Geometry-Aware Dataset Condensation for Diffusion Model Training
Pith reviewed 2026-06-28 02:05 UTC · model grok-4.3
The pith
Reformulating subset selection with one-sided partial optimal transport preserves geometric structure for diffusion model training from compact real datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
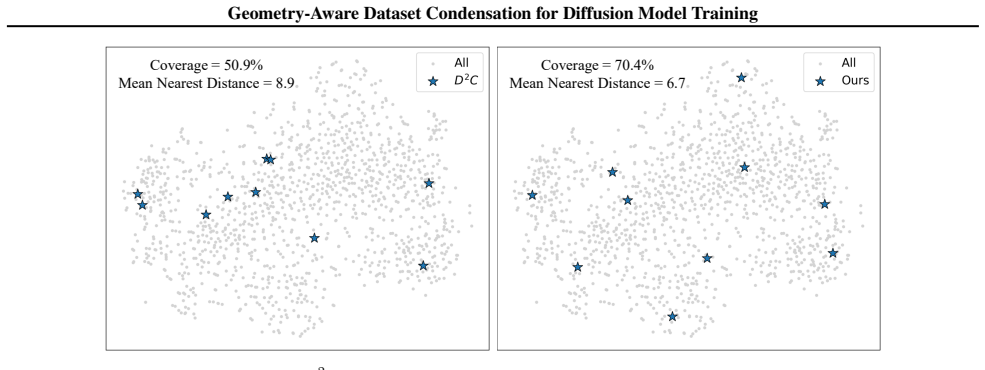
The central claim is that by incorporating one-sided partial optimal transport into real subset selection, a compact subset can be aligned with the full data distribution while allowing unmatched mass in low-density regions, thereby preserving the geometric structure necessary for effective diffusion model training, and that complementing this with feature-statistics and semantic consistency regularization yields superior fidelity and distributional coverage compared to prior methods.
What carries the argument
One-sided partial optimal transport, which selectively aligns a compact subset with the full data distribution while permitting unmatched mass in low-density regions to maintain geometric structure.
If this is right
- Superior performance in fidelity and coverage is achieved across different diffusion models, subset sizes, and resolutions.
- The method enables effective training with real data subsets rather than synthetic ones.
- A two-stage discrete optimization makes the alignment computationally feasible.
Where Pith is reading between the lines
- This selective alignment might apply to other density-based generative models beyond diffusion.
- It could lead to more efficient dataset curation pipelines for large-scale image generation tasks.
- Testing on non-image domains like audio or text could reveal broader applicability.
Load-bearing premise
That the diffusion likelihood objectives specifically require preservation of the full distributional geometry in the condensed dataset, and that the proposed transport plus regularizers achieve this preservation better than alternatives.
What would settle it
Training a diffusion model on the proposed condensed dataset and comparing its sample quality and likelihood scores against models trained on randomly selected subsets or previous condensation methods; if no improvement is observed, the claim would be falsified.
