QCFuse: Query-Aware Cache Fusion via Compressed View for Efficient RAG Serving
Pith reviewed 2026-06-28 01:45 UTC · model grok-4.3
The pith
QCFuse achieves full-prefill quality in RAG serving by fusing KV caches with a compressed-view query-aware selector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
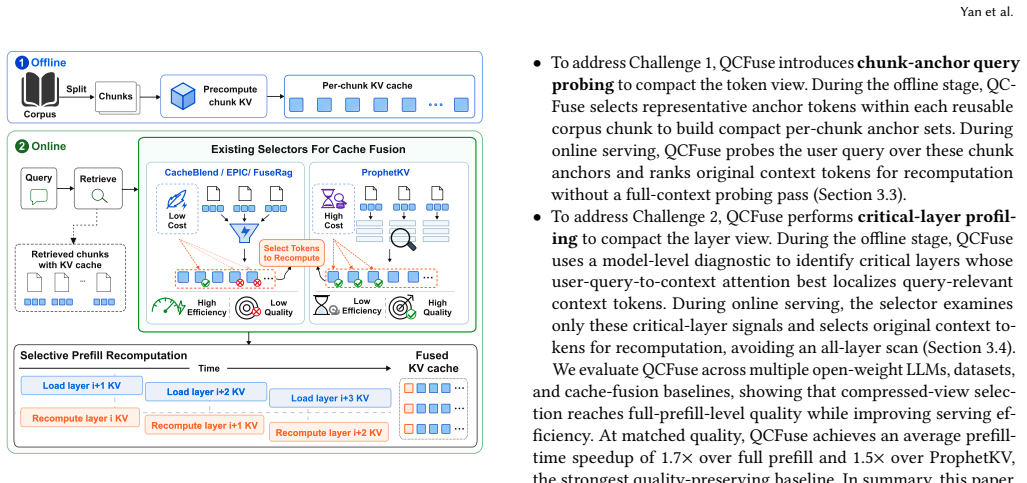
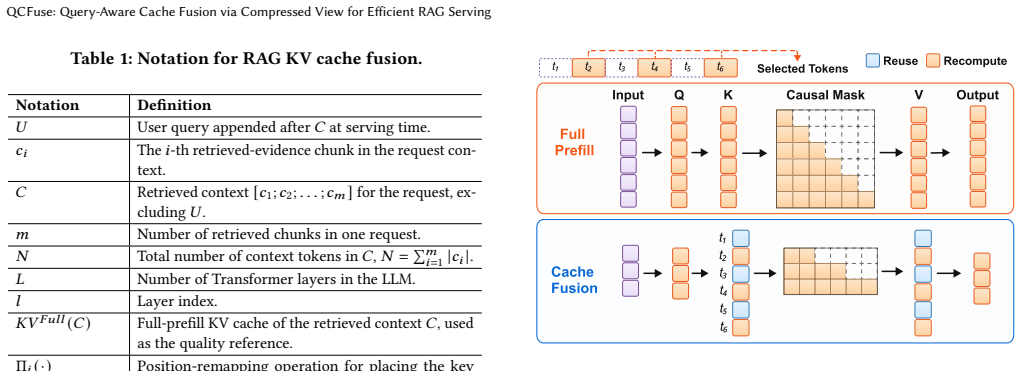
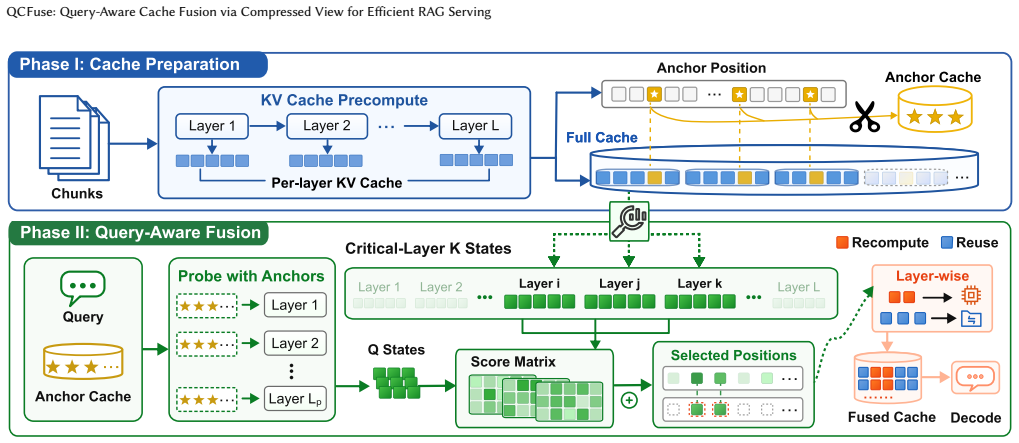
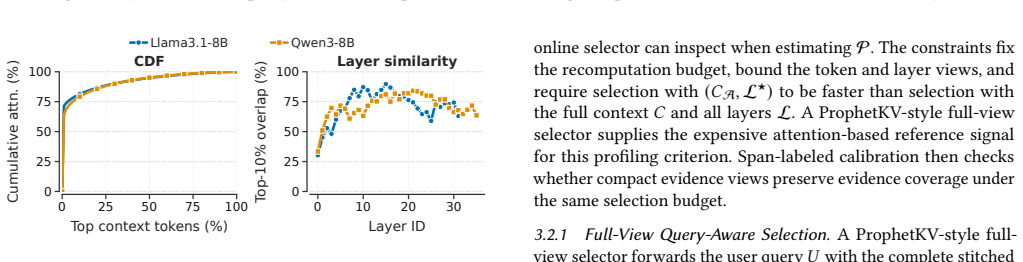
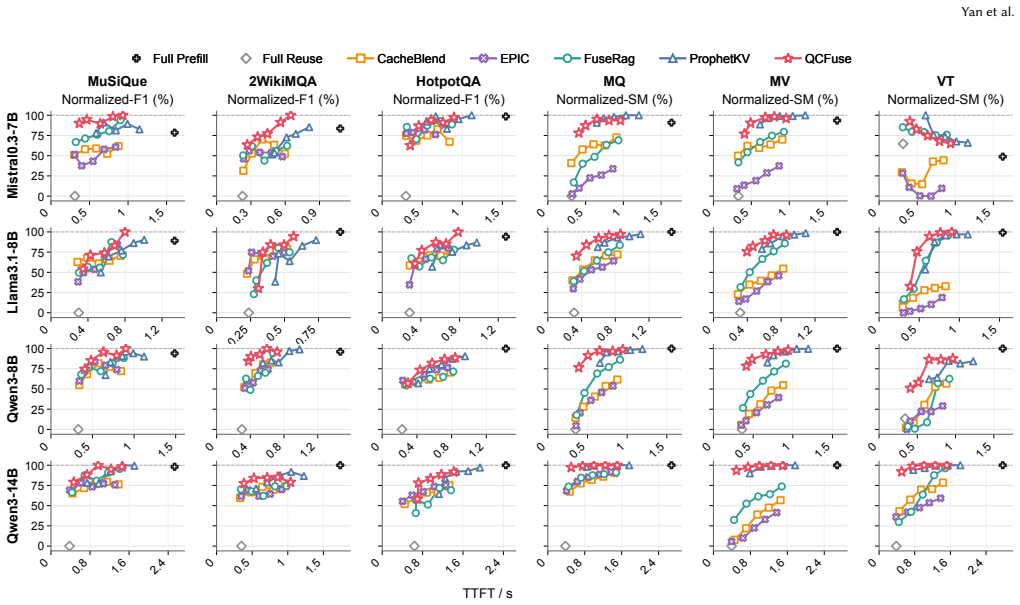
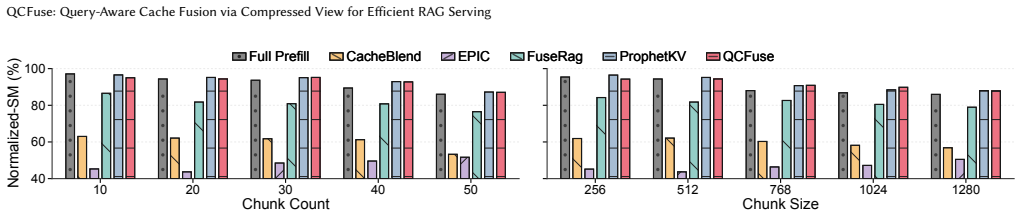
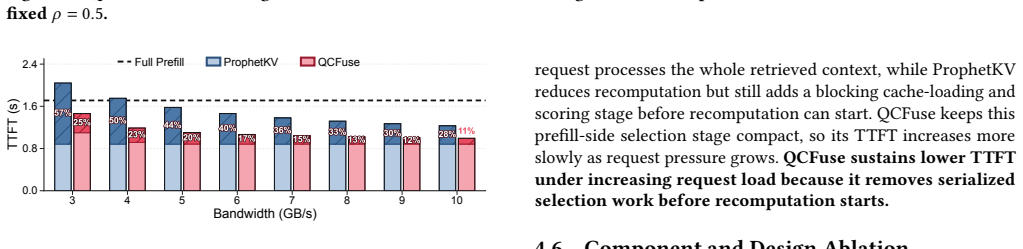
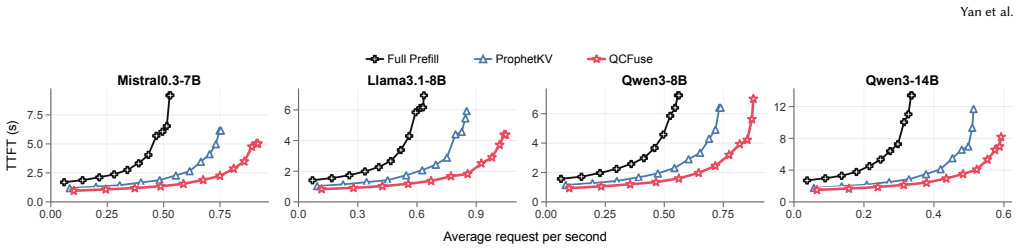
QCFuse reaches full-prefill-level quality. At matched quality, QCFuse achieves an average prefill-time speedup of 1.7x over full prefill