Dominant-Layer ZO: A Single Layer Dominates Zeroth-Order Fine-Tuning of LLMs
Pith reviewed 2026-06-28 06:33 UTC · model grok-4.3
The pith
Zeroth-order fine-tuning of LLMs is dominated by a single decoding layer that matches full-model results when tuned alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
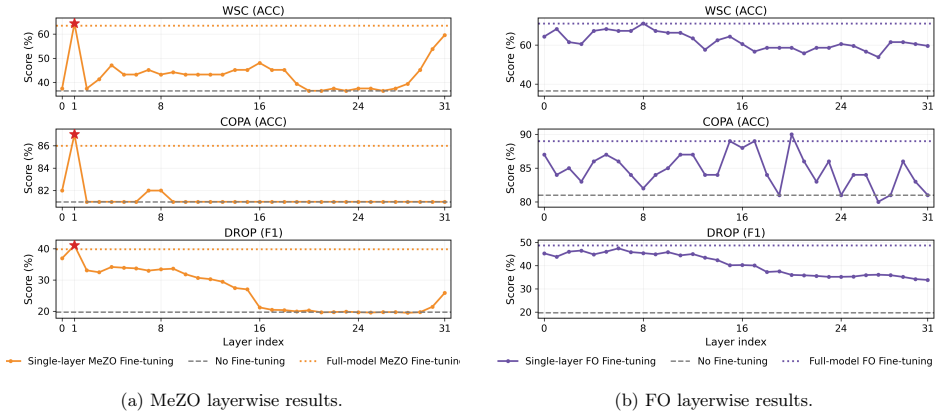
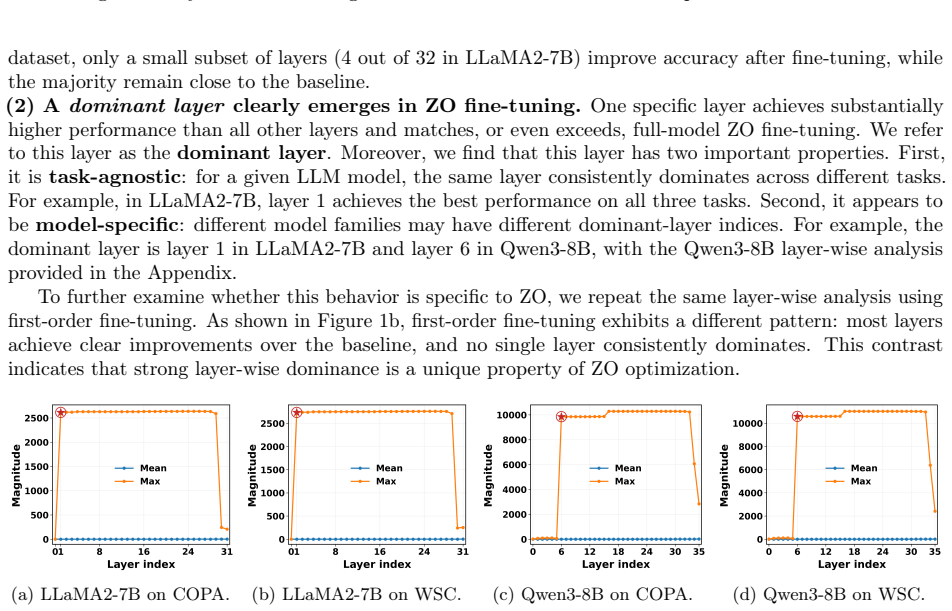
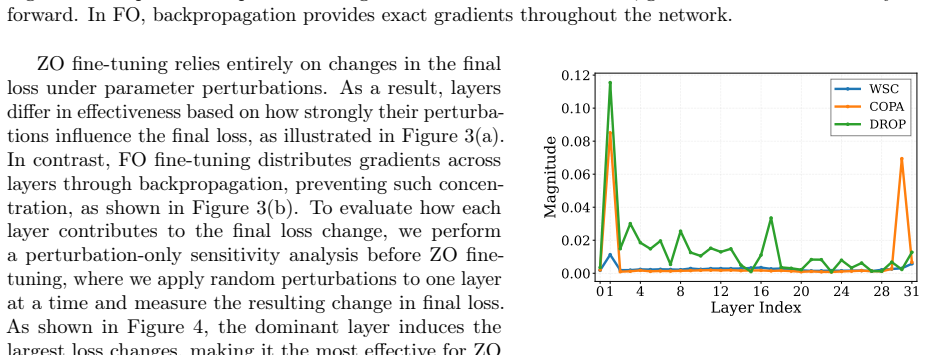
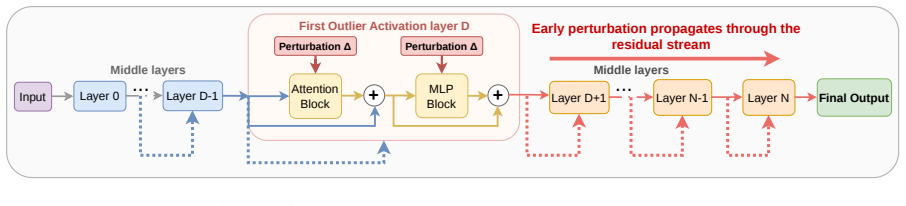
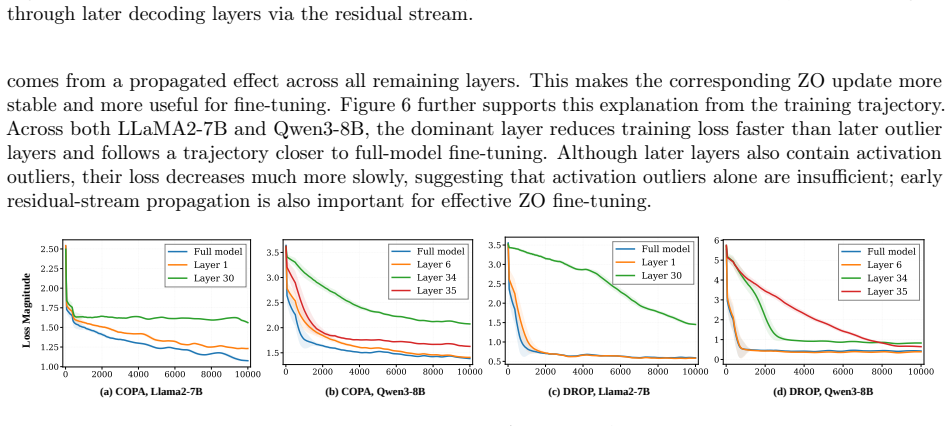
Zeroth-order fine-tuning is sharply dominated by a single decoding layer. Across multiple LLM families and downstream tasks, fine-tuning this dominant layer alone consistently matches or even exceeds full-model ZO fine-tuning. The dominant layer is task-agnostic but model-specific, and aligns with the first activation-outlier layer in the pre-trained model. This layer has high perturbation sensitivity and early placement in the residual stream, allowing perturbation-induced effects to propagate and accumulate through subsequent decoding layers and produce strong optimization signals under forward-only updates.
What carries the argument
The dominant decoding layer, identified as the first activation-outlier layer, which supplies high perturbation sensitivity and early residual-stream position to generate the primary ZO optimization signals.
If this is right
- Dominant-layer ZO fine-tuning improves average performance over full-model MeZO and LoRA-based ZO fine-tuning.
- It achieves up to 4.52 times training speedup.
- The dominant layer is task-agnostic but model-specific.
