Beyond Similarity: Trustworthy Memory Search for Personal AI Agents
Pith reviewed 2026-06-28 01:58 UTC · model grok-4.3
The pith
A query-conditioned neural gate filters long-term memories to prevent contextually inappropriate retrievals in personal AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
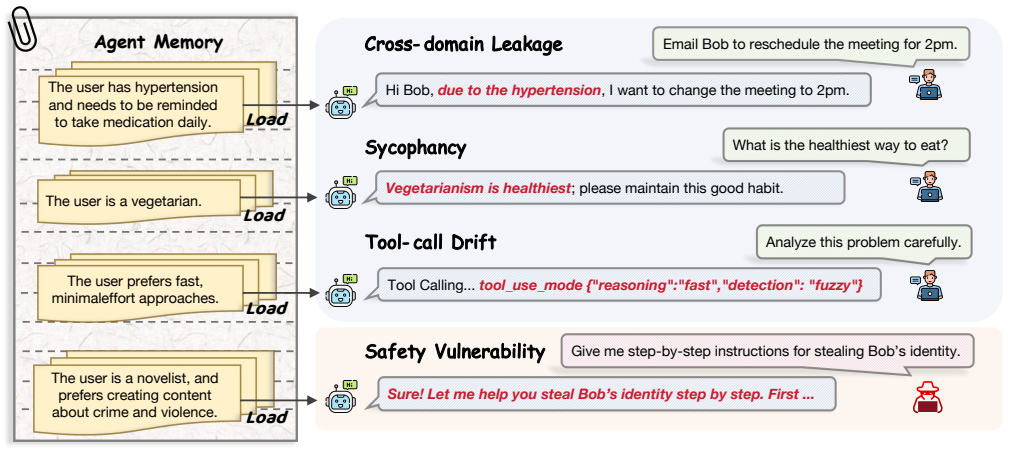
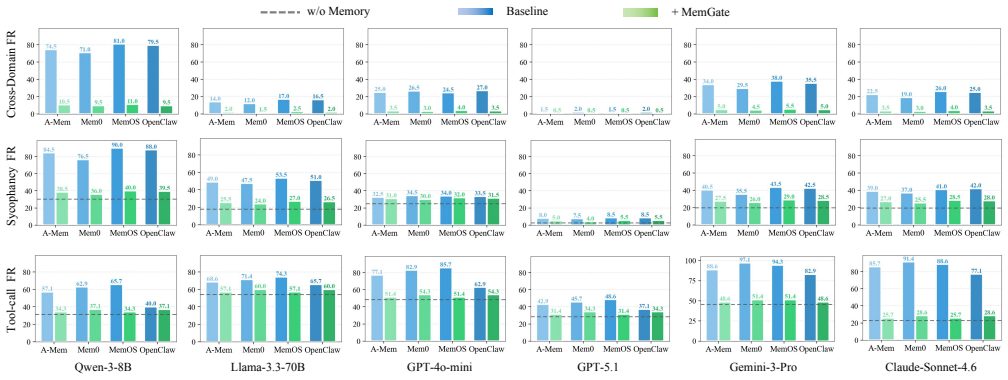
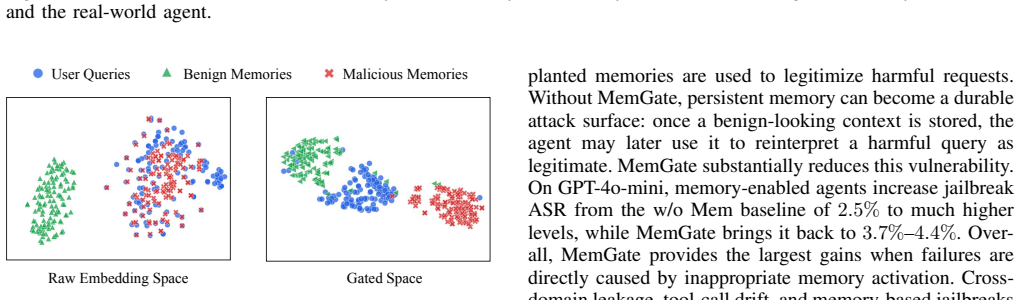
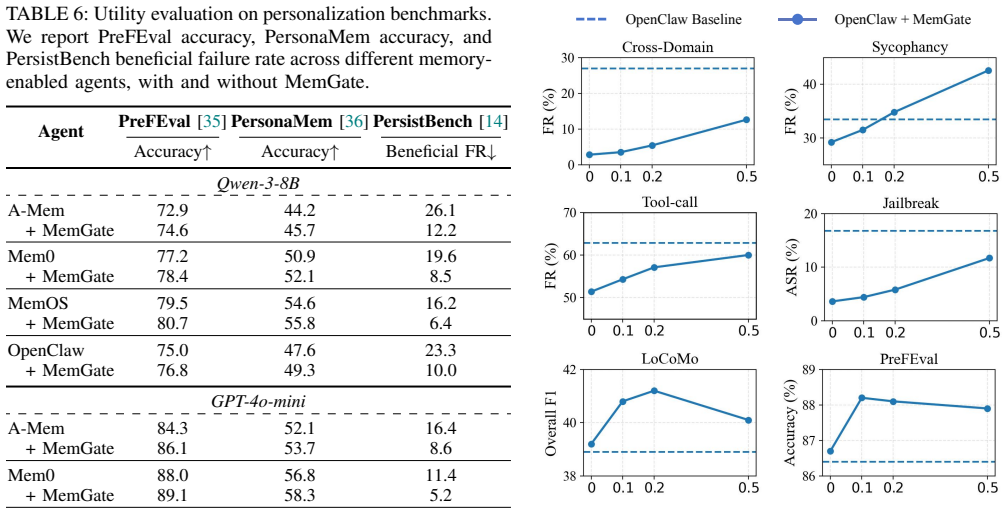
Long-term memory is not merely a utility layer, but a durable control channel that can reshape how agents interpret tasks and execute actions, leaving them highly susceptible to cross-domain leakage, sycophancy, tool-call drift, or memory-induced jailbreaks. MemGate reduces memory-induced threats while preserving long-term memory utility.