and 1.5x over ProphetKV, the strongest quality-preserving baseline, by using chunk-anchor query probing to condition user-query states on compact per-chunk anchors and critical-layer profiling to identify recomputation tokens without all-layer inspection.
What carries the argument
The compressed-view query-aware selector that uses chunk-anchor query probing and critical-layer profiling to identify relevant evidence and recomputation tokens.
If this is right
- QCFuse matches full-prefill quality on RAG tasks.
- It delivers 1.7x prefill-time speedup over full prefill at matched quality.
- It delivers 1.5x prefill-time speedup over ProphetKV at matched quality.
- The speedups hold across four open-weight LLMs and six datasets.
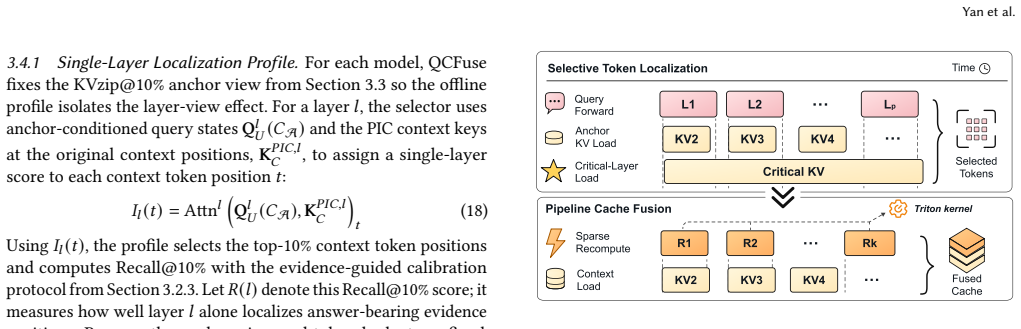
Where Pith is reading between the lines
- The same compressed probing idea might reduce recomputation needs in non-RAG settings that reuse past KV states.
- If the critical-layer choice generalizes, it could cut visibility requirements in other layer-pipelined inference systems.
- Lower prefill latency could make longer retrieved contexts practical in production RAG without extra hardware.
Load-bearing premise
Chunk-anchor query probing combined with critical-layer profiling can reliably identify relevant evidence and necessary recomputation tokens without full context or all-layer visibility.
What would settle it
Measure whether answer quality on a held-out dataset or model drops below full-prefill levels when QCFuse is applied at its reported recomputation budget.
