LEVANTE-bench: Multi-Scale Comparison of VLMs to Children Using Cognitive Tasks (or, "Is Your VLM Smarter Than a 5th Grader?")
Pith reviewed 2026-06-28 06:36 UTC · model grok-4.3
The pith
Current vision-language models align only partially with children's cognitive abilities on reasoning and spatial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
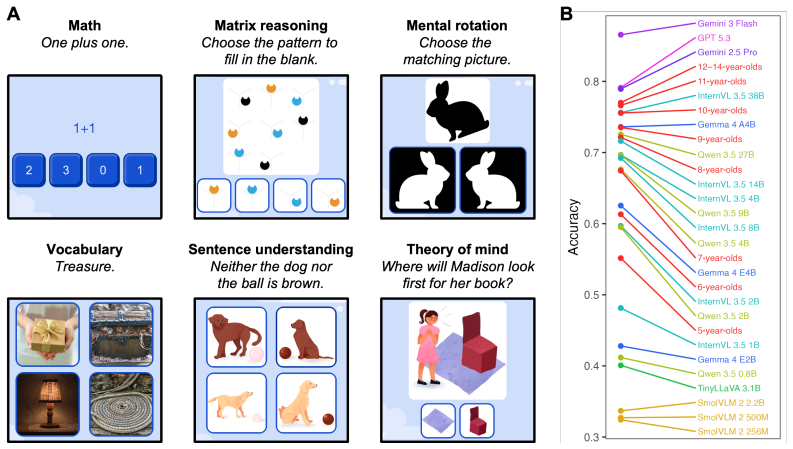
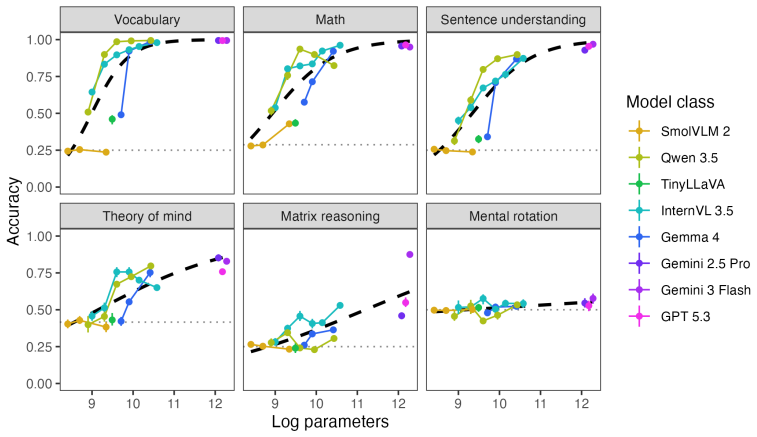
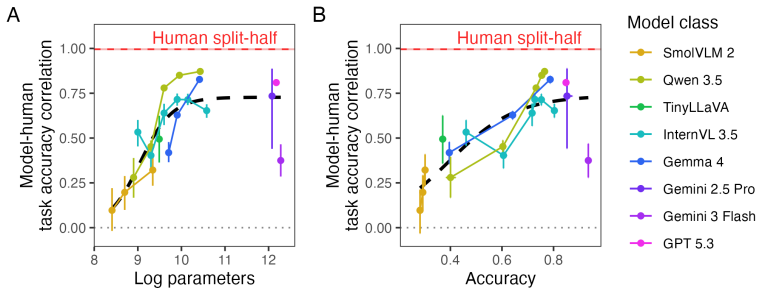
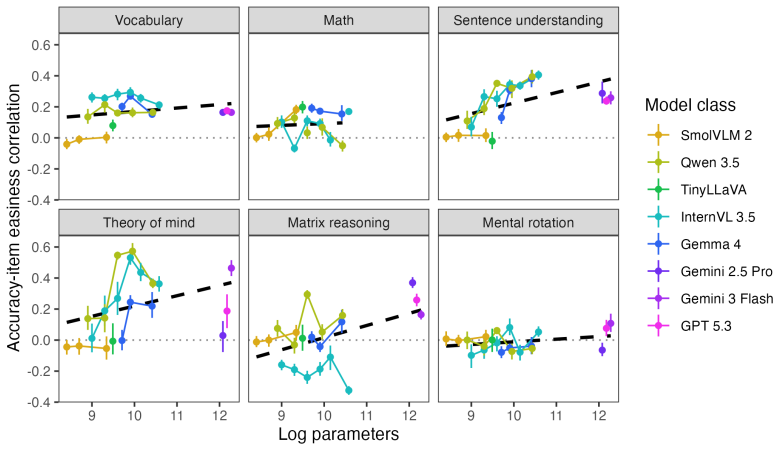
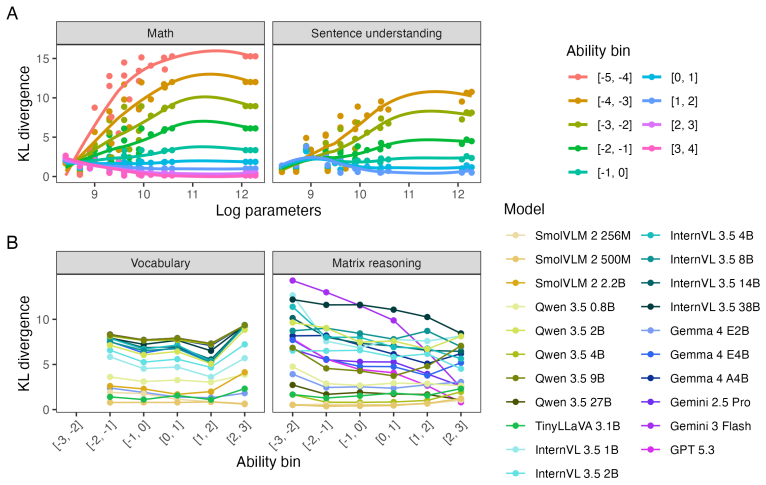
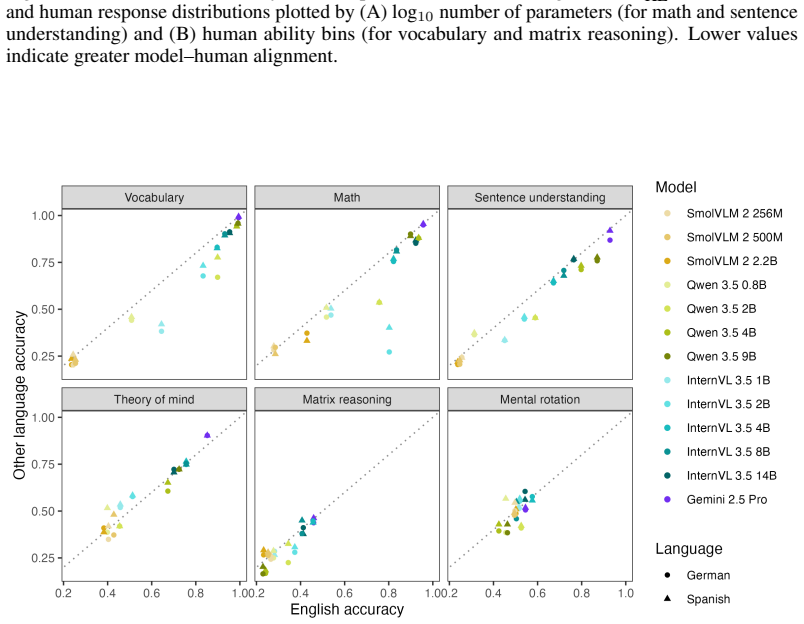
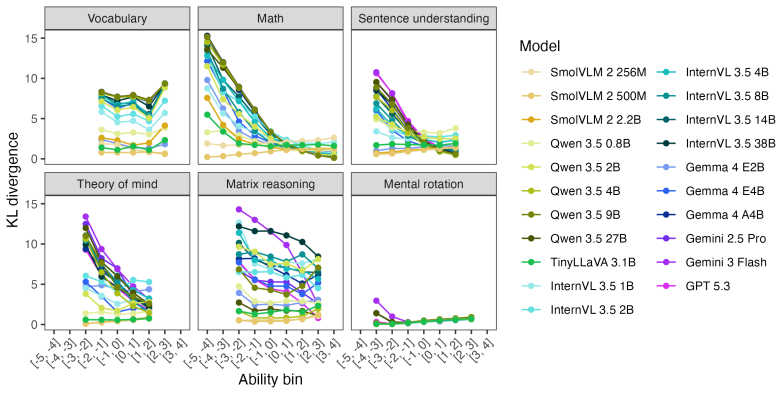
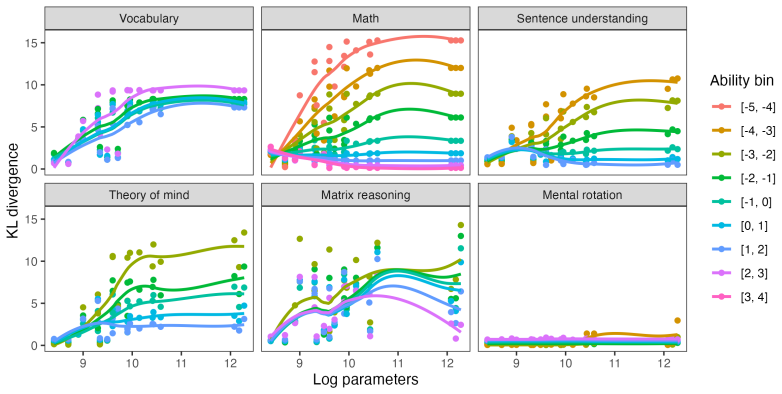
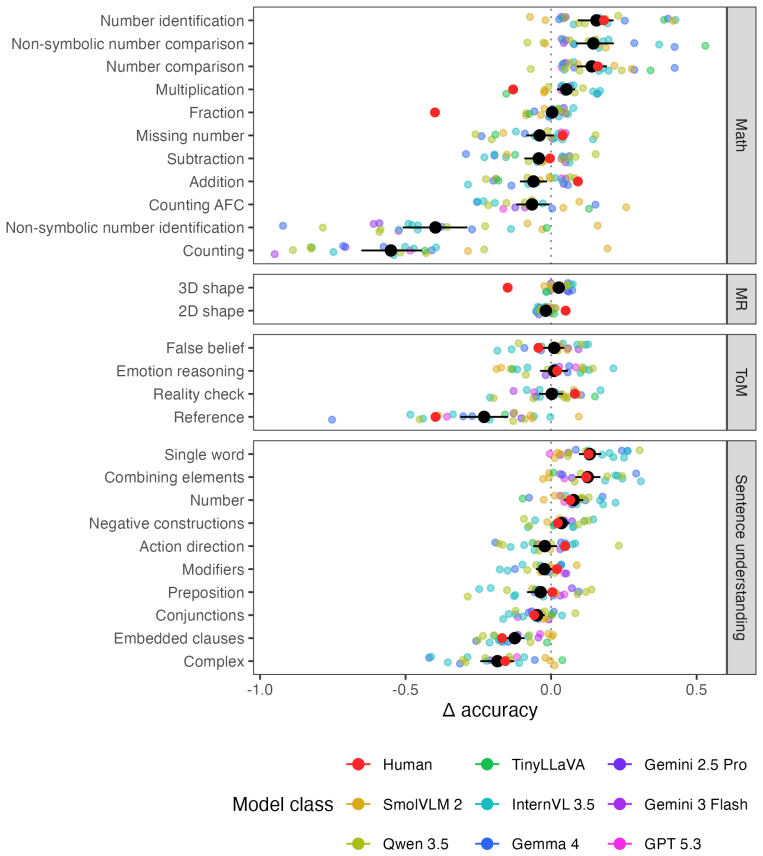
Applying the six LEVANTE tasks to VLMs and contrasting results against children's data across ages and countries reveals heterogeneous alignment: task- and item-level matches improve with model scale, error distribution matches fluctuate by task and can favor smaller models for younger children, and even top VLMs underperform on matrix reasoning and mental rotation.
What carries the argument
LEVANTE-bench, a multi-scale evaluation that scores VLMs on accuracy, task/item alignment, and error distribution match against children's trial-level responses from the six LEVANTE tasks.
