FIDES: Faithful Inference via Deep Evidence Signals for Retrieval-Memory Conflict in RAG
Pith reviewed 2026-06-28 01:50 UTC · model grok-4.3
The pith
FIDES detects token-level retrieval-memory conflicts using three internal signals and applies contrastive decoding only where needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
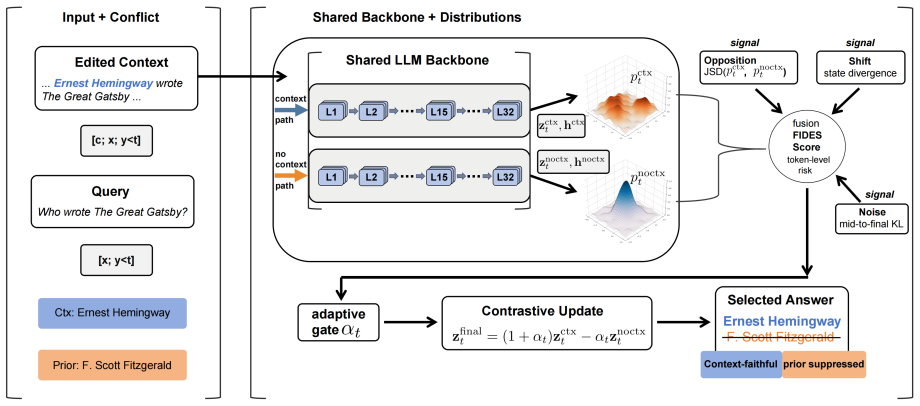
FIDES is a training-free decoder that fuses three complementary internal signals—output surface, hidden representations, and prediction trajectory—to produce a per-token measure of retrieval-memory conflict and thereby governs the strength of contrastive intervention at each decoding step, reframing the problem from how much contrast to apply to where to apply it.
What carries the argument
The per-token conflict score obtained by fusing three internal signals that probe retrieval-memory tension at output, representation, and trajectory depths.
If this is right
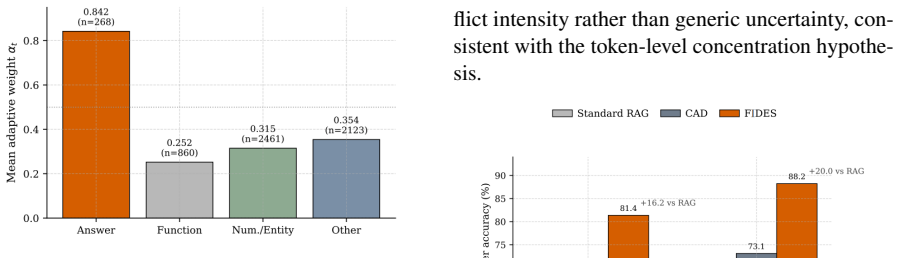
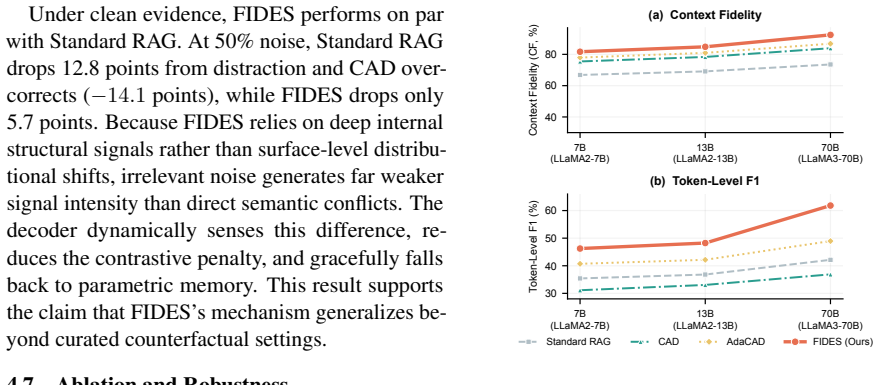
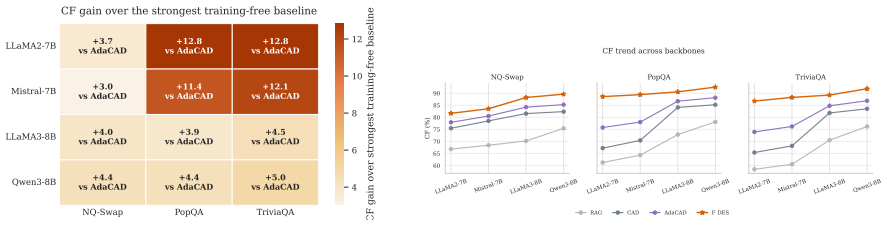
- Context fidelity improves in all 18 tested settings by 3 to 13 points over the strongest training-free baseline.