Figures

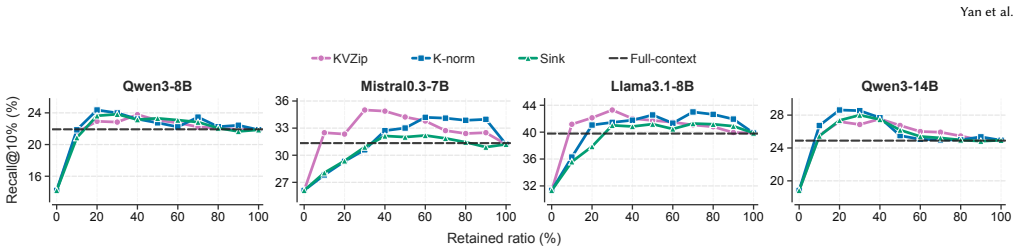
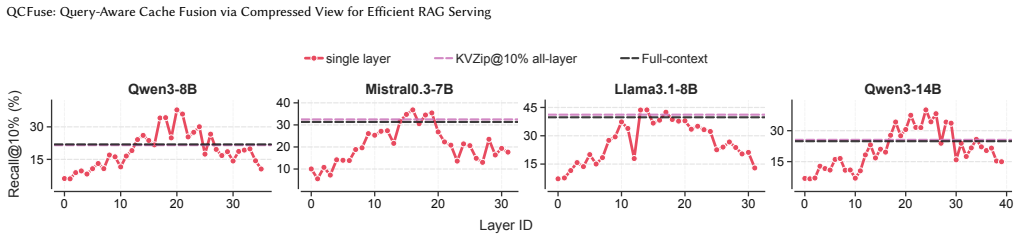
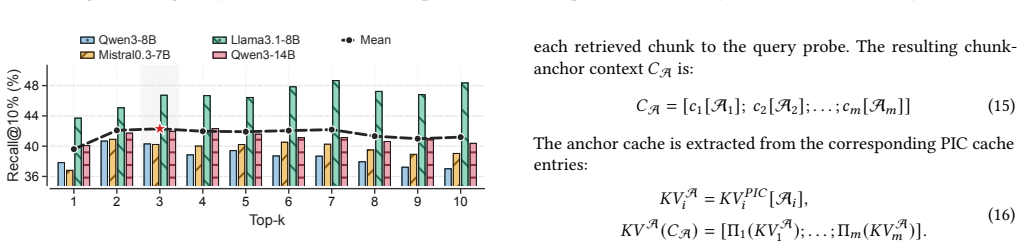

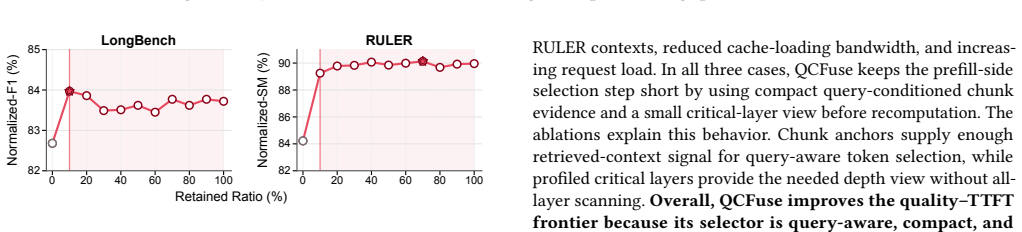
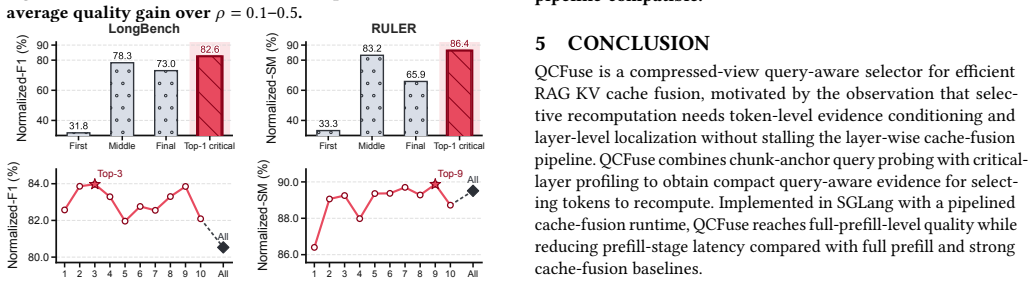
read the original abstract
Retrieval-augmented generation (RAG) improves large language model (LLM) answer quality by grounding generation in external evidence, but processing retrieved contexts makes the prefill stage a dominant serving cost. RAG cache fusion reduces this cost by reusing precomputed key-value (KV) caches for retrieved chunks and selectively recomputing tokens under the current prompt. Existing selectors, however, face a dilemma between quality and efficiency: fast query-agnostic or final-layer query-to-context selectors can miss request-relevant evidence, whereas full-view query-aware selectors require broad context and layer visibility before recomputation and therefore stall the layer-wise cache-fusion pipeline. We present QCFuse, a compressed-view query-aware selector for RAG cache fusion. QCFuse uses chunk-anchor query probing to condition user-query states on compact per-chunk anchors and critical-layer profiling to identify recomputation tokens without all-layer inspection. We implement QCFuse in SGLang and evaluate it on four open-weight LLMs across six datasets. QCFuse reaches full-prefill-level quality. At matched quality, QCFuse achieves an average prefill-time speedup of 1.7x over full prefill and 1.5x over ProphetKV, the strongest quality-preserving baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QCFuse, a compressed-view query-aware selector for RAG cache fusion that employs chunk-anchor query probing to condition on per-chunk anchors and critical-layer profiling to select recomputation tokens. It claims this reaches full-prefill quality while delivering 1.7x average prefill-time speedup over full prefill and 1.5x over ProphetKV across four open-weight LLMs and six datasets, implemented in SGLang.
Significance. If the quality-matching claim holds under the compressed-view constraints, the work would meaningfully advance efficient RAG serving by enabling layer-wise cache fusion without pipeline stalls, directly addressing the quality-efficiency tradeoff noted in prior selectors.
major comments (2)
