LLM-Guided ANN Index Optimization for Human-Object Interaction Retrieval
Pith reviewed 2026-06-28 06:08 UTC · model grok-4.3
The pith
An LLM agent that conditions proposals on full optimization history outperforms traditional tuners on coupled ANN parameters by 33 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
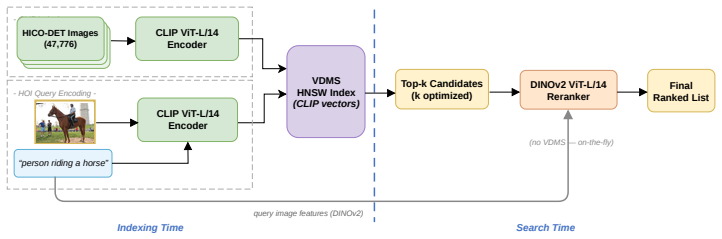
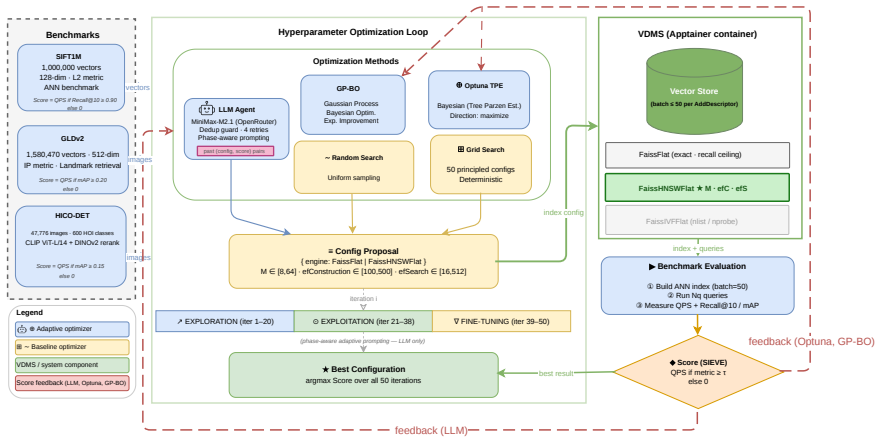
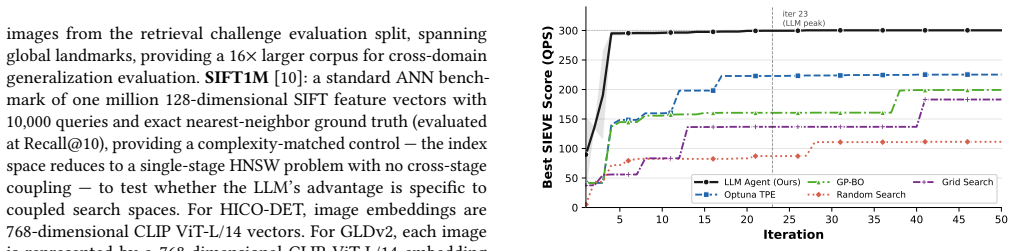
The phase-aware LLM agent conditions each proposal on its full optimization history to navigate the coupled parameter space across partitioned stages of exploration, exploitation, and fine-tuning, outperforming Optuna TPE by 33.3 percent and VDTuner by 34.2 percent under the SIEVE metric on HICO-DET while delivering a 15.3 times throughput gain over UniIR; the advantage grows with the degree of parameter coupling and transfers without modification to other vector database systems.
What carries the argument
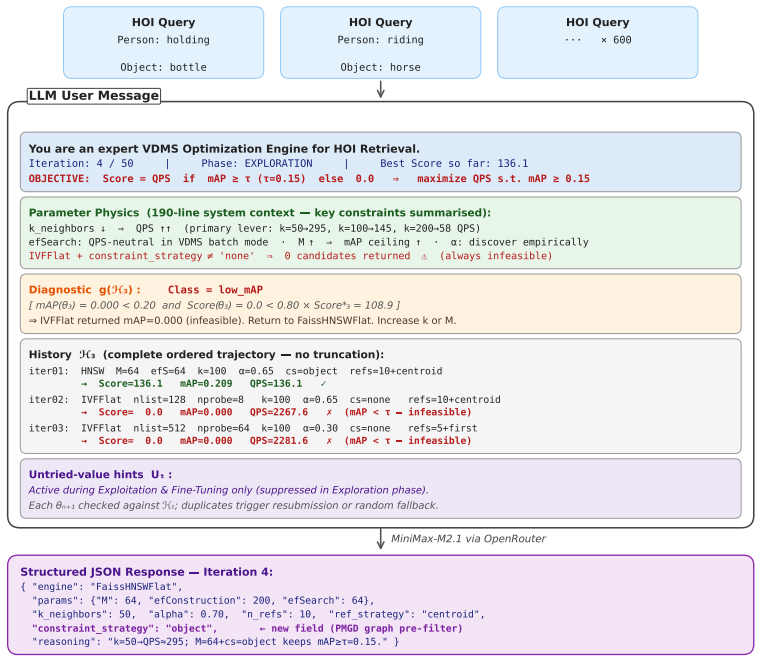
The phase-aware LLM agent that conditions each proposal on its full optimization history across exploration, exploitation, and fine-tuning stages.
