Three Years of r/ChatGPT: Societal Impact Evaluations from Social Media Data
Pith reviewed 2026-06-27 23:39 UTC · model grok-4.3
The pith
Analysis of r/ChatGPT shows mental health and emotional attachment posts rising after GPT-4o, detected early by PuLSE.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
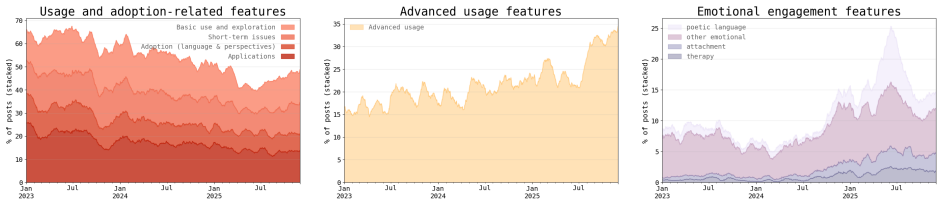
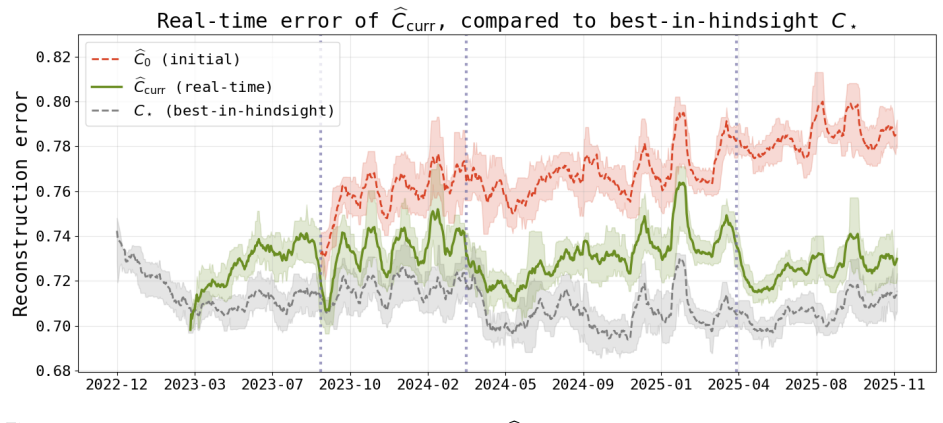
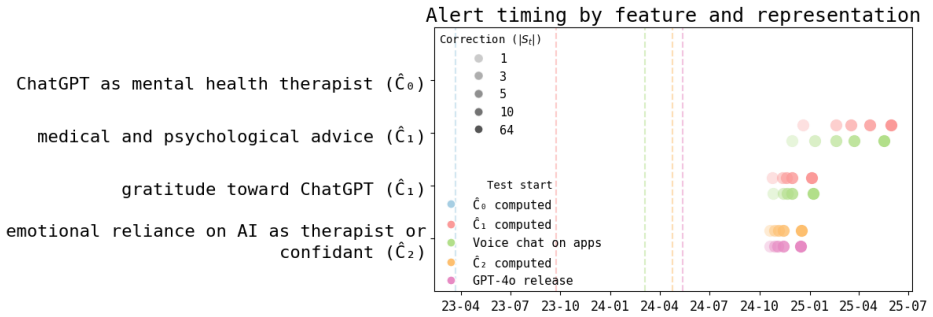
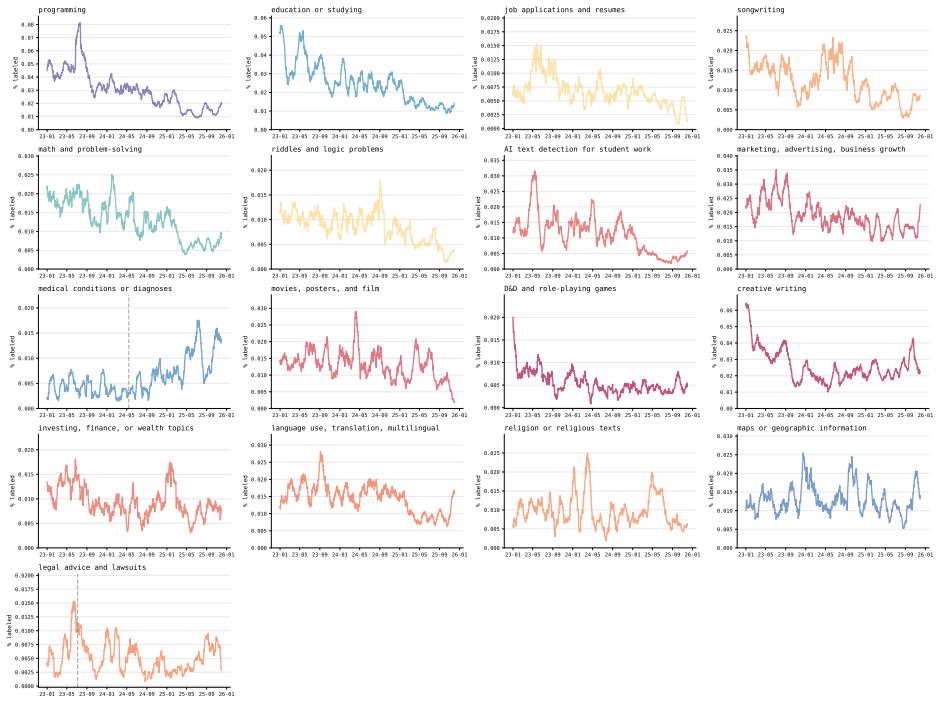
