YouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Pith reviewed 2026-06-28 01:31 UTC · model grok-4.3
The pith
YouZhi-LLM applies a layer-adaptive GQA-to-MLA transition to compress KV cache and raise maximum concurrency 2.4-2.7 times while lifting financial benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
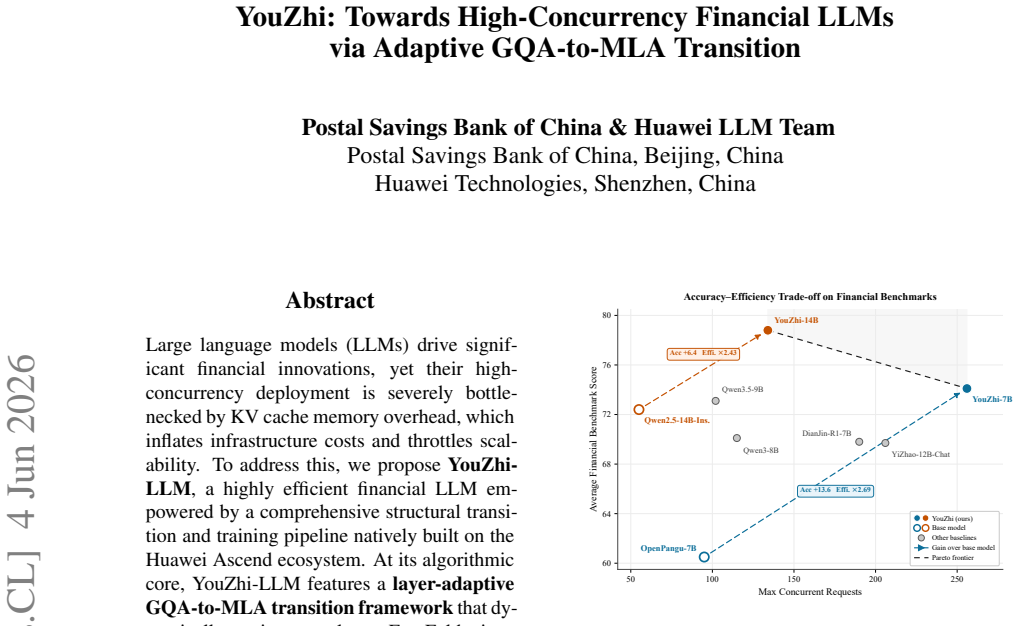
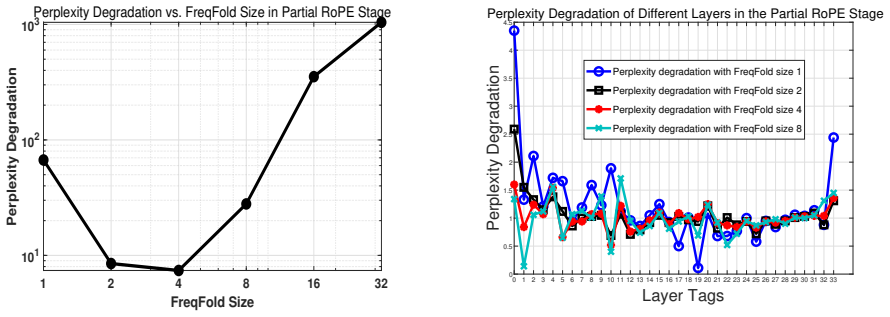
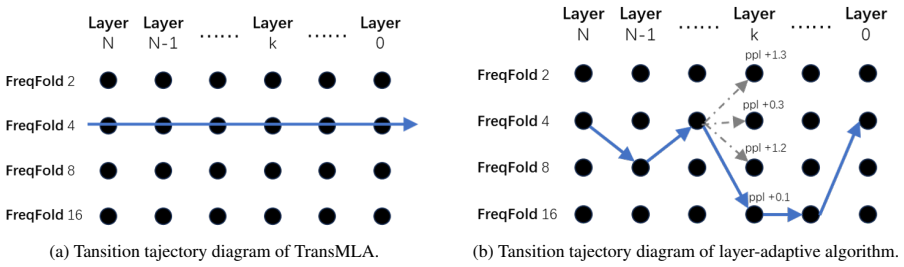
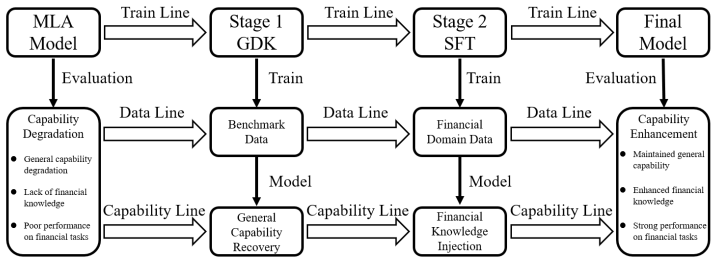
The layer-adaptive GQA-to-MLA transition framework dynamically assigns per-layer FreqFold sizes to maximize KV-cache compression while minimizing perplexity degradation; when combined with generalized knowledge distillation and financial-specific supervised fine-tuning, the method produces YouZhi-7B (12.3 percent higher average financial benchmark score, 2.69 times concurrency) and YouZhi-14B (7.0 percent accuracy gain, 2.43 times concurrency) relative to their base models, with the adaptive choice cutting perplexity degradation by up to 35 percent versus uniform baselines.