Figures




read the original abstract
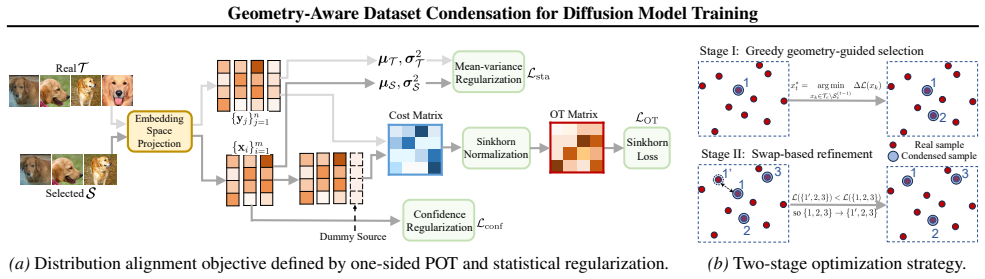
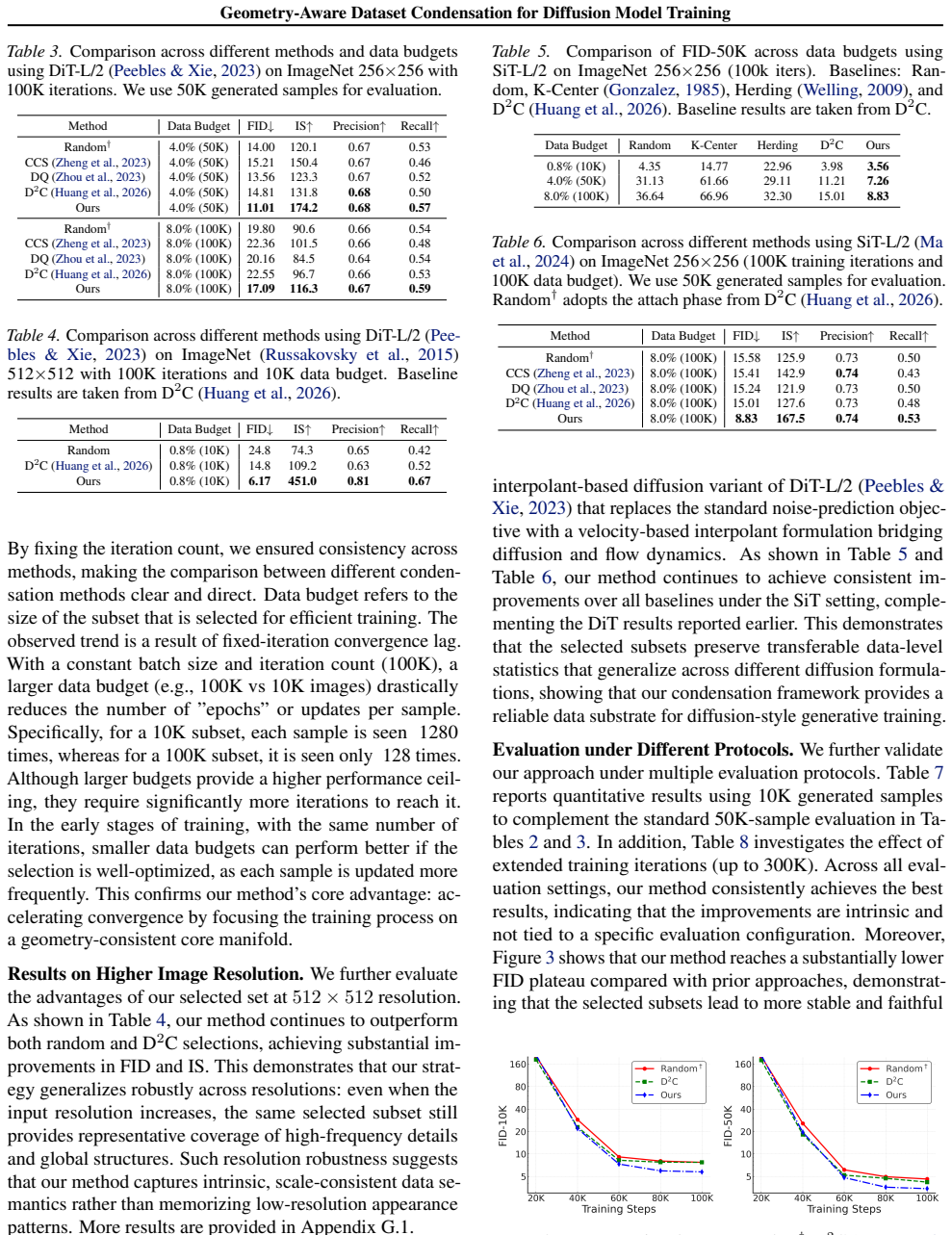
Dataset condensation aims to construct compact datasets from real data via synthesis or selection. However, existing approaches are ill-suited for diffusion model training: synthetic data generation often yields low-fidelity samples unsuitable for authentic modeling, while real subset selection typically fails to preserve the distributional geometry required by diffusion likelihood objectives. To address this, we propose to reformulate real subset selection as a geometry-aware distribution alignment problem. By incorporating one-sided partial optimal transport, our method selectively aligns a compact subset with the full data distribution while allowing unmatched mass in low-density regions, ensuring the preserved geometric structure necessary for effective diffusion model training. To further ensure distributional fidelity, we complement geometric alignment with lightweight feature-statistics and semantic consistency regularization. An efficient two-stage discrete optimization strategy is proposed to achieve this alignment objective. Extensive experiments across diffusion variants, subset sizes, image resolutions, and training rounds show that our method achieves superior fidelity and distributional coverage in diffusion model training. Codes are available at https://github.com/2018cx/GADC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes reformulating real subset selection for dataset condensation as a geometry-aware distribution alignment problem using one-sided partial optimal transport. This selectively aligns a compact subset with the full data distribution while allowing unmatched mass in low-density regions, supplemented by feature-statistics and semantic consistency regularizers, and solved via an efficient two-stage discrete optimization. The authors claim this preserves the distributional geometry required by diffusion likelihood objectives and yields superior fidelity and coverage in experiments across diffusion variants, subset sizes, resolutions, and training rounds.