- On 70B models the method reaches 92-94 percent fidelity while F1 rises to 62-63 percent.
- Token-level selectivity avoids the over-correction that global contrastive weights produce.
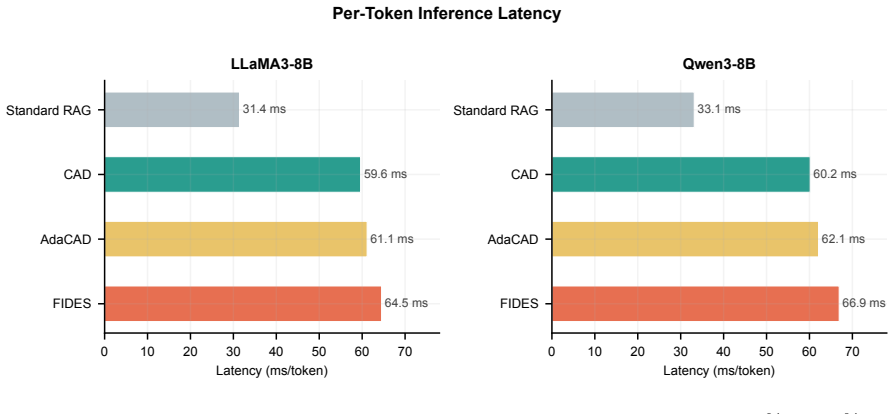
- The approach remains training-free and works across 7B to 70B backbones.
Where Pith is reading between the lines
- The same signal-fusion idea could be tested on other internal conflicts such as instruction-following versus safety rules.
- If the conflict scores prove stable across domains, they could serve as an unsupervised diagnostic for when retrieval augmentation is likely to fail.
- Replacing the fixed fusion rule with a small learned module might further improve selectivity while still avoiding full retraining.
Load-bearing premise
The three internal signals can be combined into a reliable per-token conflict measure without training or labeled conflict examples.
What would settle it
Run controlled prompts where specific tokens are known to be retrieval-memory conflicts and check whether the fused signal assigns markedly higher conflict scores to exactly those tokens than to safe tokens.
Figures


read the original abstract
When retrieved evidence contradicts parametric memory, language models frequently ignore context and default to memorized priors -- a failure that undermines the core purpose of retrieval augmentation. Contrastive decoding amplifies the context-conditioned output to suppress parametric bias, but existing methods rest on an implicit assumption that this bias is uniform across tokens. A single global contrastive weight over-penalizes safe tokens while leaving genuinely conflicted ones insufficiently corrected. We identify token-level conflict concentration: retrieval-memory tension is sharply heterogeneous, concentrated on a small fraction of answer-critical decoding steps. This reframes contrastive decoding from how much contrast to apply to where to apply it. We propose FIDES (Faithful Inference via Deep Evidence Signals), a training-free decoder that reads three internal signals probing retrieval-memory conflict at complementary depths -- output surface, hidden representations, and prediction trajectory -- and fuses them to govern intervention strength at each decoding step. Across three benchmarks and six backbones -- four primary 7B/8B models and two scaling backbones up to 70B -- FIDES achieves the best context fidelity in all 18 settings, outperforming the strongest training-free baseline by +3 to +13 points. On the 70B scale, fidelity reaches 92-94% while F1 surges to 62-63%, demonstrating that token-level selectivity unlocks generation capability that coarse contrastive rules suppress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FIDES, a training-free decoder for RAG that detects token-level retrieval-memory conflicts via three internal signals (output surface, hidden representations, prediction trajectory) and fuses them to selectively modulate contrastive decoding strength. It claims this reframes contrastive decoding from global to token-selective intervention, yielding best-in-class context fidelity across three benchmarks and six backbones (7B-70B), with gains of +3 to +13 points over training-free baselines and fidelity/F1 reaching 92-94%/62-63% at 70B scale.