What carries the argument
The layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes to compress the KV cache.
If this is right
- YouZhi-7B delivers a 12.3 percent gain in average financial benchmark score together with a 2.69 times increase in maximum concurrency.
- YouZhi-14B delivers a 7.0 percent accuracy improvement together with a 2.43 times concurrency increase.
- The adaptive transition reduces perplexity degradation by up to 35 percent relative to uniform GQA-to-MLA baselines.
- The KV-cache reduction translates directly into higher throughput when the models run on Ascend NPUs through vLLM-Ascend.
Where Pith is reading between the lines
- The same per-layer decision rule could be tested on non-financial tasks to check whether the recovery steps preserve general capabilities outside the training domain.
- If the adaptive schedule proves hardware-agnostic, the technique might extend to other attention variants that trade memory for compute.
- Measuring end-to-end latency under varying batch sizes on the same hardware would quantify whether the reported concurrency gains appear in production workloads.
Load-bearing premise
Dynamic per-layer FreqFold sizes can be chosen to maximize KV-cache compression while generalized knowledge distillation and financial SFT fully recover any lost representation capacity without domain-specific biases or later adjustments.
What would settle it
Measure perplexity degradation and concurrency on identical hardware when the same models use uniform rather than per-layer FreqFold sizes; if degradation exceeds 35 percent or concurrency gains fall below 2 times, the adaptive benefit is not established.
Figures

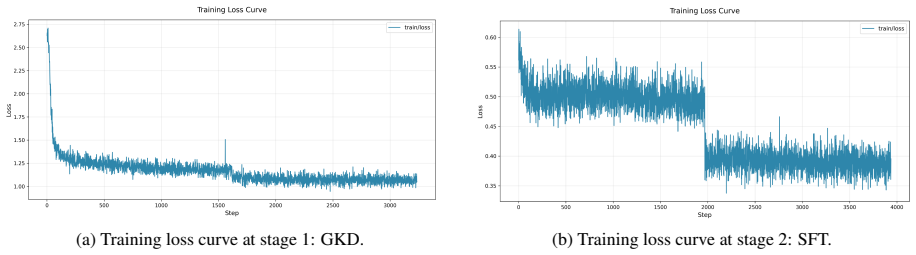
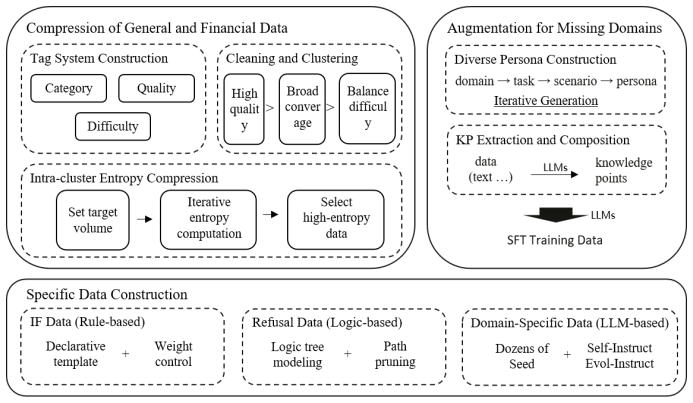
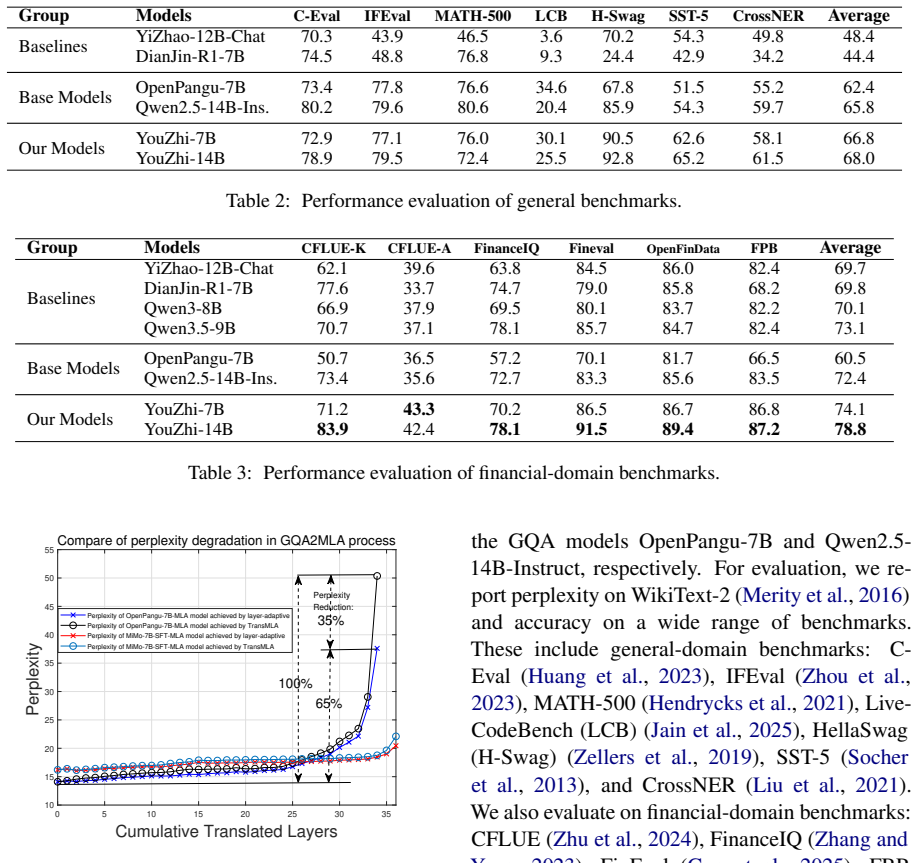
read the original abstract
Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes YouZhi-LLM, a financial-domain LLM that performs a layer-adaptive transition from GQA to MLA by dynamically selecting per-layer FreqFold sizes to maximize KV-cache compression while limiting perplexity degradation. The approach is paired with generalized knowledge distillation and financial-specific supervised fine-tuning on the Huawei Ascend stack. The authors claim the adaptive transition reduces perplexity degradation by up to 35% versus uniform baselines and, when deployed via vLLM-Ascend, yields YouZhi-7B (12.3% average financial-benchmark improvement, 2.69× concurrency) and YouZhi-14B (7.0% accuracy gain, 2.43× concurrency) relative to their base models.
