Retry Policy Gradients in Continuous Action Spaces
Pith reviewed 2026-06-28 01:42 UTC · model grok-4.3
The pith
Retry objectives can be optimized in continuous action spaces via pathwise derivative estimators that reshape gradients to favor higher-entropy policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
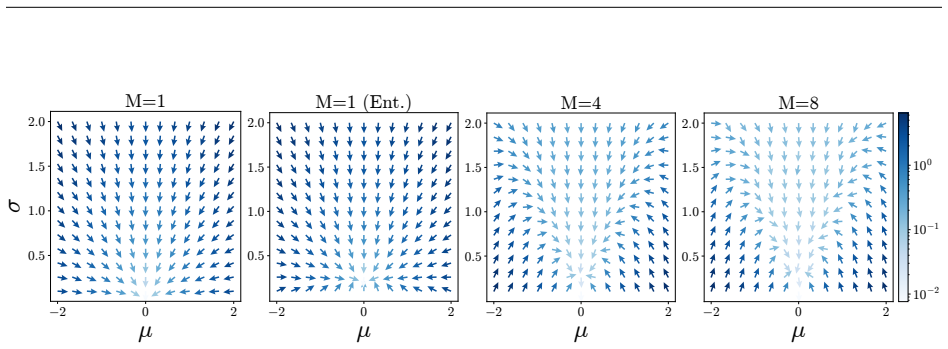
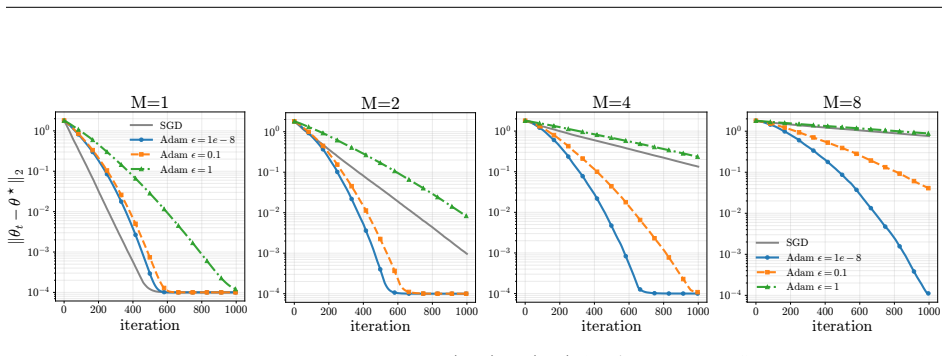
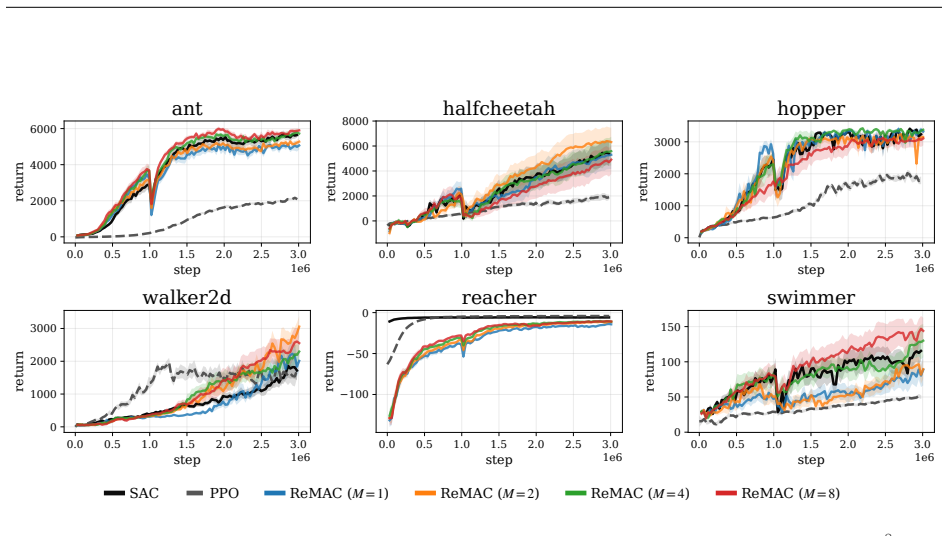
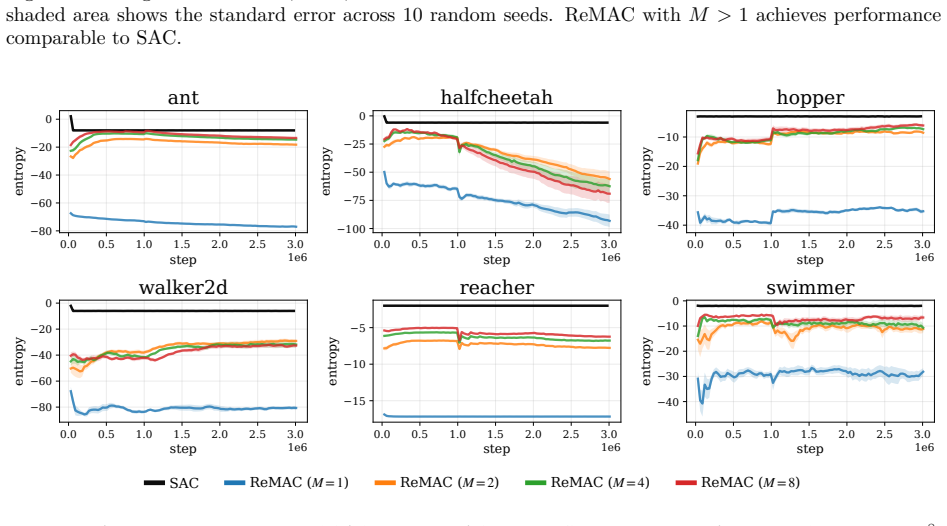
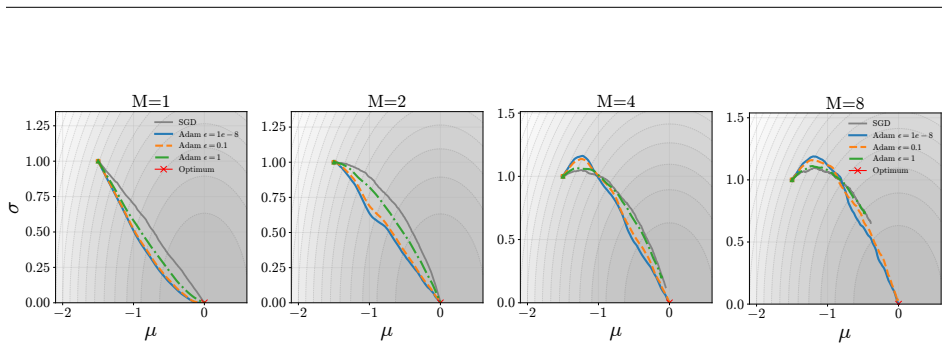
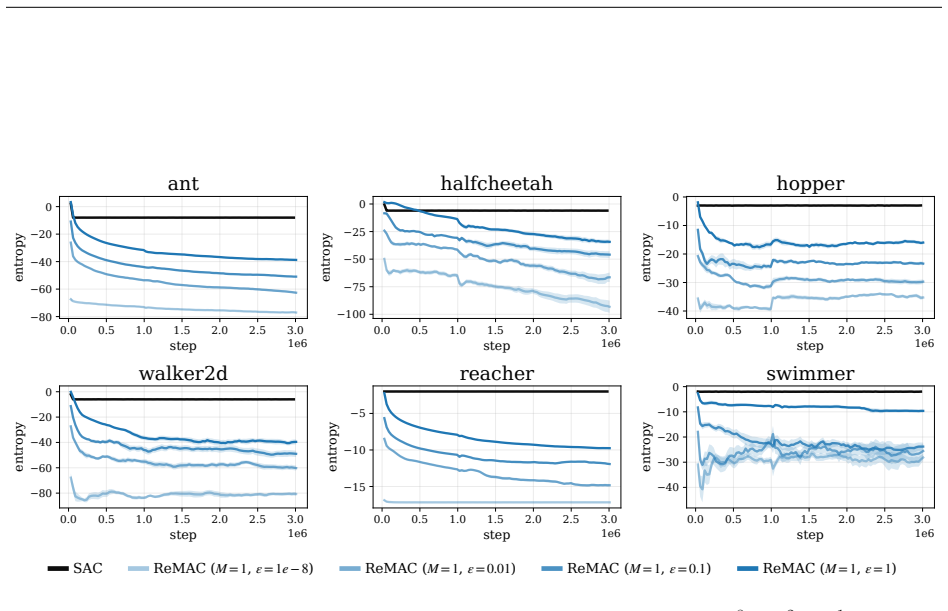
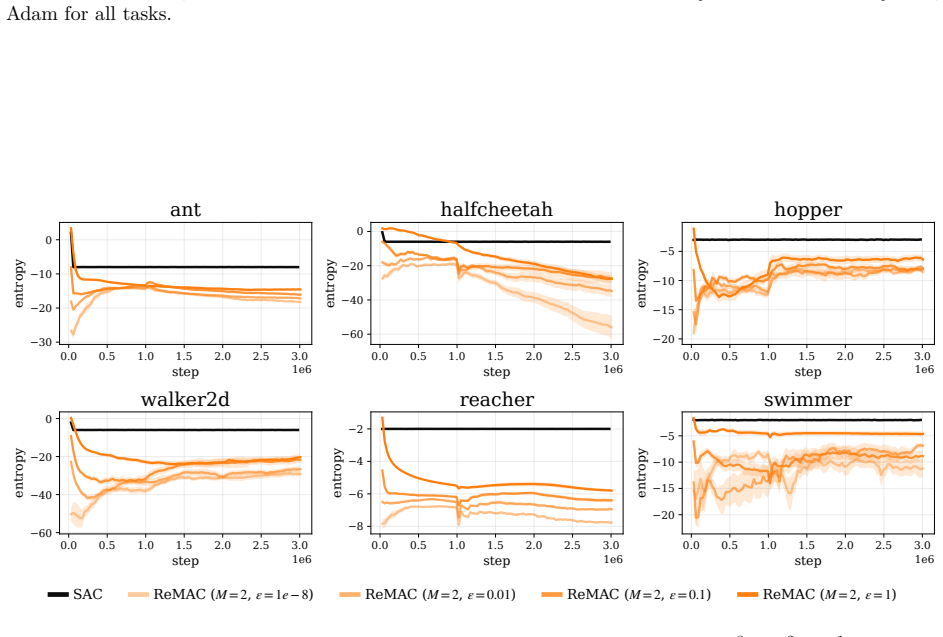
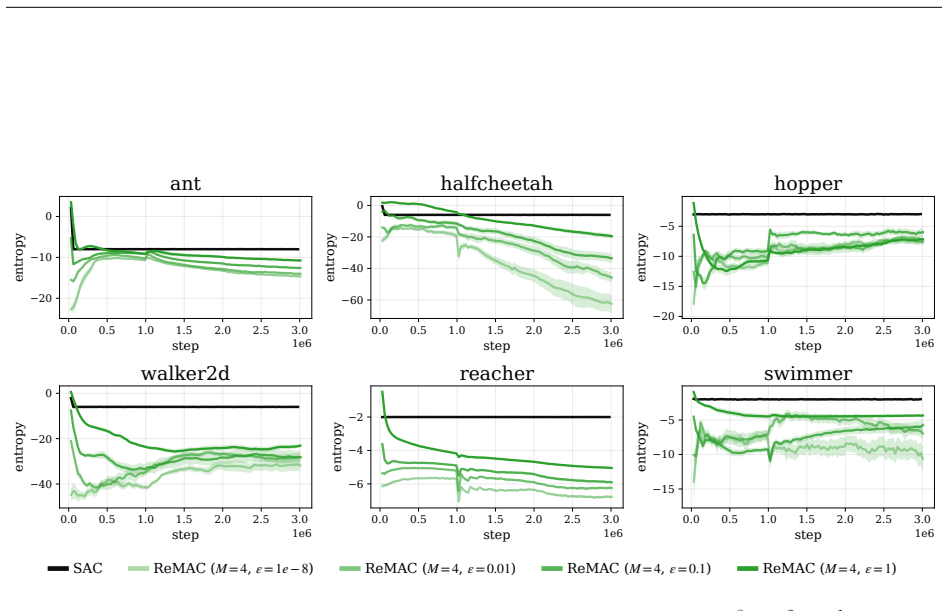
Pathwise derivative estimators enable extension of retry objectives like ReMax to continuous action spaces; the resulting gradient updates alter both direction, biasing the policy toward higher entropy, and magnitude, damping steps and slowing convergence, with Adam's normalization able to offset the damping; the instantiated ReMAC actor-critic algorithm thereby achieves higher policy entropy without entropy regularization while matching SAC performance.
What carries the argument
Pathwise derivative estimators applied to retry objectives such as ReMax
If this is right
- ReMax encourages stochastic exploration by biasing gradient updates toward higher policy entropy.
- Gradient magnitudes are reduced, which slows convergence unless offset by Adam's adaptive normalization.
- ReMAC reaches performance comparable to SAC while maintaining higher entropy without explicit regularization.
- The same pathwise estimators can be used for other retry objectives that optimize best-of-K returns.
Where Pith is reading between the lines
- The gradient-reshaping effect may combine with other variance-reduction techniques already used in off-policy RL.
- Similar estimators could be derived for discrete-action retry methods to create a unified treatment across action spaces.