Load-bearing premise
The six LEVANTE tasks and their data validly measure children's cognitive development in a form that permits direct comparison to VLM outputs.
What would settle it
A result showing that the largest VLMs produce error distributions statistically identical to those of children on every task and age band would undermine the partial-alignment conclusion.
Figures
read the original abstract
Given the inherently multimodal nature of human experience, vision-language models (VLMs) hold substantial promise for modeling human cognition as it grows and develops with experience. Realizing their potential requires tools for comparing VLMs with human cognitive development across tasks, ages, and populations. We present LEVANTE-bench, a benchmark based on tasks and data from the Learning Variability Network (LEVANTE), which distributes open-source tasks and data measuring children's cognition across languages and cultures. In LEVANTE-bench, we systematically assess VLMs on six tasks, comparing their alignment with children aged 5-12 ($N$ = 1547) across three countries. We compare models at multiple scales, assessing their overall accuracy, their task- and item-level alignment with children, and how well they match children's trial-level error distributions. Alignment was heterogeneous across scales: at the level of tasks and items, more capable models aligned better with humans. However, match to human error distributions varied widely across tasks, and for several tasks, smaller models matched younger children's errors better. In addition, even the best-performing VLMs struggled on matrix reasoning and mental rotation tasks. Thus, current VLM architectures align only partially with the cognitive abilities of children.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEVANTE-bench, a benchmark based on six tasks and data from the LEVANTE network measuring children's cognition (N=1547, ages 5-12 across three countries). It evaluates VLMs of varying scales on overall accuracy, task- and item-level alignment with children, and match to children's trial-level error distributions. Results indicate heterogeneous alignment: larger models align better at task/item levels, error-distribution matches vary (with smaller models sometimes closer to younger children on some tasks), and even top VLMs struggle on matrix reasoning and mental rotation. The central claim is that current VLM architectures align only partially with children's cognitive abilities.
