Class-Specific Branch Attention for Mitigating Gradient Interference under Class Imbalance
Pith reviewed 2026-06-28 01:14 UTC · model grok-4.3
The pith
Class-specific branch attention reduces gradient interference from majority classes to improve minority-class learning under imbalance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
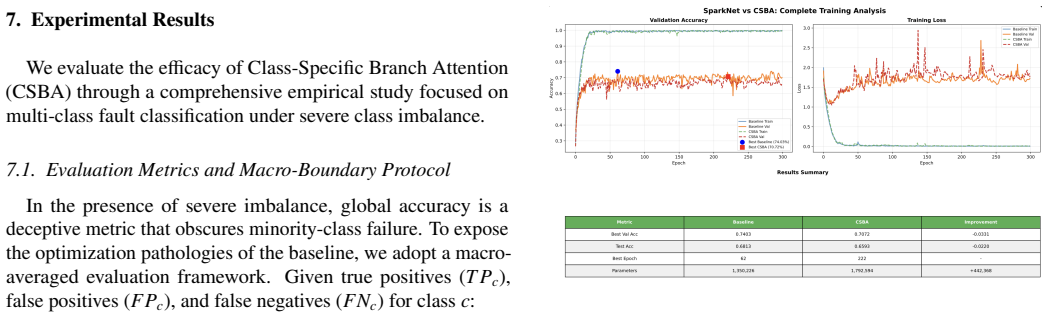
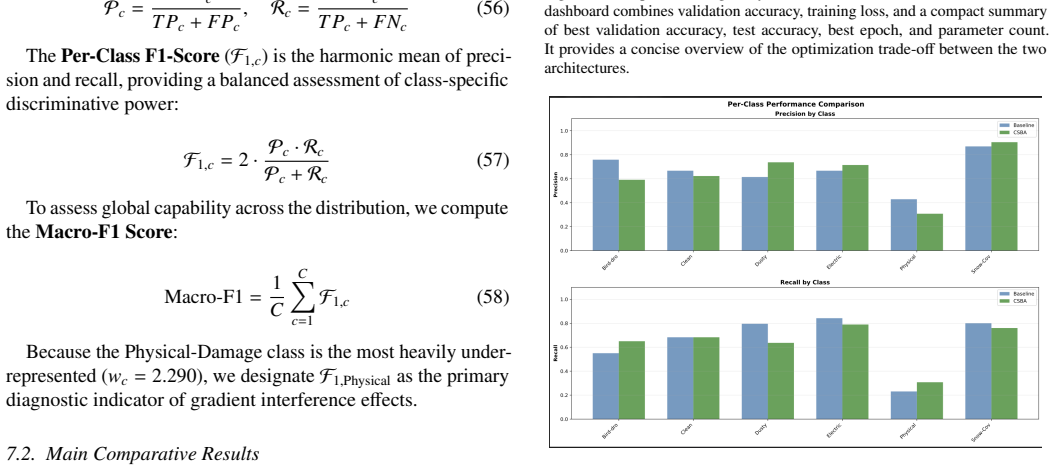
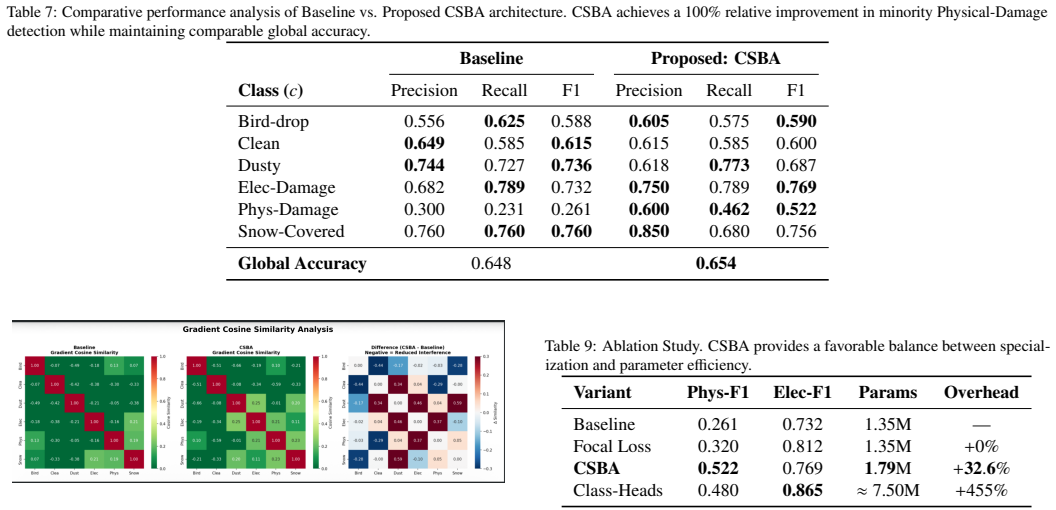
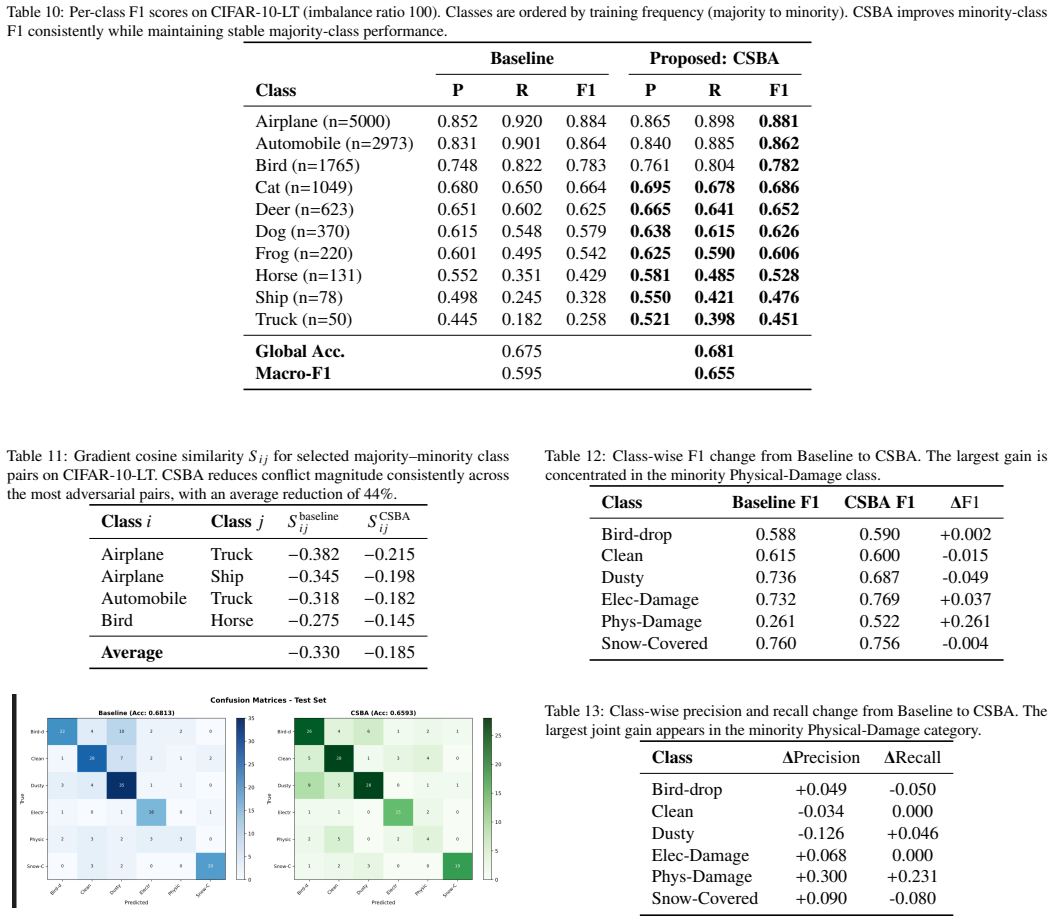
The central claim is that inter-class gradient interference in shared representations forms a distinct pathology under severe imbalance, quantifiable via a layer-wise gradient conflict matrix, and that class-specific branch attention mitigates it by enabling implicit feature decoupling across branches. This yields concrete gains such as lifting the F1 score of the physical-damage class from 0.261 to 0.522 while preserving overall accuracy, and raising Macro-F1 from 0.595 to 0.655 on CIFAR-10-LT.
What carries the argument
Class-Specific Branch Attention (CSBA), a per-branch channel reweighting module that conditions attention on class to reduce harmful gradient coupling measured by the gradient conflict matrix.
