BRepCLIP: Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding
Pith reviewed 2026-06-28 05:58 UTC · model grok-4.3
The pith
BRepCLIP produces embeddings from native CAD boundary representations that align with images and text through contrastive pretraining on tokenized faces and edges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BRepCLIP models each CAD object as a sequence of face and edge tokens equipped with discrete vocabularies for surfaces and curves plus spatial and semantic descriptors, feeds the sequence through a transformer encoder to obtain a global embedding, and aligns that embedding to CLIP image and text spaces via a joint contrastive objective, yielding more discriminative representations than point-based baselines on retrieval and classification tasks.
What carries the argument
A transformer encoder that aggregates tokenized BRep faces and edges into a global embedding aligned contrastively to CLIP's image and text encoders.
If this is right
- Top-1 retrieval accuracy rises by 40.4 percent on ABC, 22.0 percent on CADParser, and 23.9 percent on Automate relative to OpenShape.
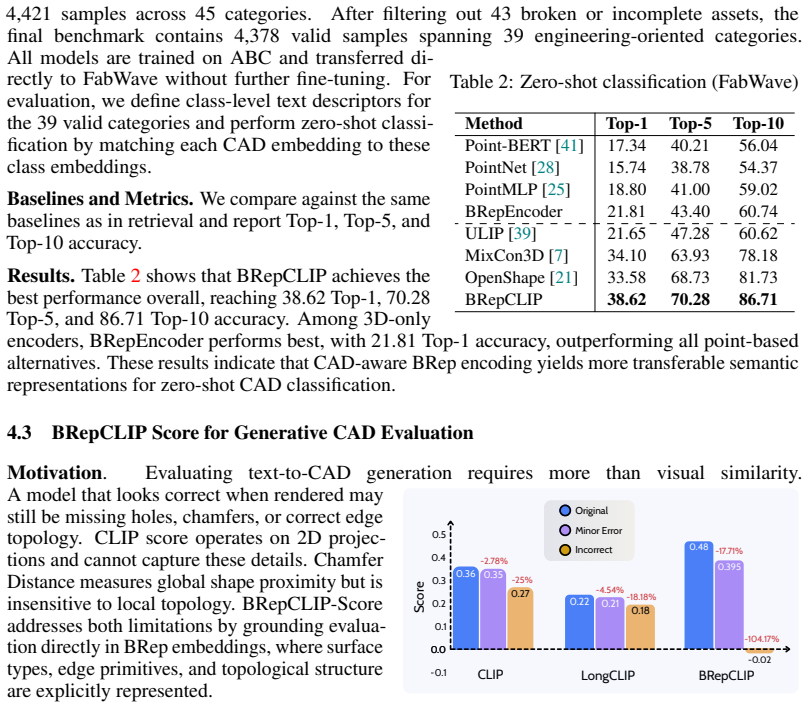
- Zero-shot classification Top-1 score on FabWave rises by 15 percent.
- The learned embeddings serve as a CAD-aware similarity metric for scoring text- and image-conditioned CAD generation outputs.
Where Pith is reading between the lines
- Design tools could use the same embeddings to suggest similar parts during modeling without manual feature extraction.
- The same tokenization scheme might support fine-tuning for other downstream CAD tasks such as segmentation or parameter prediction.
- If the alignment generalizes, BRep-based pretraining could become a standard step before applying large language models to engineering documents.
Load-bearing premise
That discrete vocabularies for surfaces and curves together with spatial and semantic descriptors are enough for a standard transformer to produce embeddings that align meaningfully with CLIP across different CAD collections.
What would settle it
A point-cloud or mesh method trained on the same CAD datasets that matches or exceeds the reported Top-1 retrieval gains of 40.4 percent on ABC, 22.0 percent on CADParser, and 23.9 percent on Automate.
