ColBERTSaR: Sparsified ColBERT Index via Product Quantization
Pith reviewed 2026-06-27 23:59 UTC · model grok-4.3
The pith
Product quantization converts ColBERT token embeddings into a sparsified inverted index that is 50-70% smaller than one-bit PLAID while retaining effectiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ColBERT with embedding quantization is equivalent to learned-sparse retrieval except for the scoring mechanism, and the resulting index is 50-70% smaller than a one-bit PLAID index while retaining retrieval effectiveness.
What carries the argument
Product quantization of ColBERT token embeddings, which sparsifies them into an inverted index that supports MaxSim scoring.
If this is right
- Storage for ColBERT-style indexes drops enough to support larger collections on the same hardware.
- Query execution can use conventional inverted-index traversal instead of embedding gathering and decompression.
- The method creates a direct bridge between dense neural retrieval and learned-sparse bag-of-words models.
- Effectiveness holds across the tested collections when the quantized index replaces the dense one.
Where Pith is reading between the lines
- The same quantization step could be applied to other dense retrieval models to produce compact inverted indexes.
- The remaining difference in scoring might be used to design hybrid exact-plus-approximate matching strategies.
- Further compression layers could be stacked on the sparsified index to reduce size even more.
Load-bearing premise
Product quantization must keep enough information in the embeddings for MaxSim to remain effective after the index is turned into an inverted structure.
What would settle it
A side-by-side run on a standard benchmark such as MS MARCO in which the quantized inverted index shows markedly lower recall or NDCG than the original ColBERT or PLAID implementation.
Figures
read the original abstract
While ColBERT is an effective neural retrieval architecture, it requires a heavy index structure to support candidate set retrieval based on approximated token embeddings, gathering and decompressing document token embeddings, and applying the MaxSim operation. Indexes in PLAID and similar ColBERT implementations require five to ten times the disk storage of the original raw text, which limits their scalability. Furthermore, prior work has identified that the gathering and decompression stages are the primary inefficiencies at query time. Limiting the number of document tokens that must be gathered by thresholding and score approximation does not eliminate the need for the entire index to support ad hoc queries. In this work, we propose an embedding quantization approach that turns a ColBERT index into a true inverted index. We show that, theoretically, ColBERT with embedding quantization is equivalent to learned-sparse retrieval except for the scoring mechanism. Empirically, we demonstrate that our index is 50-70% smaller than a one-bit PLAID index while retaining retrieval effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ColBERTSaR, which applies product quantization to ColBERT token embeddings to convert the index into a true inverted index. It claims that, theoretically, ColBERT with embedding quantization is equivalent to learned-sparse retrieval except for the scoring mechanism, and reports an empirical result that the resulting index is 50-70% smaller than a one-bit PLAID index while retaining retrieval effectiveness.
Significance. If the theoretical equivalence and empirical size reduction hold under rigorous verification, the work would address a central scalability bottleneck in ColBERT-style neural retrieval by enabling much smaller indexes without sacrificing effectiveness. The bridging of quantized dense embeddings to inverted-index structures could have broader implications for unifying dense and sparse retrieval paradigms.
major comments (3)
- [Abstract] Abstract: the central theoretical claim of equivalence between quantized ColBERT and learned-sparse retrieval (except scoring) is asserted without any derivation, proof, or argument showing that product quantization preserves the argmax ordering inside MaxSim; this is load-bearing because the equivalence requires that discretization error does not alter per-token maximum similarities.
- [Abstract] Abstract: the empirical claim of 50-70% size reduction versus one-bit PLAID while retaining effectiveness provides no datasets, metrics, experimental protocol, or error analysis, making it impossible to assess whether the product quantization actually preserves sufficient information for effective MaxSim after sparsification.
- [Abstract] Abstract: the construction assumes that mapping quantized embeddings to inverted-index codes leaves the relative ordering of highest-similarity matches unchanged, but product quantization minimizes per-subspace reconstruction error rather than bounding changes to MaxSim; no analysis or bound is supplied to address this.
Simulated Author's Rebuttal
We thank the referee for the constructive comments focusing on the abstract's presentation of our theoretical equivalence and empirical results. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central theoretical claim of equivalence between quantized ColBERT and learned-sparse retrieval (except scoring) is asserted without any derivation, proof, or argument showing that product quantization preserves the argmax ordering inside MaxSim; this is load-bearing because the equivalence requires that discretization error does not alter per-token maximum similarities.