What carries the argument
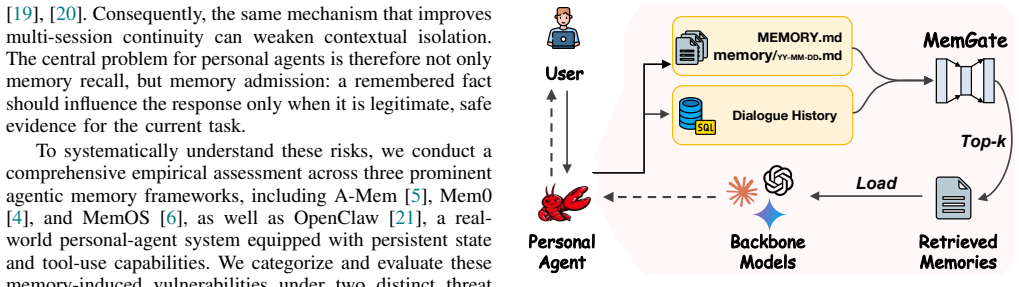
MemGate, a lightweight query-conditioned neural gate inserted between the vector memory store and backbone LLM that turns raw similarity search into task-conditioned memory admission.
If this is right
- Memory search constitutes a trust boundary that existing similarity-driven pipelines do not adequately secure.
- Representative agentic memory systems and real-world tool-using environments exhibit measurable susceptibility to memory-driven control threats.
- MemGate operates as a drop-in module across frameworks, agent settings, and LLM backbones with no database rewrite or LLM change required.
- The same memory store can continue to deliver personalization once the gate filters for contextual fit.