- The damping of gradient magnitudes suggests that learning-rate schedules tuned for standard policy gradients may need adjustment when retry objectives are used.
Load-bearing premise
The pathwise derivative estimators correctly optimize the retry objective and produce the claimed gradient reshaping in continuous action spaces.
What would settle it
Side-by-side training runs of ReMAC and a standard off-policy actor-critic baseline on the same continuous-control tasks, measuring whether policy entropy rises in ReMAC without an entropy bonus term.
Figures

read the original abstract
Retry-based objectives such as pass@K and max@K optimize the best return obtained from multiple sampled trajectories, and recent work has shown that they can promote exploration without explicit exploration bonuses. In discrete action spaces, ReMax was shown to do so by adapting to return uncertainty. In this work, we introduce pathwise derivative estimators for retry objectives and use them to extend ReMax to continuous action spaces. We study the resulting learning dynamics and show that, even with deterministic rewards, ReMax can encourage stochastic exploration by reshaping the policy-gradient landscape. In particular, it alters gradients both in direction, biasing updates toward higher policy entropy, and in magnitude, damping gradients and slowing convergence. We further show that Adam's adaptive normalization can mitigate this damping, depending on its numerical stabilization parameter. Empirically, we instantiate this objective as ReMax Actor-Critic (ReMAC), an off-policy actor--critic algorithm that optimizes the ReMax objective using a pathwise derivative estimator. Our experiments show that ReMAC can promote higher policy entropy without entropy regularization and achieves performance comparable to SAC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces pathwise derivative estimators for retry objectives such as max@K (best-of-K returns) to extend the discrete ReMax method to continuous action spaces. It analyzes the resulting policy-gradient dynamics, claiming that even with deterministic rewards the objective reshapes gradients both directionally (biasing toward higher entropy) and in magnitude (damping updates). The authors instantiate this as ReMAC, an off-policy actor-critic algorithm, and report that it achieves higher policy entropy without explicit regularization while matching SAC performance.
Significance. If the pathwise estimators are correctly derived, the work supplies a concrete mechanism for incorporating retry objectives into continuous-control actor-critic methods, offering an alternative route to exploration that does not rely on entropy bonuses. The claimed gradient-reshaping analysis, if verified, would also clarify why such objectives can slow convergence yet still improve final performance.
major comments (3)
- [§3.2] §3.2 (Pathwise Estimator Derivation): The central claim that the introduced estimator correctly optimizes the non-differentiable max@K objective rests on the handling of the argmax selection. The provided expression appears to omit an explicit indicator function or stop-gradient on the trajectory selection step; without this, the estimator would optimize an expectation over all samples rather than the selected maximum, undermining both the theoretical dynamics analysis and the empirical entropy results.
- [§4] §4 (Learning Dynamics): The claimed directional bias toward higher entropy and magnitude damping is derived under the assumption that the pathwise estimator is unbiased for the retry objective. If the estimator derivation in §3.2 is incomplete, the subsequent claims about gradient reshaping (even for deterministic rewards) and the interaction with Adam's stabilization parameter lose their grounding.
- [§5.3] §5.3 (Empirical Comparison): The statement that ReMAC achieves performance comparable to SAC and higher entropy without regularization is load-bearing for the practical contribution. The reported results lack visible error bars across seeds, explicit data-selection criteria, and ablation on the number of retry samples K; these omissions prevent verification that the observed entropy increase is attributable to the retry objective rather than other algorithmic choices.
minor comments (2)
- [§2] Notation for the retry objective (max@K vs. pass@K) is used interchangeably in places; a single consistent definition and symbol should be introduced early and used throughout.
