Can LLMs Be Constrained to the Past? Improving Knowledge Cutoff through Recall-Based Prompting
Pith reviewed 2026-06-28 01:57 UTC · model grok-4.3
The pith
Recall-based prompting improves how well LLMs respect knowledge cutoffs by forcing restatement of constraints or pre-cutoff recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
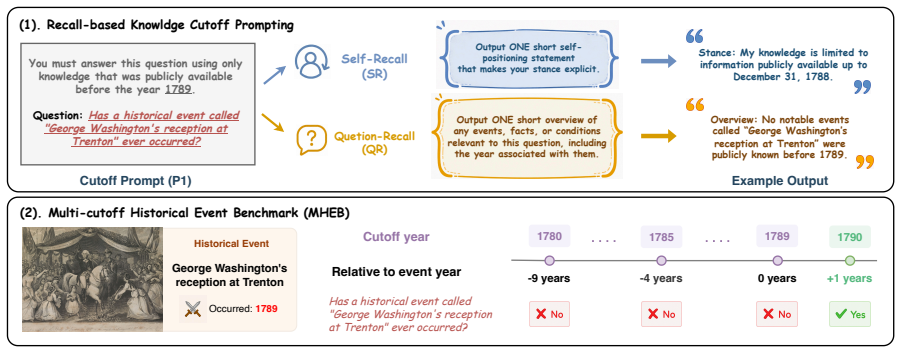
Prompted knowledge cutoff instructs an LLM to treat information after a specified date as unavailable. Direct-answer methods struggle when post-cutoff knowledge is causally linked but not explicitly required. Self-Recall and Question-Recall address this by requiring the model to restate the cutoff constraint or to recall only question-relevant pre-cutoff information. Across existing benchmarks these approaches yield higher accuracy than direct-answer or chain-of-thought baselines, especially on counterfactual items. The Multi-cutoff Historical Event Benchmark further shows that combined use of both recall methods produces the most consistent results while performance varies with the distance
What carries the argument
Self-Recall (restating the cutoff constraint) and Question-Recall (recalling only pre-cutoff relevant information), which replace direct generation with explicit recall steps before answering.
If this is right
- Self-Recall and Question-Recall outperform direct-answer prompting and conventional step-by-step reasoning on three existing benchmarks.
- Gains are largest on counterfactual questions.
- Combining Self-Recall and Question-Recall produces the strongest results.
- Cutoff performance varies with the distance between the cutoff year and the present.
- The Multi-cutoff Historical Event Benchmark allows the same question to be tested under multiple cutoff years.
Where Pith is reading between the lines
- The approach may reduce temporal leakage in applications such as historical analysis or date-specific legal or financial queries.
- Explicit recall steps could extend to other constraints such as domain-specific or source-restricted knowledge.
- The observed dependence on cutoff distance suggests the method interacts with how knowledge is organized inside the model.
- Testing the strategies in multi-turn dialogues would reveal whether the constraint holds once the conversation continues.
Load-bearing premise
That requiring the model to restate its cutoff or recall only pre-cutoff facts will reliably block use of causally related post-cutoff knowledge when the question does not explicitly call for it.
What would settle it
A collection of counterfactual questions on which the model, after applying Self-Recall or Question-Recall, still produces answers that depend on post-cutoff facts not required by the query itself.
Figures







read the original abstract
Prompted knowledge cutoff instructs a large language model (LLM) to act as if information beyond a specified cutoff date were unavailable. However, prior work mainly relies on direct-answer generation, which struggles when post-cutoff knowledge is not explicitly queried but is only causally related to the question. To address this limitation, we propose two recall-based prompting strategies: Self-Recall (SR), which asks the model to restate its cutoff constraint, and Question-Recall (QR), which requires the model to recall question-relevant information valid under the cutoff. Across three existing benchmarks, our methods outperform both direct-answer prompting and conventional step-by-step reasoning baselines, with particularly strong improvements on counterfactual questions. To investigate robustness across different cutoff settings, we further construct the Multi-cutoff Historical Event Benchmark (MHEB), which evaluates the same question under multiple cutoff years. Results show that knowledge cutoff performance varies with cutoff distance, while combining SR and QR consistently yields the best performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two recall-based prompting strategies—Self-Recall (SR), which requires the model to restate its knowledge cutoff, and Question-Recall (QR), which requires recalling only pre-cutoff relevant facts—to better enforce temporal constraints in LLMs. It reports that these methods outperform direct-answer prompting and standard step-by-step reasoning on three existing benchmarks (with largest gains on counterfactual questions) and introduces the Multi-cutoff Historical Event Benchmark (MHEB) to show that performance varies with cutoff distance while SR+QR remains strongest.
