Multilingual Fine-Tuning via Localized Gradient Conflict Resolution
Pith reviewed 2026-06-28 02:00 UTC · model grok-4.3
The pith
Localized multi-objective optimization on parameter buckets enforces refined Pareto stationarity in multilingual LLM fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
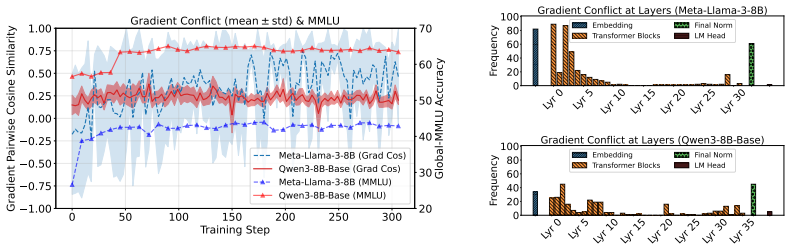
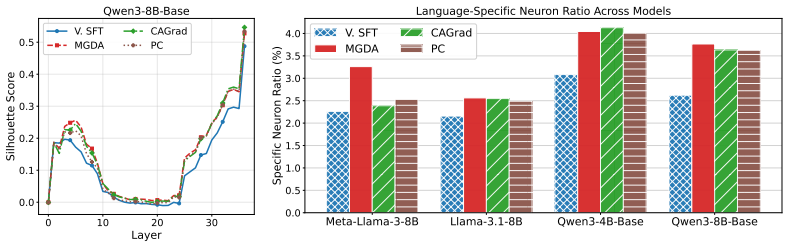
Bucket-Level MOO natively enforces Refined Pareto Stationarity, a strictly tighter necessary condition for Pareto optimality, by applying gradient-based MOO algorithms locally on parameter buckets. This mitigates interference by driving LLMs to construct distinct language-specific dimensions, improving representational separability and multilingual performance.
What carries the argument
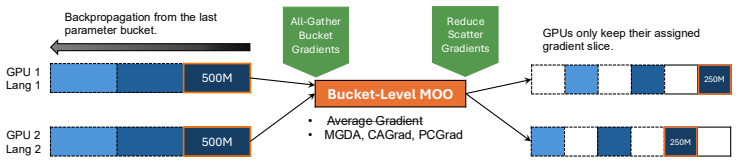
Bucket-Level MOO: a scalable distributed framework that applies gradient-based MOO algorithms locally on parameter buckets to enable conflict-aware updates without reconstructing full gradient vectors.
If this is right
- Improves performance on both seen and unseen languages compared to standard fine-tuning.
- Enhances representational separability by creating language-specific dimensions in the model.
- Scales to large LLMs by avoiding prohibitive communication overhead of full gradients.
- Provides a theoretical guarantee of refined Pareto stationarity through localized resolution.
Where Pith is reading between the lines
- Similar localized MOO techniques could address interference in other multi-task settings like instruction tuning or domain adaptation.
- The bucket approach implies that conflict resolution can be modularized, potentially allowing for dynamic bucket allocation based on observed conflicts.
- Testing on even larger models or more diverse language sets would further validate the scalability claims.
Load-bearing premise
That applying MOO locally on parameter buckets is sufficient to achieve global improvements in representational separability and performance without reconstructing or communicating full gradients.
What would settle it
An experiment that applies the method but finds no improvement in language separability or performance, or a proof that refined Pareto stationarity does not hold under the localized updates.
