Formal Concept Lattices are Good Semantic Scaffolds for Concept-Based Learning
Pith reviewed 2026-06-28 06:19 UTC · model grok-4.3
The pith
Formal concept lattices assign concepts to neural network layers by their level of generality to create staged semantic representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Formal concept lattices provide principled semantic scaffolds that naturally identify where in the network concepts should be learned based on their level of generality, allowing the model to develop staged, semantically grounded representations throughout its depth.
What carries the argument
Formal concept lattices, the hierarchical structures produced by Formal Concept Analysis that order concepts by generality and specificity to determine their assigned network layer.
If this is right
- Embeddings become more interpretable because each layer corresponds to a clear level of semantic abstraction.
- Interventions on concepts become more effective by operating at the layer where the concept is explicitly represented.
- Concept representations emerge as both meaningful and explicitly hierarchically structured rather than flat.
- Task performance remains intact while the above properties are gained.
Where Pith is reading between the lines
- The same lattice guidance could be applied during architecture search to decide layer widths based on concept count at each generality level.
- If lattices are recomputed on new data distributions, the model could adapt its internal concept placement without full retraining.
- The approach suggests a way to regularize networks so that feature emergence order matches an external semantic hierarchy rather than emerging only from data statistics.
Load-bearing premise
The hierarchical relations captured by formal concept lattices from data will align with the feature hierarchies that emerge across neural network layers.
What would settle it
Training the guided model on the same datasets and finding that concept interventions at the lattice-assigned layers produce no measurable gain in effectiveness over a flat single-layer baseline.
Figures

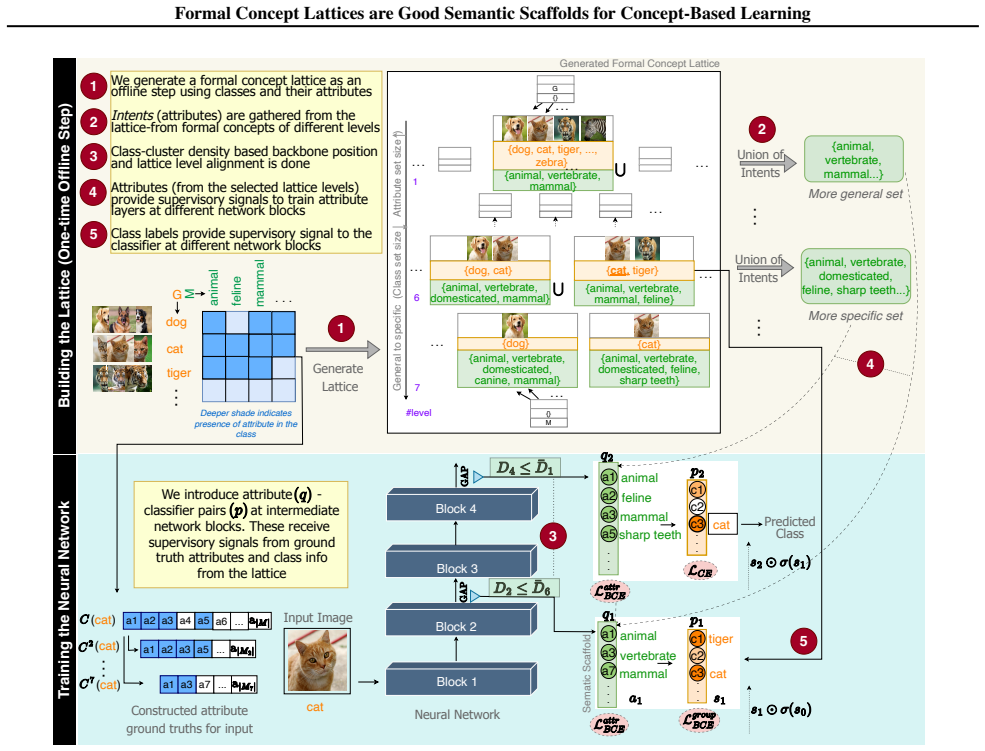
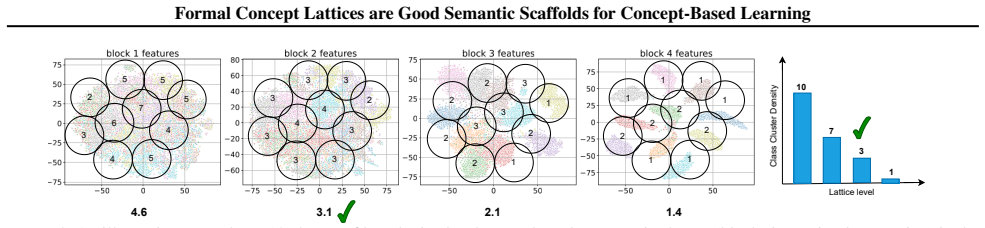
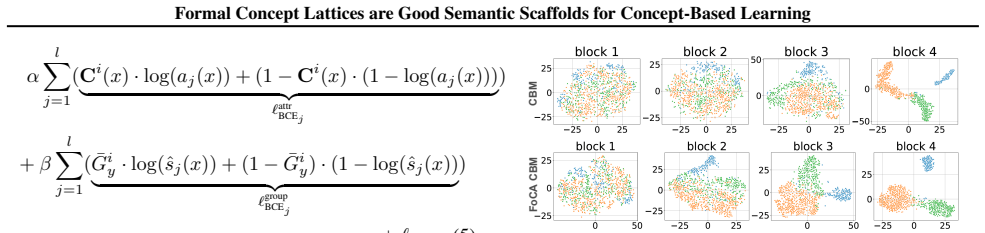
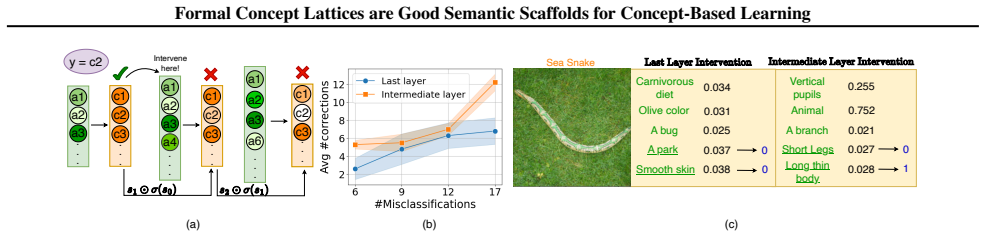

read the original abstract