Figures







read the original abstract
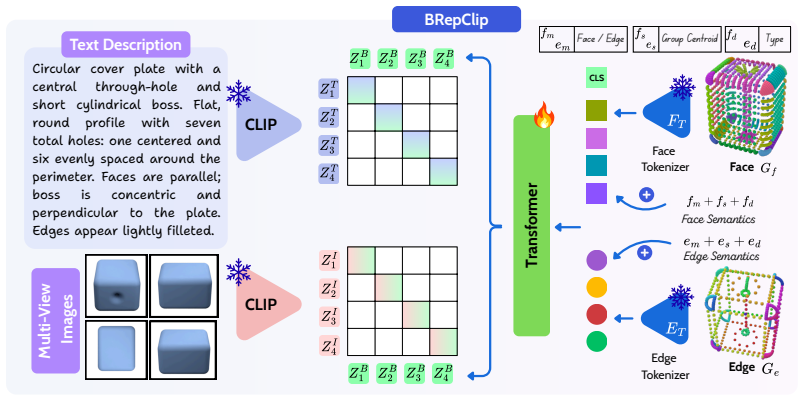
Learning representations of CAD models is a largely open problem. While 3D representation learning has flourished around point clouds and meshes, the native format of CAD - boundary representations BReps, which encodes exact parametric surfaces, curves, and their topology, has received little attention as a representation learning substrate. We introduce BRepCLIP, the first framework to align BRep geometry with language and image embeddings through contrastive pretraining. We model each CAD object as a sequence of face and edge tokens with separate discrete vocabularies for surface and curve geometry, augmented with spatial and semantic descriptors that capture surface types (e.g., cylindrical, torus, NURBS) and curve primitives (e.g., line, arc, B-spline). A transformer encoder aggregates these tokens into a global BRep embedding, aligned with CLIP's text and image encoders via a joint contrastive objective. BRepCLIP generates more discriminative and semantically grounded embeddings than existing point-based alternatives, improving Top-1 retrieval over OpenShape by 40.4%, 22.0%, and 23.9% on ABC, CADParser, and Automate, respectively, and improving zero-shot classification on FabWave by 15% in Top-1 score. We further demonstrate its utility as a CAD-aware similarity metric for evaluating text and image-conditioned CAD generation, establishing the importance of structure-aware pretraining for multimodal CAD understanding. Project page is available at https://muhammadusama100.github.io/BrepClip2026/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRepCLIP, the first contrastive pretraining framework to align native BRep representations of CAD models (tokenized faces and edges with discrete surface/curve vocabularies plus spatial and semantic descriptors) with CLIP image and text embeddings via a transformer encoder and joint contrastive loss. It reports substantial gains over point-cloud baselines: +40.4%, +22.0%, and +23.9% Top-1 retrieval on ABC, CADParser, and Automate, plus +15% zero-shot Top-1 classification on FabWave, and demonstrates utility as a similarity metric for text/image-conditioned CAD generation.
Significance. If the empirical gains are reproducible and attributable to the BRep representation rather than implementation details, the work would meaningfully advance CAD representation learning by moving beyond point-cloud or mesh approximations to the exact parametric format used in industrial design. The multimodal alignment and downstream use for generation evaluation are timely contributions.
major comments (2)
- [Method] Method (tokenization and encoder description): The headline retrieval and classification improvements rest on the assumption that the chosen discrete vocabularies for surfaces/curves, augmented only by type and primitive descriptors, retain enough continuous geometric information for meaningful alignment with CLIP spaces. No ablation or analysis is presented that isolates the effect of discretization (e.g., loss of exact NURBS coefficients or tolerances) versus the transformer architecture or contrastive objective, leaving open whether the reported 40%+ gains would persist under alternative tokenizations or on out-of-distribution CAD domains.
