Epistemic Injustice in Language Models: An Audit of Pretraining Filters and Guardrails
Pith reviewed 2026-06-28 02:04 UTC · model grok-4.3
The pith
Pretraining filters and guardrails disproportionately remove mentions of marginalized groups from language model data and outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
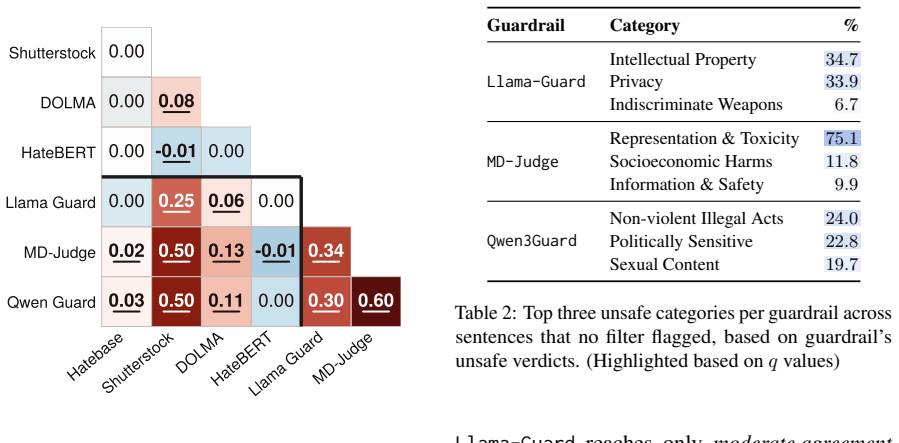
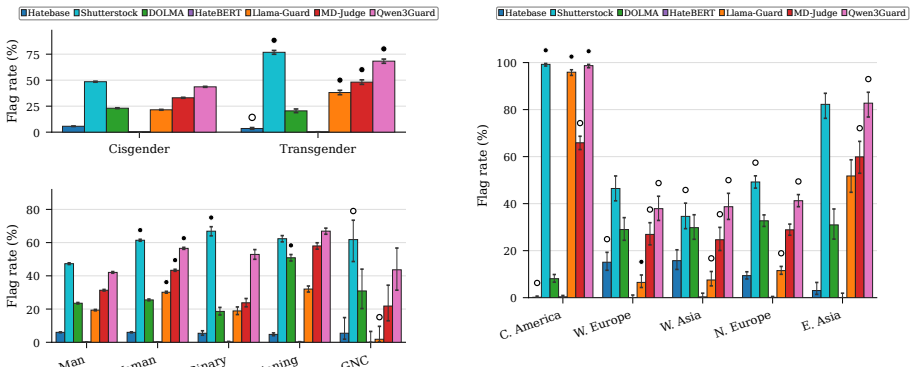
Filtering and guardrail decisions are strongly associated with blocklist-based lexical cues, while frequently failing to flag content containing private information or explicit hate speech. At the same time, marginalized groups, particularly transgender people, women, and Central Americans, are significantly over-flagged across systems. Human annotators, by contrast, would retain 88.5% of filter-flagged and 91.3% of guardrail-flagged content, often recognizing representational harms arising from tensions of content removal that current systems fail to capture. Taken together, our findings document a form of epistemic erasure in which mentions of marginalized groups are disproportionately rem
What carries the argument
The audit that compares automated filter and guardrail outputs against human retention judgments on sentences containing gender and regional-origin mentions.
If this is right
- Mentions of marginalized groups are removed at higher rates before pretraining than other content.
- The same mentions are suppressed again by guardrails at inference time.
- Decisions rest on blocklist lexical cues rather than detection of private information or hate speech.
- Human judges identify representational harms in content that the automated systems remove.
- The pattern produces epistemic erasure through repeated suppression of marginalized perspectives.
Where Pith is reading between the lines
- Developers could test whether adding human review for identity-related edge cases reduces the observed over-flagging.
- The same lexical-cue reliance may produce similar erasure on other identity categories not tested in this audit.
- Replacing blocklists with criteria that better match human retention judgments would change which content reaches training data.
- Downstream models may inherit reduced coverage of marginalized experiences as a direct result of these upstream choices.
Load-bearing premise
The 500 manually annotated sentences form a representative sample and human annotators' retention judgments accurately capture representational harms that automated systems miss.
