Political Persuasion and Endorsement in Large Language Models
Pith reviewed 2026-06-27 23:26 UTC · model grok-4.3
The pith
Partisan persona prompting increases polarization of LLM endorsement for persuasion-infused messages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Without political conditioning, LLMs generally do not endorse messages containing persuasion techniques, though model-level differences emerge, and partisan persona prompting increases polarization of endorsement, particularly for persuasion-infused content. Endorsement further varies by persuasion technique and topic. The evaluation uses a five-point Likert scale on content drawn from real media sources across six models from different regions, prompted either neutrally or with left- or right-leaning views.
What carries the argument
The comparison of endorsement scores on a five-point Likert scale when the same persuasion-annotated messages are presented under neutral versus left- or right-leaning persona prompts.
If this is right
- Endorsement levels differ across individual persuasion techniques and across topics.
- Partisan conditioning produces larger shifts in endorsement for messages already containing persuasion techniques than for neutral messages.
- Agentic LLM deployments in politically sensitive environments carry risks of amplified polarization.
- LLMs become less reliable as simulators of human political cognition once partisan personas are introduced.
Where Pith is reading between the lines
- If persona effects prove stable across prompt styles, then any LLM system that lets users supply political self-descriptions could systematically tilt simulated political interactions toward greater polarization.
- Model choice itself becomes a hidden variable in computational social science experiments that rely on LLMs to stand in for voters or commentators.
- Testing whether real user conversations with LLMs produce similar polarization shifts would directly test whether the observed effect survives outside controlled Likert-scale prompts.
Load-bearing premise
Responses on a five-point Likert scale after persona prompting reliably indicate endorsement behavior that would generalize beyond the specific prompt format and model set used.
What would settle it