- [Experiments] Experimental section (results tables): The abstract states concrete percentage improvements but the provided text supplies no information on training hyperparameters, dataset splits, statistical significance testing, or variance across runs. Without these, it is impossible to determine whether the gains over OpenShape are robust or sensitive to the particular choice of discrete vocabularies.
minor comments (1)
- The project page URL is given but no link to code or pretrained models is mentioned in the text; releasing these would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our manuscript. We address the major comments point by point below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method] Method (tokenization and encoder description): The headline retrieval and classification improvements rest on the assumption that the chosen discrete vocabularies for surfaces/curves, augmented only by type and primitive descriptors, retain enough continuous geometric information for meaningful alignment with CLIP spaces. No ablation or analysis is presented that isolates the effect of discretization (e.g., loss of exact NURBS coefficients or tolerances) versus the transformer architecture or contrastive objective, leaving open whether the reported 40%+ gains would persist under alternative tokenizations or on out-of-distribution CAD domains.
Authors: We appreciate the referee's point on the potential limitations of discretization in our tokenization approach. The design of our surface and curve vocabularies, combined with type and primitive descriptors, aims to preserve key geometric properties necessary for alignment with CLIP embeddings. The consistent performance gains across multiple datasets support that this representation is effective. However, we agree that dedicated ablations isolating the discretization effects would be beneficial. In the revised manuscript, we will include additional analysis and discussion on the impact of our tokenization choices versus the architecture and loss, as well as note the scope of our current evaluations. revision: partial
-
Referee: [Experiments] Experimental section (results tables): The abstract states concrete percentage improvements but the provided text supplies no information on training hyperparameters, dataset splits, statistical significance testing, or variance across runs. Without these, it is impossible to determine whether the gains over OpenShape are robust or sensitive to the particular choice of discrete vocabularies.
Authors: We acknowledge that the experimental details were not presented with sufficient clarity in the submitted manuscript. The revised version will incorporate a dedicated subsection detailing the training hyperparameters, dataset splits used, variance across multiple runs (including standard deviations), and any statistical significance testing. This will provide the necessary information to evaluate the robustness of the results. revision: yes
Circularity Check
No significant circularity; results are empirical
full rationale