Significance. If the task equivalence holds, this provides a multi-country, multi-age empirical benchmark for VLM cognitive modeling using real developmental data, identifying specific gaps (e.g., abstract reasoning) that could guide VLM improvements toward more human-like capabilities. The open-source basis and scale comparisons are strengths for reproducibility in the field.
major comments (2)
- [Methods / Experimental Setup] The methods description provides no details on VLM prompting strategies, visual input handling, response scoring, or controls for interface differences (e.g., tokenization and sampling vs. children's developmental experience). This is load-bearing for the partial-alignment claim, as the abstract's heterogeneous results (better task/item match for larger models, variable error matches) cannot be interpreted without evidence that the six LEVANTE tasks isolate equivalent constructs across humans and models.
- [Results] The results on heterogeneous alignment (task/item vs. error-distribution matches) report no statistical tests, error bars, or scale controls, making it impossible to assess whether observed patterns (e.g., smaller models matching younger children on some tasks) are reliable or confounded by model size and prompting. This directly affects the central claim in the abstract.
minor comments (1)
- [Abstract] The abstract would benefit from naming the six specific LEVANTE tasks to allow readers to immediately contextualize the matrix reasoning and mental rotation struggles.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] The methods description provides no details on VLM prompting strategies, visual input handling, response scoring, or controls for interface differences (e.g., tokenization and sampling vs. children's developmental experience). This is load-bearing for the partial-alignment claim, as the abstract's heterogeneous results (better task/item match for larger models, variable error matches) cannot be interpreted without evidence that the six LEVANTE tasks isolate equivalent constructs across humans and models.
Authors: We agree that the Methods section requires substantially more detail to support interpretation of the alignment results. In the revised manuscript we will add a dedicated subsection describing: (i) the exact prompting templates and few-shot examples used for each of the six tasks, (ii) image preprocessing, resolution, and encoding procedures, (iii) the deterministic response-scoring rules applied to model outputs, and (iv) any explicit attempts to equate interface conditions (e.g., presentation order, feedback absence). We will also reference the LEVANTE network's published validation studies that establish construct equivalence between the tasks as administered to children and the cognitive constructs they target. revision: yes
-
Referee: [Results] The results on heterogeneous alignment (task/item vs. error-distribution matches) report no statistical tests, error bars, or scale controls, making it impossible to assess whether observed patterns (e.g., smaller models matching younger children on some tasks) are reliable or confounded by model size and prompting. This directly affects the central claim in the abstract.
Authors: We accept that the absence of statistical quantification weakens the evidential basis for the reported patterns. In the revision we will add: (a) correlation coefficients and associated p-values (or permutation tests) for all task- and item-level alignment metrics, (b) bootstrap or analytic error bars on the alignment figures, and (c) supplementary analyses that regress alignment scores on model scale while controlling for prompting variations. These additions will allow readers to evaluate the reliability of the heterogeneous alignment findings, including the observation that smaller models sometimes better matched younger children's error distributions. revision: yes
Circularity Check
No circularity; purely empirical benchmark against external dataset
full rationale
The paper reports direct empirical comparisons of VLM outputs to children's trial-level responses on six LEVANTE tasks (N=1547 across countries), computing accuracy, item-level alignment, and error-distribution matches without any derivations, equations, fitted parameters, or predictions that reduce to the inputs by construction. No self-citations are load-bearing for the central claims, and the LEVANTE data source is described as open-source and external. The analysis contains no self-definitional steps, uniqueness theorems, or ansatzes smuggled via citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cognitive science: The newest science of the artificial.Cognitive science, 4 (1):33–46, 1980
Herbert A Simon. Cognitive science: The newest science of the artificial.Cognitive science, 4 (1):33–46, 1980
1980
-
[2]
The MIT press, 1986
David E Rumelhart, James L McClelland, PDP Research Group, et al.Parallel distributed processing, volume 1: Explorations in the microstructure of cognition: Foundations. The MIT press, 1986
1986
-
[3]
Emergent analogical reasoning in large language models.Nature Human Behaviour, 7(9):1526–1541, 2023
Taylor Webb, Keith J Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models.Nature Human Behaviour, 7(9):1526–1541, 2023
2023
-
[4]
Using cognitive psychology to understand GPT-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
Marcel Binz and Eric Schulz. Using cognitive psychology to understand GPT-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
2023
-
[5]
Cognitive modeling using artificial intelligence
Michael C Frank and Noah D Goodman. Cognitive modeling using artificial intelligence. Annual Review of Psychology, 77, 2025
2025
-
[6]
Ellie Pavlick. Symbols and grounding in large language models.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 381(2251), 2023. ISSN 1471-2962. doi: 10.1098/rsta.2022.0041. URL http://dx.doi.org/10.1098/rsta. 2022.0041
-
[7]
Bridging the data gap between children and large language models.Trends in Cognitive Sciences, 27(11):990–992, 2023
Michael C Frank. Bridging the data gap between children and large language models.Trends in Cognitive Sciences, 27(11):990–992, 2023
2023
-
[8]
Findings of the BabyLM challenge: Sample-efficient pretraining on developmentally plausible corpora
Alex Warstadt, Aaron Mueller, Leshem Choshen, Ethan Wilcox, Chengxu Zhuang, Juan Ciro, Rafael Mosquera, Bhargavi Paranjabe, Adina Williams, Tal Linzen, et al. Findings of the BabyLM challenge: Sample-efficient pretraining on developmentally plausible corpora. In Proceedings of the BabyLM Challenge at the 27th Conference on Computational Natural Language L...