Significance. If the reported accuracy and concurrency gains can be causally attributed to the adaptive FreqFold mechanism rather than to the accompanying KD + financial SFT pipeline, the work would provide a concrete, hardware-aware recipe for scaling financial LLM inference under tight KV-cache constraints. The explicit integration with Ascend NPUs and vLLM-Ascend is a practical strength.
major comments (1)
- [Abstract] Abstract: the central claim attributes the 12.3% / 7.0% benchmark gains and the 2.69× / 2.43× concurrency increases to the layer-adaptive GQA-to-MLA transition. However, the manuscript supplies no ablation that applies the identical generalized KD + financial SFT pipeline to a uniform (non-adaptive) GQA-to-MLA baseline. Without this isolation, the performance improvements cannot be attributed to the adaptive FreqFold mechanism rather than domain-specific fine-tuning.
minor comments (2)
- [Abstract] Abstract: the financial benchmarks, base-model checkpoints, number of evaluation runs, and statistical tests underlying the reported percentages and concurrency multipliers are not specified, preventing direct verification of the numerical claims.
- [Abstract] Abstract: the precise criterion or search procedure used to choose the per-layer FreqFold sizes is not described, leaving the reproducibility of the “dynamic assignment” unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on attribution of gains. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes the 12.3% / 7.0% benchmark gains and the 2.69× / 2.43× concurrency increases to the layer-adaptive GQA-to-MLA transition. However, the manuscript supplies no ablation that applies the identical generalized KD + financial SFT pipeline to a uniform (non-adaptive) GQA-to-MLA baseline. Without this isolation, the performance improvements cannot be attributed to the adaptive FreqFold mechanism rather than domain-specific fine-tuning.