The paper describes an empirical contrastive pretraining framework that tokenizes BRep faces/edges with discrete vocabularies plus spatial/semantic descriptors, feeds them to a transformer, and aligns the resulting embeddings to CLIP spaces via a joint contrastive loss. No equations, derivations, or first-principles predictions are presented anywhere in the provided text. All headline claims (40.4 % / 22.0 % / 23.9 % Top-1 retrieval gains, 15 % zero-shot lift) are reported as measured outcomes on held-out datasets; none reduce by construction to a fitted parameter, self-citation chain, or renamed input. The architecture choices are presented as design decisions, not as mathematically forced consequences of prior results by the same authors. This is the normal, non-circular case for a methods-plus-experiments paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brep boundary and junction detection for cad reverse engineering
Sk Aziz Ali, Mohammad Sadil Khan, and Didier Stricker. Brep boundary and junction detection for cad reverse engineering. In2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), 2024. 3
2024
-
[2]
A multi-modal retrieval augmented framework for user editable 3d cad model generation
A Ananthakrishnan. A multi-modal retrieval augmented framework for user editable 3d cad model generation. 2025. 3
2025
-
[3]
Chang, and Matthias Nießner
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X. Chang, and Matthias Nießner. Scan2CAD: Learning CAD model alignment in RGB-D scans. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2614–2623,
-
[4]
Development of a pilot manufacturing cyberinfrastructure with an information rich mechanical cad 3d model repository
Akshay Bharadwaj, Yang Xu, Atin Angrish, Yong Chen, and Binil Starly. Development of a pilot manufacturing cyberinfrastructure with an information rich mechanical cad 3d model repository. InInternational Manufacturing Science and Engineering Conference, 2019. 2, 7
2019
-
[5]
Cad: Do computers aid the design process after all?Intersect: The Stanford Journal of Science, Technology and Society, 2:52–66, 2009
Polly Ann Brown. Cad: Do computers aid the design process after all?Intersect: The Stanford Journal of Science, Technology and Society, 2:52–66, 2009. 1
2009
-
[6]
Cadreview: Automatically reviewing cad programs with error detection and correction
Jiali Chen, Xusen Hei, Hongfei Liu, Yuancheng Wei, Zikun Deng, Jiayuan Xie, Yi Cai, and Li Qing. Cadreview: Automatically reviewing cad programs with error detection and correction. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9909–9927, 2025. 3
2025
-
[7]
Sculpting holistic 3d representation in contrastive language-image-3d pre-training
Yipeng Gao, Zeyu Wang, Wei-Shi Zheng, Cihang Xie, and Yuyin Zhou. Sculpting holistic 3d representation in contrastive language-image-3d pre-training. InCVPR, 2024. 6, 7, 8
2024
-
[8]
Geometric deep learning for computer-aided design: A survey.IEEE Access, 13:119305–119334, 2024
Negar Heidari and Alexandros Iosifidis. Geometric deep learning for computer-aided design: A survey.IEEE Access, 13:119305–119334, 2024. 1, 3
2024
-
[9]
Uv-net: Learning from boundary representations
Pradeep Kumar Jayaraman, Aditya Sanghi, Joseph G Lambourne, Karl DD Willis, Thomas Davies, Hooman Shayani, and Nigel Morris. Uv-net: Learning from boundary representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11703–11712, 2021. 3
