ShotCrop³: Cropping Human-Centric Images into Cinematic Triple-Shot Compositions
Pith reviewed 2026-06-28 02:29 UTC · model grok-4.3
The pith
ShotCrop crops one human-centric image into three cinematic shots—establishing, medium, and close-up—each with a description, reaching 2.82 times the shot localization accuracy of GPT-5.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
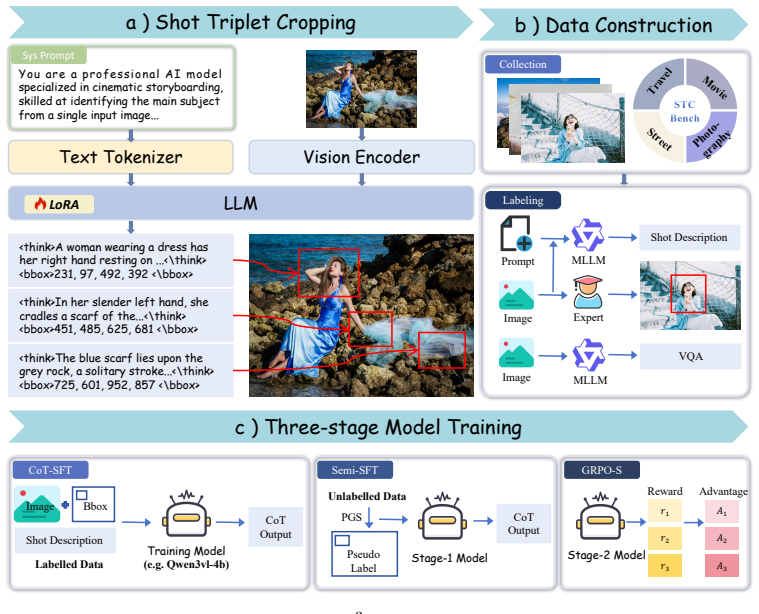
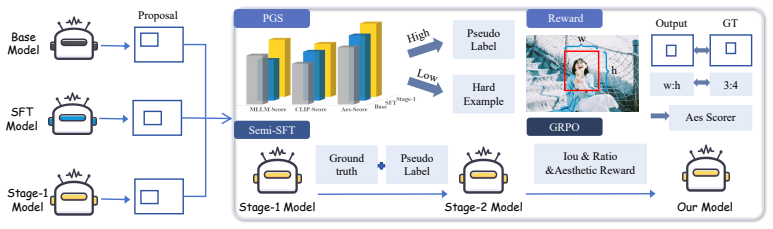
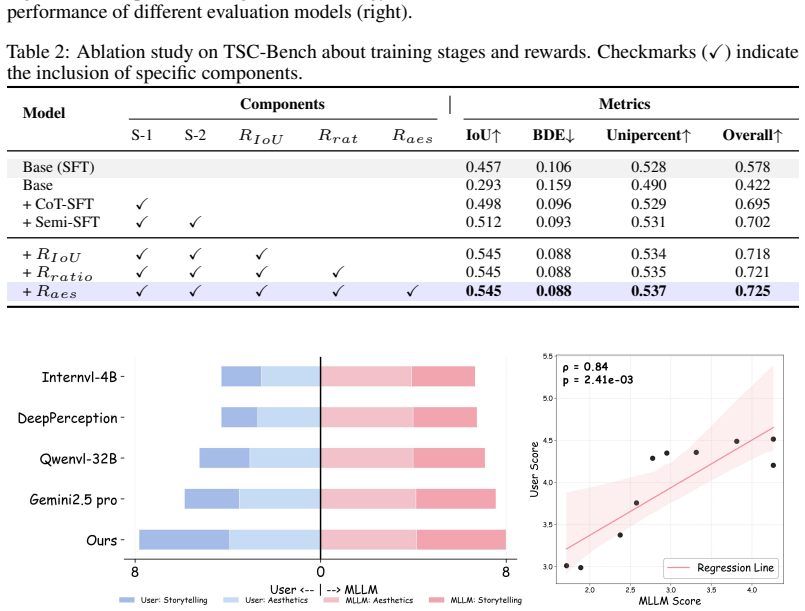
The central claim is that Triple-Shot Compositions can be learned from limited expert data by training ShotCrop in three stages: Chain-of-Thought supervised fine-tuning to build basic shot-cropping reasoning, semi-supervised fine-tuning that retains only high-confidence pseudo labels produced by combining MLLM scoring, aesthetic assessment, and CLIP similarity, and final optimization with Group Relative Policy Optimization using a composite reward; on the resulting TSC-Bench of 1.2k expert cases the model improves average shot localization accuracy by a factor of 2.82 over GPT-5.