Figures

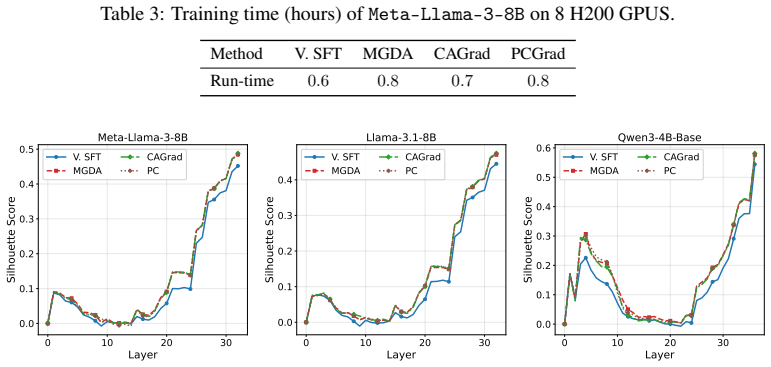
read the original abstract
The rapid evolution of Large Language Models (LLMs) has established cross-lingual versatility as a defining feature of modern systems. However, fine-tuning these models frequently induces negative interference across languages. To address this, we reformulate multilingual fine-tuning as a multi-objective optimization (MOO) problem. Specifically, we introduce Bucket-Level MOO, a scalable distributed framework that applies gradient-based MOO algorithms locally on parameter buckets. This enables conflict-aware updates without the prohibitive communication overhead of reconstructing full gradient vectors. Theoretically, we prove this localized resolution natively enforces Refined Pareto Stationarity, a strictly tighter necessary condition for Pareto optimality. Empirically, Bucket-Level MOO mitigates interference by driving LLMs to construct distinct language-specific dimensions, improving representational separability. Extensive experiments across four base LLMs demonstrate that our method significantly improves both seen and unseen multilingual performance over standard fine-tuning paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reformulates multilingual fine-tuning of LLMs as a multi-objective optimization (MOO) problem and proposes Bucket-Level MOO, which applies gradient-based MOO algorithms locally on parameter buckets to resolve conflicts scalably without reconstructing full gradients. It proves that this localized approach natively enforces Refined Pareto Stationarity (a strictly tighter necessary condition for Pareto optimality) and empirically shows that the method drives construction of distinct language-specific dimensions, yielding improved performance on both seen and unseen languages across four base LLMs compared to standard fine-tuning.
Significance. If the central theoretical claim holds, the work supplies a practical, communication-efficient framework for handling gradient conflicts in large-scale multilingual training, directly addressing negative interference. The empirical demonstration of enhanced representational separability and cross-lingual gains on multiple models provides concrete evidence of utility. The combination of a formal stationarity guarantee with distributed implementation is a notable strength for the field.
major comments (3)
- [§3] §3 (Theoretical Analysis), proof of Refined Pareto Stationarity: the claim that local per-bucket MOO 'natively enforces' the global refined condition requires an explicit argument that stationarity on bucket gradients implies the full-model condition; without cross-bucket gradient communication or stated independence assumptions, interactions spanning buckets could leave the global condition unsatisfied, directly undermining the central theoretical contribution.
- [§4] §4 (Experiments), bucket partitioning description: the empirical gains in representational separability and multilingual performance rest on the specific choice of parameter buckets, yet no ablation on bucket size, partitioning criterion, or number of buckets is reported; this leaves open whether the observed benefits arise from localization itself or from other implementation details.
- [§4.2] §4.2, Table 2 (performance metrics): the reported improvements on unseen languages are presented without variance across random seeds or statistical tests, making it difficult to assess whether the gains reliably exceed standard fine-tuning baselines and support the separability claim.
minor comments (3)
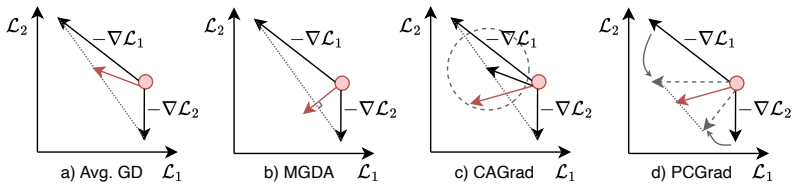
- [Introduction] Introduction: define 'parameter buckets' and the precise MOO algorithm (e.g., MGDA or similar) with a short equation or pseudocode before the theoretical claims.