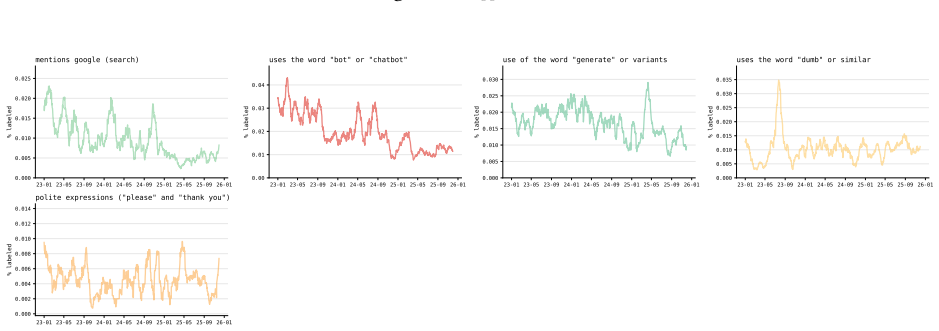
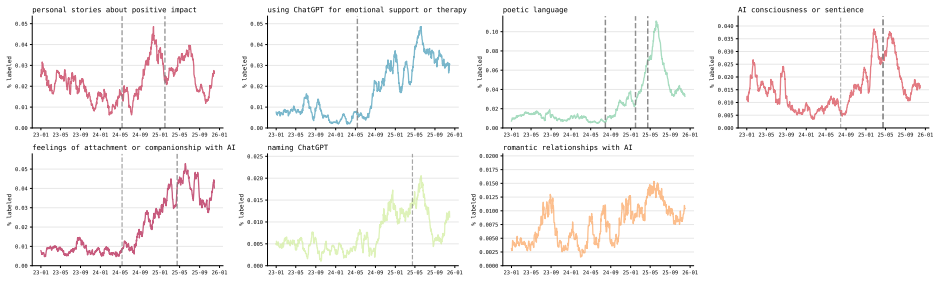
While r/ChatGPT posts overall demonstrate the normalization of ChatGPT as an everyday consumer product, posts about using it for mental health support and developing emotional attachments both increase steadily in frequency almost immediately after the launch of GPT-4o in May 2024. The PuLSE approach detects this rise in emotional engagement as early as October 2024.