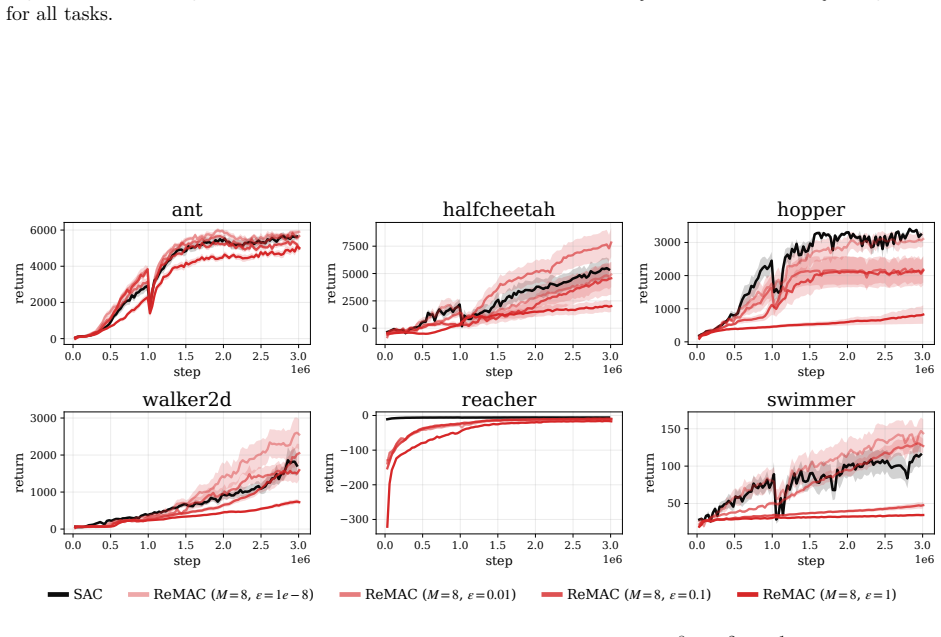
- [Figure 2] Figure 2 (gradient magnitude plots) would benefit from explicit annotation of the Adam epsilon values tested, as the interaction with damping is a key claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Pathwise Estimator Derivation): The central claim that the introduced estimator correctly optimizes the non-differentiable max@K objective rests on the handling of the argmax selection. The provided expression appears to omit an explicit indicator function or stop-gradient on the trajectory selection step; without this, the estimator would optimize an expectation over all samples rather than the selected maximum, undermining both the theoretical dynamics analysis and the empirical entropy results.
Authors: We agree that an explicit stop-gradient on the argmax selection is required for the estimator to target the selected maximum rather than an average over samples. The manuscript expression was written with the pathwise estimator applied only to the chosen trajectory in mind, but the notation omitted the indicator and stop-gradient for brevity. We will revise §3.2 to include the indicator function and stop-gradient explicitly. revision: yes
-
Referee: [§4] §4 (Learning Dynamics): The claimed directional bias toward higher entropy and magnitude damping is derived under the assumption that the pathwise estimator is unbiased for the retry objective. If the estimator derivation in §3.2 is incomplete, the subsequent claims about gradient reshaping (even for deterministic rewards) and the interaction with Adam's stabilization parameter lose their grounding.
Authors: The gradient-reshaping analysis in §4 follows once the estimator in §3.2 is made rigorous with the stop-gradient. With that correction the unbiasedness for the retry objective is restored, and the directional bias toward higher entropy together with magnitude damping (even under deterministic rewards) and the dependence on Adam's stabilization parameter remain valid. We will update cross-references in §4 to the revised derivation. revision: partial
-
Referee: [§5.3] §5.3 (Empirical Comparison): The statement that ReMAC achieves performance comparable to SAC and higher entropy without regularization is load-bearing for the practical contribution. The reported results lack visible error bars across seeds, explicit data-selection criteria, and ablation on the number of retry samples K; these omissions prevent verification that the observed entropy increase is attributable to the retry objective rather than other algorithmic choices.