- [Evaluation / §4] The central claim of full-prefill-level quality rests on the assumption that chunk-anchor probing plus critical-layer profiling suffices to identify relevant evidence and recomputation tokens. The manuscript should include a direct comparison (e.g., in the evaluation section) of selector accuracy against a full-view baseline on queries where broad context is required, with quantitative metrics such as evidence recall or end-to-end answer quality delta.
- [Experiments] Table reporting speedups at matched quality (presumably Table X) does not appear to include per-dataset variance, statistical significance, or controls for post-hoc threshold tuning; without these, the 1.7x and 1.5x averages cannot be assessed as robust across the six datasets.
minor comments (1)
- [Method] Notation for 'chunk-anchor' and 'critical-layer' should be defined with a small example in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of QCFuse. We address each major comment below and commit to revisions that improve the evaluation rigor without altering the core claims.
read point-by-point responses
-
Referee: [Evaluation / §4] The central claim of full-prefill-level quality rests on the assumption that chunk-anchor probing plus critical-layer profiling suffices to identify relevant evidence and recomputation tokens. The manuscript should include a direct comparison (e.g., in the evaluation section) of selector accuracy against a full-view baseline on queries where broad context is required, with quantitative metrics such as evidence recall or end-to-end answer quality delta.
Authors: We agree that an explicit selector-level comparison would further substantiate the compressed-view design. While our end-to-end results already show QCFuse matching full-prefill answer quality (which serves as the ultimate validation of evidence selection), we will add a new analysis in §4. This will report evidence recall for QCFuse versus a full-view oracle on a curated subset of queries requiring broad context, using the same six datasets. The addition will be limited to post-hoc analysis on existing traces to avoid new experiments. revision: yes
-
Referee: [Experiments] Table reporting speedups at matched quality (presumably Table X) does not appear to include per-dataset variance, statistical significance, or controls for post-hoc threshold tuning; without these, the 1.7x and 1.5x averages cannot be assessed as robust across the six datasets.