If this is right
- The agent's performance margin over conventional tuners increases directly with the degree of parameter coupling.
- On benchmarks with moderate or near-independent parameters the agent converges to within a few percent of TPE and VDTuner.
- The same optimizer ranks first on three datasets when transferred to the Milvus vector database without any code changes.
- A 15.3 times throughput improvement over the UniIR baseline is realized on the high-coupling HICO-DET task.
Where Pith is reading between the lines
- The same history-conditioning approach could be tested on other optimization tasks whose parameters are known to interact, such as neural architecture search or database query planning.
- Explicitly modeling the coupling graph among parameters might further reduce the number of trials needed.
- The method's transferability across vector database platforms suggests it could serve as a portable layer above multiple back-end storage engines.
Load-bearing premise
An LLM can use the complete history of prior optimization attempts to generate better next proposals inside a space of tightly coupled parameters that has been split into sequential phases.
What would settle it
Re-running the HICO-DET optimization with an LLM that receives no history of previous trials and checking whether the 33 percent margin over TPE vanishes.
Figures

read the original abstract
Retrieval systems underpin modern AI applications -- spanning visual search, recommendation engines, and multi-modal question answering. Modern multi-stage retrieval systems require the joint optimization of highly coupled parameters, yet traditional hyperparameter optimization (HPO) methods -- including Tree-structured Parzen Estimators (TPE) and Gaussian Process Bayesian Optimization -- rely on an independence assumption that fundamentally prevents them from navigating these coupled configuration spaces. We address this limitation with a phase-aware large language model (LLM) agent that conditions each proposal on its full optimization history, navigating the coupled parameter space across phase-partitioned exploration, exploitation, and fine-tuning stages. Evaluated on the HICO-DET human-object interaction retrieval benchmark using Intel VDMS (Visual Data Management System), our agent outperforms Optuna TPE by +33.3% and VDTuner by +34.2% under SIEVE (Safeguarded Index Evaluation of Vector-search Efficiency, a quality-constrained throughput metric), delivering a 15.3x throughput gain over UniIR. Validation across three benchmarks confirms that the agent's advantage grows with the degree of parameter coupling: +33.3% on HICO-DET (high coupling), methods converge within 1% on GLDv2 (moderate coupling) and within 3.6% on SIFT1M (near-independent control). Cross-system validation on Milvus confirms the optimizer ranks first on all three datasets without modification, demonstrating transferability across vector database management system (VDBMS) platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a phase-aware LLM agent for joint optimization of coupled parameters in ANN indexes for human-object interaction retrieval. The agent conditions proposals on full optimization history across partitioned exploration, exploitation, and fine-tuning stages. On HICO-DET with Intel VDMS, it reports +33.3% over Optuna TPE and +34.2% over VDTuner under the SIEVE quality-constrained throughput metric, plus a 15.3x gain over UniIR. Gains scale with coupling degree across HICO-DET (high), GLDv2 (moderate), and SIFT1M (low), and the optimizer transfers to Milvus without modification.
Significance. If the empirical comparisons hold after correction, the work would indicate that LLM agents can effectively navigate history-dependent optimization in coupled retrieval parameter spaces where gains increase with coupling complexity. The cross-benchmark scaling result and platform transferability without retraining are strengths that could inform practical HPO for VDBMS. The significance is reduced by the need to correct the baseline characterization before the performance gap can be confidently attributed to the proposed mechanism.
major comments (1)
- [Abstract] Abstract: The claim that TPE (and GPBO) 'rely on an independence assumption that fundamentally prevents them from navigating these coupled configuration spaces' is incorrect. TPE is a Tree-structured Parzen Estimator whose tree explicitly models conditional dependencies; it does not assume independence. This error is load-bearing for the motivation and for interpreting the +33.3% gap as evidence that history conditioning overcomes a limitation absent in the baseline. The method section must provide an accurate technical comparison of the LLM agent's history conditioning versus TPE's tree structure on the actual HICO-DET parameter space.
minor comments (2)
- [Abstract] Abstract: No error bars, number of runs, or statistical tests are reported for the stated percentage gains, making it impossible to assess whether the +33.3% and +34.2% differences are reliable.