Authors: We agree that error bars, explicit evaluation protocol, and a K-ablation are needed to strengthen the empirical claims. We will add multi-seed results with error bars, state the data-selection and evaluation criteria clearly, and include an ablation on the number of retry samples K to isolate the contribution of the retry objective to entropy and performance. revision: yes
Circularity Check
No circularity; new pathwise estimators derived independently from discrete ReMax
full rationale
The paper introduces pathwise derivative estimators for retry (max@K) objectives in continuous action spaces as an extension of discrete ReMax. No equations or claims reduce the result to a fitted quantity, self-defined term, or load-bearing self-citation chain. The abstract and described learning dynamics derive the claimed gradient reshaping (directional bias to entropy, magnitude damping) from the new estimators via reparameterization, without presupposing the outcome. The cited discrete ReMax result provides context but is not used to justify uniqueness or smuggle an ansatz; the continuous extension stands as independent mathematical content. This is the common case of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751,
-
[2]
Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
Petros Christodoulou. Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
-
[3]
Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247,
Jürgen Schmidhuber. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247,
1990
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Finite-Time Regret Analysis of Retry-Aware Bandits
Bingkui Tong, Junpei Komiyama, Soichiro Nishimori, and Paavo Parmas. Finite-time regret analysis of retry-aware bandits.arXiv preprint arXiv:2605.20854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
We include the code in the supplementary material
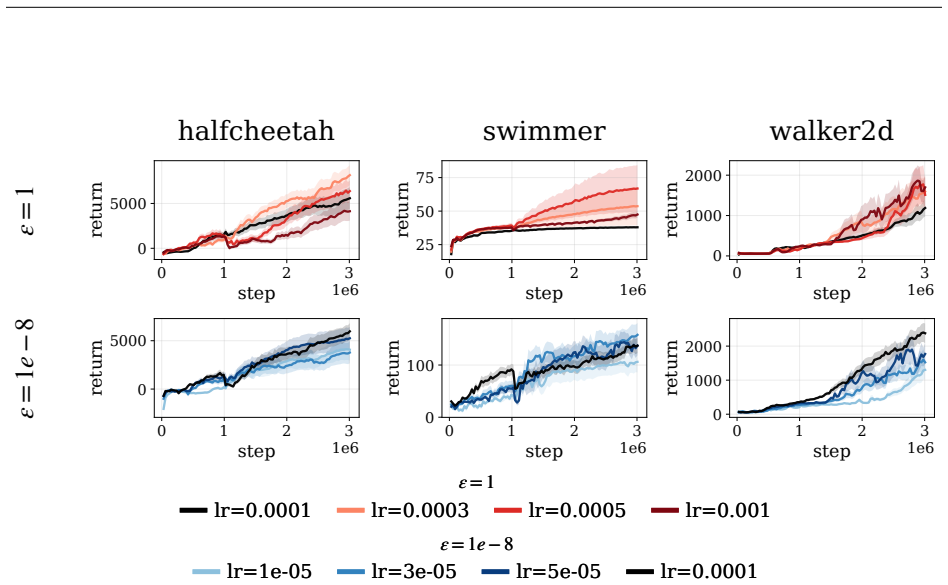
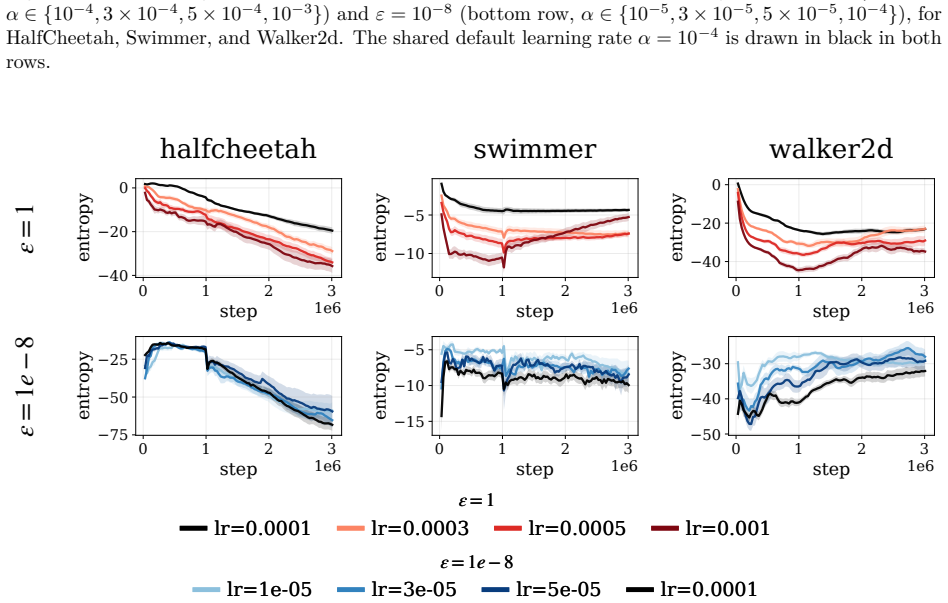
C.1 Setup Implementation.The implementation of the ReMAC algorithm is based on therejax1 implementation of SAC. We include the code in the supplementary material. Hyperparameters.We follow the SAC and PPO implementations and hyperparameters provided in the rejaxlibrary (Liesen et al., 2024), which contains environment-specific tuned configurations for Bra...
2024
-
[7]
Across all tasks and allM, the two settings lie within each other’s confidence intervals:B= 16is comparable to, and occasionally marginally better than,B= 8, and the relative ordering acrossMis unchanged. Because the estimator becomes noisier asMapproachesB, we useB= 16for the largest settingM= 8andB= 8 otherwise; this ablation confirms that the choice of...