Learning semantics is essential for deep learning models to be interpretable and better aligned with human reasoning. Concept-based models approach this by representing classes through meaningful semantic abstractions, but typically treat all concepts as a flat, unstructured set learned at a single neural network layer. This overlooks a fundamental property of human semantic understanding: concepts being organized hierarchically, from general to specific. While deep networks do learn a hierarchy of visual features, this structure is rarely aligned with explicit semantic hierarchies. Drawing on Formal Concept Analysis, we demonstrate that formal concept lattices provide principled semantic scaffolds to guide neural network learning. These lattices naturally identify where in the network concepts should be learned based on their level of generality. This allows the model to develop staged, semantically grounded representations throughout its depth. Empirical results on real-world datasets show that our models produce more interpretable embeddings, support more effective interventions, and learn concept representations that are both meaningful and hierarchically structured.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that formal concept lattices derived via Formal Concept Analysis supply a hierarchy of concept generality that can be used to assign concepts to specific layers in a neural network, thereby producing staged, semantically grounded representations. The authors assert that this alignment yields more interpretable embeddings, more effective interventions, and hierarchically structured concept representations, with supporting empirical results on real-world datasets.
Significance. If the empirical claims hold, the work supplies a principled, lattice-based mechanism for injecting explicit semantic hierarchy into concept-based models, addressing the common limitation of flat concept sets. The approach is grounded in established FCA theory and offers a concrete layer-assignment rule that could improve both interpretability and intervention efficacy while preserving task performance.
minor comments (1)
- Abstract: the summary of empirical results would be strengthened by naming the specific datasets, metrics, and baselines even at a high level, as the current phrasing leaves the strength of the reported gains difficult to gauge from the abstract alone.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and for recommending acceptance. The provided summary accurately reflects the manuscript's central claim that formal concept lattices can serve as semantic scaffolds for assigning concepts to network layers in a hierarchy-aware manner.