2021
-
[10]
Automate: A dataset and learning approach for automatic mating of cad assemblies
Benjamin Jones, Dalton Hildreth, Duowen Chen, Ilya Baran, Vladimir G Kim, and Adriana Schulz. Automate: A dataset and learning approach for automatic mating of cad assemblies. ACM Transactions on Graphics (TOG), 2021. 7
2021
-
[11]
Benjamin T. Jones, Michael Hu, Vladimir G. Kim, and Adriana Schulz. Self-supervised representation learning for CAD.arXiv preprint arXiv:2210.10807, 2022. 3
-
[12]
Ten cad challenges.IEEE computer graphics and applications, 25:81–92, 03 2005
David Kasik, William Buxton, and David Ferguson. Ten cad challenges.IEEE computer graphics and applications, 25:81–92, 03 2005. 1 10
2005
-
[13]
Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
Mohammad S Khan, Sankalp Sinha, Talha U Sheikh, Didier Stricker, Sk A Ali, and Muham- mad Z Afzal. Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024. 3, 8
2024
-
[14]
Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention
Mohammad Sadil Khan, Elona Dupont, Sk Aziz Ali, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4713–4722, June 2024. 3
2024
-
[15]
Dreamcad: Scaling multi-modal cad generation using differentiable parametric surfaces.Arxiv, 2026
Mohammad Sadil Khan, Muhammad Usama, Rolandos Alexandros Potamias, Didier Stricker, Muhammad Zeshan Afzal, Jiankang Deng, and Ismail Elezi. Dreamcad: Scaling multi-modal cad generation using differentiable parametric surfaces.Arxiv, 2026. 3, 5, 6, 7
2026
-
[16]
BrepCoder: A Unified Multimodal Large Language Model for Multi-task B-rep Reasoning
Mingi Kim, Yongjun Kim, Jungwoo Kang, and Hyungki Kim. Brepcoder: A unified multimodal large language model for multi-task b-rep reasoning.arXiv preprint arXiv:2602.22284, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
cadrille: Multi-modal cad reconstruction with reinforcement learning
Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhemchuzhnikov, Alexander Nikulin, Ilya Zisman, Anna V orontsova, Anton Konushin, Vladislav Kurenkov, and Danila Rukhovich. cadrille: Multi-modal cad reconstruction with reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2025. 8
2025
-
[18]
Brepnet: A topological message passing system for solid models
Joseph G Lambourne, Karl DD Willis, Pradeep Kumar Jayaraman, Aditya Sanghi, Peter Meltzer, and Hooman Shayani. Brepnet: A topological message passing system for solid models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12773–12782, 2021. 1, 3, 5, 6
2021
-
[19]
FastCAD: Real-time CAD retrieval and alignment from scans and videos
Florian Langer, Jihong Ju, Georgi Dikov, Gerhard Reitmayr, and Mohsen Ghafoorian. FastCAD: Real-time CAD retrieval and alignment from scans and videos. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 3
2024
-
[20]
Cad-llama: leveraging large language models for computer-aided design parametric 3d model generation
Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, and Xiangdong Zhou. Cad-llama: leveraging large language models for computer-aided design parametric 3d model generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18563–18573, 2025. 3
2025
-
[21]
