Knowledge Distillation for Visual Autoregressive Models
Pith reviewed 2026-06-28 01:58 UTC · model grok-4.3
The pith
VarKD improves knowledge distillation for visual autoregressive image models by distilling on student samples with selective teacher supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
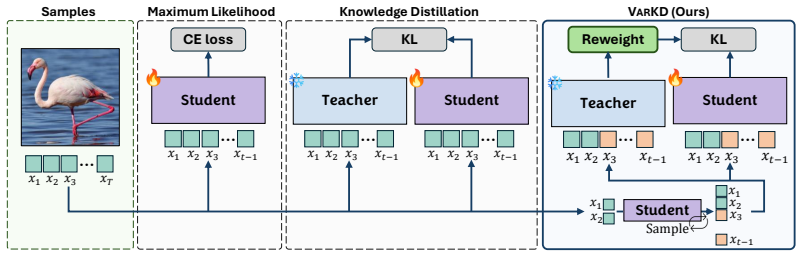
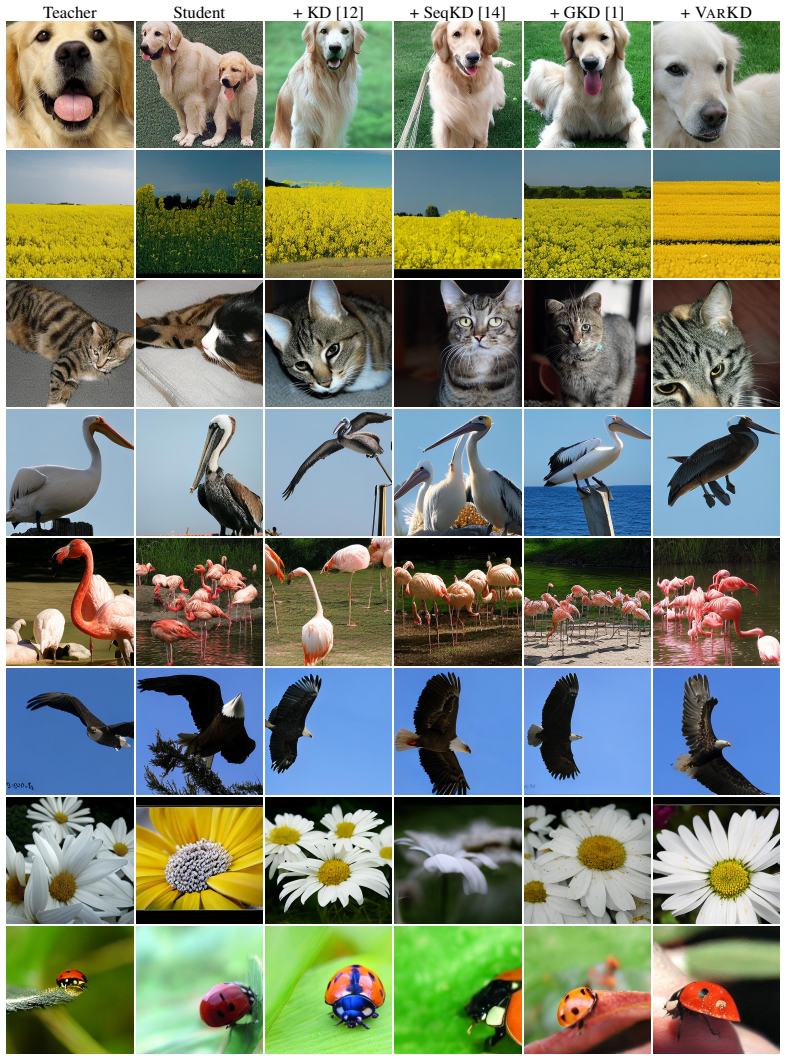
Standard distillation produces some gains yet language-based methods fail to transfer to images: long decoding horizons and visual token ambiguity render teacher supervision unreliable especially under student-conditioned contexts. VarKD addresses the issue by distilling on student samples while selectively applying teacher supervision and reducing token-level ambiguity. Experiments on ImageNet across multiple AR backbones show that VarKD consistently outperforms prior distillation baselines, narrowing the gap to large-scale models.
What carries the argument
VarKD, the distillation framework that distills on student-generated samples while selectively applying teacher supervision and reducing token-level ambiguity.
If this is right
- VarKD consistently outperforms prior distillation baselines on ImageNet.