Authors: We acknowledge the table lacks these details. In the revised manuscript we will expand the table (and its caption) to report per-dataset means with standard deviations across three random seeds, include paired t-test p-values against baselines, and explicitly state that all thresholds were selected via 5-fold cross-validation on a held-out portion of each dataset rather than post-hoc on test data. These changes will be made to the existing results without new runs. revision: yes
Circularity Check
No circularity; empirical systems paper with external baselines
full rationale
The paper is an empirical systems contribution that implements QCFuse in SGLang and reports direct speed/quality measurements against full prefill and ProphetKV on six datasets and four LLMs. No mathematical derivation chain, fitted-parameter-as-prediction, or self-citation load-bearing step is present; all quality claims rest on external experimental comparison rather than reduction to the method's own inputs or prior self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Mahapatra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, and Shiv Saini. 2025. Cache-craft: Managing chunk-caches for efficient retrieval-augmented genera- tion.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[2]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In 18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
2024
-
[3]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 4895–4901. https://doi.org/1...
-
[4]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. arXiv:2308.14508 [cs.CL] https://arxiv.org/abs/2308.14508
Pith/arXiv arXiv 2024
-
[5]
Muhammad Imam Luthfi Balaka, David Alexander, Qiming Wang, Yue Gong, Adila Krisnadhi, and Raul Castro Fernandez. 2025. Pneuma: Leveraging llms for tabular data representation and retrieval in an end-to-end system.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[6]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. 2024. PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling. arXiv:2406.02069 [cs.CL] https://arxiv.org/abs/2406.02069 QCFuse: Query-Aware Cache Fusion via Compressed View for Efficient RAG Serving
Pith/arXiv arXiv 2024
-
[7]
Cheng Chen, Chenzhe Jin, Yunan Zhang, Sasha Podolsky, Chun Wu, Szu- Po Wang, Eric Hanson, Zhou Sun, Robert Walzer, and Jianguo Wang. 2024. SingleStore-V: An Integrated Vector Database System in SingleStore.Proc. VLDB Endow.17, 12 (2024), 3772–3785. https://doi.org/10.14778/3685800.3685805
-
[8]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems, Vol. 35. 16344–16359
2022
-
[9]
Yangshen Deng, Zhengxin You, Long Xiang, Qilong Li, Peiqi Yuan, Zhaoyang Hong, Yitao Zheng, Wanting Li, Runzhong Li, Haotian Liu, et al. 2025. AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference. In Companion of the 2025 International Conference on Management of Data. 364–377. https://doi.org/10.1145/3722212.3724428
-
[10]
Alessio Devoto, Maximilian Jeblick, and Simon Jégou. 2025. Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribu- tion. https://doi.org/10.48550/arXiv.2510.00636 arXiv:2510.00636 [cs.AI]
-
[11]
Alessio Devoto, Yu Zhao, Simone Scardapane, and Pasquale Minervini. 2024. A Simple and Effective 𝐿2 Norm-Based Strategy for KV Cache Compression. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA, 18476–18499. https://doi.org/10.18653/v1/2024.emnlp-main.1027
-
[12]
Amr Elmeleegy, Nick Comly, and Sharan Chetlur. 2024. Streamlining AI Inference Performance and Deployment with NVIDIA TensorRT-LLM Chunked Prefill. NVIDIA Technical Blog. https://developer.nvidia.com/blog/streamlining-ai- inference-performance-and-deployment-with-nvidia-tensorrt-llm-chunked- prefill/ Accessed: 2026-05-28
2024
-
[13]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S. Kevin Zhou. 2024. Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference. arXiv:2407.11550 [cs.CL] https://arxiv.org/abs/2407.11550
Pith/arXiv arXiv 2024
-
[14]
Shihong Gao, Xin Zhang, Yanyan Shen, and Lei Chen. 2025. Apt-serve: Adaptive request scheduling on hybrid cache for scalable llm inference serving.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28. https://doi.org/10.1145/ 3725394
2025
-
[15]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 https: //arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2023
-
[16]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao
-
[17]
arXiv preprint arXiv:2310.01801(2023)
Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801(2023)
Pith/arXiv arXiv 2023
-
[18]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. 2024. Prompt cache: Modular attention reuse for low-latency inference. Proceedings of Machine Learning and Systems6 (2024), 325–338
2024
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[20]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang
-
[21]
InInternational confer- ence on machine learning
Retrieval augmented language model pre-training. InInternational confer- ence on machine learning. PMLR, 3929–3938
-
[22]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. arXiv:2011.01060 [cs.CL] https://arxiv.org/abs/2011.01060
Pith/arXiv arXiv 2020
-
[23]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models? arXiv:2404.06654 [cs.CL] https://arxiv.org/abs/2404.06654
Pith/arXiv arXiv 2024
-
[24]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. 2024. EPIC: Efficient Position-Independent Caching for Serving Large Language Models.arXiv preprint arXiv:2410.15332(2024)
arXiv 2024
-
[25]
Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 3543–3556. https: //doi.org/10.18653/v1/N19-1357
-
[26]
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What does BERT learn about the structure of language?. InProceedings of the 57th annual meeting of the association for computational linguistics. 3651–3657
2019
-
[27]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[28]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al
-
[29]
Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems37 (2024), 52481–52515
2024
-
[30]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. arXiv:2310.05736 [cs.CL] https://arxiv.org/abs/2310.05736
arXiv 2023
-
[31]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, B...