Openshape: Scaling up 3d shape representation towards open-world understanding.Advances in neural information processing systems, 36:44860–44879, 2023
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding.Advances in neural information processing systems, 36:44860–44879, 2023. 2, 3, 6, 7, 8, 9
2023
-
[22]
Point2cad: Reverse engineering cad models from 3d point clouds
Yujia Liu, Anton Obukhov, Jan Dirk Wegner, and Konrad Schindler. Point2cad: Reverse engineering cad models from 3d point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3763–3772, 2024. 3
2024
-
[23]
Brep-bert: Pre-training boundary representation bert with sub-graph node contrastive learning
Yunzhong Lou, Xueyang Li, Haotian Chen, and Xiangdong Zhou. Brep-bert: Pre-training boundary representation bert with sub-graph node contrastive learning. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 1657–1666, 2023. 3
2023
-
[24]
Multicad: Contrastive representa- tion learning for multi-modal 3D computer-aided design models
Weijian Ma, Minyang Xu, Xueyang Li, and Xiangdong Zhou. Multicad: Contrastive representa- tion learning for multi-modal 3D computer-aided design models. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM). ACM,
-
[25]
Rethinking network design and local geometry in point cloud: A simple residual mlp framework
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking network design and local geometry in point cloud: A simple residual mlp framework. InInternational Conference on Learning Representations, 2022. 6, 7, 8
2022
-
[26]
Sharp challenge 2023: Solving cad history and parameters recovery from point clouds and 3d scans
Dimitrios Mallis, Ali Sk Aziz, Elona Dupont, Kseniya Cherenkova, Ahmet Serdar Karadeniz, Mohammad Sadil Khan, Anis Kacem, Gleb Gusev, and Djamila Aouada. Sharp challenge 2023: Solving cad history and parameters recovery from point clouds and 3d scans. overview, datasets, metrics, and baselines. InProceedings of the IEEE/CVF International Conference on Com...
2023
-
[27]
Oscar: Open-set cad retrieval from a language prompt and a single image
Tessa Pulli, Jean-Baptiste Weibel, Peter Hönig, Matthias Hirschmanner, Markus Vincze, and Andreas Holzinger. Oscar: Open-set cad retrieval from a language prompt and a single image. arXiv preprint arXiv:2601.07333, 2026. 3
-
[28]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017. 2, 6, 7, 8
2017
-
[29]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 2
2017
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning, 2021. 2, 4
2021
-
[31]
Schinko, T
C. Schinko, T. V osgien, T. Prante, T. Schreck, and T. Ullrich. Search and retrieval in cad databases - a user-centric state-of-the-art overview. InProceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications,
-
[32]
12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications : VISAPP 2017, VISIGRAPP ; Conference date: 27-02-2017 Through 01-03-2017. 3
2017
-
[33]
Marvel-40m+: Multi-level visual elaboration for high-fidelity text-to-3d content creation
Sankalp Sinha, Mohammad Sadil Khan, Muhammad Usama, Shino Sam, Didier Stricker, Sk Aziz Ali, and Muhammad Zeshan Afzal. Marvel-40m+: Multi-level visual elaboration for high-fidelity text-to-3d content creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8105–8116, 2025. 3
2025
-
[34]