2023
-
[9]
Fast and robust visual object recognition in young children.Science Advances, 11(27):eads6821, 2025
Vladislav Ayzenberg, Sukran Bahar Sener, Kylee Novick, and Stella F Lourenco. Fast and robust visual object recognition in young children.Science Advances, 11(27):eads6821, 2025
2025
-
[10]
The developmental trajectory of object recognition robustness: Children are like small adults but unlike big deep neural networks
Lukas S Huber, Robert Geirhos, and Felix A Wichmann. The developmental trajectory of object recognition robustness: Children are like small adults but unlike big deep neural networks. Journal of vision, 23(7):4–4, 2023. 10
2023
-
[11]
Zero-shot World Models Are Developmentally Efficient Learners
Khai Loong Aw, Klemen Kotar, Wanhee Lee, Seungwoo Kim, Khaled Jedoui, Rahul Venkatesh, Lilian Naing Chen, Michael C Frank, and Daniel LK Yamins. Zero-shot world models are developmentally efficient learners, 2026. URLhttps://arxiv.org/abs/2604.10333
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
George Kachergis, Fionnuala O’Reilly, Mika Braginsky, Xingyao Xiao, Amy Lightbody, KA Shannon, Zachary Watson, Lijin Zhang, Rebecca Zhu, AB Abutto, et al. Creation and validation of the LEV ANTE core tasks: Internationalized measures of learning and development for children ages 5-12 years, 2025. URL https://doi.org/10.31234/osf.io/r4dhw_v1
-
[13]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[14]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[15]
Visual cognition in multimodal large language models.Nature Machine Intelligence, 7(1):96–106, 2025
Luca M Schulze Buschoff, Elif Akata, Matthias Bethge, and Eric Schulz. Visual cognition in multimodal large language models.Nature Machine Intelligence, 7(1):96–106, 2025
2025
-
[16]
Grounded language acquisition through the eyes and ears of a single child.Science, 383(6682):504–511, 2024
Wai Keen V ong, Wentao Wang, A Emin Orhan, and Brenden M Lake. Grounded language acquisition through the eyes and ears of a single child.Science, 383(6682):504–511, 2024
2024
-
[17]
Wai Keen V ong and Brenden M Lake. On the robustness of modeling grounded word learning through a child’s egocentric input.arXiv preprint arXiv:2507.14749, 2025
-
[18]
BabyVLM: Data-efficient pretraining of vlms inspired by infant learning
Shengao Wang, Arjun Chandra, Aoming Liu, Venkatesh Saligrama, and Boqing Gong. BabyVLM: Data-efficient pretraining of vlms inspired by infant learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1380–1390, 2025
2025
-
[19]
Shengao Wang, Wenqi Wang, Zecheng Wang, Max Whitton, Michael Wakeham, Arjun Chandra, Joey Huang, Pengyue Zhu, Helen Chen, David Li, et al. BabyVLM-V2: Toward develop- mentally grounded pretraining and benchmarking of vision foundation models.arXiv preprint arXiv:2512.10932, 2025
-
[20]
Looking while listening.Language acquisition and language disorders, pages 97–135, 2008
Anne Fernald, Renate Zangl, Ana Luz Portillo, and Virginia A Marchman. Looking while listening.Language acquisition and language disorders, pages 97–135, 2008
2008
-
[21]
Baby steps in evaluating the capacities of large language models.Nature Reviews Psychology, 2(8):451–452, 2023
Michael C Frank. Baby steps in evaluating the capacities of large language models.Nature Reviews Psychology, 2(8):451–452, 2023
2023
-
[22]
MIT press, 1996