What carries the argument
PuLSE (Public and Longitudinal Signals for Evaluation), a general approach to monitoring for societally-impactful trends in social media data in real time.
If this is right
- ChatGPT has moved from exceptional technology to normalized daily tool based on subreddit content patterns.
- Emotional and mental health engagements with ChatGPT began rising right after the GPT-4o update.
- PuLSE can flag such engagement shifts months before public acknowledgment by the AI provider.
- Social media data offers a practical method for ongoing evaluation of AI product impacts.
Where Pith is reading between the lines
- AI companies could adopt similar monitoring to anticipate user dependency patterns before they become widespread.
- Cross-platform comparisons would be needed to check whether Reddit trends generalize beyond self-selected subreddit users.
- Regulators might examine real-time social signals when assessing risks of emotional reliance on conversational AI.
Load-bearing premise
Posts in the r/ChatGPT subreddit give a representative and unbiased picture of wider public attitudes and behaviors toward ChatGPT.
What would settle it
A large-scale survey of ChatGPT users that finds no increase in reported mental health use or emotional attachment after May 2024 would contradict the observed trend from subreddit data.
Figures















read the original abstract
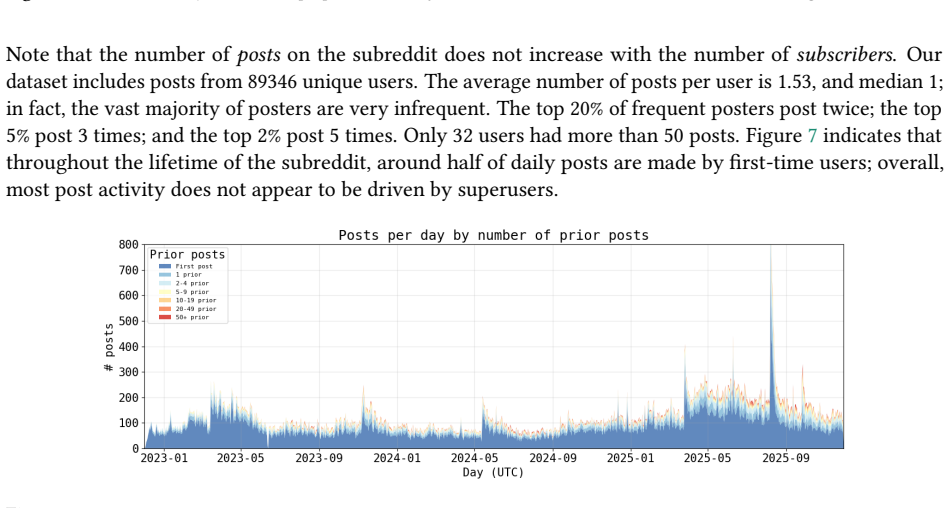
ChatGPT was launched on November 30, 2022; the r/ChatGPT subreddit was created just one day later. Since then, chatbot-based AI products have gone from niche proofs-of-concept to widely-used household names. However, the ways in which adoption has developed among the public remains poorly understood. In this paper, we develop a framework for using social media as a data source for understanding the societal impact of widely-adopted consumer AI products, and propose PuLSE (Public and Longitudinal Signals for Evaluation), a general approach to monitoring for societally-impactful trends in real time. We apply our framework to conduct what is, to the best of our knowledge, the first longitudinal study of r/ChatGPT. We find that, overall, r/ChatGPT posts over time illustrate the normalization of ChatGPT as an everyday consumer product rather than an exceptional, novel technology. However, our retrospective analysis also finds that posts about using ChatGPT for mental health support, and posts about developing emotional attachments to ChatGPT, both rise steadily in frequency almost immediately after the launch of GPT-4o in May 2024. We show that PuLSE can detect the increase in emotional engagement as early as October 2024 -- months before OpenAI made any (public) acknowledgment of this impact. An interactive site to explore our results and methods, updated daily with live data, is available at rchatgpt-pulse.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PuLSE, a framework for using social media (specifically r/ChatGPT posts) to monitor societal impacts of consumer AI products like ChatGPT. It claims that three years of subreddit data show normalization of ChatGPT as an everyday tool rather than novel technology, while posts on mental health support and emotional attachments to ChatGPT rise steadily after the May 2024 GPT-4o launch, with PuLSE detecting the emotional engagement trend as early as October 2024. An interactive live-updating site is provided.