Significance. If the per-token fusion rule proves reliable without training or labeled data, the approach would meaningfully advance training-free faithfulness techniques by exploiting conflict heterogeneity rather than uniform penalties. The multi-scale evaluation (including 70B models) and emphasis on internal signals are positive features; the training-free claim and consistent outperformance across 18 settings would be notable if the heuristic is shown to generalize.
major comments (3)
- [Method] Method section (fusion rule definition): the paper provides no explicit equation or pseudocode for how the three signals are combined into the per-token conflict measure or intervention strength (e.g., no formula for weighting, thresholding, or aggregation). This is load-bearing for the central claim, as the method is presented as a fixed, training-free heuristic whose reliability determines whether the reported gains over global contrastive baselines hold.
- [Experiments] Experiments (§4 or equivalent results tables): no ablation isolating the contribution of each of the three signals, no error bars or statistical tests on the fidelity/F1 numbers, and no description of how the fusion hyperparameters (if any) were chosen. The claim of best performance in all 18 settings therefore rests on unreported implementation details, as noted in the soundness assessment.
- [Method] §3 (signal definitions): the mapping from each internal signal to a conflict indicator is described at a high level but lacks concrete validation (e.g., correlation with known conflict tokens or comparison to oracle labels). Without this, it remains unclear whether the signals isolate genuine retrieval-memory tension rather than model-specific artifacts.
minor comments (2)
- [Abstract] Abstract and introduction: the phrase 'fuses them to govern intervention strength' is repeated without a forward reference to the precise definition; a single sentence pointing to the equation would improve clarity.
- [Experiments] Figure captions and tables: ensure all reported metrics include the exact number of runs or seeds used, even if error bars are added later.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below, agreeing that additional formalization and analysis will improve the manuscript. We will make the necessary revisions accordingly.
read point-by-point responses
-
Referee: [Method] Method section (fusion rule definition): the paper provides no explicit equation or pseudocode for how the three signals are combined into the per-token conflict measure or intervention strength (e.g., no formula for weighting, thresholding, or aggregation). This is load-bearing for the central claim, as the method is presented as a fixed, training-free heuristic whose reliability determines whether the reported gains over global contrastive baselines hold.
Authors: We agree that the absence of an explicit equation for the fusion rule is a significant omission that affects the clarity and reproducibility of the method. Although the combination logic is detailed in the text of Section 3, providing a mathematical formulation is necessary to fully support the claims. In the revised manuscript, we will add a dedicated equation defining the per-token intervention strength as a function of the three signals (output, hidden, trajectory), including any weighting or thresholding steps, and include pseudocode for the overall decoding algorithm. revision: yes
-
Referee: [Experiments] Experiments (§4 or equivalent results tables): no ablation isolating the contribution of each of the three signals, no error bars or statistical tests on the fidelity/F1 numbers, and no description of how the fusion hyperparameters (if any) were chosen. The claim of best performance in all 18 settings therefore rests on unreported implementation details, as noted in the soundness assessment.
Authors: We acknowledge these gaps in the experimental presentation. To address them, we will include a comprehensive ablation study that evaluates the performance when using each individual signal as well as all pairwise combinations, compared to the full fusion. We will also recompute the main results with multiple random seeds to provide error bars (standard deviation) and conduct statistical tests to confirm the significance of improvements over baselines. Furthermore, we will add a subsection detailing the hyperparameter selection process, which was performed on a held-out validation split from the benchmarks. revision: yes
-
Referee: [Method] §3 (signal definitions): the mapping from each internal signal to a conflict indicator is described at a high level but lacks concrete validation (e.g., correlation with known conflict tokens or comparison to oracle labels). Without this, it remains unclear whether the signals isolate genuine retrieval-memory tension rather than model-specific artifacts.