What carries the argument
The three-stage training pipeline of ShotCrop that first establishes reasoning via Chain-of-Thought fine-tuning, then augments data with multi-signal pseudo labels, and finally refines the policy through GRPO-S with a reward that scores localization, aesthetics, and narrative fit.
If this is right
- Commercial poster and storyboarding tools can output ready sets of three narrative crops with descriptions from one source image.
- The TSC-Bench supplies a fixed testbed for comparing future multi-shot composition models.
- The same staged training pattern can be reused for other tasks that need both localization and aesthetic quality when expert labels are scarce.
- The composite reward used in GRPO-S directly ties model updates to measurable improvements in shot positioning and narrative coverage.
Where Pith is reading between the lines
- The approach could be tested on non-human subjects or full video frames to see whether the pseudo-labeling still produces reliable signals outside the human-centric case.
- Embedding the model in consumer photo apps would let ordinary users generate multiple narrative crops automatically rather than cropping by hand.
- Running the pseudo-label pipeline on images with unusual lighting or poses would reveal whether any of the three scoring signals introduces consistent errors.
Load-bearing premise
The pseudo-labeling strategy that merges MLLM scoring, aesthetic assessment, and CLIP similarity produces training signals that match expert judgment without systematic bias or noise.
What would settle it
Measure shot localization accuracy and description quality of ShotCrop versus GPT-5 on a fresh set of several hundred expert-annotated human-centric images; if the factor of improvement falls well below 2.82 or varies sharply by shot type, the central performance claim does not hold.
Figures

















read the original abstract
Prior work on aesthetic composition typically produces a single aesthetically pleasing crop, overlooking the narrative value of composing multiple shots from one scene. In practice, multi-shot composition is critical for downstream creative workflows: commercial posters often require multiple crops with different emphases (e.g., context, subject, and emotion/product details) to present key story beats. Therefore, we propose \textbf{Triple-Shot Compositions (TSC)}, a composition task that generates a three-shot set -- establishing, medium, and close-up -- from a single human-centric image, each paired with a brief shot description to support visual narration. To learn TSC with limited expert annotations, we introduce \textbf{ShotCrop} which undergoes a three-stage training process: it first applies Chain-of-Thought supervised fine-tuning to establish basic reasoning and aesthetic shot-cropping skills, then performs semi-supervised fine-tuning with high-confidence pseudo labels to further enhance aesthetic capability, and is finally optimized with Group Relative Policy Optimization for \textbf{ShotCrop} (GRPO-S) using a composite reward tailored for it. Specifically, our pseudo-labeling strategy combines MLLM-based scoring, aesthetic assessment, and CLIP similarity to retain high-confidence training signals. In addition, we present TSC-Bench, a benchmark of 1.2k expert-annotated test cases. Notably, ShotCrop achieves an average improvement of \textbf{2.82} times over GPT-5 in shot localization accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Triple-Shot Compositions (TSC), a task to generate three cinematic shots (establishing, medium, and close-up) with descriptions from a single human-centric image. It proposes the ShotCrop model trained via a three-stage process: Chain-of-Thought supervised fine-tuning, semi-supervised fine-tuning with high-confidence pseudo labels from MLLM scoring, aesthetic assessment, and CLIP similarity, and optimization with Group Relative Policy Optimization (GRPO-S). The authors present TSC-Bench, a 1.2k expert-annotated benchmark, and claim that ShotCrop achieves an average 2.82 times improvement over GPT-5 in shot localization accuracy.