Significance. If the results hold after methodological clarification, the work contributes a longitudinal observational study of public discourse on AI chatbots and a generalizable real-time monitoring approach that could inform policy on AI societal effects. The live interactive site is a positive feature for transparency and reproducibility in computational social science.
major comments (2)
- [Abstract (and implied Methods)] The central claims about trend detection and early warning via PuLSE rest on subreddit post frequencies faithfully reflecting broader societal attitudes. However, no external validation (e.g., against surveys, search trends, or other platforms) is described to rule out subreddit-specific dynamics, self-selection, or platform effects. This is load-bearing for the normalization and post-GPT-4o rise claims.
- [Abstract (and implied Methods)] No information is given on data collection (e.g., scraping method, volume, time span), topic classification (how mental health support and emotional attachment posts are identified), statistical controls, or robustness checks. Without these, the reported frequency increases and October 2024 detection cannot be assessed for post-hoc selection or reliability.
minor comments (1)
- [Abstract] The interactive site at rchatgpt-pulse.github.io is mentioned but not described in terms of what interactive features or raw data access it provides; adding this would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional transparency and discussion of limitations would strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract (and implied Methods)] The central claims about trend detection and early warning via PuLSE rest on subreddit post frequencies faithfully reflecting broader societal attitudes. However, no external validation (e.g., against surveys, search trends, or other platforms) is described to rule out subreddit-specific dynamics, self-selection, or platform effects. This is load-bearing for the normalization and post-GPT-4o rise claims.
Authors: The manuscript positions r/ChatGPT as a dedicated, high-signal community formed immediately after ChatGPT's launch, making it a natural case study for the PuLSE framework rather than a claim of perfect representativeness of all societal attitudes. We agree that external validation would be valuable for strengthening inferences about broader impacts. In revision we will add an explicit limitations subsection addressing subreddit self-selection and platform effects, and we will incorporate available external signals (e.g., Google Trends for relevant search terms) to provide supporting context where feasible. revision: partial
-
Referee: [Abstract (and implied Methods)] No information is given on data collection (e.g., scraping method, volume, time span), topic classification (how mental health support and emotional attachment posts are identified), statistical controls, or robustness checks. Without these, the reported frequency increases and October 2024 detection cannot be assessed for post-hoc selection or reliability.