If this is right
- Minority-class F1 scores rise markedly, for example from 0.261 to 0.522 on the physical-damage class under severe imbalance.
- Macro-F1 improves from 0.595 to 0.655 on CIFAR-10-LT while overall accuracy stays comparable.
- The same pattern holds across multiple imbalanced visual recognition settings.
- Architectural modifications that address gradient dynamics can work alongside statistical rebalancing techniques.
- Shared representations in multi-branch networks benefit from mechanisms that promote class-aware feature separation during optimization.
Where Pith is reading between the lines
- The same branch-attention idea could be tested in transformer-based models where gradient conflicts also arise across tasks or classes.
- Combining CSBA with existing resampling or loss-reweighting methods may produce further gains if the two address orthogonal sources of imbalance.
- The gradient conflict matrix itself might serve as a diagnostic tool for choosing network depth or width in imbalanced regimes.
- Extreme imbalance ratios beyond those tested could reveal whether the attention mechanism saturates or requires additional regularization.
Load-bearing premise
Cosine similarity between class-specific gradients reliably identifies harmful interference that branch attention can reduce without creating offsetting problems elsewhere in training.
What would settle it
On a new severely imbalanced dataset, applying CSBA leaves minority-class F1 scores unchanged or lower while the gradient conflict matrix continues to report high interference between majority and minority gradients.
Figures
read the original abstract
Deep neural networks trained under severe class imbalance often exhibit degraded performance, typically attributed to statistical bias. In this work, we identify a complementary optimization-level pathology: inter-class gradient interference within shared representations, where gradients from majority classes suppress minority-class learning. To analyze this phenomenon, we introduce a diagnostic framework based on layer-wise gradient flow analysis and a Gradient Conflict Matrix, which quantifies interference using cosine similarity between class-specific gradients. Using this framework, we study multi-branch convolutional architectures and propose a lightweight modification, Class-Specific Branch Attention (CSBA), that enables branch-specific channel reweighting to reduce gradient coupling. This mechanism promotes implicit feature decoupling across branches while preserving architectural simplicity. Empirically, CSBA improves minority-class performance, increasing the F1 score for the Physical-Damage class from 0.261 to 0.522 under severe imbalance, while maintaining comparable overall accuracy. Validation on CIFAR-10-LT confirms that this behavior generalizes across imbalanced visual recognition settings, with Macro-F1 improving from 0.595 to 0.655. More broadly, our findings highlight the importance of considering optimization dynamics alongside statistical methods when designing architectures for imbalanced learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that class imbalance induces an optimization pathology of inter-class gradient interference in shared layers, which can be diagnosed via a layer-wise Gradient Conflict Matrix that quantifies pairwise interference through cosine similarity of class-specific gradients. It proposes Class-Specific Branch Attention (CSBA) as a lightweight modification to multi-branch CNNs that performs branch-specific channel reweighting to reduce this coupling, and reports that CSBA raises the Physical-Damage F1 from 0.261 to 0.522 on a severely imbalanced damage dataset while lifting Macro-F1 from 0.595 to 0.655 on CIFAR-10-LT, all while preserving overall accuracy.
Significance. If the claimed causal link between reduced gradient conflict and minority-class gains holds, the diagnostic framework and CSBA would constitute a useful architectural complement to existing re-sampling or re-weighting techniques for imbalanced learning. The introduction of an explicit gradient-flow diagnostic is a constructive step, but its utility depends on demonstrating that the cosine-based measure is actionable and that CSBA specifically mitigates the diagnosed interference.
major comments (3)
- [Section 3] Gradient Conflict Matrix definition (Section 3): reliance on cosine similarity alone ignores gradient magnitudes; majority-class gradients typically have larger norms and can dominate updates even at moderate angles. No analysis of norm effects or alternative similarity measures (e.g., dot-product or normalized by magnitude) is provided, weakening the claim that the matrix reliably identifies harmful interference.
- [Section 4] Empirical validation of the mechanism (Section 4): the manuscript reports F1 gains but does not present pre- versus post-CSBA Gradient Conflict Matrices, nor any quantitative correlation between measured conflict reduction and the observed F1 lift (0.261→0.522). Without these links the optimization diagnosis and the proposed fix remain correlational.