Significance. If the performance claims hold after verification of the pseudo-labeling process, this work could contribute to advancing AI-assisted cinematic composition tools for creative industries by addressing multi-shot narrative needs rather than single crops. The introduction of a specialized benchmark is a positive step, but the significance is tempered by the lack of validation for the training signals.
major comments (2)
- [Abstract] Abstract: The claim of a 2.82 times improvement in shot localization accuracy over GPT-5 lacks a definition of the accuracy metric, details on the evaluation protocol, error bars, statistical significance tests, or dataset split information, making it impossible to assess the reliability of the central result.
- [Abstract (pseudo-labeling strategy)] Abstract (pseudo-labeling strategy): The semi-supervised stage relies on high-confidence pseudo labels from MLLM-based scoring, aesthetic assessment, and CLIP similarity, but no correlation statistics or ablation studies are provided to verify that these pseudo labels align with the expert annotations in TSC-Bench, which is critical for the validity of the reported performance gain.
minor comments (1)
- The paper would benefit from clearer notation for the reward function in GRPO-S and more details on the composite reward tailored for ShotCrop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the pseudo-labeling validation. We address each major comment below and will revise the manuscript to improve clarity and provide additional supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 2.82 times improvement in shot localization accuracy over GPT-5 lacks a definition of the accuracy metric, details on the evaluation protocol, error bars, statistical significance tests, or dataset split information, making it impossible to assess the reliability of the central result.
Authors: We agree that the abstract would benefit from additional context on the central claim despite space constraints. Shot localization accuracy is defined as the fraction of predicted bounding boxes with IoU > 0.5 against expert annotations on TSC-Bench. The full evaluation protocol (including the 1.2k expert-annotated cases, train/test split details, error bars from repeated runs, and statistical significance testing) appears in Sections 4.1–4.2. We will revise the abstract to include a concise definition of the metric and a pointer to the evaluation section. revision: yes
-
Referee: [Abstract (pseudo-labeling strategy)] Abstract (pseudo-labeling strategy): The semi-supervised stage relies on high-confidence pseudo labels from MLLM-based scoring, aesthetic assessment, and CLIP similarity, but no correlation statistics or ablation studies are provided to verify that these pseudo labels align with the expert annotations in TSC-Bench, which is critical for the validity of the reported performance gain.
Authors: The manuscript does not currently report explicit correlation statistics or ablations between the pseudo-labeling signals and TSC-Bench expert annotations. TSC-Bench serves as a held-out test set, so we will add a new analysis in the revision: correlation coefficients computed on a held-out validation subset of the training data, plus an ablation study that removes each scoring component (MLLM, aesthetic, CLIP) in turn. These additions will appear in Section 3.2 to directly address the alignment concern. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLM-based scoring combined with aesthetic assessment and CLIP similarity reliably identifies high-quality pseudo labels for shot cropping.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2512.21675 (2025)