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description contain no equations, derivations, or explicit construction steps that could reduce to self-definition, fitted inputs, or self-citation chains. The central claim—that formal concept lattices supply a hierarchy for assigning concepts to network layers—is presented as a methodological proposal supported by empirical results on real-world datasets, without any visible load-bearing step that equates a prediction to its own input by construction. No self-citation is invoked to justify uniqueness or an ansatz, and the mapping from lattice order to layer depth is not shown to be forced by prior author work. This is the expected outcome when the manuscript supplies no internal derivation chain to inspect.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Formal concept lattices capture the hierarchical organization of semantic concepts in a way that can be aligned with neural network layer depths.
Reference graph
Works this paper leans on
-
[1]
Relational concept bottleneck models
Barbiero, P., Giannini, F., Ciravegna, G., Diligenti, M., and Marra, G. Relational concept bottleneck models. Advances in Neural Information Processing Systems, 37: 0 77663--77685, 2024
2024
-
[2]
and Kontorovich, A
Berend, D. and Kontorovich, A. A finite sample analysis of the naive bayes classifier. Journal of Machine Learning Research, 16 0 (44): 0 1519--1545, 2015. URL http://jmlr.org/papers/v16/berend15a.html
2015
-
[3]
Classification and Regression Trees
Breiman, L., Friedman, J., Stone, C., and Olshen, R. Classification and Regression Trees. Taylor & Francis, 1984. ISBN 9780412048418. URL https://books.google.co.in/books?id=JwQx-WOmSyQC
1984
-
[4]
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., and Su, J. K. This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems, 32, 2019
2019
-
[5]
Davies, D. L. and Bouldin, D. W. A cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-1 0 (2): 0 224--227, 1979. doi:10.1109/TPAMI.1979.4766909
-
[6]
Causally reliable concept bottleneck models
De Felice, G., Casanova Flores, A., De Santis, F., Santini, S., Schneider, J., Barbiero, P., and Termine, A. Causally reliable concept bottleneck models. Advances in Neural Information Processing Systems, 38: 0 149099--149139, 2026
2026
-
[7]
Fca2vec: Embedding techniques for formal concept analysis
Durrschnabel, D., Hanika, T., and Stubbemann, M. Fca2vec: Embedding techniques for formal concept analysis. In Complex Data Analytics with Formal Concept Analysis, 2019. URL https://api.semanticscholar.org/CorpusID:208291462
2019
-
[8]
and Lov \'a sz, L
Erd o s, P. and Lov \'a sz, L. Problems and results on 3-chromatic hypergraphs and some related questions. In Infinite and F inite S ets ( C olloq., K eszthely, 1973; dedicated to P . E rd o s on his 60th birthday) , volume 10 of Colloq. Math. Soc. J \'a nos Bolyai , pp.\ 609--627. North-Holland, Amsterdam, 1975
1973
-
[9]
and Lov\'asz, L
Erdos, P. and Lov\'asz, L. Problems and results on 3 -chromatic hypergraphs and some related questions. In Infinite and finite sets ( C olloq., K eszthely, 1973; dedicated to P . E rd os on his 60th birthday), V ols. I , II , III , volume Vol. 10 of Colloq. Math. Soc. J\'anos Bolyai, pp.\ 609--627. North-Holland, Amsterdam-London, 1975
1973
-
[10]
Hyperbolic entailment cones for learning hierarchical embeddings
Ganea, O., Becigneul, G., and Hofmann, T. Hyperbolic entailment cones for learning hierarchical embeddings. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 1646--1655. PMLR, 10--15 Jul 2018. URL https://proceedings.mlr.press/v80/ganea18a.html
2018
-
[11]
and Wille, R
Ganter, B. and Wille, R. Formal concept analysis: mathematical foundations. Springer Nature, 2024
2024
-
[12]
and Lukasiewicz, T
Giunchiglia, E. and Lukasiewicz, T. Coherent hierarchical multi-label classification networks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA, 2020. Curran Associates Inc. ISBN 9781713829546