Authors: The full manuscript (Section 3) derives the equivalence by showing that per-subspace product quantization allows each token's contribution in MaxSim to map to a sparse code lookup equivalent to learned-sparse retrieval, with the argmax preserved when reconstruction error is small relative to similarity margins. We agree the abstract asserts this without indicating the argument. We will revise the abstract to add a concise clause noting that the equivalence follows from subspace-independent quantization preserving per-token maxima, with the full derivation in the body. revision: yes
-
Referee: [Abstract] Abstract: the empirical claim of 50-70% size reduction versus one-bit PLAID while retaining effectiveness provides no datasets, metrics, experimental protocol, or error analysis, making it impossible to assess whether the product quantization actually preserves sufficient information for effective MaxSim after sparsification.
Authors: Abstracts are intentionally high-level; the manuscript details the protocol in Sections 4-5, including MS MARCO and TREC DL datasets, MRR@10/nDCG@10 metrics, and direct comparisons to one-bit PLAID showing 50-70% size reduction with effectiveness retained within 1-3%. Error analysis appears in the experimental results. We will add one sentence to the abstract specifying the benchmarks and retention margin to make the claim more self-contained. revision: partial
-
Referee: [Abstract] Abstract: the construction assumes that mapping quantized embeddings to inverted-index codes leaves the relative ordering of highest-similarity matches unchanged, but product quantization minimizes per-subspace reconstruction error rather than bounding changes to MaxSim; no analysis or bound is supplied to address this.
Authors: The referee is correct that PQ targets reconstruction error, not an explicit MaxSim bound. The manuscript supports the assumption via empirical retention of effectiveness rather than a formal bound on argmax changes. We will expand the theoretical section to explicitly discuss this distinction, provide intuition on why subspace quantization limits impact on MaxSim ordering, and either derive a loose bound or clarify the empirical grounding. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a theoretical equivalence between quantized ColBERT and learned-sparse retrieval (except scoring) as a derived result, alongside an empirical size comparison to an external one-bit PLAID baseline. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described construction. The equivalence claim is framed as a first-principles observation rather than a tautology or redefinition by construction, and the index sparsification is motivated by external efficiency concerns. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aleksandar Armacki, Dragana Bajovic, Dusan Jakovetic, and Soummya Kar
-
[2]
InInternational Conference on Machine Learning
Gradient based clustering. InInternational Conference on Machine Learning. PMLR, 929–947
- [3]
-
[4]
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Recipro- cal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. 758–759
2009
-
[5]
Thibault Formal, Stéphane Clinchant, Hervé Déjean, and Carlos Lassance. 2024. Splate: Sparse late interaction retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2635–2640
2024
- [6]
-
[7]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse lexical and expansion model for first stage ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval. 2288–2292
2021
-
[8]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. A white box analysis of ColBERT. InEuropean Conference on Information Retrieval. Springer, 257–263
2021
-
[9]
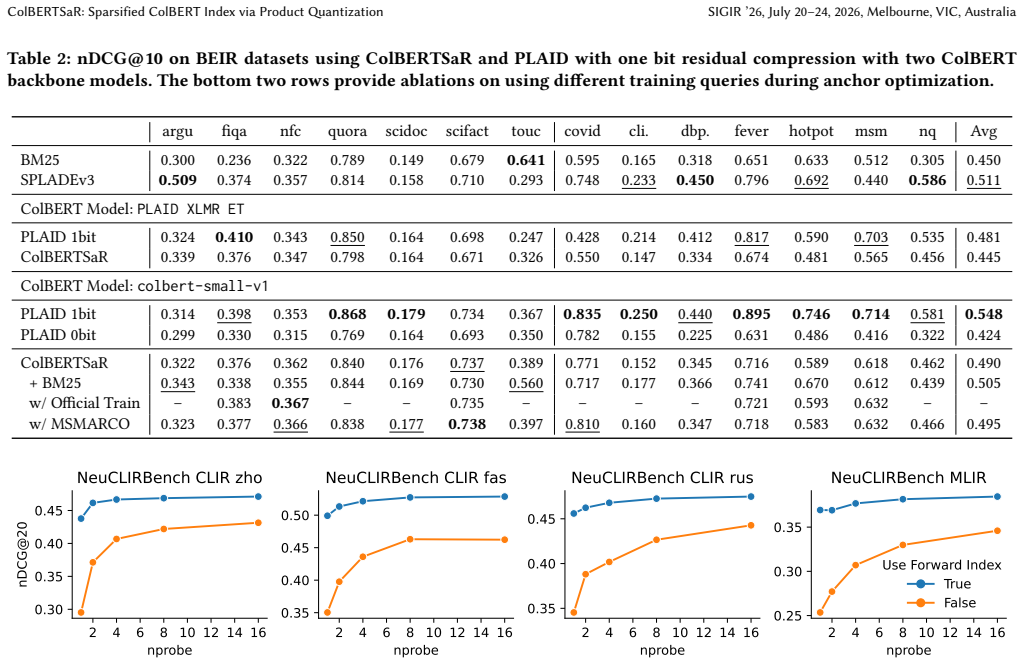
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quanti- zation.IEEE transactions on pattern analysis and machine intelligence36, 4 (2013), 744–755. ColBERTSaR: Sparsified ColBERT Index via Product Quantization SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Table 2: nDCG@10 on BEIR datasets using ColBERTSaR and PLAID with on...