- [Related Work] Related Work: include a brief comparison to prior distributed or federated MOO approaches to clarify novelty of the bucket-level localization.
- Notation: ensure consistent use of symbols for per-bucket gradients versus global gradients throughout the proofs and experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify opportunities to strengthen the theoretical exposition and empirical validation. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Analysis), proof of Refined Pareto Stationarity: the claim that local per-bucket MOO 'natively enforces' the global refined condition requires an explicit argument that stationarity on bucket gradients implies the full-model condition; without cross-bucket gradient communication or stated independence assumptions, interactions spanning buckets could leave the global condition unsatisfied, directly undermining the central theoretical contribution.
Authors: We appreciate the request for an explicit bridging argument. Section 3 defines refined Pareto stationarity component-wise over the parameter vector. Because the buckets form a disjoint partition of the parameters and the per-bucket gradients are computed independently with no cross-bucket terms in the gradient expression, satisfaction of the stationarity condition on each bucket directly implies the condition on the concatenated global gradient. We will add a short lemma in the revision that states this aggregation formally, together with the observation that the MOO solver is applied to the local gradient of each bucket. revision: yes
-
Referee: [§4] §4 (Experiments), bucket partitioning description: the empirical gains in representational separability and multilingual performance rest on the specific choice of parameter buckets, yet no ablation on bucket size, partitioning criterion, or number of buckets is reported; this leaves open whether the observed benefits arise from localization itself or from other implementation details.
Authors: We agree that systematic ablations would better isolate the contribution of localization. In the revised manuscript we will report additional experiments that vary (i) bucket granularity (layer-wise versus module-wise), (ii) the number of buckets, and (iii) the partitioning heuristic (random versus magnitude-based). These results will be placed in an expanded experimental section to demonstrate robustness of the observed gains. revision: yes
-
Referee: [§4.2] §4.2, Table 2 (performance metrics): the reported improvements on unseen languages are presented without variance across random seeds or statistical tests, making it difficult to assess whether the gains reliably exceed standard fine-tuning baselines and support the separability claim.
Authors: We acknowledge the value of reporting variability and significance. The revised version will include results averaged over three random seeds with standard deviations added to Table 2. We will also report paired statistical tests (e.g., t-tests) comparing Bucket-Level MOO against the standard fine-tuning baseline on the unseen-language metrics. revision: yes
Circularity Check
No significant circularity; theoretical claim presented as independent proof.
full rationale
The paper's central theoretical step is a stated proof that localized bucket-level MOO natively enforces Refined Pareto Stationarity as a stricter necessary condition. No equations or text in the provided abstract reduce this claim to a fitted parameter, self-definition, or self-citation chain; the result is framed as derived from the localized application rather than presupposed by it. Empirical claims of improved separability are presented as consequences of the method, not as inputs renamed as outputs. The derivation chain remains self-contained against external benchmarks with no load-bearing reductions to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Less, but Better: Efficient Multilingual Expansion for LLM s via Layer-wise Mixture-of-Experts
Zhang, Xue and Liang, Yunlong and Meng, Fandong and Zhang, Songming and Chen, Yufeng and Xu, Jinan and Zhou, Jie. Less, but Better: Efficient Multilingual Expansion for LLM s via Layer-wise Mixture-of-Experts. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.878
-
[2]
The Fourteenth International Conference on Learning Representations , year=