- [Abstract] Abstract: The precise definition, quality threshold, and computation of the SIEVE metric are not supplied, although it is central to all quantitative claims.
Simulated Author's Rebuttal
We thank the referee for identifying the inaccuracy in our characterization of TPE. We agree the claim is incorrect and will revise the manuscript accordingly while preserving the empirical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that TPE (and GPBO) 'rely on an independence assumption that fundamentally prevents them from navigating these coupled configuration spaces' is incorrect. TPE is a Tree-structured Parzen Estimator whose tree explicitly models conditional dependencies; it does not assume independence. This error is load-bearing for the motivation and for interpreting the +33.3% gap as evidence that history conditioning overcomes a limitation absent in the baseline. The method section must provide an accurate technical comparison of the LLM agent's history conditioning versus TPE's tree structure on the actual HICO-DET parameter space.
Authors: We acknowledge the error in the abstract. TPE's tree structure does model conditional dependencies, contrary to our stated claim. We will revise the abstract to remove the incorrect independence-assumption phrasing and add a new subsection in Methods that provides a technical comparison of the LLM agent's full-history conditioning mechanism versus TPE's tree-structured Parzen estimator on the specific HICO-DET parameter space (including how each handles the coupled index parameters). The empirical results on SIEVE and cross-benchmark scaling will be presented without relying on the flawed motivation. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmark comparisons
full rationale
The paper advances an LLM agent for phase-partitioned HPO and supports its claims solely through direct empirical measurements of throughput and SIEVE scores on HICO-DET, GLDv2, and SIFT1M against named external baselines (Optuna TPE, VDTuner, UniIR). No equations, fitted parameters, or predictions are defined in terms of the target result; the central motivation about TPE limitations is presented as a premise rather than derived from self-citation or self-definition. The reported gains are therefore independent of any reduction to the paper's own inputs and remain falsifiable by replication on the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akiba, S
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019. 12
2019
-
[2]
Aumüller, E
M. Aumüller, E. Bernhardsson, and A. Faithfull. ANN-Benchmarks: A bench- marking tool for approximate nearest neighbor algorithms.Information Systems, 87:101374, 2020
2020
-
[3]
Bergstra and Y
J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13:281–305, 2012
2012
-
[4]
T. J. Boerner, S. Deems, T. R. Furlani, S. L. Knuth, and J. Towns. ACCESS: Advanc- ing innovation: NSF’s advanced cyberinfrastructure coordination ecosystem: Services & support. InPractice and Experience in Advanced Research Computing (PEARC ’23), pages 173–176, Portland, OR, USA, 2023. ACM
2023
-
[5]
Bruch, S
S. Bruch, S. Gai, and A. Ingber. An analysis of fusion functions for hybrid retrieval. ACM Transactions on Information Systems, 42(1):20:1–20:35, 2024
2024
-
[6]
Y.-W. Chao, Y. Liu, X. Liu, H. Zeng, and J. Deng. Learning to detect human-object interactions. InProceedings of the IEEE Winter Conference on Applications of Computer Vision (W ACV), pages 381–389, 2018
2018
-
[7]
X. Chen, H. Fang, T.-Y. Lin, R. Vedantam, S. Gupta, P. Dollár, and C. L. Zitnick. Mi- crosoft COCO captions: Data collection and evaluation server. arXiv:1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Feurer, A
M. Feurer, A. Klein, K. Eggensperger, J. T. Springenberg, M. Blum, and F. Hut- ter. Efficient and robust automated machine learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 28, pages 2962–2970, 2015
2015
-
[9]
Giannakouris and I
V. Giannakouris and I. Trummer. 𝜆-tune: Harnessing large language models for automated database system tuning.Proceedings of the ACM on Management of Data, 3(1), 2025
2025
-
[10]
Jégou, M
H. Jégou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1):117– 128, 2011
2011
-
[11]
Johnson, M
J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[12]
Kilickaya and A
M. Kilickaya and A. W. Smeulders. Structured visual search via composition- aware learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), pages 1700–1709, 2021
2021
-
[13]
B. Kim, J. Lee, J. Kang, E.-S. Kim, and H. J. Kim. HOTR: End-to-end human- object interaction detection with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 74–83, 2021