- [Section 4.3] Ablation design (Section 4.3): no experiment isolates the class-specific reweighting component of CSBA from generic multi-branch architectural effects. A control using identical multi-branch topology without the class-specific attention is required to establish that the reported gains are attributable to the proposed mechanism rather than increased capacity or ensembling.
minor comments (2)
- [Abstract] The abstract states improvements on two datasets but supplies neither the number of runs nor error bars; adding these details would strengthen the empirical claims.
- [Section 3] Notation for the Gradient Conflict Matrix entries should be made explicit (e.g., whether entries are averaged over layers or computed per layer) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our diagnostic framework and the CSBA mechanism. We address each major comment below.
read point-by-point responses
-
Referee: [Section 3] Gradient Conflict Matrix definition (Section 3): reliance on cosine similarity alone ignores gradient magnitudes; majority-class gradients typically have larger norms and can dominate updates even at moderate angles. No analysis of norm effects or alternative similarity measures (e.g., dot-product or normalized by magnitude) is provided, weakening the claim that the matrix reliably identifies harmful interference.
Authors: We agree that gradient magnitudes are relevant to a full characterization of interference. Cosine similarity was chosen to isolate directional conflict in shared layers, but we will revise Section 3 to include an analysis of gradient norms (e.g., comparing majority vs. minority norms) and evaluate a magnitude-normalized variant of the conflict measure. revision: yes
-
Referee: [Section 4] Empirical validation of the mechanism (Section 4): the manuscript reports F1 gains but does not present pre- versus post-CSBA Gradient Conflict Matrices, nor any quantitative correlation between measured conflict reduction and the observed F1 lift (0.261→0.522). Without these links the optimization diagnosis and the proposed fix remain correlational.
Authors: We will add pre- and post-CSBA Gradient Conflict Matrices (for both the damage dataset and CIFAR-10-LT) to Section 4, together with a quantitative correlation between average conflict reduction and per-class F1 gains to directly link the mechanism to the reported improvements. revision: yes
-
Referee: [Section 4.3] Ablation design (Section 4.3): no experiment isolates the class-specific reweighting component of CSBA from generic multi-branch architectural effects. A control using identical multi-branch topology without the class-specific attention is required to establish that the reported gains are attributable to the proposed mechanism rather than increased capacity or ensembling.
Authors: We will include the requested control experiment in the revised Section 4.3: a multi-branch CNN with identical topology and capacity but without the class-specific attention, trained under the same protocol, to isolate the contribution of the CSBA reweighting. revision: yes
Circularity Check
No significant circularity; empirical method with independent diagnostic and results
full rationale
The paper presents an empirical architecture modification (CSBA) guided by a new diagnostic (Gradient Conflict Matrix using cosine similarity on class-specific gradients). No equations, fitted parameters, or self-citations are shown that reduce the claimed improvements or the interference-mitigation claim to a tautology or input by construction. The central results are performance deltas on held-out test sets (F1 gains on minority classes), which are externally falsifiable and not forced by the diagnostic definition itself. This is a standard empirical contribution with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cosine similarity between class-specific gradients quantifies harmful interference
invented entities (1)
-
Class-Specific Branch Attention (CSBA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. Buda, A. Maki, M. A. Mazurowski, A systematic study of the class imbalance problem in convolutional neural networks, Neural Networks 106 (2018) 249–259
2018
-
[2]