- It narrows the performance gap to large-scale models.
- The gains hold across multiple AR backbones.
- Selective supervision reduces the impact of unreliable teacher signals during student decoding.
Where Pith is reading between the lines
- Distillation for long-horizon visual generation may benefit more from student-conditioned contexts than from teacher-forced ones.
- The selective-supervision pattern could inform compression work on other ambiguous token sequences such as video frames.
- A direct test would measure whether VarKD also improves efficiency when combined with quantization on the same backbones.
Load-bearing premise
Distilling on student-generated samples while selectively applying teacher supervision and reducing token-level ambiguity will reliably address the unreliability caused by long decoding horizons and visual token ambiguity in AR image models.
What would settle it
Applying VarKD to an autoregressive backbone on ImageNet and observing no outperformance over prior distillation baselines would falsify the central effectiveness claim.
Figures





read the original abstract
Autoregressive (AR) image generation models are highly expressive but computationally intensive, motivating effective model compression. Knowledge distillation (KD) is a natural approach for model compression and has been widely studied in language modeling, yet its behavior in visual AR generation remains underexplored. In this work, we present the first systematic study of distillation strategies for AR image models. Our analysis shows that while standard distillation can yield meaningful gains, recent methods developed for language do not directly transfer to images: long decoding horizons and visual token ambiguity make teacher supervision unreliable especially under student-conditioned contexts. To address this, we propose VarKD, a distillation framework for visual autoregressive models that distills on student samples while selectively applying teacher supervision and reducing token-level ambiguity. Experiments on ImageNet across multiple AR backbones show that VarKD consistently outperforms prior distillation baselines, narrowing the gap to large-scale models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first systematic study of knowledge distillation for visual autoregressive image generation models. It finds that language-based KD methods do not transfer directly due to long decoding horizons and visual token ambiguity causing unreliable teacher supervision under student-conditioned contexts. The proposed VarKD framework distills using student-generated samples while selectively applying teacher supervision and reducing token-level ambiguity. Experiments on ImageNet with multiple AR backbones are reported to show that VarKD outperforms prior distillation baselines and narrows the gap to large-scale models.
Significance. If the empirical results hold with rigorous evidence, this would represent a significant contribution as the first systematic exploration of KD tailored to visual AR models, offering a practical compression technique that could help close the performance gap between small and large-scale generative models in computer vision.
major comments (1)
- [Abstract] Abstract: the claim that VarKD 'consistently outperforms prior distillation baselines' is asserted without any quantitative results, error bars, dataset splits, ablation details, or specific metrics, making it impossible to verify whether the data support the central claim.
Simulated Author's Rebuttal
We thank the referee for their review and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that VarKD 'consistently outperforms prior distillation baselines' is asserted without any quantitative results, error bars, dataset splits, ablation details, or specific metrics, making it impossible to verify whether the data support the central claim.
Authors: We agree that the abstract states the performance claim at a high level. The manuscript provides the supporting quantitative evidence in Section 4 (Experiments), including tables with FID and other metrics across multiple AR backbones on ImageNet, comparisons to baselines, and ablations. To address the concern directly, we will revise the abstract to incorporate a concise statement of the key quantitative improvements. revision: yes
Circularity Check
No significant circularity; purely empirical claims
full rationale
The manuscript contains no equations, derivations, or parameter-fitting steps that could reduce to their own inputs by construction. The central contribution is an empirical comparison of distillation methods on ImageNet across AR backbones, with VarKD presented as a practical framework whose performance is validated directly against baselines. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises; the analysis of teacher unreliability under long horizons is used only to motivate the method, not to derive its correctness. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of knowledge distillation and autoregressive token modeling hold for visual data.