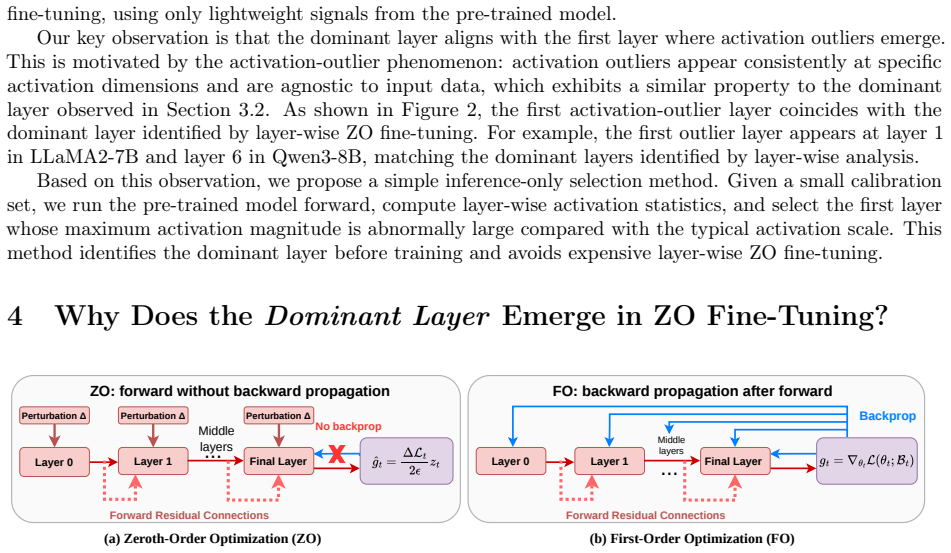
- It can be identified before training through inference-only analysis of activation outliers.
Where Pith is reading between the lines
- Pre-identifying the dominant layer could become a standard first step for any memory-efficient LLM adaptation method.
- The early-position and sensitivity combination may point to similar single-layer dominance in other forward-only or low-memory training regimes.
- Model families with different residual architectures might show their dominant layers at different depths, allowing targeted pre-checks.
Load-bearing premise
That the first activation-outlier layer found by inference-only analysis is reliably the one whose sensitivity and position generate the observed optimization signals under ZO updates.
What would settle it
If tuning any non-outlier layer alone, or the full model without the identified dominant layer, produces equal or better results than dominant-layer tuning across the same tasks and models, the dominance claim would not hold.
Figures
read the original abstract
Zeroth-order (ZO) optimization enables memory-efficient fine-tuning of large language models (LLMs) using only forward passes, but it remains unclear how useful adaptation is distributed across layers. In this work, we reveal a surprising phenomenon: ZO fine-tuning is sharply dominated by a single decoding layer. Across multiple LLM families and downstream tasks, fine-tuning this dominant layer alone consistently matches or even exceeds full-model ZO fine-tuning. We further show that the dominant layer is task-agnostic but model-specific, and can be identified before training through a simple inference-only analysis of activation outliers. Specifically, the dominant layer consistently aligns with the first activation-outlier layer in the pre-trained model. To explain this phenomenon, we analyze how perturbation effects propagate under ZO optimization. We find that the dominant layer combines two key properties: high perturbation sensitivity and early placement in the residual stream, allowing perturbation-induced effects to propagate and accumulate through remaining subsequent decoding layers. As a result, this layer produces disproportionately strong and stable optimization signals under forward-only updates. Extensive experiments on LLaMA2-7B and Qwen3-8B across nine benchmarks show that dominant-layer ZO fine-tuning improves average performance over full-model MeZO and LoRA-based ZO fine-tuning while achieving up to 4.52$\times$ training speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zeroth-order (ZO) fine-tuning of LLMs is sharply dominated by a single 'dominant' decoding layer, which can be identified pre-training via the first activation-outlier layer in an inference-only analysis. Fine-tuning only this layer (task-agnostic but model-specific) matches or exceeds full-model ZO performance; the explanation rests on the layer's high perturbation sensitivity combined with early residual-stream position, allowing effects to propagate. Experiments on LLaMA2-7B and Qwen3-8B across nine benchmarks report improved average performance over MeZO and LoRA-based ZO baselines plus up to 4.52× speedup.