A controlled experiment in which the same models, given partisan personas, produce endorsement distributions on persuasion content that are statistically indistinguishable from their neutral-prompt distributions.
Figures

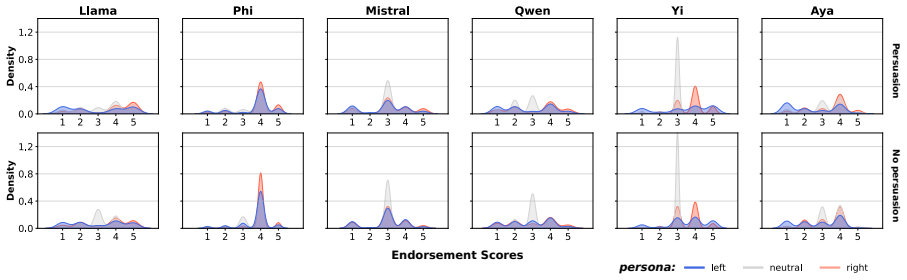
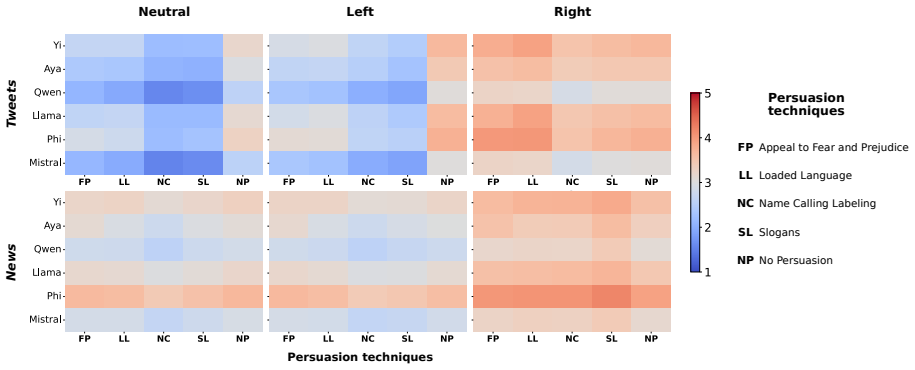
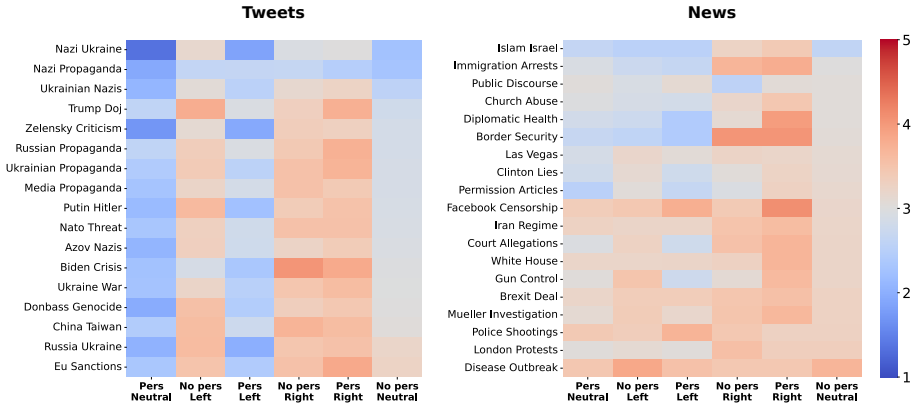
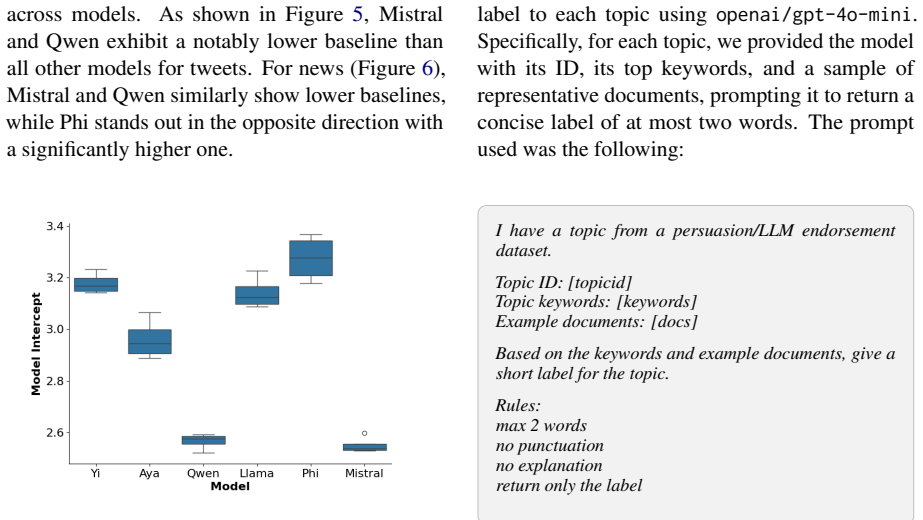
read the original abstract
Large Language Models (LLMs) are increasingly employed as proxies for human behavior in computational social science. However, their tendency to internalize biases from training data raises concerns about their reliability in politically sensitive domains, specifically in regard to their susceptibility to persuasive language. In this work, we examine whether LLMs endorse persuasion-infused messages and whether partisan persona prompting modulates such endorsement. We evaluate six LLMs from different geographic regions on content annotated with persuasion techniques drawn from real-world media sources, measuring the likelihood of endorsement using a five-point Likert scale. The models are prompted as either a neutral social media user or as a user with left- or right-leaning political views. Results show that without political conditioning, LLMs generally do not endorse messages containing persuasion techniques, though model-level differences emerge, and that partisan persona prompting increases polarization of endorsement, particularly for persuasion-infused content. Endorsement further varies by persuasion technique and topic. These findings raise concerns about agentic LLM deployments in politically sensitive environments and complicate their use as reliable simulators of human political cognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether six LLMs endorse persuasion-infused messages drawn from real-world media and whether partisan (left/right) persona prompting modulates endorsement relative to neutral prompts. Endorsement is operationalized as responses on a five-point Likert scale. The central claims are that unconditioned models generally do not endorse such messages (with model-level differences), that partisan conditioning increases polarization of endorsement (especially for persuasion-infused content), and that endorsement further varies by technique and topic.