Jeffrey L Elman.Rethinking innateness: A connectionist perspective on development, volume 10. MIT press, 1996
1996
-
[23]
Innateness is (still) an orienting principle for language development, 2026
Leher Singh, Marisa Casillas, Shanley Allen, Michael Frank, and Caroline Rowland. Innateness is (still) an orienting principle for language development, 2026. URL https://osf.io/ preprints/psyarxiv/ykz8j_v1
2026
- [24]
-
[25]
Tsaftaris
Ilias Stogiannidis, Steven McDonagh, and Sotirios A. Tsaftaris. Mind the gap: Benchmarking spatial reasoning in vision-language models, 2025. URL https://arxiv.org/abs/2503. 19707
2025
-
[26]
Hawkins, Nuno Vasconcelos, Tal Golan, Dezhi Luo, and Hokin Deng
Yijiang Li, Qingying Gao, Tianwei Zhao, Bingyang Wang, Haoran Sun, Haiyun Lyu, Robert D. Hawkins, Nuno Vasconcelos, Tal Golan, Dezhi Luo, and Hokin Deng. Core knowledge deficits in multi-modal language models, 2025. URLhttps://arxiv.org/abs/2410.10855
-
[27]
BabyVision: Visual reasoning beyond language, 2026
Liang Chen, Weichu Xie, Yiyan Liang, Hongfeng He, Hans Zhao, Zhibo Yang, Zhiqi Huang, Haoning Wu, Haoyu Lu, Y charles, Yiping Bao, Yuantao Fan, Guopeng Li, Haiyang Shen, Xuanzhong Chen, Wendong Xu, Shuzheng Si, Zefan Cai, Wenhao Chai, Ziqi Huang, Fangfu Liu, Tianyu Liu, Baobao Chang, Xiaobo Hu, Kaiyuan Chen, Yixin Ren, Yang Liu, Yuan Gong, and Kuan Li. Ba...
-
[28]
Alvin Wei Ming Tan, Jane Yang, Tarun Sepuri, Khai Loong Aw, Robert Z Sparks, Zi Yin, Virginia A Marchman, Michael C Frank, and Bria Long. Assessing the alignment between infants’ visual and linguistic experience using multimodal language models.arXiv preprint arXiv:2511.18824, 2025
-
[29]
KiV A: Kid-inspired visual analogies for testing large multimodal models, 2025
Eunice Yiu, Maan Qraitem, Anisa Noor Majhi, Charlie Wong, Yutong Bai, Shiry Ginosar, Alison Gopnik, and Kate Saenko. KiV A: Kid-inspired visual analogies for testing large multimodal models, 2025. URLhttps://arxiv.org/abs/2407.17773
-
[30]
Over- reliance on English hinders cognitive science.Trends in cognitive sciences, 26(12):1153–1170, 2022
Damián E Blasi, Joseph Henrich, Evangelia Adamou, David Kemmerer, and Asifa Majid. Over- reliance on English hinders cognitive science.Trends in cognitive sciences, 26(12):1153–1170, 2022
2022
-
[31]
DevBench: A multimodal developmental benchmark for language learning
Alvin Wei Ming Tan, Sunny Yu, Bria Long, Wanjing Anya Ma, Tonya Murray, Rebecca D Silverman, Jason D Yeatman, and Michael C Frank. DevBench: A multimodal developmental benchmark for language learning. InAdvances in Neural Information Processing Systems, volume 37, pages 77445–77467, Vancouver, BC, January 2025
2025
-
[32]
Fantastic bugs and where to find them in ai benchmarks, 2025
Sang Truong, Yuheng Tu, Michael Hardy, Anka Reuel, Zeyu Tang, Jirayu Burapacheep, Jonathan Perera, Chibuike Uwakwe, Ben Domingue, Nick Haber, and Sanmi Koyejo. Fantastic bugs and where to find them in ai benchmarks, 2025. URLhttps://arxiv.org/abs/2511. 16842
2025
-
[33]
Michael C Frank, Heidi A Baumgartner, Mika Braginsky, George Kachergis, Amy A Lightbody, Robert Z Sparks, Rebecca Zhu, Stephanie M Carlson, Sandra Graham, Sebastián J Lipina, et al. Learning Variability Network Exchange (LEV ANTE): A global framework for measuring children’s learning variability through collaborative data sharing.Child development, 96(6):...