Multilingual Routing in Mixture-of-Experts , author=. The Fourteenth International Conference on Learning Representations , year=
-
[3]
When Less Language is More: Language-Reasoning Disentanglement Makes
Weixiang Zhao and Jiahe Guo and Yang Deng and Tongtong Wu and Wenxuan Zhang and Yulin Hu and Xingyu Sui and Yanyan Zhao and Wanxiang Che and Bing Qin and Tat-Seng Chua and Ting Liu , booktitle=. When Less Language is More: Language-Reasoning Disentanglement Makes. 2026 , url=
2026
-
[4]
2026 , eprint=
Language of Thought Shapes Output Diversity in Large Language Models , author=. 2026 , eprint=
2026
-
[5]
and Tu, Zhuowen and Bergen, Benjamin K
Chang, Tyler A. and Tu, Zhuowen and Bergen, Benjamin K. The Geometry of Multilingual Language Model Representations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.9
-
[6]
Advances in Neural Information Processing Systems , editor=
Less-forgetting Multi-lingual Fine-tuning , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[7]
International Conference on Learning Representations , year=
Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models , author=. International Conference on Learning Representations , year=
-
[8]
Synergy over Discrepancy: A Partition-Based Approach to Multi-Domain
Hua Ye and Siyuan Chen and Haoliang Zhang and Weihao Luo and Yanbin Li and Xuan Zhang , booktitle=. Synergy over Discrepancy: A Partition-Based Approach to Multi-Domain. 2025 , url=
2025
-
[9]
Journal of Computational and Applied Mathematics , author =
Peter J. Rousseeuw , keywords =. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis , journal =. 1987 , issn =. doi:https://doi.org/10.1016/0377-0427(87)90125-7 , url =
-
[10]
Forty-first International Conference on Machine Learning , year=
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications , author=. Forty-first International Conference on Machine Learning , year=
-
[11]
2023 , eprint=
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel , author=. 2023 , eprint=
2023
-
[12]
2020 , eprint=
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models , author=. 2020 , eprint=
2020
-
[13]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , url =
Penedo, Guilherme and Kydl\'. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , url =. Advances in Neural Information Processing Systems , doi =
-
[14]
2025 , eprint=
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
MuBench: Assessment of Multilingual Capabilities of Large Language Models Across 61 Languages , author=. 2025 , eprint=
2025
-
[16]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[17]
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Bandarkar, Lucas and Liang, Davis and Muller, Benjamin and Artetxe, Mikel and Shukla, Satya Narayan and Husa, Donald and Goyal, Naman and Krishnan, Abhinandan and Zettlemoyer, Luke and Khabsa, Madian. The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants. Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[18]
2024 , eprint=
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation , author=. 2024 , eprint=
2024
-
[19]
Muennighoff, Niklas and Yang, Zitong and Shi, Weijia and Li, Xiang Lisa and Fei-Fei, Li and Hajishirzi, Hannaneh and Zettlemoyer, Luke and Liang, Percy and Candes, Emmanuel and Hashimoto, Tatsunori. s1: Simple test-time scaling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1025
-
[20]
Conflict-Averse Gradient Descent for Multi-task learning , url =
Liu, Bo and Liu, Xingchao and Jin, Xiaojie and Stone, Peter and Liu, Qiang , booktitle =. Conflict-Averse Gradient Descent for Multi-task learning , url =
-
[21]
LIMA: Less Is More for Alignment , url =
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srinivasan and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and YU, LILI and Zhang, Susan and Ghosh, Gargi and Lewis, Mike and Zettlemoyer, Luke and Levy, Omer , booktitle =. LIMA: Less Is More for Alignment , url =
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Leveraging Variable Sparsity to Refine Pareto Stationarity in Multi-Objective Optimization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Naval research logistics quarterly , volume=
An algorithm for quadratic programming , author=. Naval research logistics quarterly , volume=. 1956 , publisher=
1956
-
[24]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[25]