Shuo Cao, Jiayang Li, Xiaohui Li, Yuandong Pu, Kaiwen Zhu, Yuanting Gao, Siqi Luo, Yi Xin, Qi Qin, Yu Zhou, et al. Unipercept: Towards unified perceptual-level image understanding across aesthetics, quality, structure, and texture.arXiv preprint arXiv:2512.21675, 2025
-
[3]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yolo-world: Real- time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real- time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
2024
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Learning subject- aware cropping by outpainting professional photos
James Hong, Lu Yuan, Michaël Gharbi, Matthew Fisher, and Kayvon Fatahalian. Learning subject- aware cropping by outpainting professional photos. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 2175–2183, 2024
2024
-
[7]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
2024
-
[8]
Beyond image borders: Learning feature extrapolation for unbounded image composition
Xiaoyu Liu, Ming Liu, Junyi Li, Shuai Liu, Xiaotao Wang, Lei Lei, and Wangmeng Zuo. Beyond image borders: Learning feature extrapolation for unbounded image composition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13023–13032, 2023
2023
-
[9]
Groma: Localized visual tokenization for grounding multimodal large language models
Chuofan Ma, Yi Jiang, Jiannan Wu, Zehuan Yuan, and Xiaojuan Qi. Groma: Localized visual tokenization for grounding multimodal large language models. InEuropean Conference on Computer Vision, pages 417–435. Springer, 2024
2024
-
[10]
Xinyu Ma, Ziyang Ding, Zhicong Luo, Chi Chen, Zonghao Guo, Derek F Wong, Xiaoyi Feng, and Maosong Sun. Deepperception: Advancing r1-like cognitive visual perception in mllms for knowledge-intensive visual grounding.arXiv preprint arXiv:2503.12797, 2025
-
[11]
Image cropping under design constraints
Takumi Nishiyasu, Wataru Shimoda, and Yoichi Sato. Image cropping under design constraints. In Proceedings of the 5th ACM International Conference on Multimedia in Asia, pages 1–7, 2023
2023
-
[12]
Find beauty in the rare: Contrastive composition feature clustering for nontrivial cropping box regression
Zhiyu Pan, Yinpeng Chen, Jiale Zhang, Hao Lu, Zhiguo Cao, and Weicai Zhong. Find beauty in the rare: Contrastive composition feature clustering for nontrivial cropping box regression. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 2011–2019, 2023
2011
-
[13]
Pseudo label fusion with uncertainty estimation for semi-supervised cropping box regression.IEEE Transactions on Multimedia, 26:8157–8171, 2024
Zhiyu Pan, Jiahao Cui, Kewei Wang, Yizheng Wu, and Zhiguo Cao. Pseudo label fusion with uncertainty estimation for semi-supervised cropping box regression.IEEE Transactions on Multimedia, 26:8157–8171, 2024
2024
-
[14]
Zoomer: Adaptive image focus optimization for black-box mllm
Jiaxu Qian, Chendong Wang, Yifan Yang, Chaoyun Zhang, Huiqiang Jiang, Xufang Luo, Yu Kang, Qingwei Lin, Anlan Zhang, Shiqi Jiang, et al. Zoomer: Adaptive image focus optimization for black-box mllm. arXiv preprint arXiv:2505.00742, 2025
-
[15]
arXiv preprint arXiv:2411.14347 (2024)
Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, et al. Dino-x: A unified vision model for open-world object detection and understanding.arXiv preprint arXiv:2411.14347, 2024
-
[16]
Instructcrop: Teaching multimodal large language models to crop aesthetic images
Xiangfei Sheng, Pangu Xie, Weidong Zou, Pengfei Chen, Tong Zhu, and Leida Li. Instructcrop: Teaching multimodal large language models to crop aesthetic images. InProceedings of the 33rd ACM International Conference on Multimedia, pages 6830–6839, 2025
2025
-
[17]