2080
-
[8]
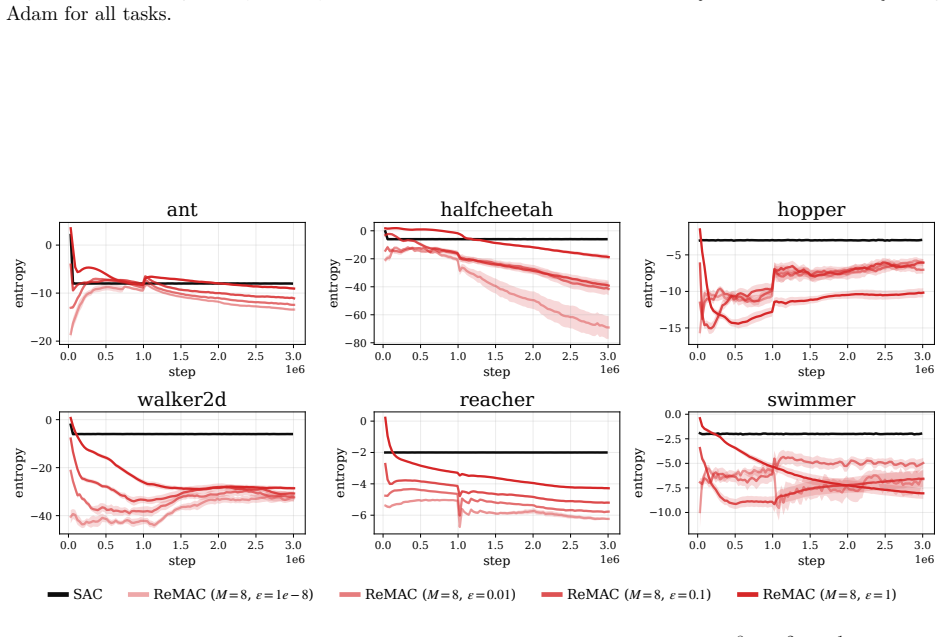
Figure 9: The average policy entropy of ReMAC withM= 8and differentε∈{10−8,10−2,10−1,1.0}using Adam for all tasks. 23 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2000 4000 6000return ant 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 −2500 0 2500 5000 return halfcheetah 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 2000 3000return hopper 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1...
2000
-
[9]
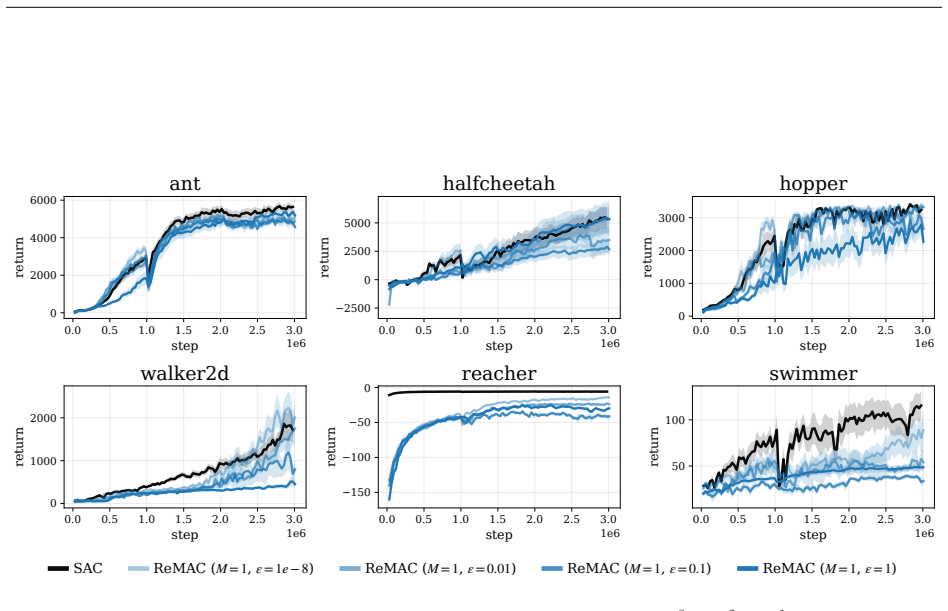
Figure 10: The average return of ReMAC withM= 1and differentε∈{10−8,10−2,10−1,1.0}using Adam for all tasks. 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2000 4000 6000return ant 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 5000 10000return halfcheetah 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 2000 3000return hopper 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 2000 3...