Comptes Rendus Mathematique , volume=
Multiple-gradient descent algorithm (MGDA) for multiobjective optimization , author=. Comptes Rendus Mathematique , volume=. 2012 , publisher=
2012
-
[26]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[28]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[29]
How do Large Language Models Handle Multilingualism? , url =
Zhao, Yiran and Zhang, Wenxuan and Chen, Guizhen and Kawaguchi, Kenji and Bing, Lidong , booktitle =. How do Large Language Models Handle Multilingualism? , url =. doi:10.52202/079017-0489 , editor =
-
[30]
Towards Understanding Multi-Task Learning (Generalization) of LLM s via Detecting and Exploring Task-Specific Neurons
Leng, Yongqi and Xiong, Deyi. Towards Understanding Multi-Task Learning (Generalization) of LLM s via Detecting and Exploring Task-Specific Neurons. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[31]
The Emergence of Abstract Thought in Large Language Models Beyond Any Language , year =
Yuxin Chen and Yiran Zhao and Yang Zhang and An Zhang and Kenji Kawaguchi and Shafiq Joty and Junnan Li and Tat-Seng Chua and Michael Qizhe Shieh and Wenxuan Zhang , booktitle =. The Emergence of Abstract Thought in Large Language Models Beyond Any Language , year =
-
[32]
Frontiers of Computer Science , volume=
A survey on multilingual large language models: Corpora, alignment, and bias , author=. Frontiers of Computer Science , volume=. 2025 , publisher=
2025
-
[33]
When Less Language is More: Language-Reasoning Disentanglement Makes
Weixiang Zhao and Jiahe Guo and Yang Deng and Tongtong Wu and Wenxuan Zhang and Yulin Hu and Xingyu Sui and Yanyan Zhao and Wanxiang Che and Bing Qin and Tat-Seng Chua and Ting Liu , booktitle=. When Less Language is More: Language-Reasoning Disentanglement Makes. 2025 , url=
2025
-
[34]
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[35]
Wang, Zirui and Lipton, Zachary C. and Tsvetkov, Yulia. On Negative Interference in Multilingual Models: Findings and A Meta-Learning Treatment. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.359
-
[36]
Gradient Surgery for Multi-Task Learning , url =
Yu, Tianhe and Kumar, Saurabh and Gupta, Abhishek and Levine, Sergey and Hausman, Karol and Finn, Chelsea , booktitle =. Gradient Surgery for Multi-Task Learning , url =
-
[37]
The Eleventh International Conference on Learning Representations , year=
Recon: Reducing Conflicting Gradients From the Root For Multi-Task Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
Crosslingual Generalization through Multitask Finetuning
Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Le Scao, Teven and Bari, M Saiful and Shen, Sheng and Yong, Zheng Xin and Schoelkopf, Hailey and Tang, Xiangru and Radev, Dragomir and Aji, Alham Fikri and Almubarak, Khalid and Albanie, Samuel and Alyafeai, Zaid and Webson, Albert and Raff, Edward and Ra...
-
[39]
2023 , eprint=
Bactrian-X: Multilingual Replicable Instruction-Following Models with Low-Rank Adaptation , author=. 2023 , eprint=
2023
-
[40]
Pan, Xingyuan and Huang, Luyang and Kang, Liyan and Liu, Zhicheng and Lu, Yu and Cheng, Shanbo. G - DIG : Towards Gradient-based DI verse and hi G h-quality Instruction Data Selection for Machine Translation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.821
-
[41]
Zhang, Yuanchi and Wang, Yile and Liu, Zijun and Wang, Shuo and Wang, Xiaolong and Li, Peng and Sun, Maosong and Liu, Yang. Enhancing Multilingual Capabilities of Large Language Models through Self-Distillation from Resource-Rich Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 202...
-
[42]
Monolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca
Chen, Pinzhen and Ji, Shaoxiong and Bogoychev, Nikolay and Kutuzov, Andrey and Haddow, Barry and Heafield, Kenneth. Monolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[43]
Advances in Neural Information Processing Systems 31 , editor =
Multi-Task Learning as Multi-Objective Optimization , author =. Advances in Neural Information Processing Systems 31 , editor =. 2018 , publisher =
2018
-
[44]
Mathematical methods of operations research , volume=
Steepest descent methods for multicriteria optimization , author=. Mathematical methods of operations research , volume=. 2000 , publisher=
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.