Y . Fu, L. Xiang, Y . Zahid, G. Ding, T. Mei, Q. Shen, J. Han, Long-tailed visual recognition with deep models: A methodological survey and evaluation, Neurocomputing 509 (2022) 290–309. doi:10.1016/j.neucom.2022.08.031
-
[3]
Lin, et al., Focal loss for dense object detection, in: ICCV , 2017, pp
T.-Y . Lin, et al., Focal loss for dense object detection, in: ICCV , 2017, pp. 2980–2988
2017
-
[4]
K. Cao, C. Wei, A. Gaidon, N. Arechiga, T. Ma, Learning imbalanced datasets with label-distribution-aware margin loss, in: Advances in Neural Information Processing Sys- tems, 2019, pp. 1565–1576
2019
-
[5]
Y . Cui, M. Jia, T.-Y . Lin, Y . Song, S. Belongie, Class- balanced loss based on effective number of samples, in: CVPR, 2019, pp. 9268–9277
2019
-
[6]
LeCun, Y
Y . LeCun, Y . Bengio, G. Hinton, Deep learning, Nature 521 (2015) 436–444
2015
-
[7]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, G. Hinton, Imagenet classifica- tion with deep convolutional neural networks, in: NeurIPS, 2012, pp. 1097–1105
2012
-
[8]
Szegedy, et al., Going deeper with convolutions, in: CVPR, 2015, pp
C. Szegedy, et al., Going deeper with convolutions, in: CVPR, 2015, pp. 1–9
2015
-
[9]
He, et al., Deep residual learning for image recognition, in: CVPR, 2016, pp
K. He, et al., Deep residual learning for image recognition, in: CVPR, 2016, pp. 770–778
2016
-
[10]
Pamungkas, et al., Pv fault classification challenges under imbalance, Energy Reports (2023)
R. Pamungkas, et al., Pv fault classification challenges under imbalance, Energy Reports (2023). 13
2023
-
[11]
Hu, et al., Maintenance strategies for photovoltaic sys- tems, Solar Energy (2016)
Y . Hu, et al., Maintenance strategies for photovoltaic sys- tems, Solar Energy (2016)
2016
-
[12]
J.-X. Zhuang, J. Cai, J. Zhang, W.-S. Zheng, R. Wang, Class attention to regions of lesion for imbalanced medical image recognition, Neurocomputing 542 (2023) 126577. doi:10.1016/j.neucom.2023.126577
-
[13]
Q. Chen, Q. Liu, E. Lin, A knowledge-guide hierarchical learning method for long-tailed image classification, Neurocomputing 469 (2022) 36–45. doi:10.1016/j.neucom.2021.10.029
-
[14]
A. M. Tiong, J. Li, G. Lin, B. Li, C. Xiong, S. C. Hoi, Im- proving tail-class representation with centroid contrastive learning, Pattern Recognition Letters 168 (2023) 123–130
2023
-
[15]
Ramaneti, et al., Solar panel fault detection using deep learning, IEEE Access (2021)
R. Ramaneti, et al., Solar panel fault detection using deep learning, IEEE Access (2021)
2021
-
[16]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: CVPR, 2018, pp. 7132–7141
2018
-
[17]
S. Woo, J. Park, J.-Y . Lee, I. S. Kweon, Cbam: Convo- lutional block attention module, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–19
2018
-
[18]
Z. Niu, G. Zhong, H. Yu, A review on the attention mecha- nism of deep learning, Neurocomputing 452 (2021) 48–62. doi:10.1016/j.neucom.2021.03.091
-
[19]
M. K. I. Hossain, A. Hemmati, J. Lee, Dual focal loss to address class imbalance in seman- tic segmentation, Neurocomputing 462 (2021) 69–87. doi:10.1016/j.neucom.2021.08.107
-
[20]
L. Xiang, Y . Ding, Y . Xu, X. Wang, T. Mei, J. Han, Curricular-balanced long-tailed learning, Neurocomputing 571 (2024) 127121. doi:10.1016/j.neucom.2023.127121
-
[21]
R. Peng, C. Zhao, X. Chen, Z. Wang, Y . Liu, Y . Liu, X. Lan, A causality guided loss for imbalanced learning in scene graph generation, Neurocomputing 598 (2024) 128042. doi:10.1016/j.neucom.2024.128042
-
[22]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, A. Rabinovich, Gradnorm: Gradient normalization for adaptive loss bal- ancing in deep multitask networks, in: Proceedings of the 35th International Conference on Machine Learning, 2018, pp. 794–803
2018
-
[23]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, C. Finn, Gradient surgery for multi-task learning, in: Advances in Neural Information Processing Systems, V ol. 33, 2020, pp. 5824–5836
2020
-
[24]
F. N. Iandola, M. W. Moskewicz, K. Ashraf, S. Han, W. J. Dally, K. Keutzer, Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5mb model size, arXiv preprint arXiv:1602.07360 (2016)
Pith/arXiv arXiv 2016
-
[25]
Afroz, Solar panel clean and faulty images, Kaggle (2023)
P. Afroz, Solar panel clean and faulty images, Kaggle (2023). URL https://www.kaggle.com/datasets/pythonafroz/solar-panel-clean-and-faulty-images 14
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.