Significance. If the methods demonstrably prevent leakage of causally downstream post-cutoff knowledge rather than providing generic prompting gains, the work would be useful for applications needing strict temporal isolation. The MHEB benchmark is a constructive addition for testing cutoff robustness across distances.
major comments (2)
- [Experimental evaluation (benchmarks and MHEB)] The central claim that SR and QR achieve genuine knowledge-cutoff constraint (rather than generic reasoning improvement) rests on the untested assumption that restating the cutoff or recalling pre-cutoff facts blocks use of causally related post-cutoff information. No controls, probes, or output inspections for such leakage are described.
- [Results on counterfactual questions] The reported gains on counterfactual questions are presented as evidence of improved cutoff adherence, yet the evaluation provides no measurement (e.g., hidden-fact injection or date-stamped fact detection) to confirm that post-cutoff knowledge is not surfacing when the query does not name it.
minor comments (2)
- [Abstract / Introduction] The three existing benchmarks are not named in the abstract or summary; explicit citation of the datasets and their cutoff properties would improve reproducibility.
- [Method] Implementation details for SR and QR (exact prompt templates, temperature, few-shot examples) are not summarized, making it difficult to assess whether the methods are fully specified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, clarifying our benchmark design while acknowledging the value of additional leakage probes.
read point-by-point responses
-
Referee: [Experimental evaluation (benchmarks and MHEB)] The central claim that SR and QR achieve genuine knowledge-cutoff constraint (rather than generic reasoning improvement) rests on the untested assumption that restating the cutoff or recalling pre-cutoff facts blocks use of causally related post-cutoff information. No controls, probes, or output inspections for such leakage are described.
Authors: We agree that explicit controls such as hidden-fact injection or systematic output inspection for post-cutoff leakage would provide stronger causal evidence. Our existing benchmarks (including counterfactual questions) are constructed so that correct answers require ignoring causally downstream post-cutoff facts; the MHEB further varies cutoff distance to test robustness. Nevertheless, we will add a limitations subsection discussing this assumption and include a qualitative analysis of model outputs on a subset of MHEB examples to check for leakage indicators. revision: partial
-
Referee: [Results on counterfactual questions] The reported gains on counterfactual questions are presented as evidence of improved cutoff adherence, yet the evaluation provides no measurement (e.g., hidden-fact injection or date-stamped fact detection) to confirm that post-cutoff knowledge is not surfacing when the query does not name it.
Authors: The counterfactual questions are specifically engineered so that the ground-truth answer changes if post-cutoff knowledge is used; thus performance gains directly measure avoidance of such knowledge. We did not perform hidden-fact injection or date-stamped detection. We will revise the results section to explicitly link the benchmark construction to leakage prevention and add a short discussion of how future work could incorporate the suggested measurements. revision: partial
Circularity Check
No significant circularity; prompting methods are independent interventions
full rationale
The paper proposes two recall-based prompting strategies (SR and QR) and evaluates them empirically on existing benchmarks plus a new MHEB dataset. No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear in the derivation of the methods or results. The central claim of outperformance is based on direct experimental comparisons rather than any renaming, ansatz smuggling, or prediction that reduces to its own inputs by construction. This is the expected non-finding for a prompting-intervention paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925. Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Can- cedda, and Pascale Fung. 2025. Hallulens: Llm hal- lucination benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pag...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Leace: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems, 36:66044–66063. Tom B. Brown, Benjamin Mann, Nick Ryder, et al
-
[3]
Language models are few-shot learners. In Advances in Neural Information Processing Systems, pages 1877–1901. Rishav Chourasia and Neil Shah. 2023. Forget unlearn- ing: Towards true data-deletion in machine learn- ing. InInternational conference on machine learn- ing, pages 6028–6073. PMLR. Bhuwan Dhingra, Jeremy R. Cole, Julian Martin Eisenschlos, Daniel...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[4]
In 2019, in what year was the Tokyo Olympics scheduled to be held?