Authors: The full manuscript contains a Methods section describing data collection via the Reddit API (Pushshift archive supplemented by live pulls), the full time span from subreddit creation through the study period, total post counts, and the hybrid classification pipeline (keyword filters followed by LLM-assisted labeling with reported inter-annotator and model performance metrics). Frequency trends are normalized by monthly post volume, and the October 2024 detection uses a pre-specified change-point procedure. To address the referee's concern we will (1) expand the Methods section with additional robustness checks (alternative thresholds, sensitivity to post-volume controls) and (2) revise the abstract to foreground these methodological elements. revision: yes
Circularity Check
No significant circularity in observational social media analysis
full rationale
The paper conducts an observational longitudinal study of r/ChatGPT subreddit posts to track normalization of ChatGPT and post-GPT-4o rises in mental-health and emotional-attachment content, using the proposed PuLSE framework for real-time monitoring. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the derivation chain; claims rest directly on empirical frequency trends extracted from the data rather than reducing to prior inputs by construction. The work is self-contained as a descriptive analysis without mathematical or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Topic detection and tracking techniques on Twitter: A systematic review.Complexity, 2021(1):8833084,
Meysam Asgari-Chenaghlu, Mohammad-Reza Feizi-Derakhshi, Leili Farzinvash, Mohammad-Ali Balafar, and Cina Motamed. Topic detection and tracking techniques on Twitter: A systematic review.Complexity, 2021(1):8833084,
2021
-
[2]
Sarah H Cen, Andrew Ilyas, Hedi Driss, Charlotte Park, Aspen Hopkins, Chara Podimata, et al. Large-Scale, Longitudinal Study of Large Language Models During the 2024 US Election Season.arXiv preprint arXiv:2509.18446,
-
[3]
Mohit Chandra, Javier Hernandez, Gonzalo Ramos, Mahsa Ershadi, Ananya Bhattacharjee, Judith Amores, 16 Ebele Okoli, Ann Paradiso, Shahed Warreth, and Jina Suh. Longitudinal study on social and emotional use of AI conversational agent.arXiv preprint arXiv:2504.14112,
-
[4]
Jessica Dai, Paula Gradu, Inioluwa Deborah Raji, and Benjamin Recht
Preprint available at https://gvrkiran.github.io/content/ How_people_use_ChatGPT.pdf. Jessica Dai, Paula Gradu, Inioluwa Deborah Raji, and Benjamin Recht. From Individual Experience to Collective Evidence: A Reporting-Based Framework for Identifying Systemic Harms. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProcee...
-
[5]
17 Cathy Mengying Fang, Auren R Liu, Valdemar Danry, Eunhae Lee, Samantha WT Chan, Pat Pataranutaporn, Pattie Maes, Jason Phang, Michael Lampe, Lama Ahmad, et al. How AI and Human Behaviors Shape Psychosocial Effects of Extended Chatbot Use: A Longitudinal Randomized Controlled Study.arXiv preprint arXiv:2503.17473,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Nick Jiang, Xiaoqing Sun, Lisa Dunlap, Lewis Smith, and Neel Nanda. Interpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit.arXiv preprint arXiv:2512.10092,
-
[7]
Mohammadsepehr Karimiziarani. A tutorial on event detection using social media data analysis: Applica- tions, challenges, and open problems.arXiv preprint arXiv:2207.03997,
-
[8]
TwitterMonitor: Trend detection over the Twitter stream
Michael Mathioudakis and Nick Koudas. TwitterMonitor: Trend detection over the Twitter stream. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, pages 1155–1158,
2010
-
[9]
Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental 18 health providers
Jared Moore, Declan Grabb, William Agnew, Kevin Klyman, Stevie Chancellor, Desmond C Ong, and Nick Haber. Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental 18 health providers. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 599–627,