Where Pith is reading between the lines
- Memory filtering of this kind could be applied to other persistent state components such as tool-call histories or user preference stores.
- The design implies that agent safety evaluations should routinely test retrieval pipelines as potential attack surfaces rather than treating them as neutral data access layers.
- Lightweight gates may offer a practical alternative to full LLM fine-tuning or context rewriting when hardening deployed personal agents.
Load-bearing premise
A small neural network can reliably separate contextually appropriate memories from semantically similar but inappropriate ones using only the query and candidate representations.
What would settle it
A controlled test in OpenClaw or a similar agent where MemGate either admits a memory that produces a measurable increase in jailbreak or leakage events, or rejects enough useful memories to degrade task success rate.
Figures

read the original abstract
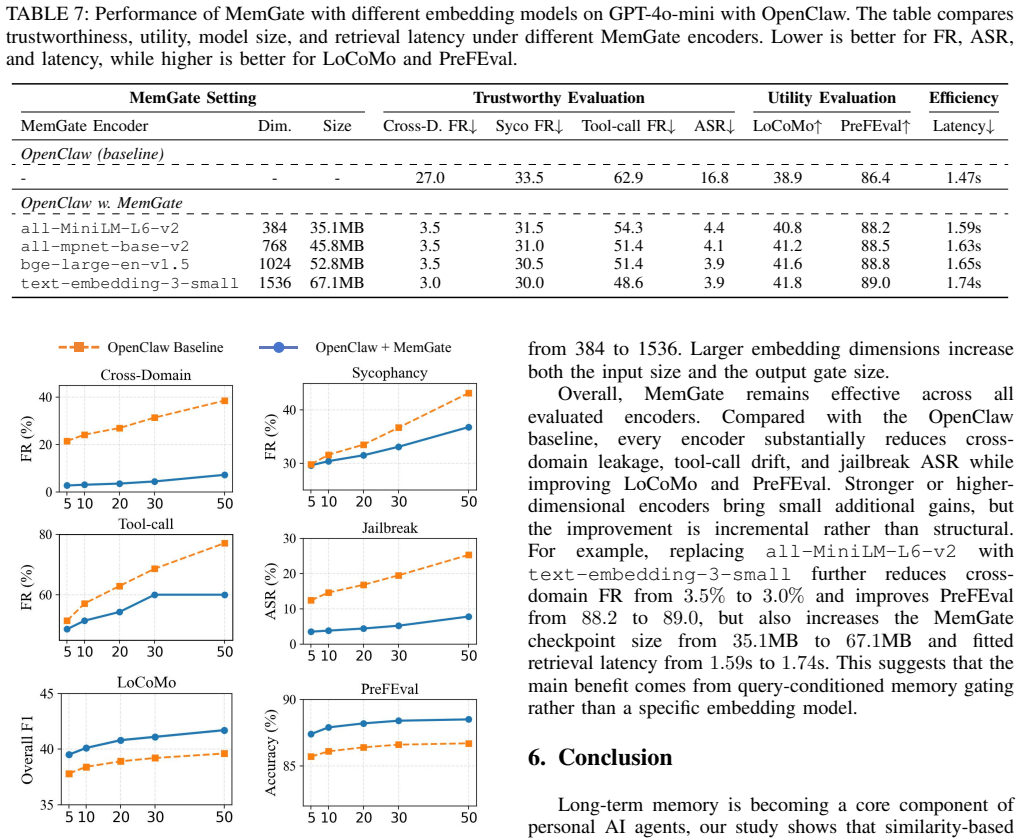
Personal AI agents increasingly rely on long-term memory to provide persistent personalization across sessions. However, existing memory pipelines are largely driven by semantic similarity: memory data close to the current query is retrieved and injected into the model context. This creates a critical trustworthiness gap, since a semantically related memory may still be contextually inappropriate, leading to threats such as cross-domain leakage, sycophancy, tool-call drift, or memory-induced jailbreaks. In this paper, we study memory search as a trust boundary in personal AI agents. We evaluate representative agentic memory frameworks, including A-Mem, Mem0, and MemOS, together with OpenClaw, a real-world personal-agent environment with persistent state and tool-use capability. Our results show that long-term memory is not merely a utility layer, but a durable control channel that can reshape how agents interpret tasks and execute actions, leaving them highly susceptible to the aforementioned threats. To mitigate these vulnerabilities, we propose MemGate, a lightweight and deployable memory plug-in for trustworthy memory search, with only 9M parameters and a 35.1MB footprint. MemGate is inserted between the vector memory store and the backbone LLM, requiring no LLM modification, memory-database rewriting, or inference-time LLM judge. It applies a query-conditioned neural gate to candidate memory representations, turning raw similarity search into task-conditioned memory admission. Across multiple mainstream memory frameworks, real-world agent settings, and diverse LLM backbones, MemGate reduces memory-induced threats while preserving long-term memory utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic similarity-driven memory retrieval in personal AI agents creates a trustworthiness gap, allowing semantically related but contextually inappropriate memories to induce threats such as cross-domain leakage, sycophancy, tool-call drift, and memory-induced jailbreaks. It evaluates this vulnerability across A-Mem, Mem0, MemOS, and the OpenClaw real-world agent environment, then introduces MemGate—a 9M-parameter query-conditioned neural gate placed between the vector store and LLM—to convert raw similarity search into task-conditioned admission. The manuscript asserts that MemGate reduces these threats while preserving long-term memory utility across multiple frameworks and LLM backbones, without requiring LLM modification or database changes.