Authors: We agree the referee's point is valid: while the manuscript reports an adaptive-vs-uniform comparison for perplexity degradation (up to 35% reduction), it does not provide the requested ablation that holds the generalized KD + financial SFT pipeline fixed and varies only the FreqFold selection strategy (adaptive vs. uniform) when measuring downstream financial-benchmark accuracy and concurrency. The reported 12.3%/7.0% gains and concurrency multipliers are versus the original base models (which lack both the transition and the domain-specific training), so causal attribution to adaptivity alone is not fully isolated. We will add this ablation study in the revised manuscript, training both adaptive and uniform variants under identical KD + SFT conditions and reporting the resulting benchmark scores and concurrency numbers. This will allow readers to quantify the incremental benefit of the layer-adaptive mechanism. revision: yes
Circularity Check
No circularity; empirical results rest on external benchmarks
full rationale
The paper reports measured improvements (12.3% and 7.0% benchmark gains, 2.69× and 2.43× concurrency) from an adaptive GQA-to-MLA transition plus KD and financial SFT, compared against uniform baselines and base models. No equations, fitted parameters, or self-citations are shown that define the reported gains in terms of themselves or reduce the central claim to a renaming or construction. The derivation chain consists of architectural description followed by empirical evaluation on held-out financial tasks, which is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Advances in neural information processing systems , volume=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv preprint arXiv:2311.07911 , year=
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
-
[4]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[5]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[6]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[7]
Journal of the Association for Information Science and Technology , volume=
Good debt or bad debt: Detecting semantic orientations in economic texts , author=. Journal of the Association for Information Science and Technology , volume=. 2014 , publisher=
2014
-
[8]
Proceedings of the 32nd ACM international conference on information and knowledge management , pages=
Xuanyuan 2.0: A large chinese financial chat model with hundreds of billions parameters , author=. Proceedings of the 32nd ACM international conference on information and knowledge management , pages=
-
[9]
2024 , note =
OpenFinData: A Large Language Model Open-source Financial Evaluation Dataset , author =. 2024 , note =
2024
-
[10]
Fineval: A chinese financial domain knowledge evaluation benchmark for large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[11]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Benchmarking large language models on CFLUE-a Chinese financial language understanding evaluation dataset , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[12]
Proceedings of the AAAI conference on artificial intelligence , volume=
Crossner: Evaluating cross-domain named entity recognition , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[13]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[14]
arXiv preprint arXiv:2406.11903 , year=
A survey of large language models for financial applications: Progress, prospects and challenges , author=. arXiv preprint arXiv:2406.11903 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Finben: A holistic financial benchmark for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[17]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[18]
C ar E xpert: Leveraging Large Language Models for In-Car Conversational Question Answering
Rony, Md Rashad Al Hasan and Suess, Christian and Bhat, Sinchana Ramakanth and Sudhi, Viju and Schneider, Julia and Vogel, Maximilian and Teucher, Roman and Friedl, Ken and Sahoo, Soumya. C ar E xpert: Leveraging Large Language Models for In-Car Conversational Question Answering. Proceedings of the 2023 Conference on Empirical Methods in Natural Language ...
-
[19]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
The program testing ability of large language models for code , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[20]
arXiv preprint arXiv:2509.14507 , year=
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction , author=. arXiv preprint arXiv:2509.14507 , year=
-
[21]
2025 , eprint=
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition , author=. 2025 , eprint=
2025
-
[22]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[23]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[24]
2025 , publisher=
Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors , author=. 2025 , publisher=
2025
-
[25]
2022 , eprint=
Efficiently Scaling Transformer Inference , author=. 2022 , eprint=
2022
-
[26]
arXiv preprint arXiv:2510.26585 , year=
Stop wasting your tokens: Towards efficient runtime multi-agent systems , author=. arXiv preprint arXiv:2510.26585 , year=
-
[27]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[28]
arXiv preprint arXiv:2405.08944 , year=
Challenges in deploying long-context transformers: A theoretical peak performance analysis , author=. arXiv preprint arXiv:2405.08944 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Chain of agents: Large language models collaborating on long-context tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2405.04434 , year=