invented entities (1)
-
VarKD framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
2024
-
[2]
Why exposure bias matters: An imitation learning perspective of error accumulation in language generation
Kushal Arora, Layla El Asri, Hareesh Bahuleyan, and Jackie Chi Kit Cheung. Why exposure bias matters: An imitation learning perspective of error accumulation in language generation. InFindings of the Association for Computational Linguistics: ACL 2022, pages 700–710, 2022
2022
-
[3]
Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
2015
-
[4]
Model compression
Cristian Bucilu ˇa, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541, 2006
2006
-
[5]
Medusa: Simple llm inference acceleration framework with multiple decoding heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024
Pith/arXiv arXiv 2024
-
[6]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
2020
-
[7]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
Pith/arXiv arXiv 2025
-
[8]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[9]
Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Miniplm: Knowledge distillation for pre-training language models.arXiv preprint arXiv:2410.17215, 2024
arXiv 2024
-
[10]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 15733–15744, 2025
2025
-
[11]
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Parallel auto-regressive image generation through spatial locality.arXiv preprint arXiv:2412.04062, 2024
arXiv 2024
-
[12]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[13]
Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sung-Yub Kim, and Eunho Yang. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding.arXiv preprint arXiv:2410.03355, 2024
arXiv 2024
-
[14]
Sequence-level knowledge distillation
Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1317–1327, 2016
2016
-
[15]
Professor forcing: A new algorithm for training recurrent networks.Advances in neural information processing systems, 29, 2016
Alex M Lamb, Anirudh Goyal ALIAS PARTH GOY AL, Ying Zhang, Saizheng Zhang, Aaron C Courville, and Yoshua Bengio. Professor forcing: A new algorithm for training recurrent networks.Advances in neural information processing systems, 29, 2016
2016
-
[16]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11523–11532, 2022. 11
2022
-
[17]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[18]
Autoregressive image generation with randomized parallel decoding
Haopeng Li, Jinyue Yang, Guoqi Li, and Huan Wang. Autoregressive image generation with randomized parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[19]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024
Pith/arXiv arXiv 2024
-
[20]
Eagle-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7421–7432, 2024
2024
-
[21]
Autoregressive knowledge distillation through imitation learning
Alexander Lin, Jeremy Wohlwend, Howard Chen, and Tao Lei. Autoregressive knowledge distillation through imitation learning. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6121–6133, 2020
2020
-
[22]
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yi Xin, Xinyue Li, Qi Qin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal generative pretraining.arXiv preprint arXiv:2408.02657, 2024
arXiv 2024
-
[23]
On-policy distillation.ThinkingMachinesLab: Connectionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Con- nectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy- distillation
-
[24]
Multi-scale local speculative decoding for image generation.arXiv preprint arXiv:2601.05149, 2026
Elia Peruzzo, Guillaume Sautière, and Amirhossein Habibian. Multi-scale local speculative decoding for image generation.arXiv preprint arXiv:2601.05149, 2026
Pith/arXiv arXiv 2026
-
[25]
Mitigating exposure bias in large language model distillation: An imitation learning approach.Neural Computing and Applications, 37(18):12013–12029, 2025
Andrea Pozzi, Alessandro Incremona, Daniele Tessera, and Daniele Toti. Mitigating exposure bias in large language model distillation: An imitation learning approach.Neural Computing and Applications, 37(18):12013–12029, 2025
2025
-
[26]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[27]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
2021
-
[28]
Sequence level training with recurrent neural networks.arXiv preprint arXiv:1511.06732, 2015
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks.arXiv preprint arXiv:1511.06732, 2015
Pith/arXiv arXiv 2015
-
[29]
Generating diverse high-fidelity images with vq-vae-2.Advances in neural information processing systems, 32, 2019
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2.Advances in neural information processing systems, 32, 2019
2019
-
[30]
Sucheng Ren, Yaodong Yu, Nataniel Ruiz, Feng Wang, Alan Yuille, and Cihang Xie. M-var: Decoupled scale-wise autoregressive modeling for high-quality image generation.arXiv preprint arXiv:2411.10433, 2024
arXiv 2024
-
[31]
Beyond next-token: Next-x prediction for autoregressive visual generation