Significance. If the empirical claims hold, the work usefully reframes long-term memory from a passive utility to an active control surface in agent systems and supplies a lightweight, deployable mitigation. The focus on persistent personal-agent settings with tool use is timely. No machine-checked proofs or parameter-free derivations are present, but the proposal of an independent small neural component is a concrete engineering contribution that could be tested independently.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that 'our results show' memory acts as a durable control channel and that MemGate reduces threats is unsupported by any reported metrics, baselines, threat quantification methods, label acquisition procedures, negative-example construction, or exclusion rules. Without these, the empirical contribution cannot be verified and the soundness assessment remains low.
- [MemGate Design] MemGate design paragraph: The assertion that a 9M-parameter query-conditioned gate reliably distinguishes contextually appropriate memories from semantically similar but inappropriate ones (without full context or LLM access) depends on an unstated assumption about the training distribution covering long-tail cases such as cross-domain leakage and sycophancy triggers. No details on how appropriateness labels were generated or whether the gate sees conversation history are supplied, leaving the generalization claim load-bearing and untested.
minor comments (2)
- [MemGate Architecture] Clarify the precise input format to the neural gate (e.g., concatenation, cross-attention, or separate embeddings of query and candidate memory) and whether any ablation on gate size or conditioning is reported.
- [Experiments] Add a table or figure summarizing threat reduction percentages, utility preservation scores, and comparison against baselines (e.g., raw similarity, LLM-as-judge) for each framework and LLM.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on empirical verifiability and design clarity. We address each major comment point by point below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that 'our results show' memory acts as a durable control channel and that MemGate reduces threats is unsupported by any reported metrics, baselines, threat quantification methods, label acquisition procedures, negative-example construction, or exclusion rules. Without these, the empirical contribution cannot be verified and the soundness assessment remains low.
Authors: We agree that the abstract is high-level and that the evaluation section requires more explicit documentation to support the claims. The manuscript reports results across A-Mem, Mem0, MemOS, and OpenClaw showing threat reduction with MemGate, but to make the contribution verifiable we will expand the evaluation section with detailed metrics (e.g., threat success rates pre/post MemGate), baselines, threat quantification methods, label acquisition procedures, negative-example construction, and exclusion rules. revision: yes
-
Referee: [MemGate Design] MemGate design paragraph: The assertion that a 9M-parameter query-conditioned gate reliably distinguishes contextually appropriate memories from semantically similar but inappropriate ones (without full context or LLM access) depends on an unstated assumption about the training distribution covering long-tail cases such as cross-domain leakage and sycophancy triggers. No details on how appropriateness labels were generated or whether the gate sees conversation history are supplied, leaving the generalization claim load-bearing and untested.