2020
-
[13]
Giunchiglia, E. and Lukasiewicz, T. Multi-label classification neural networks with hard logical constraints. J. Artif. Int. Res., 72: 0 759–818, January 2022. ISSN 1076-9757. doi:10.1613/jair.1.12850. URL https://doi.org/10.1613/jair.1.12850
-
[14]
Gyurek, C., Talukder, N., and Hasan, M. A. Binder: Hierarchical concept representation through order embedding of binary vectors. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 980--991, 2024
2024
-
[15]
Harvey, N. J. and Vondrák, J. An algorithmic proof of the lovasz local lemma via resampling oracles. In 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, pp.\ 1327--1346, 2015. doi:10.1109/FOCS.2015.85
-
[16]
and Saul, L
Kearns, M. and Saul, L. Large deviation methods for approximate probabilistic inference. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, UAI'98, pp.\ 311–319, San Francisco, CA, USA, 1998. Morgan Kaufmann Publishers Inc. ISBN 155860555X
1998
-
[17]
Probabilistic concept bottleneck models
Kim, E., Jung, D., Park, S., Kim, S., and Yoon, S.-H. Probabilistic concept bottleneck models. ArXiv, abs/2306.01574, 2023. URL https://api.semanticscholar.org/CorpusID:259063823
arXiv 2023
-
[18]
W., Nguyen, T., Tang, Y
Koh, P. W., Nguyen, T., Tang, Y. S., Mussmann, S., Pierson, E., Kim, B., and Liang, P. Concept bottleneck models. In International conference on machine learning, pp.\ 5338--5348. PMLR, 2020
2020
-
[19]
Learning multiple layers of features from tiny images
Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009
2009
-
[20]
Kuznetsov, S. O. On stability of a formal concept. Annals of Mathematics and Artificial Intelligence, 49 0 (1): 0 101--115, 2007
2007
-
[21]
Logicseg: Parsing visual semantics with neural logic learning and reasoning
Li, L., Wang, W., and Yang, Y. Logicseg: Parsing visual semantics with neural logic learning and reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 4122--4133, October 2023
2023
-
[22]
Hybrid concept bottleneck models
Liu, Y., Zhang, T., and Gu, S. Hybrid concept bottleneck models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 20179--20189, 2025
2025
-
[23]
Glancenets: Interpretabile, leak-proof concept-based models
Marconato, E., Passerini, A., and Teso, S. Glancenets: Interpretabile, leak-proof concept-based models. In Neural Information Processing Systems, 2022. URL https://api.semanticscholar.org/CorpusID:249209924
2022
-
[24]
and Kiela, D
Nickel, M. and Kiela, D. Poincar\' e embeddings for learning hierarchical representations. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/5...
2017
-
[25]
Oikarinen, T., Das, S., Nguyen, L. M., and Weng, T.-W. Label-free concept bottleneck models. arXiv preprint arXiv:2304.06129, 2023
arXiv 2023
-
[26]
The building blocks of interpretability
Olah, C., Satyanarayan, A., Johnson, I., Carter, S., Schubert, L., Ye, K., and Mordvintsev, A. The building blocks of interpretability. Distill, 3 0 (3): 0 e10, 2018
2018
-
[27]
P., Ienco, D., and Marcos, D
Panousis, K. P., Ienco, D., and Marcos, D. Coarse-to-fine concept bottleneck models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=RMdnTnffou
2024
-
[28]
J., Jiang, Y., and Veitch, V
Park, K., Choe, Y. J., Jiang, Y., and Veitch, V. The geometry of categorical and hierarchical concepts in large language models. In International Conference on Learning Representations, volume 2025, pp.\ 76441--76463, 2025
2025
-
[29]
Bert4fca: A method for bipartite link prediction using formal concept analysis and bert
Peng, S., Yang, H., and Yamamoto, A. Bert4fca: A method for bipartite link prediction using formal concept analysis and bert. Plos one, 19 0 (6): 0 e0304858, 2024
2024
-
[30]
J., Espinosa Zarlenga, M., and Jamnik, M
Raman, N. J., Espinosa Zarlenga, M., and Jamnik, M. Understanding inter-concept relationships in concept-based models. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, p...