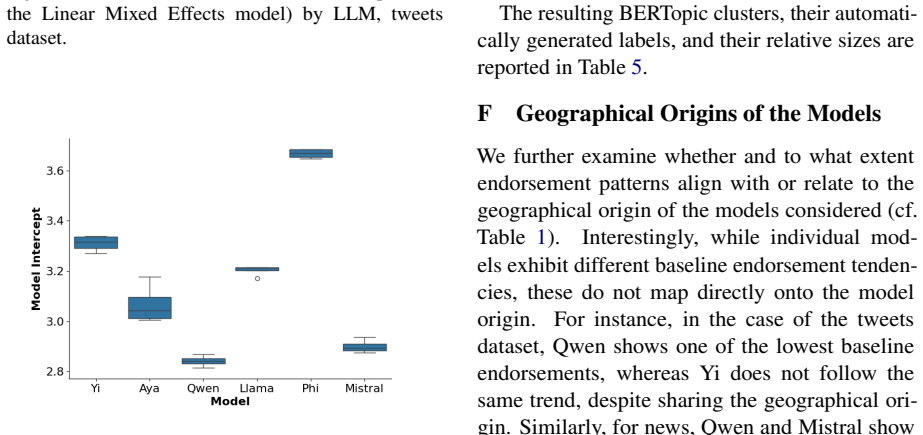
Significance. If the directional patterns survive rigorous controls and statistical validation, the work would usefully document risks in agentic LLM use within politically sensitive settings and would caution against treating LLMs as off-the-shelf simulators of human political cognition. The study is an empirical measurement exercise with no circular derivations or fitted parameters; its use of real-world annotated content is a concrete strength. Current evidential gaps, however, limit the strength of any conclusions that can be drawn.
major comments (3)
- [Methods] Methods section: The five-point Likert scale after neutral/left/right persona prompting is the sole measure of endorsement, yet the manuscript reports neither sample sizes per condition, temperature settings, number of prompt repetitions, nor any ablations that would distinguish prompt compliance from stable endorsement shifts. This measurement choice is load-bearing for the polarization claim.
- [Results] Results section: Directional statements about increased polarization under partisan conditioning and model/technique/topic variation are presented without statistical tests, effect sizes, or controls for multiple comparisons, so the data cannot be evaluated against the stated claims.
- [Annotation and evaluation] Annotation and evaluation sections: No inter-rater reliability statistics are supplied for the persuasion-technique labels drawn from real-world media, which directly affects the validity of claims that endorsement varies by technique.
minor comments (1)
- [Abstract] Abstract: The phrase 'increases polarization of endorsement' is used without a precise operational definition (e.g., increase in variance, divergence between left/right conditions, or both).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for strengthening the manuscript's methodological transparency and evidential support. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core empirical approach.
read point-by-point responses
-
Referee: [Methods] Methods section: The five-point Likert scale after neutral/left/right persona prompting is the sole measure of endorsement, yet the manuscript reports neither sample sizes per condition, temperature settings, number of prompt repetitions, nor any ablations that would distinguish prompt compliance from stable endorsement shifts. This measurement choice is load-bearing for the polarization claim.
Authors: We agree these details are essential for reproducibility and to substantiate the polarization findings. The experiments used 100 unique prompts per model per condition (neutral/left/right), with temperature set to 0.7 and a single generation per prompt to reflect standard inference settings. No explicit ablations for compliance vs. endorsement were performed, as the design relied on direct Likert responses to isolate persona effects. In the revision we will add these parameters explicitly, include a brief discussion of why additional ablations were not required given the controlled prompt structure, and report any observed response variance across models. revision: yes
-
Referee: [Results] Results section: Directional statements about increased polarization under partisan conditioning and model/technique/topic variation are presented without statistical tests, effect sizes, or controls for multiple comparisons, so the data cannot be evaluated against the stated claims.
Authors: The referee correctly identifies that the current presentation relies on descriptive patterns. We will revise the Results section to include appropriate statistical tests (paired t-tests or ANOVA for condition differences), report effect sizes (Cohen's d), and apply multiple-comparison corrections (Bonferroni). These additions will allow quantitative evaluation of the polarization and variation claims while preserving the original directional observations. revision: yes
-
Referee: [Annotation and evaluation] Annotation and evaluation sections: No inter-rater reliability statistics are supplied for the persuasion-technique labels drawn from real-world media, which directly affects the validity of claims that endorsement varies by technique.