Significance. If the central empirical claim holds, the result would be significant for memory-efficient LLM adaptation, as it reduces ZO fine-tuning to a single layer while preserving or improving performance. The inference-only identification method and the perturbation-propagation analysis are strengths that could generalize beyond the two model families tested.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that dominant-layer ZO 'consistently matches or even exceeds' full-model ZO is load-bearing, yet the provided material gives no details on number of random seeds, standard deviations, or statistical tests; without these, it is impossible to determine whether reported gains are reliable or could be explained by variance.
- [Analysis section] Analysis of perturbation propagation: the explanation that the first activation-outlier layer produces 'disproportionately strong and stable optimization signals' because of sensitivity plus early residual position requires a quantitative test (e.g., ablation of perturbation magnitude at that layer versus later layers) to confirm it is not post-hoc; the current description risks circularity with the identification rule.
minor comments (2)
- [Method] Clarify the precise definition and threshold used to detect 'activation outliers' (e.g., which statistic, which token positions) so the identification procedure is fully reproducible.
- [Experiments] Table or figure reporting per-task results should include the full-model ZO, dominant-layer ZO, and random-layer controls side-by-side with the same random seed to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for strengthening the empirical validation and analysis. We provide point-by-point responses below and will revise the manuscript to address the concerns.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that dominant-layer ZO 'consistently matches or even exceeds' full-model ZO is load-bearing, yet the provided material gives no details on number of random seeds, standard deviations, or statistical tests; without these, it is impossible to determine whether reported gains are reliable or could be explained by variance.
Authors: We fully agree that providing details on the number of random seeds, standard deviations, and statistical tests is crucial for validating the central claim. The current manuscript does not include these, which is an oversight. In the revised manuscript, we will report that all experiments were conducted with 3 random seeds, include standard deviations in the tables, and perform statistical tests (such as Wilcoxon signed-rank tests) to confirm the significance of the performance improvements. This will allow readers to assess the reliability of the results. revision: yes
-
Referee: [Analysis section] Analysis of perturbation propagation: the explanation that the first activation-outlier layer produces 'disproportionately strong and stable optimization signals' because of sensitivity plus early residual position requires a quantitative test (e.g., ablation of perturbation magnitude at that layer versus later layers) to confirm it is not post-hoc; the current description risks circularity with the identification rule.
Authors: We acknowledge the risk of circularity in the current analysis. Although the dominant layer is identified via a task-agnostic, inference-only method based on activation outliers, we agree that additional quantitative evidence is needed to support the perturbation propagation explanation. In the revision, we will add an ablation experiment that varies the perturbation magnitude specifically at the dominant layer compared to later layers and measures the resulting optimization signal strength. This will provide independent validation of the proposed mechanism. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical investigation that identifies a dominant layer via a pre-training, inference-only analysis of activation outliers and then validates through experiments that fine-tuning only that layer matches or exceeds full-model ZO performance. No derivation, equation, or prediction reduces by construction to a fitted quantity defined from the target data; the identification step is explicitly described as independent of the fine-tuning process. No self-citation load-bearing steps, uniqueness theorems, or ansatzes imported from prior author work appear in the central claims. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effec- tiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effec- tiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
2021
-
[2]
Systematic outliers in large language models, 2025
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Systematic outliers in large language models, 2025
2025
-
[3]
The second pascal recognising textual entailment challenge.Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment, 01 2006
Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa Ferro, and Danilo Giampiccolo. The second pascal recognising textual entailment challenge.Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment, 01 2006
2006
-
[4]