Significance. If the central claims hold with proper verification, the approach could meaningfully advance efficient diffusion model training by addressing limitations of synthetic data (low fidelity) and standard subset selection (poor geometry preservation). The code release at the provided GitHub link is a strength for reproducibility. However, without direct evidence isolating the OT contribution, the significance remains provisional.
major comments (1)
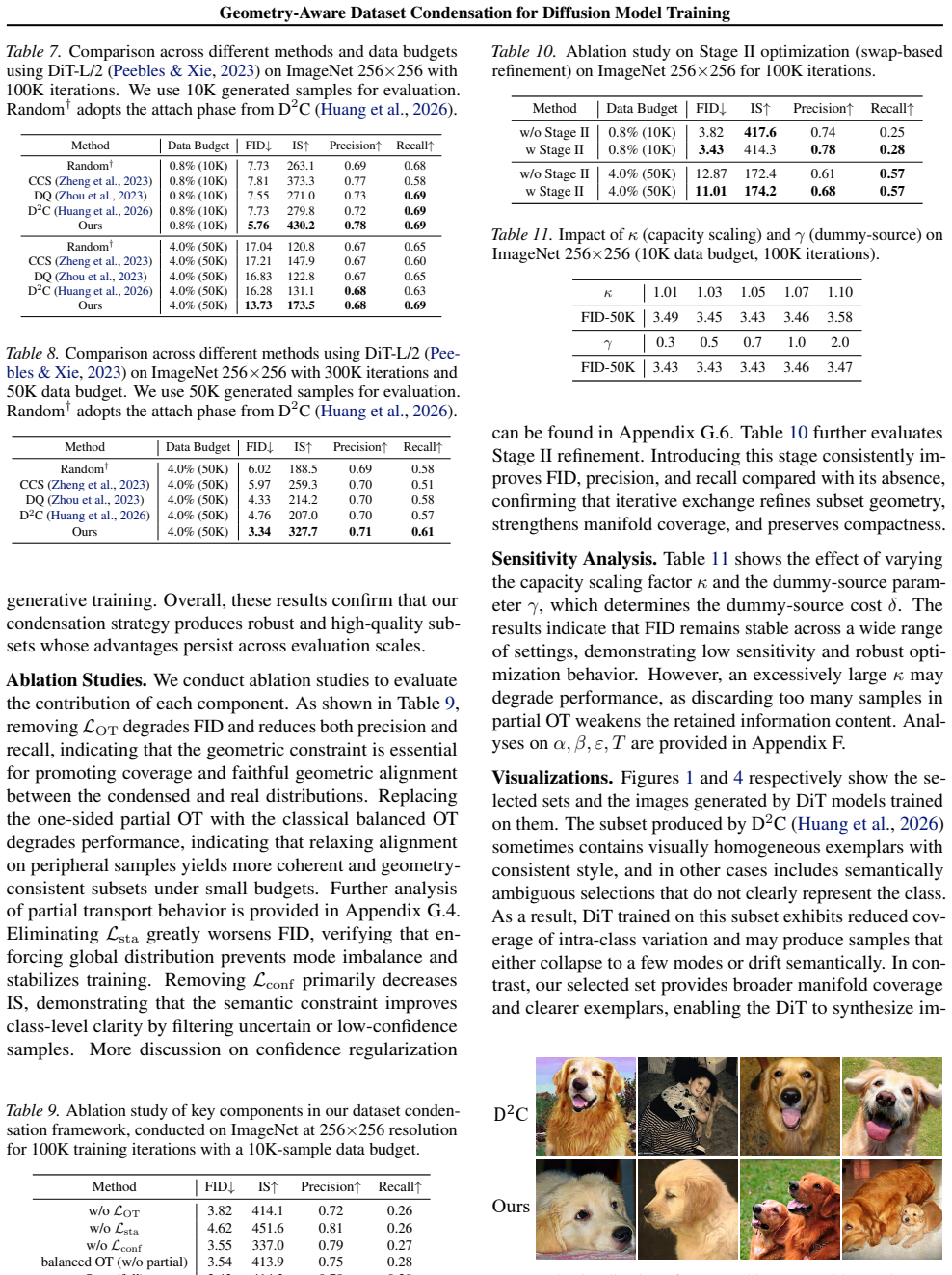
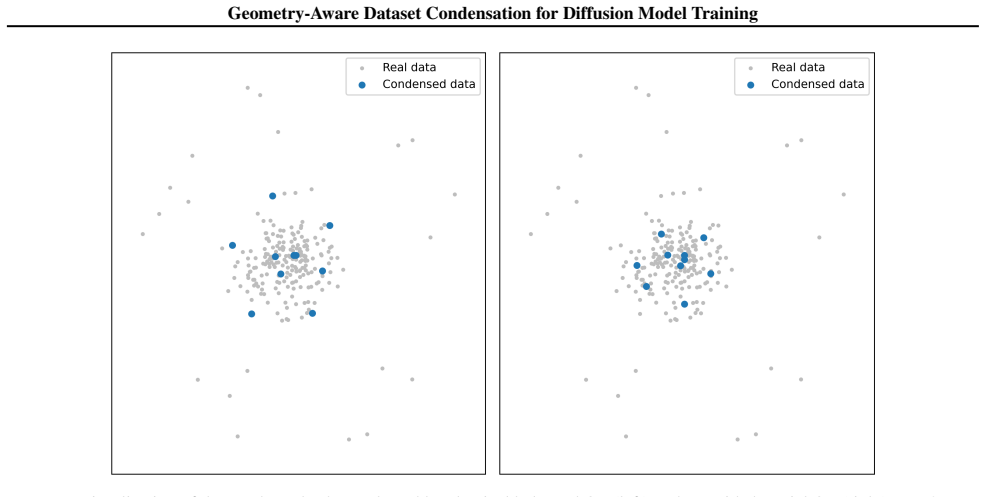
- [Experiments] Experiments (throughout, including claims of 'superior fidelity and distributional coverage'): no explicit post-selection geometry diagnostic is reported (e.g., empirical Wasserstein distance to the full distribution, mode-coverage statistic, or score-function alignment between subset and full data) that isolates the one-sided partial OT term from the regularizers or from simple diversity heuristics. Downstream FID/coverage numbers therefore cannot confirm that geometry preservation is what drives the gains, as required by the central claim.
minor comments (1)
- [Abstract] Abstract: the statement that 'extensive experiments show superior results' provides no quantitative numbers, baselines, error bars, or ablation details, which weakens the ability to assess the claims from the abstract alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment raises an important point about isolating the contribution of the one-sided partial OT term, which we address below.
read point-by-point responses
-
Referee: Experiments (throughout, including claims of 'superior fidelity and distributional coverage'): no explicit post-selection geometry diagnostic is reported (e.g., empirical Wasserstein distance to the full distribution, mode-coverage statistic, or score-function alignment between subset and full data) that isolates the one-sided partial OT term from the regularizers or from simple diversity heuristics. Downstream FID/coverage numbers therefore cannot confirm that geometry preservation is what drives the gains, as required by the central claim.