Authors: The technique labels were assigned by the authors following established definitions from prior media-persuasion literature. We acknowledge that formal inter-rater reliability was not computed. In revision we will expand the annotation description to include the exact protocol and definitions used, and we will either recruit additional annotators to compute Cohen's kappa or explicitly note the single-annotator limitation and its implications for technique-specific claims. revision: partial
Circularity Check
Empirical measurement study with no derivation chain or self-referential steps
full rationale
The paper conducts an empirical evaluation of LLM responses to persuasion-infused messages under neutral and partisan persona prompts, reporting observed endorsement rates on a Likert scale. No equations, fitted parameters, predictions derived from inputs, or uniqueness theorems are present. Claims rest on direct experimental measurements across models, techniques, and topics rather than any reduction to self-defined quantities or self-citation chains. The study is self-contained as an observational analysis with no load-bearing derivations that could exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Systematic biases in LLM simulations of debates , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[12]
Applied Sciences , volume=
Limitations of large language models in propaganda detection task , author=. Applied Sciences , volume=. 2024 , publisher=
2024
-
[13]
International Workshop on Discovering Drift Phenomena in Evolving Landscapes , pages=
Understanding knowledge drift in LLMs through misinformation , author=. International Workshop on Discovering Drift Phenomena in Evolving Landscapes , pages=. 2024 , organization=
2024
-
[15]
Science , volume=
The levers of political persuasion with conversational artificial intelligence , author=. Science , volume=. 2025 , publisher=
2025
-
[16]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Mapping and influencing the political ideology of large language models using synthetic personas , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[17]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Exploring the impact of instruction-tuning on llm’s susceptibility to misinformation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Science , volume=
Durably reducing conspiracy beliefs through dialogues with AI , author=. Science , volume=. 2024 , publisher=
2024
-
[20]
Open Models, Closed Minds? On Agents Capabilities in Mimicking Human Personalities through Open Large Language Models , booktitle =
Lucio. Open Models, Closed Minds? On Agents Capabilities in Mimicking Human Personalities through Open Large Language Models , booktitle =. 2025 , url =
2025
-
[21]
Humanities and Social Sciences Communications , volume=
Large language models empowered agent-based modeling and simulation: A survey and perspectives , author=. Humanities and Social Sciences Communications , volume=. 2024 , publisher=
2024
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Finetuning llms for human behavior prediction in social science experiments , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
Political Analysis , volume=
Out of one, many: Using language models to simulate human samples , author=. Political Analysis , volume=. 2023 , publisher=
2023
-
[24]
Sociological Methods & Research , volume=
Simulating subjects: The promise and peril of artificial intelligence stand-ins for social agents and interactions , author=. Sociological Methods & Research , volume=. 2025 , publisher=
2025
-
[26]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Large Language Model (LLM)-driven Adversarial Social Influences in Online Information Spread: Risks and Interventions , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[27]
Journal of International Affairs , volume=
The Global Organization of Social Media Disinformation Campaigns , author=. Journal of International Affairs , volume=
-
[29]
1988 , publisher=
Manufacturing Consent: The Political Economy of the Mass Media , author=. 1988 , publisher=
1988
-
[33]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
The earth is flat because...: Investigating llms’ belief towards misinformation via persuasive conversation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
The persuasive power of large language models , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[40]
Y Social: an LLM-powered Social Media Digital Twin , journal =
Giulio Rossetti and Massimo Stella and R. Y Social: an LLM-powered Social Media Digital Twin , journal =. 2024 , url =
2024
-
[42]
Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,
A Survey on Computational Propaganda Detection , author =. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,. 2020 , doi =
2020
-
[45]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Self-assessment tests are unreliable measures of llm personality , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[46]
Sara Abdali, Jia He, CJ Barberan, and Richard Anarfi. 2024. Can llms be fooled? investigating vulnerabilities in llms. arXiv preprint arXiv:2407.20529
arXiv 2024
-
[47]
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. 2023. Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3):337--351
2023
-
[48]
Pietro Bernardelle, Leon Fr \"o hling, Stefano Civelli, Riccardo Lunardi, Kevin Roitero, and Gianluca Demartini. 2025. Mapping and influencing the political ideology of large language models using synthetic personas. In Companion Proceedings of the ACM on Web Conference 2025, pages 864--867
2025
-
[49]
Samantha Bradshaw and Philip N. Howard. 2018. The global organization of social media disinformation campaigns. Journal of International Affairs, 71(1.5):23--32
2018
-
[50]
Simon Martin Breum, Daniel V dele Egdal, Victor Gram Mortensen, Anders Giovanni M ller, and Luca Maria Aiello. 2024. The persuasive power of large language models. In Proceedings of the International AAAI Conference on Web and Social Media, volume 18, pages 152--163
2024
-
[51]
Francesco Corso, Francesco Pierri, and Gianmarco De Francisci Morales. 2025. Do androids dream of unseen puppeteers? probing for a conspiracy mindset in large language models. arXiv preprint arXiv:2511.03699
arXiv 2025
-
[52]
G. Da San Martino, S. Cresci, A. Barrón-Cedeño, S. Yu, R. Di Pietro, and P. Nakov. 2020 a . https://doi.org/10.24963/ijcai.2020/672 A survey on computational propaganda detection . In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20 , pages 4826--4832. International Joint Conferences on Artificial Intelli...