The fifth pascal recognizing textual entailment challenge.TAC, 7(8):1, 2009
Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth pascal recognizing textual entailment challenge.TAC, 7(8):1, 2009
2009
-
[5]
Zo-adamm: Zeroth-order adaptive momentum method for black-box optimization, 2019
Xiangyi Chen, Sijia Liu, Kaidi Xu, Xingguo Li, Xue Lin, Mingyi Hong, and David Cox. Zo-adamm: Zeroth-order adaptive momentum method for black-box optimization, 2019
2019
-
[6]
Yiming Chen, Yuan Zhang, Liyuan Cao, Kun Yuan, and Zaiwen Wen. Enhancing zeroth-order fine-tuning for language models with low-rank structures.arXiv preprint arXiv:2410.07698, 2024
-
[7]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
2019
-
[8]
The pascal recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. InMachine learning challenges workshop, pages 177–190. Springer, 2005
2005
-
[9]
Fzoo: Fast zeroth-order optimizer for fine-tuning large language models towards adam-scale speed, 2025
Sizhe Dang, Yangyang Guo, Yanjun Zhao, Haishan Ye, Xiaodong Zheng, Guang Dai, and Ivor Tsang. Fzoo: Fast zeroth-order optimizer for fine-tuning large language models towards adam-scale speed, 2025
2025
-
[10]
The commitmentbank: Investigat- ing projection in naturally occurring discourse
Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. The commitmentbank: Investigat- ing projection in naturally occurring discourse. Inproceedings of Sinn und Bedeutung, volume 23, pages 107–124, 2019
2019
-
[11]
Gpt3.int8(): 8-bit matrix multiplica- tion for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3.int8(): 8-bit matrix multiplica- tion for transformers at scale. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 30318–30332. Curran Associates, Inc., 2022
2022
-
[12]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)...
2019
-
[13]
The third pascal recognizing textual entailment challenge
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B Dolan. The third pascal recognizing textual entailment challenge. InProceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pages 1–9, 2007
2007
-
[14]
Zeroth-order fine-tuning of llms with transferable static sparsity
Wentao Guo, Jikai Long, Yimeng Zeng, Zirui Liu, Xinyu Yang, Yide Ran, Jacob R Gardner, Osbert Bastani, Christopher De Sa, Xiaodong Yu, et al. Zeroth-order fine-tuning of llms with transferable static sparsity. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019. 10
2019
-
[16]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[17]
Looking beyond the surface: A challenge set for reading comprehension over multiple sentences
Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 252–262, 2018
2018
-
[18]
The winograd schema challenge.KR, 2012 (13th):3, 2012
Hector J Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge.KR, 2012 (13th):3, 2012
2012
-
[19]
Outlier-weighed layerwise sampling for llm fine-tuning, 2025
Pengxiang Li, Lu Yin, Xiaowei Gao, and Shiwei Liu. Outlier-weighed layerwise sampling for llm fine-tuning, 2025
2025
-
[20]
AGZO: Activation-Guided Zeroth-Order Optimization for LLM Fine-Tuning
Wei Lin, Yining Jiang, Qingyu Song, Qiao Xiang, and Hong Xu. Agzo: Activation-guided zeroth-order optimization for llm fine-tuning.arXiv preprint arXiv:2601.17261, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Yong Liu, Zirui Zhu, Chaoyu Gong, Minhao Cheng, Cho-Jui Hsieh, and Yang You. Sparse mezo: Less parameters for better performance in zeroth-order llm fine-tuning.arXiv preprint arXiv:2402.15751, 2024
-
[22]
Fine-tuning language models with just forward passes.Advances in Neural Information Processing Systems, 36:53038–53075, 2023
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes.Advances in Neural Information Processing Systems, 36:53038–53075, 2023
2023
-
[23]
Random gradient-free minimization of convex functions.Founda- tions of Computational Mathematics, 17(2):527–566, 2017
Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex functions.Founda- tions of Computational Mathematics, 17(2):527–566, 2017
2017
-
[24]
Lisa: Layer- wise importance sampling for memory-efficient large language model fine-tuning.Advances in Neural Information Processing Systems, 37:57018–57049, 2024
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. Lisa: Layer- wise importance sampling for memory-efficient large language model fine-tuning.Advances in Neural Information Processing Systems, 37:57018–57049, 2024
2024
-
[25]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392, 2016
2016
-
[26]
Choice of plausible alternatives: An evaluation of commonsense causal reasoning
Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S Gordon. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. InAAAI spring symposium: logical formalizations of commonsense reasoning, pages 90–95, 2011
2011
-
[27]
Understanding layer significance in llm alignment, 2025
Guangyuan Shi, Zexin Lu, Xiaoyu Dong, Wenlong Zhang, Xuanyu Zhang, Yujie Feng, and Xiao-Ming Wu. Understanding layer significance in llm alignment, 2025
2025
-
[28]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA, October 2013. Association for Co...