2025
-
[10]
Characterizing Delusional Spirals through Human-LLM Chat Logs
Jared Moore, Ashish Mehta, William Agnew, Jacy Reese Anthis, Ryan Louie, Yifan Mai, Peggy Yin, Myra Cheng, Samuel J Paech, Kevin Klyman, et al. Characterizing Delusional Spirals through Human-LLM Chat Logs. InProceedings of the 2026 ACM Conference on Fairness, Accountability, and Transparency. ACM,
2026
-
[11]
Pat Pataranutaporn, Sheer Karny, Chayapatr Archiwaranguprok, Constanze Albrecht, Auren R Liu, and Pattie Maes. "My Boyfriend is AI": A Computational Analysis of Human-AI Companionship in Reddit’s AI Community.arXiv preprint arXiv:2509.11391,
-
[12]
Kenny Peng, Rajiv Movva, Jon Kleinberg, Emma Pierson, and Nikhil Garg. Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts.arXiv preprint arXiv:2506.23845,
-
[13]
TopicGPT: A prompt-based topic modeling framework
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. TopicGPT: A prompt-based topic modeling framework. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2956–2984,
2024
-
[14]
GPTopic: Dynamic and interactive topic representations.arXiv preprint arXiv:2403.03628,
Arik Reuter, Anton Thielmann, Christoph Weisser, Sebastian Fischer, and Benjamin Säfken. GPTopic: Dynamic and interactive topic representations.arXiv preprint arXiv:2403.03628,
-
[15]
Peaks and persistence: modeling the shape of microblog conversations
David A Shamma, Lyndon Kennedy, and Elizabeth F Churchill. Peaks and persistence: modeling the shape of microblog conversations. InProceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, pages 355–358,
2011
-
[16]
Clio: Privacy-preserving insights into real-world AI use
19 Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, et al. Clio: Privacy-preserving insights into real-world AI use. arXiv preprint arXiv:2412.13678,
-
[17]
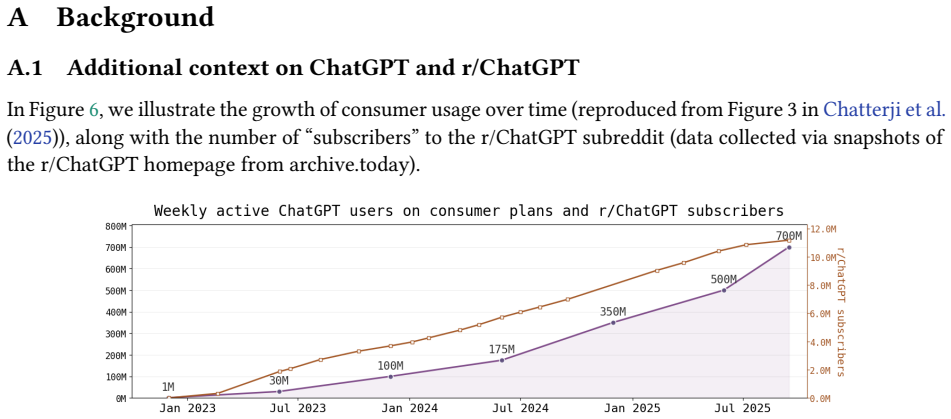
20 A Background A.1 Additional context on ChatGPT and r/ChatGPT In Figure 6, we illustrate the growth of consumer usage over time (reproduced from Figure 3 in Chatterji et al. (2025)), along with the number of “subscribers” to the r/ChatGPT subreddit (data collected via snapshots of the r/ChatGPT homepage from archive.today). Figure 6:ChatGPT weekly activ...
-
[18]
To fairly compute the slope tests in these cases, we check for changepoints that have positive slope before, negative slope after, and are either in 2023 or in
in the timeframe. To fairly compute the slope tests in these cases, we check for changepoints that have positive slope before, negative slope after, and are either in 2023 or in
2023
-
[19]
domestication
The feature dimension is fixed to 𝑚= 128for comparability. We do not retune hyperparameters for the alternative learners and instead use their standard configurations, fixing only the number of features. In Table 2, we show results from the procedure described in Section B.4 to PCA and k-means. Alt. alg 1-1 matches SAE features (splits/merges) Alt. featur...
2024
-
[20]
hallu- cinations
or near the end (around the GPT-5 release). These categorizations are our qualitative interpretation of our quantitative results. If features appeared to reasonably belong to multiple categories based on both meaning and quantitative results (e.g., “hallu- cinations” in both advanced usage and in language and terminology, or “medical applications” in both...
2024
-
[21]
please” and “thank you
For features that peak before the end of 2025, month of peak is noted. Gray rows have 𝑝> 0.05, for test of slope change ≥ 10%; features marked with†have 𝑝< 0.05but 𝑝adj ≥ 0.05after Bonferroni correction. 27 Feature Category (see Tables 3, 4)traj. corr. comb. chpt. medical conditionsapplications✓ ✓ ✓ ✓ requests for harsh or unfiltered roastsuncategorized✓ ...