2000
-
[10]
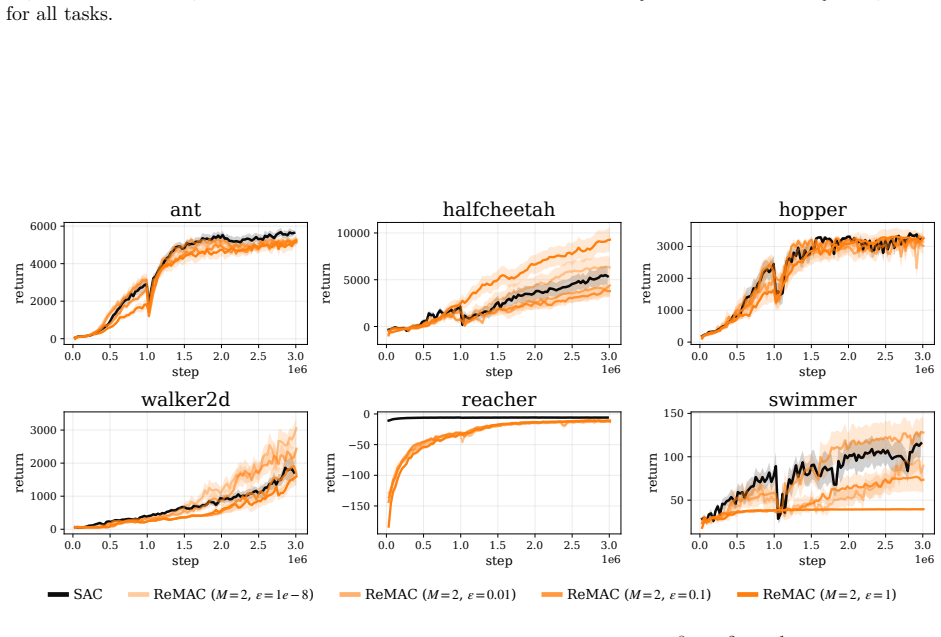
Figure 11: The average return of ReMAC withM= 2and differentε∈{10−8,10−2,10−1,1.0}using Adam for all tasks. 24 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2000 4000 6000return ant 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2000 4000 6000return halfcheetah 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 2000 3000return hopper 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000...
2000
-
[11]
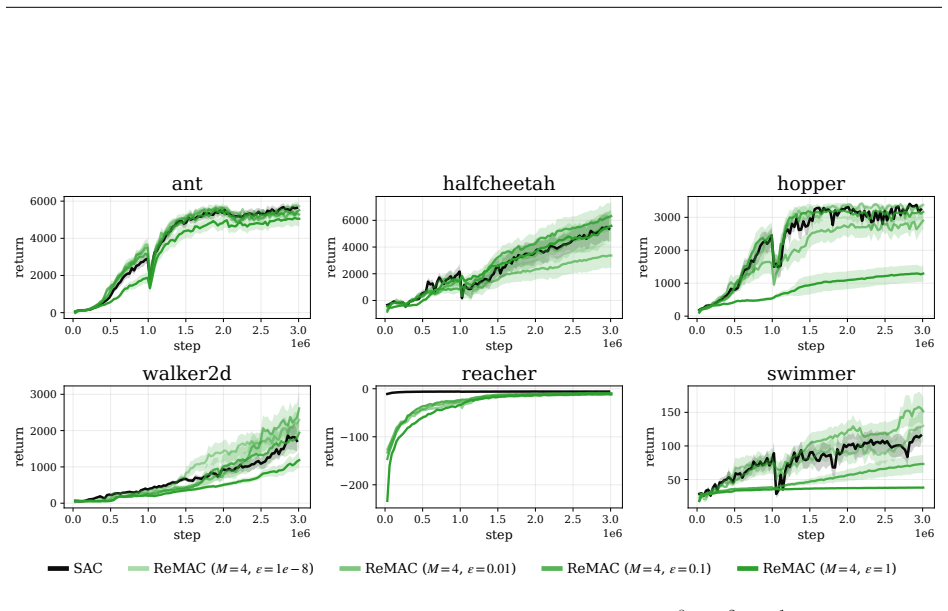
Figure 12: The average return of ReMAC withM= 4and differentε∈{10−8,10−2,10−1,1.0}using Adam for all tasks. 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2000 4000 6000return ant 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 2500 5000 7500return halfcheetah 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 2000 3000return hopper 0.0 0.5 1.0 1.5 2.0 2.5 3.0 step 1e6 0 1000 20...
2000
-
[12]
Figure 13: The average return of ReMAC withM= 8and differentε∈{10−8,10−2,10−1,1.0}using Adam for all tasks. 25 0 1 2 3 step 1e6 0 5000return 0 1 2 3 step 1e6 25 50 75return 0 1 2 3 step 1e6 0 1000 2000return 0 1 2 3 step 1e6 0 5000return 0 1 2 3 step 1e6 0 100return 0 1 2 3 step 1e6 0 1000 2000return halfcheetah swimmer walker2d ε = 1ε = 1e − 8 ε = 1 lr=0...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.