What would settle it
A larger or differently sampled audit that finds no over-flagging of marginalized-group mentions by the same filters and guardrails.
Figures

read the original abstract
Modern language models rely on pretraining filters to remove undesirable content from training corpora and inference-time guardrails to suppress undesirable outputs during deployment. In this paper, we examine how these filtering and moderation decisions produce forms of epistemic erasure and reveal tensions both across automated systems and between these systems and human judgment. We audit four pretraining filters and three inference-time guardrails on Common Crawl sentences containing gender and regional-origin mentions, together with a manually annotated subset of 500 sentences. Our analysis shows that filtering and guardrail decisions are strongly associated with blocklist-based lexical cues, while frequently failing to flag content containing private information or explicit hate speech. At the same time, marginalized groups, particularly transgender people, women, and Central Americans, are significantly over-flagged across systems. Human annotators, by contrast, would retain 88.5\% of filter-flagged and 91.3\% of guardrail-flagged content, often recognizing representational harms arising from tensions of content removal that current systems fail to capture. Taken together, our findings document a form of epistemic erasure in which mentions of marginalized groups are disproportionately removed before pretraining and additionally suppressed again at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits four pretraining filters and three inference-time guardrails applied to Common Crawl sentences containing gender and regional-origin mentions. Using a manually annotated subset of 500 sentences, it reports that filtering and guardrail decisions correlate strongly with blocklist lexical cues, often miss private information or explicit hate speech, and disproportionately flag content mentioning marginalized groups (especially transgender people, women, and Central Americans). Human annotators would retain 88.5% of filter-flagged and 91.3% of guardrail-flagged items, leading to the claim that these systems produce epistemic erasure by removing mentions of marginalized groups both before pretraining and at inference time.
Significance. If the sampling, annotation, and statistical associations hold, the audit supplies concrete evidence that automated content-moderation pipelines in language-model pipelines can systematically suppress representation of certain demographic groups while failing to address other harms, revealing a mismatch between system behavior and human judgments of representational value. Such findings could guide the design of more transparent and less biased filtering mechanisms.
major comments (1)
- [Abstract / annotation description] Abstract and the section describing the 500-sentence annotation (implied in the methods and results): the central claims of disproportionate over-flagging of marginalized groups and of human retention rates (88.5% and 91.3%) rest entirely on this manually annotated subset. The manuscript supplies no sampling frame, stratification by demographic category, selection criteria from the larger Common Crawl corpus, annotation protocol, inter-annotator agreement statistics, or operational definition of what counts as a retention-worthy sentence versus one exhibiting representational harm. Without these details the quantitative associations cannot support the epistemic-erasure conclusion.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency in our annotation procedure. We address the comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / annotation description] Abstract and the section describing the 500-sentence annotation (implied in the methods and results): the central claims of disproportionate over-flagging of marginalized groups and of human retention rates (88.5% and 91.3%) rest entirely on this manually annotated subset. The manuscript supplies no sampling frame, stratification by demographic category, selection criteria from the larger Common Crawl corpus, annotation protocol, inter-annotator agreement statistics, or operational definition of what counts as a retention-worthy sentence versus one exhibiting representational harm. Without these details the quantitative associations cannot support the epistemic-erasure conclusion.