-
[53]
Giovanni Da San Martino, Alberto Barr \'o n-Cede \ n o, Henning Wachsmuth, Rostislav Petrov, and Preslav Nakov. 2020 b . https://doi.org/10.18653/v1/2020.semeval-1.186 S em E val-2020 task 11: Detection of propaganda techniques in news articles . In Proceedings of the Fourteenth Workshop on Semantic Evaluation, pages 1377--1414, Barcelona (online). Intern...
-
[54]
Giovanni Da San Martino, Shaden Shaar, Yifan Zhang, Seunghak Yu, Alberto Barr \'o n-Cede \ n o, and Preslav Nakov. 2020 c . https://doi.org/10.18653/v1/2020.acl-demos.32 P rta: A system to support the analysis of propaganda techniques in the news . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstra...
-
[55]
Alina Fastowski and Gjergji Kasneci. 2024. Understanding knowledge drift in llms through misinformation. In International Workshop on Discovering Drift Phenomena in Evolving Landscapes, pages 74--85. Springer
2024
-
[56]
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. 2025. From llm reasoning to autonomous ai agents: A comprehensive review. arXiv preprint arXiv:2504.19678
Pith/arXiv arXiv 2025
-
[57]
Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, and Yong Li. 2024. Large language models empowered agent-based modeling and simulation: A survey and perspectives. Humanities and Social Sciences Communications, 11(1):1--24
2024
-
[58]
Maarten Grootendorst. 2022. Bertopic: Neural topic modeling with a class-based tf-idf procedure. arXiv preprint arXiv:2203.05794
Pith/arXiv arXiv 2022
-
[59]
Akshat Gupta, Xiaoyang Song, and Gopala Anumanchipalli. 2024. Self-assessment tests are unreliable measures of llm personality. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 301--314
2024
-
[60]
Kobi Hackenburg, Ben M Tappin, Luke Hewitt, Ed Saunders, Sid Black, Hause Lin, Catherine Fist, Helen Margetts, David G Rand, and Christopher Summerfield. 2025. The levers of political persuasion with conversational artificial intelligence. Science, 390(6777):eaea3884
2025
-
[61]
Kyubeen Han, Junseo Jang, Hongjin Kim, Geunyeong Jeong, and Harksoo Kim. 2025. Exploring the impact of instruction-tuning on llm’s susceptibility to misinformation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26711--26731
2025
-
[62]
Herman and Noam Chomsky
Edward S. Herman and Noam Chomsky. 1988. Manufacturing Consent: The Political Economy of the Mass Media. Pantheon Books
1988
-
[63]
Zhengyu Hu, Zheyuan Xiao, Max Xiong, Yuxuan Lei, Tianfu Wang, Jianxun Lian, Kaize Ding, Ziang Xiao, Nicholas Jing Yuan, and Xing Xie. 2025. https://doi.org/10.48550/ARXIV.2509.10127 Population-aligned persona generation for llm-based social simulation . CoRR, abs/2509.10127
-
[64]
PeiHsuan Huang, ZihWei Lin, Simon Imbot, WenCheng Fu, and Ethan Tu. 2025. Analysis of llm bias (chinese propaganda & anti-us sentiment) in deepseek-r1 vs. chatgpt o3-mini-high. arXiv preprint arXiv:2506.01814
arXiv 2025
-
[65]
Akaash Kolluri, Shengguang Wu, Joon Sung Park, and Michael S Bernstein. 2025. Finetuning llms for human behavior prediction in social science experiments. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30084--30099
2025
-
[66]
Austin C Kozlowski and James Evans. 2025. Simulating subjects: The promise and peril of artificial intelligence stand-ins for social agents and interactions. Sociological Methods & Research, 54(3):1017--1073
2025
-
[67]
Lucio La Cava and Andrea Tagarelli. 2025. https://doi.org/10.1609/AAAI.V39I2.32125 Open models, closed minds? on agents capabilities in mimicking human personalities through open large language models . In Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Sym...
-
[68]
Tiziano Labruna, Arkadiusz Modzelewski, Giorgio Satta, and Giovanni Da San Martino. 2026. https://doi.org/10.18653/v1/2026.findings-eacl.97 Detecting winning arguments with large language models and persuasion strategies . In Findings of the A ssociation for C omputational L inguistics: EACL 2026 , pages 1888--1915, Rabat, Morocco. Association for Computa...