Balancing speed and executability in interactive text-to-cad code generation for early-stage parametric cad ideation
Yuhao Sun, Hao Cheng, Shang Zheng, Hualong Yu, and Haitao Zou. Balancing speed and executability in interactive text-to-cad code generation for early-stage parametric cad ideation. Journal of King Saud University Computer and Information Sciences, 2026. 8
2026
-
[35]
Nurbgen: High-fidelity text-to-cad generation through llm-driven nurbs modeling
Muhammad Usama, Mohammad Sadil Khan, Didier Stricker, and Muhammad Zeshan Afzal. Nurbgen: High-fidelity text-to-cad generation through llm-driven nurbs modeling. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9603–9611, 2026. 3
2026
-
[36]
Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to-cad generation through infusing visual feedback in large language models.arXiv preprint arXiv:2501.19054, 2025. 8
-
[37]
Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced multimodal llms
Siyu Wang, Cailian Chen, Xinyi Le, Qimin Xu, Lei Xu, Yanzhou Zhang, and Jie Yang. Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced multimodal llms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7880–7888,
-
[38]
Deepcad: A deep generative network for computer- aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer- aided design models. InProceedings of the IEEE/CVF international conference on computer vision, pages 6772–6782, 2021. 3, 8
2021
-
[39]
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. Cad-mllm: Unify- ing multimodality-conditioned cad generation with mllm.arXiv preprint arXiv:2411.04954,
-
[40]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1179–1189, 2023. 2, 6, 7, 8
2023
-
[41]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding
Le Xue, Ning Yu, Shu Zhang, Artemis Panagopoulou, Junnan Li, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, et al. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27091–27101, 2024. 2, 3 12
2024
-
[42]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19313–19322, 2022. 2, 4, 6, 7, 8
2022
-
[43]
Shuming Zhang, Zhidong Guan, Hao Jiang, Tao Ning, Xiaodong Wang, and Pingan Tan. Brep2seq: a dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models.Journal of Computational Design and Engineering, 11(1):110– 134, 2024. 3
2024
-
[44]
Cadparser: a learning approach of sequence modeling for b-rep cad
Shengdi Zhou, Tianyi Tang, and Bin Zhou. Cadparser: a learning approach of sequence modeling for b-rep cad. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, 2023. 7
2023
-
[45]
Bringing attention to cad: Boundary representation learning via transformer.Computer-Aided Design, 189:103940, December 2025
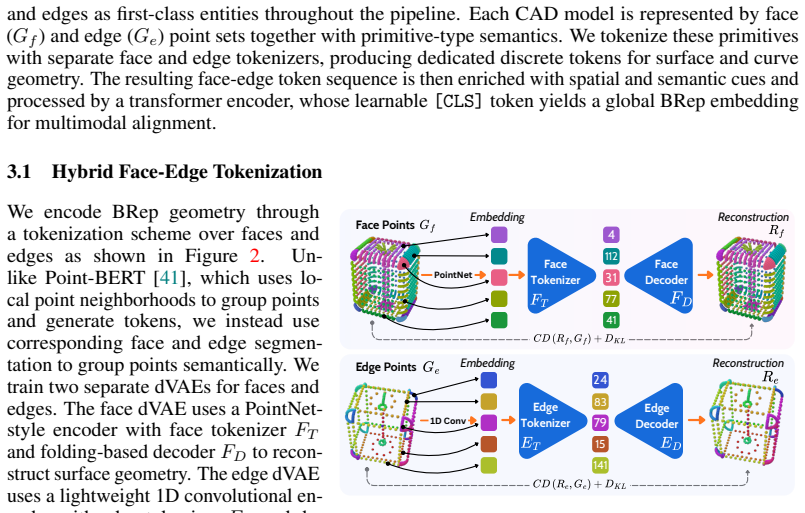
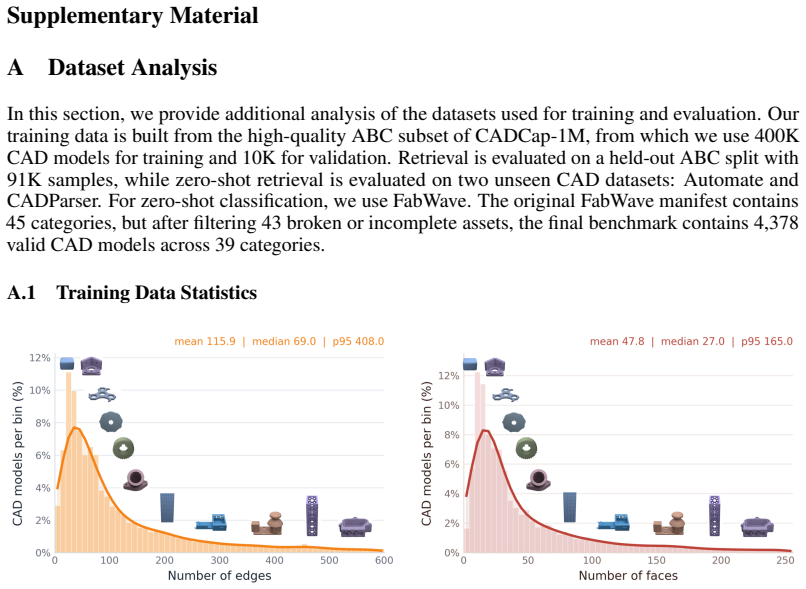
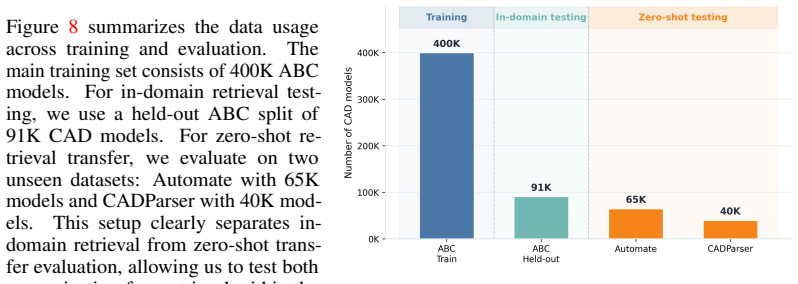
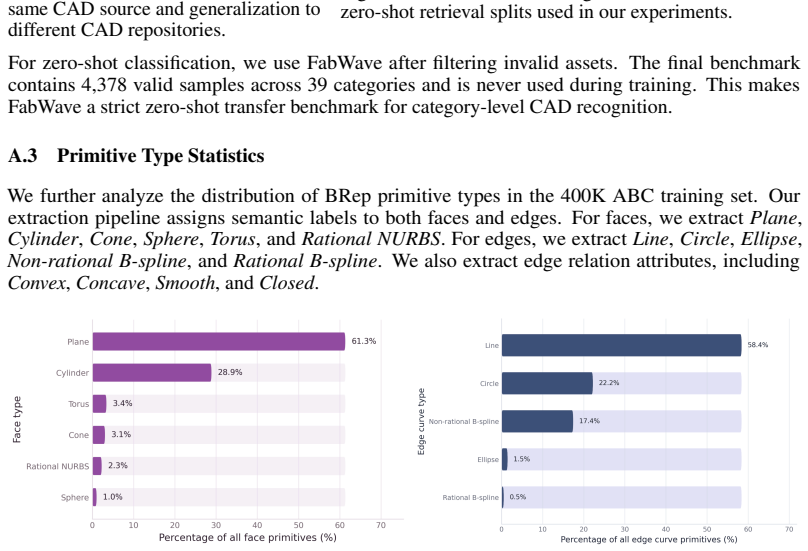
Qiang Zou and Lizhen Zhu. Bringing attention to cad: Boundary representation learning via transformer.Computer-Aided Design, 189:103940, December 2025. 3 13 Supplementary Material A Dataset Analysis In this section, we provide additional analysis of the datasets used for training and evaluation. Our training data is built from the high-quality ABC subset ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.