2024
-
[32]
https://doi.org/10.18653/v1/2024.acl-long.91
-
[33]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shufan Liu, Xuanzhe Liu, and Xin Jin. 2024. Ragcache: Efficient knowledge caching for retrieval-augmented generation.ACM Transactions on Computer Systems(2024)
2024
-
[34]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 6769–6781. https://doi.org/10.18653/v1/2020....
-
[35]
Lee, Sangdoo Yun, and Hyun Oh Song
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. 2025. KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction.arXiv preprint arXiv:2505.23416(2025)
arXiv 2025
-
[36]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title =
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[37]
Efficient memory management for large language model serving with pagedattention,
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Effi- cient Memory Management for Large Language Model Serving with PagedAt- tention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). Association for Computing Machinery, New York, NY, USA, 61...
-
[38]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[39]
Guoliang Li, Xuanhe Zhou, and Xinyang Zhao. 2024. LLM for Data Management. Proc. VLDB Endow.17, 12 (2024), 4213–4216. https://doi.org/10.14778/3685800. 3685838
-
[40]
Yuhang Li, Rong Gu, Chengying Huan, Zhibin Wang, Renjie Yao, Chen Tian, and Guihai Chen. 2025. Hotprefix: Hotness-aware kv cache scheduling for efficient prefix sharing in llm inference systems.Proceedings of the ACM on Management of Data3, 4 (2025), 1–27. https://doi.org/10.1145/3749168
-
[41]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Informa- tion Processing Systems37 (2024), 22947–22970
2024
-
[42]
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. 2024. QServe: W4A8KV4 Quantization and System Co- design for Efficient LLM Serving. arXiv:2405.04532 [cs.CL] https://arxiv.org/ abs/2405.04532
arXiv 2024
-
[43]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[44]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, and Junchen Jiang. 2025. LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference. arXiv:2510.09665 [cs.LG] https://arxiv.org/abs/2510.09665
arXiv 2025
-
[45]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. 2024. CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving. arXiv:2310.07240 [cs.NI] https://arxiv.org/abs/2310.07240
arXiv 2024
-
[46]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time. InAdvances in Neural Information Process- ing Systems, Vol. 36. https://papers.nips.cc/paper_files/paper/2023/ha...
2023
-
[47]
Samuel Madden, Michael J. Cafarella, Michael J. Franklin, and Tim Kraska. 2024. Databases Unbound: Querying All of the World’s Bytes with AI.Proc. VLDB Endow.17, 12 (2024), 4546–4554. https://doi.org/10.14778/3685800.3685916
-
[48]
Smith, and Mike Lewis
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. InInterna- tional Conference on Learning Representations. https://openreview.net/forum? id=R8sQPpGCv0 Yan et al
2022
-
[49]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text. InProceed- ings of the 2016 Conference on Empirical Methods in Natural Language Pro- cessing. Association for Computational Linguistics, Austin, Texas, 2383–2392. https://doi.org/10.18653/v1/D16-1264
-
[50]
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-Attention with Relative Position Representations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, 464–468. https://doi.org/10.18653...
