3B-Instruct
2024
-
[53]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Con- ference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[54]
American mathematics competitions (AMC) 2023
Mathematical Association of America. American mathematics competitions (AMC) 2023. Mathematical Association of America, 2023. URL https://maa.org/student-programs/amc/. Accessed 2026-06- 03
2023
-
[55]
American invitational mathematics examination (AIME) 2024
Mathematical Association of America. American invitational mathematics examination (AIME) 2024. Mathematical Association of America, 2024. URL https://maa.org/ maa-invitational-competitions/. Accessed 2026-06-03
2024
-
[56]
American invitational mathematics examination (AIME) 2025
Mathematical Association of America. American invitational mathematics examination (AIME) 2025. Mathematical Association of America, 2025. URL https://maa.org/ maa-invitational-competitions/. Accessed 2026-06-03. 13 Appendix Index Quick guide to the appendix Ref. Content AInformation-theoretic formalization of reasoning on OPT⋆ A.1 Effective optima and sc...
2025
-
[57]
a prompt function that converts the current structured state into a natural-language prompt
-
[58]
a JSON action schema, specified by the required action keys
-
[59]
a step validator, which implementschk t(s, a)
-
[60]
a state-transition rule, which applies a valid action to the current state
-
[61]
a terminal-state predicate
-
[62]
facility
an objective function, which implementseval t(·)on terminal states. The model is asked to provide a short reasoning trace and then exactly one action. In the default experiments, the action is parsed from {"answer": [{...}]}. The parser also records whether the response was valid JSON, whether it contained the required keys, and whether the parsed action ...
-
[63]
the task has not already been selected
-
[64]
the worker has not already been used
-
[65]
the worker is eligible for the task
-
[66]
all resource budgets remain satisfied
-
[67]
"=empty,
all hard Boolean clauses remain satisfied. The rollout terminates when no additional task-worker pair can be added without violating these conditions. Objective and tie-breakThe learning objective is to maximize the total weight of satisfied soft clauses. For oracle reporting, ties are broken lexicographically: first minimize resource usage in the fixed r...
-
[68]
Assign exactly one candidate to each role
-
[69]
Each candidate can be used at most once
-
[70]
Maximize X chosen fit scores − X conflict penalties among selected candidates
-
[71]
answer": [ {
Tie-breaker: among equal total scores, prefer the assignment with the highest minimum individual fit. Current state • Number of roles:6 • Number of candidates:7 • Already assigned role-candidate pairs:[] Fit matrix Rows are candidates and columns are roles. candidate 0: role scores {0: 9, 1: 9, 2: 1, 3: 3, 4: 8, 5: 3} candidate 1: role scores {0: 6, 1: 4,...
-
[72]
Maximize the total weight of satisfied soft clauses, subject to budgets, worker eligibil- ity, and hard logic
-
[73]
Tie-breaker A: among equal soft-clause scores, minimize resource usage lexicographi- cally
-
[74]
answer": [ {
Tie-breaker B: among remaining ties, prefer fewer selected tasks. Budgets Money= 12,Time= 11. Workers worker_index 0: W1 worker_index 1: W2 worker_index 2: W3 worker_index 3: W4 Tasks task_index 0, A: costs {Money: 2, Time: 1}, eligible workers [2] task_index 1, B: costs {Money: 2, Time: 4}, eligible workers [1] task_index 2, C: costs {Money: 4, Time: 3},...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.