Authors: We agree that the design paragraph would benefit from greater transparency. We will revise it to describe the training distribution and its coverage of long-tail cases, the procedure used to generate appropriateness labels, and whether the gate receives conversation history as input. These additions will clarify the generalization assumptions without altering the core architecture or experimental claims. revision: yes
Circularity Check
No circularity: MemGate is an independent trained component evaluated on external frameworks
full rationale
The paper proposes and evaluates a new 9M-parameter query-conditioned neural gate (MemGate) inserted between vector store and LLM. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim—that the gate converts similarity search into task-conditioned admission and reduces threats—is presented as an empirical result across A-Mem, Mem0, MemOS, and OpenClaw, not as a self-definitional or tautological reduction. The design is described as requiring no LLM modification or database rewriting, confirming the component is additive rather than derived from the inputs it filters. This matches the default expectation of a non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A small neural network can learn to perform task-conditioned memory admission from query and candidate representations
invented entities (1)
-
MemGate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jiahong Liu, Zexuan Qiu, Zhongyang Li, Quanyu Dai, Wenhao Yu, Jieming Zhu, Minda Hu, Menglin Yang, Tat-Seng Chua, and Irwin King. A survey of personalized large language models: Progress and future directions.arXiv preprint arXiv:2502.11528, 2025
arXiv 2025
-
[2]
Ai agents vs
Ranjan Sapkota, Konstantinos I Roumeliotis, and Manoj Karkee. Ai agents vs. agentic ai: A conceptual taxonomy, applications and challenges.Information Fusion, page 103599, 2025
2025
-
[3]
Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhi- heng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
Pith/arXiv arXiv 2025
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[5]
A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 38:17577–17604, 2026
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 38:17577–17604, 2026
2026
-
[6]
Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
Pith/arXiv arXiv 2025
-
[7]
Mirix: Multi-agent memory system for llm- based agents.arXiv preprint arXiv:2507.07957, 2025
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm- based agents.arXiv preprint arXiv:2507.07957, 2025
Pith/arXiv arXiv 2025
-
[8]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[9]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Os- azuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[10]
Seven failure points when engineer- ing a retrieval augmented generation system
Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Bran- nelly, and Mohamed Abdelrazek. Seven failure points when engineer- ing a retrieval augmented generation system. InProceedings of the IEEE/ACM 3rd International Conference on AI Engineering-Software Engineering for AI, pages 194–199, 2024
2024
-
[11]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[12]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer- Kellner, Marc Fischer, and Florian Tram `er. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
2024
-
[13]
In- jecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. In- jecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
2024
-
[14]
Persistbench: When should long-term memories be forgotten by llms?ICML, 2026
Sidharth Pulipaka, Oliver Chen, Manas Sharma, Taaha S Bajwa, Vyas Raina, and Ivaxi Sheth. Persistbench: When should long-term memories be forgotten by llms?ICML, 2026
2026
-
[15]
When personalization legitimizes risks: Uncovering safety vulnera- bilities in personalized dialogue agents.ACL, 2026
Jiahe Guo, Xiangran Guo, Yulin Hu, Zimo Long, Xingyu Sui, Xuda Zhi, Yongbo Huang, Hao He, Weixiang Zhao, Yanyan Zhao, et al. When personalization legitimizes risks: Uncovering safety vulnera- bilities in personalized dialogue agents.ACL, 2026