-
[51]
Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150 https://arxiv.org/abs/1911.02150
Pith/arXiv arXiv 2019
-
[52]
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. 2025. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013(2025)
Pith/arXiv arXiv 2025
-
[53]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2023. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864 [cs.CL] https://arxiv.org/abs/2104.09864
Pith/arXiv arXiv 2023
-
[54]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 235. PMLR, 47901–47911. https: //proceedings.mlr.press/v235/tang24l.html
2024
-
[55]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[56]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. BERT rediscovers the classical NLP pipeline. InProceedings of the 57th annual meeting of the association for computational linguistics. 4593–4601
2019
-
[57]
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. 2017. NewsQA: A Machine Comprehen- sion Dataset. InProceedings of the 2nd Workshop on Representation Learning for NLP. Association for Computational Linguistics, Vancouver, Canada, 191–200. https://doi.org/10.18653/v1/W17-2623
-
[58]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[59]
arXiv:2108.00573 [cs.CL] https://arxiv.org/abs/2108.00573
MuSiQue: Multihop Questions via Single-hop Question Composition. arXiv:2108.00573 [cs.CL] https://arxiv.org/abs/2108.00573
-
[60]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[61]
Jesse Vig and Yonatan Belinkov. 2019. Analyzing the structure of attention in a transformer language model.arXiv preprint arXiv:1906.04284(2019)
Pith/arXiv arXiv 2019
-
[62]
Jiahao Wang, Weiyu Xie, Mingxing Zhang, Boxin Zhang, Jianwei Dong, Yuening Zhu, Chen Lin, Jingqi Tang, Yaochen Han, Zhiyuan Ai, et al. 2026. From prefix cache to fusion rag cache: Accelerating llm inference in retrieval-augmented generation.Proceedings of the ACM on Management of Data4, 1 (SIGMOD (2026), 1–28
2026
-
[63]
Shihao Wang, Jiahao Chen, Yanqi Pan, Hao Huang, Yichen Hao, Xiangyu Zou, Wen Xia, Wentao Zhang, Chong Qiu, and Pengfei Wang. 2026. ProphetKV: User-Query-Driven Selective Recomputation for Efficient KV Cache Reuse in Retrieval-Augmented Generation.ArXivabs/2602.02579 (2026)
arXiv 2026
-
[64]
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, and Maosong Sun. 2024. Infllm: Training-free long-context extrapolation for llms with an efficient context memory.Advances in Neural Information Processing Systems37 (2024), 119638–119661
2024
-
[65]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InInternational Conference on Learning Representations. https://openreview.net/forum?id= NG7sS51zVF
2024
-
[66]
Fangyuan Xu, Weijia Shi, and Eunsol Choi. 2023. RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation. arXiv:2310.04408 [cs.CL] https://arxiv.org/abs/2310.04408
arXiv 2023
-
[67]
Dongjie Yang, Xiaodong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao
-
[68]
InFindings of the Association for Computational Linguistics: ACL
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference. InFindings of the Association for Computational Linguistics: ACL
-
[69]
https://doi.org/10.18653/v1/2024.findings-acl.195
Association for Computational Linguistics, Bangkok, Thailand, 3258–3270. https://doi.org/10.18653/v1/2024.findings-acl.195
-
[70]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. arXiv:1809.09600 [cs.CL] https://arxiv.org/abs/1809.09600
Pith/arXiv arXiv 2018
-
[71]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. InProceedings of the Twentieth European Conference on Computer Systems. 94–109
2025
-
[72]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung- Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’22). USENIX Association, Carlsbad, CA, USA, 521–538
2022
-
[73]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. 2025. Native sparse attention: Hardware-aligned and natively trainable sparse attention. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 23078–23097
2025
-
[74]
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, and Bin Cui. 2025. Pqcache: Product quantization-based kvcache for long context llm inference.Proceedings of the ACM on Management of Data3, 3 (2025), 1–30. https://doi.org/10.1145/3725338
-
[75]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36 (2023), 34661–34710
2023
-
[76]
Xinyang Zhao, Xuanhe Zhou, and Guoliang Li. 2024. Chat2Data: An Interactive Data Analysis System with RAG, Vector Databases and LLMs.Proc. VLDB Endow. 17, 12 (2024), 4481–4484. https://doi.org/10.14778/3685800.3685905
-
[77]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2023. SGLang: Efficient Execution of Struc- tured Language Model Programs. https://doi.org/10.48550/arXiv.2312.07104 arXiv:2312.07104 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.07104 2023
-
[78]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, Santa Clara, CA, USA, 193–210
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.