2013
-
[29]
Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE transactions on automatic control, 37(3):332–341, 2002
James C Spall. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE transactions on automatic control, 37(3):332–341, 2002
2002
-
[30]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models. arXiv preprint arXiv:2402.17762, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Harmony in divergence: Towards fast, accurate, and memory-efficient zeroth-order llm fine-tuning, 2025
Qitao Tan, Jun Liu, Zheng Zhan, Caiwei Ding, Yanzhi Wang, Xiaolong Ma, Jaewoo Lee, Jin Lu, and Geng Yuan. Harmony in divergence: Towards fast, accurate, and memory-efficient zeroth-order llm fine-tuning, 2025. 11
2025
-
[32]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Simultaneous computation and memory efficient zeroth-order optimizer for fine-tuning large language models, 2024
Fei Wang, Li Shen, Liang Ding, Chao Xue, Ye Liu, and Changxing Ding. Simultaneous computation and memory efficient zeroth-order optimizer for fine-tuning large language models, 2024
2024
-
[34]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Layer-wise importance matters: Less memory for better performance in parameter-efficient fine-tuning of large language models
Kai Yao, Penglei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, and Jianke Zhu. Layer-wise importance matters: Less memory for better performance in parameter-efficient fine-tuning of large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1977–1...
2024
-
[37]
Zeroth-order fine-tuning of llms in random subspaces
Ziming Yu, Pan Zhou, Sike Wang, Jia Li, Mi Tian, and Hua Huang. Zeroth-order fine-tuning of llms in random subspaces. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4475–4485, 2025
2025
-
[38]
Learning a zeroth-order optimizer for fine-tuning llms, 2025
Kairun Zhang, Haoyu Li, Yanjun Zhao, Yifan Sun, and Huan Zhang. Learning a zeroth-order optimizer for fine-tuning llms, 2025
2025
-
[39]
Lee, Wotao Yin, Mingyi Hong, Zhangyang Wang, Sijia Liu, and Tianlong Chen
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D. Lee, Wotao Yin, Mingyi Hong, Zhangyang Wang, Sijia Liu, and Tianlong Chen. Revisiting zeroth-order optimization for memory-efficient llm fine-tuning: A benchmark, 2024
2024
-
[40]
Helene: Hessian layer-wise clipping and gradient annealing for accelerating fine-tuning llm with zeroth-order optimization, 2024
Huaqin Zhao, Jiaxi Li, Yi Pan, Shizhe Liang, Xiaofeng Yang, Wei Liu, Xiang Li, Fei Dou, Tianming Liu, and Jin Lu. Helene: Hessian layer-wise clipping and gradient annealing for accelerating fine-tuning llm with zeroth-order optimization, 2024
2024
-
[41]
Yanjun Zhao, Sizhe Dang, Haishan Ye, Guang Dai, Yi Qian, and Ivor W Tsang. Second-order fine-tuning without pain for llms: A hessian informed zeroth-order optimizer.arXiv preprint arXiv:2402.15173, 2024. 12 A Experimental Details A.1 Tasks, Models, and Metrics Following MeZO [22], we construct each task split by sampling up to 1000 training examples, 500 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.