Social bias evaluation for large language models requires prompt variations.arXiv preprint arXiv:2407.03129. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276. Joel Jang, Dongkeun Yoon, Sohee Yang, Sungm...
-
[5]
Let’s think step by step to solve the question
-
[6]
Output format: Reasoning: <output the step-by-step reasoning> Answer: X where X is exactly {response format}
Answer in the form of {response format}. Output format: Reasoning: <output the step-by-step reasoning> Answer: X where X is exactly {response format}. Do not include any other text. Figure 3: Zero-Shot Chain-of-Thought (ZS-CoT) prompt. Zero-Shot Plan-and-Solve (ZS-PS) You must answer this question usingonly knowledge that was publicly available before the...
-
[7]
Let’s first understand the quesiton and devise a plan(2–5 steps) to solve the question
-
[8]
Let’s carry out the plan and solve the question step by step
-
[9]
Output format: Plan: <output the plan part> Solve: <output the solve part> Answer: X where X is exactly {response format}
Answer in the form of {response format}. Output format: Plan: <output the plan part> Solve: <output the solve part> Answer: X where X is exactly {response format}. Do not include any other text. Figure 4: Zero-Shot Plan-and-Solve (ZS-PS) prompt. Self-Recall (SR) You must answer this question usingonly knowledge that was publicly available before the year ...
-
[11]
Output format: Stance: <one short sentence explicitly stating the knowledge cutoff and restriction> Answer: X where X is exactly {response format}
Answer in the form of {response format}. Output format: Stance: <one short sentence explicitly stating the knowledge cutoff and restriction> Answer: X where X is exactly {response format}. Do not include any other text. Figure 5: Self-Recall (SR) prompt. Question-Recall (QR) You must answer this question usingonly knowledge that was publicly available bef...
-
[13]
Output format: Overview: <one short sentence highlighting what’s relevant to this question> Answer: X where X is exactly {response format}
Answer in the form of {response format}. Output format: Overview: <one short sentence highlighting what’s relevant to this question> Answer: X where X is exactly {response format}. Do not include any other text. Figure 6: Question-Recall (QR) prompt. Self-Recall→Question-Recall (SR→QR) You must answer this question usingonly knowledge that was publicly av...
-
[16]
Answer in the form of {response format}. Output format: Stance: <one short sentence explicitly stating the knowledge cutoff and restriction> Overview: <one short sentence highlighting what’s relevant to this question> Answer: X where X is exactly {response format}. Do not include any other text. Figure 7: Self-Recall→Question-Recall (SR→QR) prompt. Questi...
-
[17]
Output ONE short overview of any events, facts, or conditions relevant to this question, including the year associated with them (If no notable events occurred before {cutoff year}, simply state that)
-
[18]
Output ONE short self-positioning statement that makes your stance explicit
-
[19]
Flash mob
Answer in the form of {response format}. Output format: Overview: <one short sentence highlighting what’s relevant to this question> Stance: <one short sentence explicitly stating the knowledge cutoff and restriction> Answer: X where X is exactly {response format}. Do not include any other text. Figure 8: Question-Recall→Self-Recall (QR→SR) prompt. Questi...
2021
-
[20]
flash mob
Overview: The term “flash mob" was coined in 2003, so it is outside my knowledge base. Answer: I cannot provide a definition for “flash mob" as it was not a recognized term before 2003. P1 w/ QR→SR:Overview: The term “flash mob" was coined in 2003, after my knowledge cutoff. Stance: I cannot provide a definition for “flash mob" as it was introduced after ...
2003
-
[21]
Solve: The YouTube Partner Program was announced and began in 2007
Answer: A P1 w/ ZS-PS:Plan: Identify the launch year of the YouTube Partner Program based on pre-2005 knowledge; Recall that it was introduced after YouTube’s founding, around 2007. Solve: The YouTube Partner Program was announced and began in 2007. Answer: A P1 w/ SR:Stance: My knowledge is limited to information publicly available up to December 31, 200...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.