Authors: We agree that the current experiments do not include explicit post-selection geometry diagnostics that directly isolate the one-sided partial OT contribution. In the revised manuscript we will add quantitative diagnostics, including the empirical Wasserstein distance between the selected subset and the full data distribution as well as mode-coverage statistics, computed both with and without the OT term (and against simple diversity baselines). These will be reported alongside the existing FID and coverage results to better substantiate the central claim that geometry preservation drives the observed gains. revision: yes
Circularity Check
No significant circularity; derivation is a proposed reformulation without self-referential reduction.
full rationale
The abstract and provided text present a novel reformulation of subset selection as a geometry-aware alignment problem solved via one-sided partial optimal transport plus regularizers and two-stage optimization. No equations, fitted parameters renamed as predictions, or self-citations appear in the given material that would reduce the claimed preservation of distributional geometry to an input by construction. The method is offered as an independent proposal for diffusion training, with downstream experiments cited as validation rather than tautological restatements. This is the common case of a self-contained algorithmic contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion likelihood objectives require preserved distributional geometry that existing condensation methods fail to maintain.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2507.05914 , year=
Accelerating Diffusion Model Training under Minimal Budgets: A Condensation-Based Perspective , author=. arXiv preprint arXiv:2507.05914 , year=
-
[2]
International Conference on Learning Representations (ICLR) , year=
An Empirical Study of Example Forgetting during Deep Neural Network Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
Conference on Neural Information Processing Systems (NeurIPS) , volume=
Partial optimal transport with applications on positive-unlabeled learning , author=. Conference on Neural Information Processing Systems (NeurIPS) , volume=
-
[4]
arXiv preprint arXiv:2110.07580 , year=
Graph condensation for graph neural networks , author=. arXiv preprint arXiv:2110.07580 , year=
-
[5]
Theoretical computer science , volume=
Clustering to minimize the maximum intercluster distance , author=. Theoretical computer science , volume=. 1985 , publisher=
1985
-
[6]
International Conference on Learning Representations (ICLR) , year=
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
AAAI Conference on Artificial Intelligence (AAAI) , volume=
Adaptive Dataset Quantization , author=. AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[8]
Reed and Dragomir Anguelov and Dumitru Erhan and Vincent Vanhoucke and Andrew Rabinovich , title =
Christian Szegedy and Wei Liu and Yangqing Jia and Pierre Sermanet and Scott E. Reed and Dragomir Anguelov and Dumitru Erhan and Vincent Vanhoucke and Andrew Rabinovich , title =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[9]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Christian Szegedy and Vincent Vanhoucke and Sergey Ioffe and Jonathon Shlens and Zbigniew Wojna , title =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[10]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[11]
arXiv preprint arXiv:2501.10605 , year =
Wasserstein Adaptive Value Estimation for Actor-Critic Reinforcement Learning , author =. arXiv preprint arXiv:2501.10605 , year =
-
[12]
JCST , volume =
Semi-discrete optimal transport for long-tailed classification , author =. JCST , volume =
-
[13]
Monograph: Optimal Transport: Old and New , pages =
The wasserstein distances , author =. Monograph: Optimal Transport: Old and New , pages =. 2009 , publisher=
2009
-
[14]
IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , volume =
An optimal transport analysis on generalization in deep learning , author =. IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , volume =
-
[15]
International Joint Conference on Language Resources and Evaluation and International Conference on Computational Linguistics (LREC-COLING) , pages =
Sinkhorn Distance Minimization for Knowledge Distillation , author =. International Joint Conference on Language Resources and Evaluation and International Conference on Computational Linguistics (LREC-COLING) , pages =
-
[16]
arXiv preprint arXiv:2512.08317 , year=
GeoDM: Geometry-aware Distribution Matching for Dataset Distillation , author=. arXiv preprint arXiv:2512.08317 , year=
-
[17]
AAAI , volume=
M3d: Dataset condensation by minimizing maximum mean discrepancy , author=. AAAI , volume=
-
[18]
Statistical Data Analysis Based on the L1-Norm and Related Methods , editor=
Clustering by means of medoids , author=. Statistical Data Analysis Based on the L1-Norm and Related Methods , editor=. 1987 , publisher=
1987
-
[19]
IEEE Access , year=
Cyclic Learning Rate-Based Co-Training for Image Classification With Noisy Labels , author=. IEEE Access , year=