2024
-
[31]
Using fca for encoding closure operators into neural networks
Rudolph, S. Using fca for encoding closure operators into neural networks. In International Conference on Conceptual Structures, pp.\ 321--332. Springer, 2007
2007
-
[32]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. ImageNet Large Scale Visual Recognition Challenge . International Journal of Computer Vision (IJCV), 115 0 (3): 0 211--252, 2015. doi:10.1007/s11263-015-0816-y
-
[33]
Sarkar, A., Vijaykeerthy, D., Sarkar, A., and Balasubramanian, V. N. A framework for learning ante-hoc explainable models via concepts. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 10276--10285, 2022
2022
-
[34]
Sawada, Y. and Nakamura, K. Concept bottleneck model with additional unsupervised concepts. IEEE Access, 10: 0 41758--41765, 2022. doi:10.1109/ACCESS.2022.3167702
-
[35]
Understanding and enhancing robustness of concept-based models
Sinha, S., Huai, M., Sun, J., and Zhang, A. Understanding and enhancing robustness of concept-based models. In AAAI Conference on Artificial Intelligence, 2022. URL https://api.semanticscholar.org/CorpusID:254069697
2022
-
[36]
Vlg-cbm: Training concept bottleneck models with vision-language guidance
Srivastava, D., Yan, G., and Weng, T.-W. Vlg-cbm: Training concept bottleneck models with vision-language guidance. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 79057--79094. Curran Associates, Inc., 2024. URL https://proceedings.neuri...
2024
-
[37]
Sun, A., Yuan, Y., Ma, P., and Wang, S. Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning. arXiv preprint arXiv:2402.05945, 2024
arXiv 2024
-
[38]
A., Fern \'a ndez, G., and Doeller, C
Theves, S., Neville, D. A., Fern \'a ndez, G., and Doeller, C. F. Learning and representation of hierarchical concepts in hippocampus and prefrontal cortex. Journal of Neuroscience, 41 0 (36): 0 7675--7686, 2021
2021
-
[39]
Tishby, N. and Zaslavsky, N. Deep learning and the information bottleneck principle, 2015. URL https://arxiv.org/abs/1503.02406
Pith/arXiv arXiv 2015
-
[40]
Troy, A. D., Zhang, G.-Q., and Tian, Y. Faster concept analysis. In Proceedings of the 15th International Conference on Conceptual Structures: Knowledge Architectures for Smart Applications, ICCS '07, pp.\ 206–219, Berlin, Heidelberg, 2007. Springer-Verlag. ISBN 9783540736806. doi:10.1007/978-3-540-73681-3_16. URL https://doi.org/10.1007/978-3-540-73681-3_16
-
[41]
Stochastic concept bottleneck models
Vandenhirtz, M., Laguna, S., Marcinkevi c s, R., and Vogt, J. Stochastic concept bottleneck models. Advances in Neural Information Processing Systems, 37: 0 51787--51810, 2024 a
2024
-
[42]
Stochastic concept bottleneck models
Vandenhirtz, M., Laguna, S., Marcinkevi c s, R., and Vogt, J. Stochastic concept bottleneck models. Advances in Neural Information Processing Systems, 37: 0 51787--51810, 2024 b
2024
-
[43]
Order-embeddings of images and language
Vendrov, I., Kiros, R., Fidler, S., and Urtasun, R. Order-embeddings of images and language. arXiv preprint arXiv:1511.06361, 2015
Pith/arXiv arXiv 2015
-
[44]
Lampert, Bernt Schiele, and Zeynep Akata
Xian, Y., Lampert, C. H., Schiele, B., and Akata, Z. Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly. IEEE Transactions on Pattern Analysis &; Machine Intelligence, 41 0 (09): 0 2251--2265, sep 2019. ISSN 1939-3539. doi:10.1109/TPAMI.2018.2857768
-
[45]
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification
Yang, Y., Panagopoulou, A., Zhou, S., Jin, D., Callison-Burch, C., and Yatskar, M. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 19187--19197, 2023
2023
-
[46]
Post-hoc concept bottleneck models
Yuksekgonul, M., Wang, M., and Zou, J. Post-hoc concept bottleneck models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=nA5AZ8CEyow
2023
-
[47]
E., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Diligenti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., Lio, P., and Jamnik, M
Zarlenga, M. E., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Diligenti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., Lio, P., and Jamnik, M. Concept embedding models. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=HXCPA2GXf_
2022
-
[48]
Zeiler, M. D. and Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, pp.\ 818--833. Springer, 2014
2014
-
[49]
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM, 64 0 (3): 0 107–115, February 2021. ISSN 0001-0782. doi:10.1145/3446776. URL https://doi.org/10.1145/3446776
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.