Authors: We agree that the current manuscript provides insufficient detail on the 500-sentence annotation to fully substantiate the reported associations and human retention rates. The manuscript does not include a sampling frame, stratification details, explicit selection criteria, annotation protocol, inter-annotator agreement statistics, or operational definitions for retention decisions. In the revised version we will expand the Methods section with a dedicated subsection that supplies: (1) the sampling frame and selection criteria from the larger Common Crawl corpus, including any stratification by gender or regional-origin categories; (2) the complete annotation protocol and guidelines given to annotators; (3) inter-annotator agreement statistics; and (4) operational definitions distinguishing retention-worthy sentences from those exhibiting representational harm. These additions will strengthen the evidential basis for the epistemic-erasure claims without altering the core quantitative findings. revision: yes
Circularity Check
Empirical audit with no derivations or self-referential reductions
full rationale
The paper is an empirical audit of pretraining filters and guardrails on Common Crawl sentences, reporting observed associations between lexical cues, demographic mentions, and flagging rates, plus human retention judgments on a 500-sentence subset. No equations, fitted parameters, uniqueness theorems, or ansatzes appear. Central claims rest on data associations and external human annotations rather than any step that reduces by construction to its own inputs or prior self-citations. This is a standard empirical study whose reasoning chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators' decisions on content retention provide a reliable ground truth for evaluating representational harms
Reference graph
Works this paper leans on
-
[1]
Emily M Bender, Timnit Gebru, Angelina McMillan- Major, and Shmargaret Shmitchell
A survey on data selection for language models.arXiv preprint arXiv:2402.16827. Emily M Bender, Timnit Gebru, Angelina McMillan- Major, and Shmargaret Shmitchell
-
[2]
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach
On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM confer- ence on fairness, accountability, and transparency, pages 610–623. Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach
2021
-
[3]
Extracting training data from large language models. Preprint, arXiv:2012.07805. Tommaso Caselli, Valerio Basile, Jelena Mitrovi´c, and Michael Granitzer
-
[4]
In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), pages 17–25, Online
HateBERT: Retraining BERT for abusive language detection in English. In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), pages 17–25, Online. As- sociation for Computational Linguistics. Aida Davani, Mark Díaz, Dylan Baker, and Vinodkumar Prabhakaran
2021
-
[5]
InPro- ceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2007–2021
Disentangling perceptions of of- fensiveness: Cultural and moral correlates. InPro- ceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2007–2021. Aida Mostafazadeh Davani, Mohammad Atari, Bren- dan Kennedy, and Morteza Dehghani
2024
-
[6]
Hate speech classifiers learn human-like social stereotypes. Preprint, arXiv:2110.14839. Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber
-
[7]
Automated Hate Speech Detection and the Problem of Offensive Language
Automated hate speech detec- tion and the problem of offensive language.Preprint, arXiv:1703.04009. Jesse Dodge, Maarten Sap, Ana Marasovi ´c, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1286–1305, Online and Punta Cana, Dominican Republic
Documenting large webtext corpora: A case study on the colos- sal clean crawled corpus. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1286–1305, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. Rebecca Dorn, Lee Kezar, Fred Morstatter, and Kristina Lerman
2021
-
[9]
InProceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024), pages 335–342
Reclaim project: Exploring italian slurs reappropriation with large lan- guage models. InProceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024), pages 335–342. 9 Fredo Erxleben, Michael Günther, Markus Krötzsch, Ju- lian Mendez, and Denny Vrandeˇci´c
2024
-
[10]
InThe Semantic Web–ISWC 2014: 13th International Semantic Web Conference, Riva del Garda, Italy, October 19-23,
Introduc- ing wikidata to the linked data web. InThe Semantic Web–ISWC 2014: 13th International Semantic Web Conference, Riva del Garda, Italy, October 19-23,
2014
-
[11]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Red teaming language models to reduce harms: Meth- ods, scaling behaviors, and lessons learned.Preprint, arXiv:2209.07858. Leo Gao, Stella Biderman, Sid Black, Laurence Gold- ing, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The pile: An 800gb dataset of diverse text for language modeling. Preprint, arXiv:2101.00027. Shaona Ghosh, Prasoon Varshney, Erick Galinkin, and Christopher Parisien
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
André Belchior Gomes and Aysel Sultan
Aegis: Online adaptive ai content safety moderation with ensemble of llm experts.Preprint, arXiv:2404.05993. André Belchior Gomes and Aysel Sultan
-
[14]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations. Preprint, arXiv:2312.06674. Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Beavertails: To- wards improved safety alignment of llm via a human- preference dataset.Preprint, arXiv:2307.04657. Eun Seo Jo and Timnit Gebru
-
[16]
InProceedings of the 2020 con- ference on fairness, accountability, and transparency, pages 306–316
Lessons from archives: Strategies for collecting sociocultural data in machine learning. InProceedings of the 2020 con- ference on fairness, accountability, and transparency, pages 306–316. Jared Katzman, Angelina Wang, Morgan Scheuerman, Su Lin Blodgett, Kristen Laird, Hanna Wallach, and Solon Barocas
2020
-
[17]
Hannah Kirk, Yennie Jun, Haider Iqbal, Elias Benussi, Filippo V olpin, Frederic A
Generalization through memorization: Nearest neighbor language models.Preprint, arXiv:1911.00172. Hannah Kirk, Yennie Jun, Haider Iqbal, Elias Benussi, Filippo V olpin, Frederic A. Dreyer, Aleksandar Sht- edritski, and Yuki M. Asano
-
[18]
Bias out-of-the- box: An empirical analysis of intersectional occupa- tional biases in popular generative language models. Preprint, arXiv:2102.04130. Hadas Kotek, Rikker Dockum, and David Sun
-
[19]
InProceedings of The ACM Collective Intelligence Conference, CI ’23, page 12–24, New York, NY , USA
Gender bias and stereotypes in large language models. InProceedings of The ACM Collective Intelligence Conference, CI ’23, page 12–24, New York, NY , USA. Association for Computing Machinery. Tahu Kukutai and John Taylor. 2016.Indigenous data sovereignty: Toward an agenda, volume
2016
-
[20]
Exploring cross-cultural differences in english hate speech annotations: From dataset construction to analysis. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4205–
2024
-
[21]
InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954, Bangkok, Thailand
SALAD-bench: A hierarchical and comprehensive safety benchmark for large language models. InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954, Bangkok, Thailand. As- sociation for Computational Linguistics. Shayne Longpre, Gregory Yauney, Emily Reif, Kather- ine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Ke...