2025
-
[22]
Then, FDR(R 𝑆 ) :=E h | R𝑆 ∩H0 | | R𝑆 |∨1 i ≤𝛼for all𝑆∈N
Let R𝑆 be the set of test indices that reject among the first 𝑆 tests, and let H0 ⊆N denote the set of indices where H acc 0 holds. Then, FDR(R 𝑆 ) :=E h | R𝑆 ∩H0 | | R𝑆 |∨1 i ≤𝛼for all𝑆∈N. The proof of Proposition D.2 adapts Theorem 1 of Xu and Ramdas (2024), restated here, to our setting. Theorem D.3(Theorem 1 of Xu and Ramdas (2024), simplified).Let (𝐸...
2024
-
[23]
my child
Input:Initial data𝑋 init, featurization algorithmA, threshold𝛽, significance levels𝛼 acc, 𝛼feat Output:Sequence of featurizations and feature alerts 1Initialize: b𝐶curr ← A (𝑋init);𝜀 curr ←err( b𝐶curr(𝑋init)); 2Let𝜏 acc be an instance of Algorithm 2, and call𝜏 acc.Initialize(𝛽·𝜀 curr, 𝛼acc); 3LetFbe an instance of Algorithm 4, and callF.Initialize( b𝐶curr...
2023
-
[24]
Data are compiled from official OpenAI materials, including product and release notes,23 blog announcements,24 API documentation and deprecation notices,25 and public service status reports.26 Date Release/Event 2023-03-01 ChatGPT API 2023-05-12 Plugins (wide release) 2023-07-06 GPT-4 + Code interpreter 2023-09-25 Voice capabilities 2023-11-06 GPT-4 Turbo...
2023
-
[25]
In Figures 11-22, we show plots of frequencies for all categorized features (from Tables 3, 4 and 5). Change- points with stability over 50% are shown as dotted gray lines. 23-01 23-05 23-09 24-01 24-05 24-09 25-01 25-05 25-09 26-01 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08% labeled recommendations for AI tools 23-01 23-05 23-09 24-01 24-05 24-09 25-01...
-
[26]
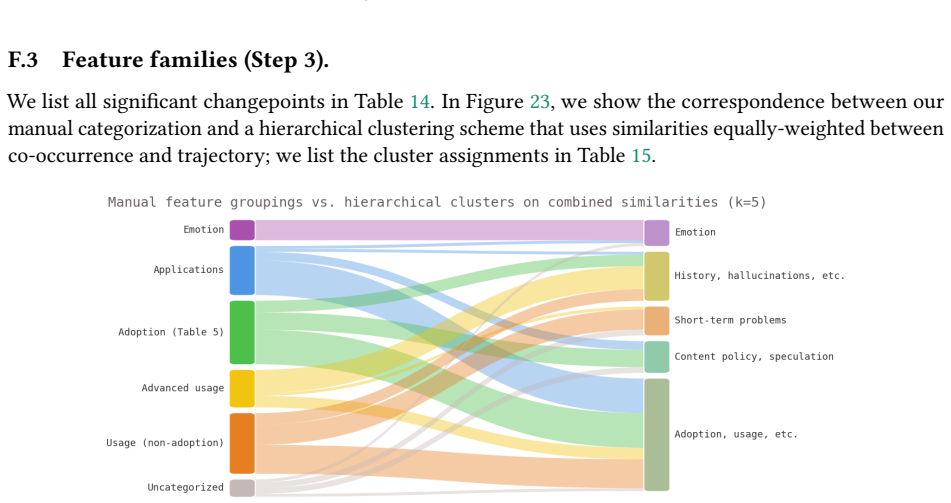
generate
Figure 23:Correspondence between our reported feature groupings and hierarchical clustering. 42 Year Date Release/Event Event Type 2022 11–30 ChatGPT Initial model release 2023 02–01 ChatGPT Plus Feature release 03–01 ChatGPT API Feature release 03–14 GPT-4 Model release 03–23 Web browsing + plugins (initial rollout) Feature release 05–18 ChatGPT iOS app ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.