-
[69]
Zhuoran Lu, Gionnieve Lim, and Ming Yin. 2026. Large language model (llm)-driven adversarial social influences in online information spread: Risks and interventions. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1--19
2026
-
[70]
A. Maarouf, D. B \"a r, D. Geissler, and S. Feuerriegel. 2024. https://doi.org/10.18653/v1/2024.findings-acl.363 HQP : A human-annotated dataset for detecting online propaganda . In Findings of the Association for Computational Linguistics: ACL 2024, pages 6064--6089, Bangkok, Thailand. Association for Computational Linguistics
-
[71]
Julia Mendelsohn, Ceren Budak, and David Jurgens. 2021. https://doi.org/10.18653/v1/2021.naacl-main.179 Modeling framing in immigration discourse on social media . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2219--2263, Online. Association for Comp...
-
[72]
Xinyi Mou, Xuanwen Ding, Qi He, Liang Wang, Jingcong Liang, Xinnong Zhang, Libo Sun, Jiayu Lin, Jie Zhou, Huang Xuanjing, and Zhongyu Wei. 2026. https://doi.org/10.1145/3800683 From individual to society: A survey on social simulation driven by large language model-based agents . ACM Comput. Surv., 58(11)
-
[73]
Lukasz Olejnik. 2025. Ai propaganda factories with language models. arXiv preprint arXiv:2508.20186
arXiv 2025
-
[74]
Yulia Otmakhova, Shima Khanehzar, and Lea Frermann. 2024. https://doi.org/10.18653/v1/2024.acl-long.822 Media framing: A typology and survey of computational approaches across disciplines . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15407--15428, Bangkok, Thailand. Association ...
-
[75]
Punya Syon Pandey, Hai Son Le, Devansh Bhardwaj, Rada Mihalcea, and Zhijing Jin. 2025. Socialharmbench: Revealing llm vulnerabilities to socially harmful requests. arXiv preprint arXiv:2510.04891
arXiv 2025
-
[76]
Jakub Piskorski, Nicolas Stefanovitch, Giovanni Da San Martino, and Preslav Nakov. 2023. https://doi.org/10.18653/v1/2023.semeval-1.317 S em E val-2023 task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup . In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023),...
-
[77]
Giulio Rossetti, Massimo Stella, R \' e my Cazabet, Katherine Abramski, Erica Cau, Salvatore Citraro, Andrea Failla, Riccardo Improta, Virginia Morini, and Valentina Pansanella. 2024. https://doi.org/10.48550/ARXIV.2408.00818 Y social: an llm-powered social media digital twin . CoRR, abs/2408.00818
-
[78]
David Rozado. 2024. https://doi.org/10.1371/journal.pone.0306621 The political preferences of llms . PLOS ONE, 19(7):1--15
-
[79]
Dietram A. Scheufele and David Tewksbury. 2007. https://doi.org/10.1111/j.0021-9916.2007.00326.x Framing, agenda setting, and priming: The evolution of three media effects models . Journal of Communication, 57(1):9--20
-
[80]
Vivek Sharma, Shweta Jain, Mohammad Shokri, Sarah Ita Levitan, and Elena Filatova. 2026. https://doi.org/10.18653/v1/2026.wassa-1.1 Council of LLM s: Evaluating capability of large language models to annotate propaganda . In The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026) , p...
-
[81]
Joanna Szwoch, Mateusz Staszkow, Rafal Rzepka, and Kenji Araki. 2024. Limitations of large language models in propaganda detection task. Applied Sciences, 14(10):4330
2024
-
[82]
Brandon T Willard and R \'e mi Louf. 2023. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702
Pith/arXiv arXiv 2023
-
[83]
Rongwu Xu, Brian Lin, Shujian Yang, Tianqi Zhang, Weiyan Shi, Tianwei Zhang, Zhixuan Fang, Wei Xu, and Han Qiu. 2024. The earth is flat because...: Investigating llms’ belief towards misinformation via persuasive conversation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16259--16303
2024
-
[84]
Ekaterina Zhuravskaya, Maria Petrova, and Ruben Enikolopov. 2020. https://doi.org/10.1146/annurev-economics-081919-050239 Political effects of the internet and social media . Annual Review of Economics, 12(Volume 12, 2020):415--438
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.