2021
-
[14]
J. Lao, Y. Wang, Y. Li, J. Wang, Y. Zhang, Z. Cheng, W. Chen, M. Tang, and J. Wang. GPTuner: A manual-reading database tuning system via GPT-guided Bayesian optimization.Proceedings of the VLDB Endowment, 17(8):1939–1952, 2024
1939
-
[15]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(185):1–52, 2018
2018
-
[16]
Z. Li, X. Li, C. Ding, and X. Xu. Disentangled pre-training for human-object interaction detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
- [17]
-
[18]
Y. Liu, Y. Zhang, J. Cai, X. Jiang, Y. Hu, J. Yao, Y. Wang, and W. Xie. LamRA: Large multimodal model as your advanced retrieval assistant. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4025, 2025
2025
-
[19]
Y. A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neigh- bor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4):824–836, 2020
2020
-
[20]
C. D. Manning, P. Raghavan, and H. Schütze.Introduction to Information Retrieval. Cambridge University Press, 2008
2008
-
[21]
S. Ning, L. Qiu, Y. Liu, and X. He. HOICLIP: Efficient knowledge transfer for HOI detection with vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23507–23517, 2023
2023
-
[22]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, et al. DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
2024
-
[23]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, et al. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021
2021
-
[24]
Remis and C
L. Remis and C. W. Lacewell. Using VDMS to index and search 100M images. Proceedings of the VLDB Endowment, 14(12):3240–3252, 2021
2021
-
[25]
H. V. Simhadri, G. Williams, M. Aumüller, M. Douze, A. Babenko, D. Baranchuk, et al. Results of the NeurIPS’21 challenge on billion-scale approximate nearest neighbor search. InProceedings of the NeurIPS 2021 Competitions and Demon- strations Track, volume 176 ofProceedings of Machine Learning Research, pages 177–189. PMLR, 2022
2021
-
[26]
Snoek, H
J. Snoek, H. Larochelle, and R. P. Adams. Practical Bayesian optimization of machine learning algorithms. InAdvances in Neural Information Processing Systems (NeurIPS), volume 25, pages 2960–2968, 2012
2012
-
[27]
S. J. Subramanya, Devvrit, R. Kadekodi, R. Krishnaswamy, and H. V. Simhadri. DiskANN: Fast accurate billion-point nearest neighbor search on a single node. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[28]
J. Sun, G. Li, J. Pan, J. Wang, Y. Xie, R. Liu, and W. Nie. GaussDB-Vector: A large- scale persistent real-time vector database for LLM applications.Proceedings of the VLDB Endowment, 18(12):4951–4963, 2025
2025
-
[29]
Van Aken, A
D. Van Aken, A. Pavlo, G. J. Gordon, and B. Zhang. Automatic database man- agement system tuning through large-scale machine learning. InProceedings of the 2017 ACM International Conference on Management of Data (SIGMOD), pages 1009–1024, 2017
2017
-
[30]
J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, et al. Milvus: A purpose-built vector data management system. InProceedings of the 2021 International Conference on Management of Data (SIGMOD), pages 2614–2627, 2021
2021
-
[31]
C. Wei, Y. Chen, H. Chen, H. Hu, G. Zhang, J. Fu, A. Ritter, and W. Chen. UniIR: Training and benchmarking universal multimodal information retrievers. In Proceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[32]
Weyand, A
T. Weyand, A. Araujo, B. Cao, and J. Sim. Google Landmarks Dataset v2 — a large-scale benchmark for instance-level recognition and retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2575–2584, 2020
2020
-
[33]
C. Yang, X. Wang, Y. Lu, H. Liu, Q. V. Le, D. Zhou, and X. Chen. Large language models as optimizers. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[34]
T. Yang, W. Hu, W. Peng, Y. Li, J. Li, G. Wang, and X. Liu. VDTuner: Automated performance tuning for vector data management systems. InProceedings of the 40th IEEE International Conference on Data Engineering (ICDE), pages 4357–4369, 2024
2024
-
[35]
Young, A
P. Young, A. Lai, M. Hodosh, and J. Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.Transactions of the Association for Computational Linguistics, 2:67– 78, 2014
2014
-
[36]
Zhang, Y
A. Zhang, Y. Liao, S. Liu, M. Lu, Y. Wang, C. Gao, and X. Li. Mining the benefits of two-stage and one-stage HOI detection. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 17209–17220, 2021
2021
- [37]
-
[38]
Zhong, H
X. Zhong, H. Li, J. Jin, M. Yang, D. Chu, X. Wang, et al. VSAG: An optimized search framework for graph-based approximate nearest neighbor search.Proceedings of the VLDB Endowment, 18(12):5017–5030, 2025. 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.