Joint probability distribution regression for image cropping
Tengfei Shi, Chenglizhao Chen, Yuanbo He, Wenfeng Song, and Aimin Hao. Joint probability distribution regression for image cropping. In2023 IEEE International Conference on Image Processing (ICIP), pages 990–994. IEEE, 2023. 10
2023
-
[18]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Spatial-semantic collaborative cropping for user generated content
Yukun Su, Yiwen Cao, Jingliang Deng, Fengyun Rao, and Qingyao Wu. Spatial-semantic collaborative cropping for user generated content. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4988–4997, 2024
2024
-
[20]
Image cropping with spatial-aware feature and rank consistency
Chao Wang, Li Niu, Bo Zhang, and Liqing Zhang. Image cropping with spatial-aware feature and rank consistency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10052–10061, 2023
2023
-
[21]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Good view hunting: Learning photo composition from dense view pairs
Zijun Wei, Jianming Zhang, Xiaohui Shen, Zhe Lin, Radomir Mech, Minh Hoai, and Dimitris Samaras. Good view hunting: Learning photo composition from dense view pairs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5437–5446, 2018
2018
-
[23]
Aescrop: Aesthetic-driven cropping guided by composition
Yen-Hong Wong and Lai-Kuan Wong. Aescrop: Aesthetic-driven cropping guided by composition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3906–3913, 2025
2025
-
[24]
Focusing on your subject: Deep subject-aware image composition recommendation networks.Computational Visual Media, 9(1):87–107, 2023
Guo-Ye Yang, Wen-Yang Zhou, Yun Cai, Song-Hai Zhang, and Fang-Lue Zhang. Focusing on your subject: Deep subject-aware image composition recommendation networks.Computational Visual Media, 9(1):87–107, 2023
2023
-
[25]
PhotoFramer: Multi-modal Image Composition Instruction
Zhiyuan You, Ke Wang, He Zhang, Xin Cai, Jinjin Gu, Tianfan Xue, Chao Dong, and Zhoutong Zhang. Photoframer: Multi-modal image composition instruction.arXiv preprint arXiv:2512.00993, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aesthetic image cropping meets vlp: Enhancing good while reducing bad.Journal of Visual Communication and Image Representation, 105:104316, 2024
Quan Yuan, Leida Li, and Pengfei Chen. Aesthetic image cropping meets vlp: Enhancing good while reducing bad.Journal of Visual Communication and Image Representation, 105:104316, 2024
2024
-
[27]
Reliable and efficient image cropping: A grid anchor based approach
Hui Zeng, Lida Li, Zisheng Cao, and Lei Zhang. Reliable and efficient image cropping: A grid anchor based approach. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5949–5957, 2019
2019
-
[28]
Human-centric image cropping with partition-aware and content-preserving features
Bo Zhang, Li Niu, Xing Zhao, and Liqing Zhang. Human-centric image cropping with partition-aware and content-preserving features. InEuropean Conference on Computer Vision, pages 181–197. Springer, 2022
2022
-
[29]
Ke Zhang, Tianyu Ding, Jiachen Jiang, Tianyi Chen, Ilya Zharkov, Vishal M Patel, and Luming Liang. Pro- crop: Learning aesthetic image cropping from professional compositions.arXiv preprint arXiv:2505.22490, 2025
-
[30]
sequence of shots,
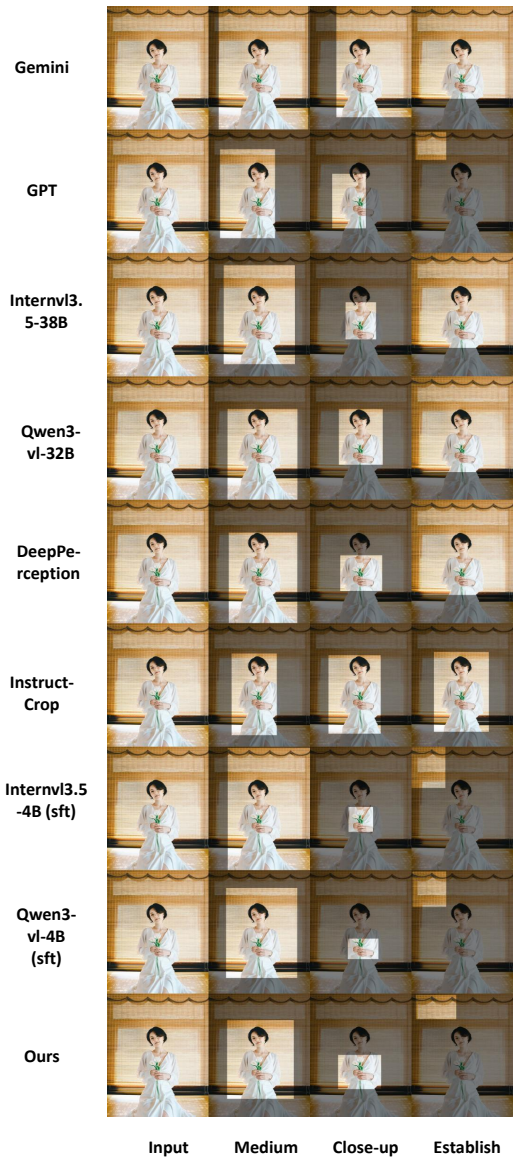
Zhihang Zhong, Mingxi Cheng, Zhirong Wu, Yuhui Yuan, Yinqiang Zheng, Ji Li, Han Hu, Stephen Lin, Yoichi Sato, and Imari Sato. Clipcrop: conditioned cropping driven by vision-language model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 294–304, 2023. 11 A Qualitative Comparison Figures 9-16 present additional qualitativ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.