-
[20]
International Journal of Computer Vision (IJCV) , volume=
Gl-mcm: Global and local maximum concept matching for zero-shot out-of-distribution detection , author=. International Journal of Computer Vision (IJCV) , volume=. 2025 , publisher=
2025
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
Rethinking long-tailed dataset distillation: A uni-level framework with unbiased recovery and relabeling , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[22]
IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
SinKD: Sinkhorn Distance Minimization for Knowledge Distillation , author =. IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Optimizing distributional geometry alignment with optimal transport for generative dataset distillation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[24]
International Conference on Learning Representations (ICLR) , year =
Cross-Domain Offline Policy Adaptation with Optimal Transport and Dataset Constraint , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
AAAI Conference on Artificial Intelligence (AAAI) , year =
Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models , author =. AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[26]
arXiv preprint arXiv:2501.18901 , year =
Lightspeed Geometric Dataset Distance via Sliced Optimal Transport , author =. arXiv preprint arXiv:2501.18901 , year =
-
[27]
arXiv preprint arXiv:2503.08155 , year =
Domain Adaptation and Entanglement: an Optimal Transport Perspective , author =. arXiv preprint arXiv:2503.08155 , year =
-
[28]
2024 , url =
Meta , title =. 2024 , url =
2024
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year =
On the benefit of optimal transport for curriculum reinforcement learning , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year =
-
[30]
IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
Sample efficient deep reinforcement learning with online state abstraction and causal transformer model prediction , author =. IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
-
[31]
IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
CVaR-Constrained Policy Optimization for Safe Reinforcement Learning , author =. IEEE Transactions on Neural Networks and Learning Systems (TNNLS) , year =
-
[32]
Conference on Neural Information Processing Systems (NeurIPS) , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Conference on Neural Information Processing Systems (NeurIPS) , volume=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Dataset quantization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[34]
Proceedings of the European conference on computer vision (ECCV) , pages=
Dataset quantization with active learning based adaptive sampling , author=. Proceedings of the European conference on computer vision (ECCV) , pages=. 2024 , organization=
2024
-
[35]
International Conference on Machine Learning (ICML) , pages=
Herding dynamical weights to learn , author=. International Conference on Machine Learning (ICML) , pages=
-
[36]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
DELT: A Simple Diversity-driven EarlyLate Training for Dataset Distillation , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[37]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Towards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[38]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Emphasizing Discriminative Features for Dataset Distillation in Complex Scenarios , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[39]
arXiv preprint arXiv:2508.01139 , year=
Dataset Condensation with Color Compensation , author=. arXiv preprint arXiv:2508.01139 , year=
-
[40]
AAAI Conference on Artificial Intelligence (AAAI) , volume =
Hierarchical multi-marginal optimal transport for network alignment , author =. AAAI Conference on Artificial Intelligence (AAAI) , volume =
-
[41]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Hierarchical Features Matter: A Deep Exploration of Progressive Parameterization Method for Dataset Distillation , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[42]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[43]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Dataset distillation by matching training trajectories , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[44]
arXiv preprint arXiv:2502.20653 , year=
Dataset Distillation with Neural Characteristic Function: A Minmax Perspective , author=. arXiv preprint arXiv:2502.20653 , year=
-
[45]
arXiv preprint arXiv:2501.07575 , year=
Dataset Distillation via Committee Voting , author=. arXiv preprint arXiv:2501.07575 , year=
-
[46]
arXiv preprint arXiv:2502.05673 , year=
The Evolution of Dataset Distillation: Toward Scalable and Generalizable Solutions , author=. arXiv preprint arXiv:2502.05673 , year=
-
[47]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume =
Ruonan Yu and Songhua Liu and Xinchao Wang , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume =
-
[48]
arXiv preprint arXiv:2305.01975 , year=
A Survey on Dataset Distillation: Approaches, Applications and Future Directions , author=. arXiv preprint arXiv:2305.01975 , year=