-
[10]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravis- hankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion- point nearest neighbor search on a single node.Advances in neural information processing Systems32 (2019)
2019
-
[11]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[12]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
2020
-
[13]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
- [14]
-
[15]
Dawn Lawrie, James Mayfield, Eugene Yang, Andrew Yates, Sean MacAvaney, Ronak Pradeep, Scott Miller, Paul McNamee, and Luca Soldaini. 2026. Neu- CLIRTech: Chinese Monolingual and Cross-Language Information Retrieval Evaluation in a Challenging Domain.arXiv preprint arXiv:2602.05334(2026)
-
[16]
Dawn Lawrie, James Mayfield, Eugene Yang, Andrew Yates, Sean MacAvaney, Ronak Pradeep, Scott Miller, Paul McNamee, and Luca Soldani. 2025. NeuCLIR- Bench: A Modern Evaluation Collection for Monolingual, Cross-Language, and Multilingual Information Retrieval.arXiv preprint arXiv:2511.14758(2025)
-
[17]
Jinhyuk Lee, Zhuyun Dai, Sai Meher Karthik Duddu, Tao Lei, Iftekhar Naim, Ming-Wei Chang, and Vincent Zhao. 2024. Rethinking the role of token retrieval in multi-vector retrieval.Advances in Neural Information Processing Systems36 (2024)
2024
-
[18]
Minghan Li, Sheng-Chieh Lin, Barlas Oguz, Asish Ghoshal, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. 2023. CITADEL: Conditional token in- teraction via dynamic lexical routing for efficient and effective multi-vector re- trieval. InProceedings of the 61st Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers)....
2023
-
[19]
Sean MacAvaney and Nicola Tonellotto. 2024. A reproducibility study of plaid. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1411–1419
2024
-
[20]
Joel Mackenzie, Antonio Mallia, Alistair Moffat, and Matthias Petri. 2022. Ac- celerating learned sparse indexes via term impact decomposition. InFindings of the Association for Computational Linguistics: EMNLP 2022. 2830–2842
2022
-
[21]
Antonio Mallia, Omar Khattab, Torsten Suel, and Nicola Tonellotto. 2021. Learn- ing passage impacts for inverted indexes. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1723–1727
2021
-
[22]
Franco Maria Nardini, Cosimo Rulli, and Rossano Venturini. 2024. Efficient multi-vector dense retrieval with bit vectors. InEuropean Conference on Infor- mation Retrieval. Springer, 3–17
2024
- [23]
-
[24]
Thong Nguyen, Sean MacAvaney, and Andrew Yates. 2023. A unified framework for learned sparse retrieval. InEuropean Conference on Information Retrieval. Springer, 101–116
2023
-
[25]
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022. PLAID: an efficient engine for late interaction retrieval. InProceedings of the 31st SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Yang, et al. ACM International Conference on Information & Knowledge Management. 1747– 1756
2022
-
[26]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. Colbertv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of the 2022 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technolo- gies. 3715–3734
2022
-
[27]
Jan Luca Scheerer, Matei Zaharia, Christopher Potts, Gustavo Alonso, and Omar Khattab. 2025. WARP: An efficient engine for multi-vector retrieval. InProceed- ings of the 48th international ACM SIGIR conference on research and development in information retrieval. 2504–2512
2025
-
[28]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Xiao Wang, Craig Macdonald, Nicola Tonellotto, and Iadh Ounis. 2023. Repro- ducibility, replicability, and insights into dense multi-representation retrieval models: from colbert to col. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2552–2561
2023
-
[30]
Eugene Yang, Dawn Lawrie, and James Mayfield. 2024. Distillation for multi- lingual information retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2368–2373
2024
-
[31]
Eugene Yang, Dawn Lawrie, James Mayfield, Douglas W Oard, and Scott Miller
-
[32]
InEuropean Conference on Information Retrieval
Translate-distill: learning cross-language dense retrieval by translation and distillation. InEuropean Conference on Information Retrieval. Springer, 50– 65
-
[33]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.