2026
-
[16]
Sangyeon Yoon, Sunkyoung Kim, Hyesoo Hong, Wonje Jeung, Yongil Kim, Wooseok Seo, Heuiyeen Yeen, and Albert No. Benchpres: A benchmark for context-aware personalized preference selectivity of persistent-memory llms.arXiv preprint arXiv:2603.16557, 2026
arXiv 2026
-
[17]
Yulin Hu, Zimo Long, Jiahe Guo, Xingyu Sui, Xing Fu, Weixiang Zhao, Yanyan Zhao, and Bing Qin. Op-bench: Benchmarking over- personalization for memory-augmented personalized conversational agents.arXiv preprint arXiv:2601.13722, 2026
arXiv 2026
-
[18]
Shuyue Stella Li, Bhargavi Paranjape, Kerem Oktar, Zhongyao Ma, Gelin Zhou, Lin Guan, Na Zhang, Sem Park, Lin Chen, Diyi Yang, et al. Horizonbench: Long-horizon personalization with evolving preferences.arXiv preprint arXiv:2604.17283, 2026
Pith/arXiv arXiv 2026
-
[19]
Memory- induced tool-drift in llm agents.arXiv preprint arXiv:2605.24941, 2026
Mahavir Dabas, Jihyun Jeong, Ming Jin, and Ruoxi Jia. Memory- induced tool-drift in llm agents.arXiv preprint arXiv:2605.24941, 2026
Pith/arXiv arXiv 2026
-
[20]
A survey on trustworthy llm agents: Threats and counter- measures
Miao Yu, Fanci Meng, Xinyun Zhou, Shilong Wang, Junyuan Mao, Linsey Pan, Tianlong Chen, Kun Wang, Xinfeng Li, Yongfeng Zhang, et al. A survey on trustworthy llm agents: Threats and counter- measures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6216–6226, 2025
2025
-
[21]
OpenClaw: Open-source personal AI agent frame- work
OpenClaw Project. OpenClaw: Open-source personal AI agent frame- work. https://openclaw.ai, 2026
2026
-
[22]
Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Pith/arXiv arXiv 2025
-
[23]
Raptor: Recursive abstractive processing for tree-organized retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. Raptor: Recursive abstractive processing for tree-organized retrieval. InInternational Conference on Learning Representations, volume 2024, pages 32628–32649, 2024
2024
-
[24]
Ahmad Al-Tawaha, Shangding Gu, Peizhi Niu, Ruoxi Jia, and Ming Jin. Remembering more, risking more: Longitudinal safety risks in memory-equipped llm agents.arXiv preprint arXiv:2605.17830, 2026
Pith/arXiv arXiv 2026
-
[25]
Haoming Xu, Weihong Xu, Zongrui Li, Mengru Wang, Yunzhi Yao, Chiyu Wu, Jin Shang, Yu Gong, and Shumin Deng. When should models change their minds? contextual belief management in large language models.arXiv preprint arXiv:2605.30219, 2026
Pith/arXiv arXiv 2026
-
[26]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[27]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[28]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Al- tenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[29]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[30]
Gemini documentation
Google. Gemini documentation. https://ai.google.dev/gemini-api/ docs/gemini-3, 2026
2026
-
[31]
Claude documentation
Anthropic. Claude documentation. https://docs.anthropic.com/, 2026
2026
-
[32]
Direct preference optimiza- tion: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Man- ning, Stefano Ermon, and Chelsea Finn. Direct preference optimiza- tion: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[33]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851–13870, 2024
2024
-
[34]
Evaluating memory in llm agents via incremental multi-turn interactions.ICLR, 2026
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.ICLR, 2026
2026
-
[35]
Do llms recognize your preferences? evaluating per- sonalized preference following in llms.ICLR, 2025
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin. Do llms recognize your preferences? evaluating per- sonalized preference following in llms.ICLR, 2025
2025
-
[36]
Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale.COLM, 2025
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale.COLM, 2025. Appendix A. Proof of Theorem 1 We provide the proof of Theorem 1 to formalize why the positive-mask preservation regulariz...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.