Authors: The signals were designed based on established techniques for probing model internals, and their utility is demonstrated empirically through superior performance. However, we agree that direct validation would strengthen the methodological contribution. In the revision, we will add an analysis section that computes correlations between each signal's values and tokens identified as high-conflict via an oracle (defined as tokens where the model's output differs significantly with and without the retrieved context). This will provide evidence that the signals capture retrieval-memory conflicts specifically. revision: yes
Circularity Check
No circularity; training-free heuristic on internal signals is self-contained.
full rationale
The paper describes FIDES as a training-free decoder that fuses three internal signals (output surface, hidden representations, prediction trajectory) to modulate contrastive decoding at token level. No equations, fitted parameters, self-citations, or uniqueness theorems are referenced in the provided text that would reduce the fusion rule or performance claims to a definition or input by construction. The method is presented as an empirical heuristic applied to model internals, with reported gains treated as external validation across benchmarks and scales. This satisfies the default expectation of no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6835–6855, Suzhou, China
CoCoA: Confidence- and context-aware adap- tive decoding for resolving knowledge conflicts in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6835–6855, Suzhou, China. Association for Computational Linguistics. Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins,...
2025
-
[2]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg
Curran Associates, Inc. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023a. Inference- time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, volume 36, pages 41451–41530. Curran Associates, Inc. Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, J...
-
[3]
Entity-based knowledge conflicts in question answering. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic. Association for Computational Linguistics. Xuhua Ma, Richong Zhang, and Zhijie Nie. 2026. CoRect: Context-aware logit contrast for hidden state rec...
-
[4]
strongest same-budget training-free base- line
ReDeEP: Detecting hallucination in retrieval- augmented generation via mechanistic interpretabil- ity. InThe Thirteenth International Conference on Learning Representations. Spotlight. Xiaqiang Tang, Yi Wang, Keyu Hu, Rui Xu, Chuang Li, Weigao Sun, Jian Li, and Sihong Xie. 2025. SSFO: Self-supervised faithfulness optimization for retrieval-augmented gener...
-
[5]
Run the context path on [d;x;y <t] and the no- context path on[x;y <t]
-
[6]
Extract the next-token logits and last-token hidden states from both paths
-
[7]
Compute Opposition t, Shift t, and Noise t using Eqs. (2)–(4)
-
[8]
5) and map toα t via Eq
Fuse the three signals into FIDES_Scoret (Eq. 5) and map toα t via Eq. (6)
-
[9]
Formz f inal t = (1 +α t)zctx t −α tznoctx t
-
[10]
Figure 8: Algorithmic summary of one FIDES decoding step
Decode the next token from softmax(zf inal t ) under the chosen policy (greedy in main experiments). Figure 8: Algorithmic summary of one FIDES decoding step. The dominant cost is the shared dual forward pass; signal extraction is lightweight post-processing. Step 1: Automatic generation.GPT-4 rewrites the answer-bearing span in the original passage to a ...
-
[11]
Fluency: The edited sentence reads naturally and is grammatically correct
-
[12]
Table 13: Full scalability results across all three benchmarks
Answer-type match: The counterfactual an- swer belongs to the same semantic category as the original. Table 13: Full scalability results across all three benchmarks. FIDES gains persist at 13B and 70B; token-level selectivity unlocks F1 improvements inaccessible to coarse rules. NQ-Swap PopQA TriviaQA Model Method CF EM F1 CF EM F1 CF EM F1 LLaMA2-13B Sta...
1953
-
[13]
Examples that fail any of the three criteria are discarded
Conflict presence: The edited passage unam- biguously contradicts the original answer—a reader who only sees the edited passage would give a different answer than one who only relies on general knowledge. Examples that fail any of the three criteria are discarded. Inter-annotator agreement on the final retained set is κ= 0.91 . Disagreements are re- solve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.