2025
-
[34]
Yutong Xie, Qiaozhu Mei, Walter Yuan, and Matthew O Jackson. Using large language models to categorize strategic situations and decipher motivations behind human behaviors.Proceedings of the National Academy of Sciences, 122(35):e2512075122, 2025
2025
-
[35]
Predicting results of social science experiments using large language models.Preprint, 2024
Luke Hewitt, Ashwini Ashokkumar, Isaias Ghezae, and Robb Willer. Predicting results of social science experiments using large language models.Preprint, 2024
2024
-
[36]
Re-evaluating theory of mind evaluation in large language models.Philosophical Transactions of the Royal Society B: Biological Sciences, 380 (1932), 2025
Jennifer Hu, Felix Sosa, and Tomer Ullman. Re-evaluating theory of mind evaluation in large language models.Philosophical Transactions of the Royal Society B: Biological Sciences, 380 (1932), 2025
1932
-
[37]
AIPsychoBench: Understanding the psychometric differences between llms and humans.Topics in Cognitive Science, 18(2):e70041, 2026
Wei Xie, Zhenhua Wang, Shuoyoucheng Ma, Xiaobing Sun, Kai Chen, Enze Wang, Wei Liu, and Hanying Tong. AIPsychoBench: Understanding the psychometric differences between llms and humans.Topics in Cognitive Science, 18(2):e70041, 2026
2026
-
[38]
arXiv preprint arXiv:2306.09479 , year=
Ian R McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, et al. Inverse scaling: When bigger isn’t better.arXiv preprint arXiv:2306.09479, 2023
-
[39]
Development of cognitive intelligence in pre-trained language models
Raj Sanjay Shah, Khushi Bhardwaj, and Sashank Varma. Development of cognitive intelligence in pre-trained language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9632–9657, 2024
2024
-
[40]
Eunice Yiu, Eliza Kosoy, and Alison Gopnik. Transmission versus truth, imitation versus innovation: What children can do that large language and language-and-vision models cannot (yet).Perspectives on Psychological Science, 19(5):874–883, 2024
2024
-
[41]
Meta-analysis of theory-of-mind development: The truth about false belief.Child development, 72(3):655–684, 2001
Henry M Wellman, David Cross, and Julanne Watson. Meta-analysis of theory-of-mind development: The truth about false belief.Child development, 72(3):655–684, 2001
2001
-
[42]
Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(45):e2405460121, 2024
Michal Kosinski. Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(45):e2405460121, 2024. 12
2024
-
[43]
Benchmarking progress to infant-level physical reasoning in ai.Transactions on Machine Learning Research, 2022
Luca Weihs, Amanda Yuile, Renée Baillargeon, Cynthia Fisher, Gary Marcus, Roozbeh Mot- taghi, and Aniruddha Kembhavi. Benchmarking progress to infant-level physical reasoning in ai.Transactions on Machine Learning Research, 2022
2022
-
[44]
ModelVsBaby: A develop- mentally motivated benchmark of out-of-distribution object recognition.Preprint at https://osf
Saber Sheybani, LB Smith, Z Tiganj, SS Maini, and A Dendukuri. ModelVsBaby: A develop- mentally motivated benchmark of out-of-distribution object recognition.Preprint at https://osf. io/preprints/psyarxiv/83gae_v1, 2024
2024
-
[45]
MEWL: Few-shot multimodal word learning with referential uncertainty
Guangyuan Jiang, Manjie Xu, Shiji Xin, Wei Liang, Yujia Peng, Chi Zhang, and Yixin Zhu. MEWL: Few-shot multimodal word learning with referential uncertainty. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofP...
2023
-
[46]
The NIH Infant and Toddler Toolbox: A new standardized tool for assessing neurodevelopment in children ages 1–42 months.Child Development, 95(6):2252–2254, 2024
Richard Gershon, Miriam A Novack, and Aaron J Kaat. The NIH Infant and Toddler Toolbox: A new standardized tool for assessing neurodevelopment in children ages 1–42 months.Child Development, 95(6):2252–2254, 2024
2024
-
[47]
Psychology Press, 2013
Susan E Embretson and Steven P Reise.Item response theory for psychologists. Psychology Press, 2013
2013
-
[48]
A measurement science roadmap: From human assessment to ai evaluation, 2026
Sang Truong, Noah Goodman, Emma Brunskill, Ben Domingue, Nick Haber, and Sanmi Koyejo. A measurement science roadmap: From human assessment to ai evaluation, 2026
2026
-
[49]
Multiple group irt
R Darrell Bock and Michele F Zimowski. Multiple group irt. InHandbook of modern item response theory, pages 433–448. Springer, 1997
1997
-
[50]
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Bojie Li. Incompressible knowledge probes: Estimating black-box LLM parameter counts via factual capacity, 2026. URLhttps://arxiv.org/abs/2604.24827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
incompressible knowledge probes
Benjamin Sturgeon and Lawrence Chan. Sanity-checking “incompressible knowledge probes”, Apr 2026. URL https://www.lesswrong.com/posts/veFMEzDDyWaer2Sms/ sanity-checking-incompressible-knowledge-probes