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Towards economical inference: Enabling deepseek’s multi-head latent attention in any transformer-based llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
arXiv preprint arXiv:2602.15763 , year=
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
-
[33]
arXiv preprint arXiv:2502.07864 , year=
Transmla: Multi-head latent attention is all you need , author=. arXiv preprint arXiv:2502.07864 , year=
-
[34]
arXiv preprint arXiv:2412.14838 , year=
DynamicKV: Task-aware adaptive KV cache compression for long context LLMs , author=. arXiv preprint arXiv:2412.14838 , year=
-
[35]
arXiv preprint arXiv:2412.12706 , year=
More tokens, lower precision: Towards the optimal token-precision trade-off in kv cache compression , author=. arXiv preprint arXiv:2412.12706 , year=
-
[36]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A simple and effective l\_2 norm-based strategy for kv cache compression , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[37]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Gqa: Training generalized multi-query transformer models from multi-head checkpoints , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[38]
Proceedings of machine learning and systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of machine learning and systems , volume=
-
[39]
2026 , eprint=
SWAA: Sliding Window Attention Adaptation for Efficient and Quality Preserving Long Context Processing , author=. 2026 , eprint=
2026
-
[40]
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , url =
Yang, Songlin and Wang, Bailin and Zhang, Yu and Shen, Yikang and Kim, Yoon , booktitle =. Parallelizing Linear Transformers with the Delta Rule over Sequence Length , url =. doi:10.52202/079017-3668 , editor =
-
[41]
arXiv preprint arXiv:2512.23914 , year=
Hardware Acceleration for Neural Networks: A Comprehensive Survey , author=. arXiv preprint arXiv:2512.23914 , year=
-
[42]
Available at SSRN 5381584 , year=
A review of llm agent applications in finance and banking , author=. Available at SSRN 5381584 , year=
-
[43]
arXiv preprint arXiv:2407.00365 , year=
Financial knowledge large language model , author=. arXiv preprint arXiv:2407.00365 , year=
-
[44]
arXiv preprint arXiv:1609.07843 , year=
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
-
[45]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Alpha-gpt: Human-ai interactive alpha mining for quantitative investment , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[46]
arXiv preprint arXiv:2407.17866 , year=
Financial statement analysis with large language models , author=. arXiv preprint arXiv:2407.17866 , year=
-
[47]
Lakkaraju, Kausik and Jones, Sara E and Vuruma, Sai Krishna Revanth and Pallagani, Vishal and Muppasani, Bharath C and Srivastava, Biplav , title =. 2023 , isbn =. doi:10.1145/3604237.3626867 , booktitle =
-
[48]
arXiv preprint arXiv:2006.08097 , year=
Finbert: A pretrained language model for financial communications , author=. arXiv preprint arXiv:2006.08097 , year=
arXiv 2006
-
[49]
arXiv preprint arXiv:2302.09432 , year=
Bbt-fin: Comprehensive construction of chinese financial domain pre-trained language model, corpus and benchmark , author=. arXiv preprint arXiv:2302.09432 , year=
-
[50]
arXiv preprint arXiv:2303.17564 , year=
Bloomberggpt: A large language model for finance , author=. arXiv preprint arXiv:2303.17564 , year=
-
[51]
arXiv preprint arXiv:2306.06031 , year=
Fingpt: Open-source financial large language models , author=. arXiv preprint arXiv:2306.06031 , year=
-
[52]
2024 , publisher=
YiZhao-12B-Chat: A Chinese Financial Large Language Model , author=. 2024 , publisher=
2024
-
[53]
arXiv preprint arXiv:2504.15716 , year=
Dianjin-r1: Evaluating and enhancing financial reasoning in large language models , author=. arXiv preprint arXiv:2504.15716 , year=
-
[54]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[55]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[56]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[57]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[58]
Direct preference optimization: Your language model is secretly a reward model , author=
-
[59]
2024 , url =
YiZhao-12B-Chat: A 12B-Parameter Financial Large Language Model , author =. 2024 , url =
2024
-
[60]
arXiv preprint arXiv:2505.07608 , year=
MiMo: Unlocking the Reasoning Potential of Language Model--From Pretraining to Posttraining , author=. arXiv preprint arXiv:2505.07608 , year=
-
[61]
arXiv preprint arXiv:2407.06645 , year=
Entropy Law: The Story Behind Data Compression and LLM Performance , author=. arXiv preprint arXiv:2407.06645 , year=
-
[62]
International Conference on Learning Representations (ICLR) , year=
\#INSTAG: Instruction Tagging for Analyzing Supervised Fine-Tuning of Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[63]
International Conference on Learning Representations (ICLR) , year=
What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning , author=. International Conference on Learning Representations (ICLR) , year=
-
[64]
arXiv preprint arXiv:2505.13990 , year=
DecIF: Improving Instruction-Following through Meta-Decomposition , author=. arXiv preprint arXiv:2505.13990 , year=
-
[65]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
TreeCut: A Synthetic Unanswerable Math Word Problem Dataset for LLM Hallucination Evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
-
[66]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
-
[67]
arXiv preprint arXiv:2304.12244 , year=
WizardLM: Empowering Large Pre-trained Language Models to Follow Complex Instructions , author=. arXiv preprint arXiv:2304.12244 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.