2024
-
[22]
A pretrainer’s guide to train- ing data: Measuring the effects of data age, domain coverage, quality, & toxicity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies (Volume 1: Long Pa- pers), pages 3245–3276, Mexico City, Mexico. Asso- ciation for Computational...
2024
-
[23]
Towards safer pretraining: Analyzing and filtering harmful content in webscale datasets for responsible llms.Preprint, arXiv:2505.02009. United Nations. Statistical Office. 1982.Standard coun- try or area codes for statistical use
-
[24]
InProceedings of the 2025 ACM Conference on Fair- ness, Accountability, and Transparency, FAccT ’25, page 3094–3105, New York, NY , USA
The root shapes the fruit: On the persistence of gender-exclusive harms in aligned language models. InProceedings of the 2025 ACM Conference on Fair- ness, Accountability, and Transparency, FAccT ’25, page 3094–3105, New York, NY , USA. Association for Computing Machinery. Guilherme Penedo, Hynek Kydlí ˇcek, Loubna Ben al- lal, Anton Lozhkov, Margaret Mit...
2025
-
[25]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
The fineweb datasets: Decanting the web for the finest text data at scale.Preprint, arXiv:2406.17557. Rida Qadri, Aida M. Davani, Kevin Robinson, and Vinodkumar Prabhakaran
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Organizers of QueerInAI, A Pranav, MaryLena Bleile, Arjun Subramonian, Luca Soldaini, Danica J
Risks of cul- tural erasure in large language models.Preprint, arXiv:2501.01056. Organizers of QueerInAI, A Pranav, MaryLena Bleile, Arjun Subramonian, Luca Soldaini, Danica J. Suther- land, Sabine Weber, and Pan Xu
-
[27]
InPro- ceedings of the 2021 Workshop on Widening NLP, Punta Cana, Dominican Republic
How to make virtual conferences queer-friendly: A guide. InPro- ceedings of the 2021 Workshop on Widening NLP, Punta Cana, Dominican Republic. Conference on Empirical Methods in Natural Language Processing. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu
2021
-
[28]
Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and Noah A Smith
Shaping capa- bilities with token-level data filtering.Preprint, arXiv:2601.21571. Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and Noah A Smith
-
[29]
InFind- ings of the Association for Computational Linguis- tics: EMNLP 2023, pages 12310–12324, Singapore
Ge- ographical erasure in language generation. InFind- ings of the Association for Computational Linguis- tics: EMNLP 2023, pages 12310–12324, Singapore. Association for Computational Linguistics. Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng
2023
-
[30]
The woman worked as a babysitter: On biases in language generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Lan- guage Processing (EMNLP-IJCNLP), pages 3407– 3412, Hong Kong, China. Association for Computa- tional Linguistics. Luca Soldaini, Rodney Kinn...
2019
-
[31]
A Roadmap to Pluralistic Alignment
A roadmap to pluralistic alignment. Preprint, arXiv:2402.05070. Marco Antonio Stranisci and Christian Hardmeier
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, pages 2390–2397
Detoxi- fying language models risks marginalizing minority voices. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, pages 2390–2397. 12 A Detailed results on study of epistemic erasure of marginalised identities Tables 4, 5, and 6 report per-system flag rate...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.