2026
-
[52]
Questioning the survey responses of large language models.Advances in Neural Information Processing Systems, 37:45850–45878, 2024
Ricardo Dominguez-Olmedo, Moritz Hardt, and Celestine Mendler-Dünner. Questioning the survey responses of large language models.Advances in Neural Information Processing Systems, 37:45850–45878, 2024
2024
-
[53]
Observational scaling laws and the predictability of language model performance, October 2024
Yangjun Ruan, Chris J Maddison, and Tatsunori Hashimoto. Observational scaling laws and the predictability of language model performance, October 2024
2024
-
[54]
Large vision models can solve mental rotation problems, 2026
Sebastian Ray Mason, Anders Gjølbye, Phillip Chavarria Højbjerg, Lenka Tˇetková, and Lars Kai Hansen. Large vision models can solve mental rotation problems, 2026. URL https://arxiv. org/abs/2509.15271
-
[55]
Lvlm- count: Enhancing the counting ability of large vision-language models, 2026
Muhammad Fetrat Qharabagh, Mohammadreza Ghofrani, and Kimon Fountoulakis. Lvlm- count: Enhancing the counting ability of large vision-language models, 2026. URL https: //arxiv.org/abs/2412.00686
-
[56]
Quentin Garrido, Nicolas Ballas, Mahmoud Assran, Adrien Bardes, Laurent Najman, Michael Rabbat, Emmanuel Dupoux, and Yann LeCun. Intuitive physics understanding emerges from self-supervised pretraining on natural videos.arXiv preprint arXiv:2502.11831, 2025
-
[57]
Jennifer Hu and Michael C Frank. Auxiliary task demands mask the capabilities of smaller language models.arXiv preprint arXiv:2404.02418, 2024
-
[58]
What can language models tell us about human cognition? Current Directions in Psychological Science, 33(3):181–189, 2024
Louise Connell and Dermot Lynott. What can language models tell us about human cognition? Current Directions in Psychological Science, 33(3):181–189, 2024
2024
-
[59]
How can deep neural networks inform theory in psychological science?Current directions in psychological science, 33(5):325–333, 2024
Sam Whitman McGrath, Jacob Russin, Ellie Pavlick, and Roman Feiman. How can deep neural networks inform theory in psychological science?Current directions in psychological science, 33(5):325–333, 2024. 13
2024
-
[60]
You are a visual vocabulary expert
Alex Warstadt, Leshem Choshen, Aaron Mueller, Adina Williams, Ethan Wilcox, and Chengxu Zhuang. Call for papers—The BabyLM challenge: Sample-efficient pretraining on a develop- mentally plausible corpus.arXiv preprint arXiv:2301.11796, 2023. 14 A Prompt sensitivity analysis We conducted a systematic exploration of prompt design across all six tasks and mu...
-
[61]
Extended reasoning consumed the token budget without producing a parseable answer
CoT hurts small models.For sub-2B models, chain-of-thought instructions reduced both accuracy and parse rate on vocabulary ( −23.5 pp), sentence understanding ( −10.1 pp), and matrix reasoning (−7.6 pp). Extended reasoning consumed the token budget without producing a parseable answer
-
[62]
Similarly, the describe-first strategy that helped Qwen 2B on sentence understanding (+13.1 pp) was not effective for the 0.8B variant
Prompt gains are model-specific.The expert system prompt that boosted InternVL 8B on matrix reasoning by +12.7 ppdecreasedInternVL 2B accuracy by −20.3 pp on the same task. Similarly, the describe-first strategy that helped Qwen 2B on sentence understanding (+13.1 pp) was not effective for the 0.8B variant
-
[63]
The apparent best result (62.7% via self-consistency on Qwen2.5-VL-3B) was not significant under a bias-aware null model (p≈0.183)
Mental rotation resists prompting.Across Qwen 0.8B, InternVL 2B, InternVL 8B, and three spatial fine-tuned models (SpaceThinker, SpaceOm, SpatialThinker), no prompt strategy reliably exceeded chance after controlling for position bias via answer-permutation debiasing. The apparent best result (62.7% via self-consistency on Qwen2.5-VL-3B) was not significa...
-
[64]
Lower values indicate greater model–human alignment
Spatial fine-tuning does not help.Three models fine-tuned for spatial reasoning (Space- Thinker, SpaceOm, SpatialThinker-Oxford) all scored 59.0% with the baseline elimination 15 Figure 7: DKL between model and human response distributions plotted by log 10 number of parameters for all tasks. Lower values indicate greater model–human alignment. prompt—ide...
-
[65]
In sentence understanding (0.8B), combining all phases yielded 35.4% vs
Stacking phases has diminishing or negative returns.Full-stack combinations often underperformed the best single phase. In sentence understanding (0.8B), combining all phases yielded 35.4% vs. 43.4% for the structural stack alone. In vocabulary, the full stack was the exception that improved over individual phases (+12.4 pp), driven by synergistic interac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.