-
[49]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[50]
arXiv preprint arXiv:2108.11080 , year=
Heredity-aware child face image generation with latent space disentanglement , author=. arXiv preprint arXiv:2108.11080 , year=
-
[51]
Neighbor-aware Geodesic Transportation for Neighborhood Refinery , author=
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Incentivizing reasoning for advanced instruction-following of large language models , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[53]
arXiv preprint arXiv:1612.00804 , year =
Restricted Strong Convexity Implies Weak Submodularity , author =. arXiv preprint arXiv:1612.00804 , year =
-
[54]
International Conference on Machine Learning (ICML) , pages =
Submodular Meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection , author =. International Conference on Machine Learning (ICML) , pages =
-
[55]
arXiv preprint arXiv:1312.6114 , year =
Auto-Encoding Variational Bayes , author =. arXiv preprint arXiv:1312.6114 , year =
-
[56]
arXiv preprint arXiv:2304.07193 , year=
DINOv2: Learning Robust Visual Features without Supervision , author =. arXiv preprint arXiv:2304.07193 , year=
-
[57]
arXiv preprint arXiv:2506.01942 , year=
OD3: Optimization-free Dataset Distillation for Object Detection , author=. arXiv preprint arXiv:2506.01942 , year=
-
[58]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Pruning then reweighting: Towards data-efficient training of diffusion models , author=. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[59]
2024 , booktitle=
Elucidating the Design Space of Dataset Condensation , author=. 2024 , booktitle=
2024
-
[60]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[61]
Findings of the ACL , year =
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models , author =. Findings of the ACL , year =
-
[62]
AISTATS , series =
Guaranteed Non-convex Optimization: Submodular Maximization over Continuous Domains , author =. AISTATS , series =. 2017 , publisher =
2017
-
[63]
Submodularity and curvature: the optimal algorithm , author=
-
[64]
Submodular set functions, matroids and the greedy algorithm: Tight worst-case bounds and some generalizations of the Rado–Edmonds theorem , journal =
Michele Conforti and G. Submodular set functions, matroids and the greedy algorithm: Tight worst-case bounds and some generalizations of the Rado–Edmonds theorem , journal =. 1984 , issn =
1984
-
[65]
Iyer and Stefanie Jegelka and Jeff A
Rishabh K. Iyer and Stefanie Jegelka and Jeff A. Bilmes , title =. Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[66]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[67]
International Joint Conference on Artificial Intelligence (IJCAI) , year=
A Survey on Dataset Distillation: Approaches, Applications and Future Directions , author=. International Joint Conference on Artificial Intelligence (IJCAI) , year=
-
[68]
arXiv preprint arXiv:1811.10959 , year=
Dataset distillation , author=. arXiv preprint arXiv:1811.10959 , year=
-
[69]
Transactions on Machine Learning Research (TMLR) , year=
Data Distillation: A Survey , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[70]
Conference on Neural Information Processing Systems (NeurIPS) , year=
Hyperbolic Dataset Distillation , author=. Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[71]
International Conference on Learning Representations (ICLR) , year=
Coverage-centric Coreset Selection for High Pruning Rates , author=. International Conference on Learning Representations (ICLR) , year=
-
[72]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Efficient dataset distillation via minimax diffusion , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[73]
arXiv preprint arXiv:2403.07142 , year =
One Category One Prompt: Dataset Distillation using Diffusion Models , author =. arXiv preprint arXiv:2403.07142 , year =
-
[74]
Su, Duo and Hou, Junjie and Gao, Weizhi and Tian, Yingjie and Tang, Bowen , booktitle =. D\^
-
[75]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Spanning Training Progress: Temporal Dual-Depth Scoring (TDDS) for Enhanced Dataset Pruning , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[76]
International Conference on Machine Learning (ICML) , pages =
Wasserstein generative adversarial networks , author =. International Conference on Machine Learning (ICML) , pages =
-
[77]
Conference on Neural Information Processing Systems (NeurIPS) , volume =
Improved training of wasserstein gans , author =. Conference on Neural Information Processing Systems (NeurIPS) , volume =
-
[78]
Physical Review E , volume =
Renormalization group flow, optimal transport, and diffusion-based generative model , author =. Physical Review E , volume =
-
[79]
Conference on Neural Information Processing Systems (NeurIPS) , year=
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective , author=. Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[80]
Cui, Jiacheng and Bi, Xinyue and Luo, Yaxin and Zhao, Xiaohan and Liu, Jiacheng and Shen, Zhiqiang , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.