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. Beyond next-token: Next-x prediction for autoregressive visual generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15781–15791, 2025
2025
-
[32]
Efficient reductions for imitation learning
Stéphane Ross and Drew Bagnell. Efficient reductions for imitation learning. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 661–668. JMLR Workshop and Conference Proceedings, 2010
2010
-
[33]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011. 12
2011
-
[34]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[35]
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
Pith/arXiv arXiv 2024
-
[36]
Haotian Tang, Yecheng Wu, Shang Yang, Enze Xie, Junsong Chen, Junyu Chen, Zhuoyang Zhang, Han Cai, Yao Lu, and Song Han. Hart: Efficient visual generation with hybrid autore- gressive transformer.arXiv preprint arXiv:2410.10812, 2024
arXiv 2024
-
[37]
Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
Pith/arXiv arXiv 2024
-
[38]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[39]
Con- ditional image generation with pixelcnn decoders.Advances in neural information processing systems, 29, 2016
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Con- ditional image generation with pixelcnn decoders.Advances in neural information processing systems, 29, 2016
2016
-
[40]
Pixel recurrent neural networks
Aäron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. InInternational conference on machine learning, pages 1747–1756. PMLR, 2016
2016
-
[41]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[43]
Anton V oronov, Denis Kuznedelev, Mikhail Khoroshikh, Valentin Khrulkov, and Dmitry Baranchuk. Switti: Designing scale-wise transformers for text-to-image synthesis.arXiv preprint arXiv:2412.01819, 2024
arXiv 2024
-
[44]
Visual self-refinement for autoregressive models.arXiv preprint arXiv:2510.00993, 2025
Jiamian Wang, Ziqi Zhou, Chaithanya Kumar Mummadi, Sohail Dianat, Majid Rabbani, Raghu- veer Rao, Chen Qiu, and Zhiqiang Tao. Visual self-refinement for autoregressive models.arXiv preprint arXiv:2510.00993, 2025
arXiv 2025
-
[45]
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl.arXiv preprint arXiv:2504.11455, 2025
arXiv 2025
-
[46]
Emu3: Next-token prediction is all you need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
Pith/arXiv arXiv 2024
-
[47]
Tokenbridge: Bridging continuous and discrete tokens for autoregressive visual generation
Yuqing Wang, Zhijie Lin, Yao Teng, Yuanzhi Zhu, Shuhuai Ren, Jiashi Feng, and Xihui Liu. Tokenbridge: Bridging continuous and discrete tokens for autoregressive visual generation. InInternational Conference on Computer Vision (ICCV)(19/10/2025-23/10/2025, Honolulu, Hawai’i), 2025
2025
-
[48]
Jingxuan Wei, Linzhuang Sun, Yichong Leng, Xu Tan, Bihui Yu, and Ruifeng Guo. Sentence- level or token-level? a comprehensive study on knowledge distillation.arXiv preprint arXiv:2404.14827, 2024
arXiv 2024
-
[49]
F-divergence minimization for sequence- level knowledge distillation
Yuqiao Wen, Zichao Li, Wenyu Du, and Lili Mou. F-divergence minimization for sequence- level knowledge distillation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10817–10834, 2023
2023
-
[50]
Rethinking exposure bias in language modeling.arXiv preprint arXiv:1910.11235, 2019
Yifan Xu, Kening Zhang, Haoyu Dong, Yuezhou Sun, Wenlong Zhao, and Zhuowen Tu. Rethinking exposure bias in language modeling.arXiv preprint arXiv:1910.11235, 2019. 13
arXiv 1910
-
[51]
Locally hierarchical auto-regressive modeling for image generation.Advances in Neural Information Processing Systems, 35:16360–16372, 2022
Tackgeun You, Saehoon Kim, Chiheon Kim, Doyup Lee, and Bohyung Han. Locally hierarchical auto-regressive modeling for image generation.Advances in Neural Information Processing Systems, 35:16360–16372, 2022
2022
-
[52]
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
Pith/arXiv arXiv 2022
-
[53]
Towards understanding and improving knowledge distillation for neural machine translation
Songming Zhang, Yunlong Liang, Shuaibo Wang, Yufeng Chen, Wenjuan Han, Jian Liu, and Jinan Xu. Towards understanding and improving knowledge distillation for neural machine translation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8062–8079, 2023
2023
-
[54]
Zhuoyang Zhang, Luke J Huang, Chengyue Wu, Shang Yang, Kelly Peng, Yao Lu, and Song Han. Locality-aware parallel decoding for efficient autoregressive image generation.arXiv preprint arXiv:2507.01957, 2025
arXiv 2025
-
[55]
Holistic tokenizer for autoregressive image generation
Anlin Zheng, Haochen Wang, Yucheng Zhao, Weipeng Deng, Tiancai Wang, Xiangyu Zhang, and Xiaojuan Qi. Holistic tokenizer for autoregressive image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16916–16926, 2025
2025
-
[56]
Revisiting knowledge distillation for autoregressive language models
Qihuang Zhong, Liang Ding, Li Shen, Juhua Liu, Bo Du, and Dacheng Tao. Revisiting knowledge distillation for autoregressive language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10900–10913, 2024
2024
-
[57]
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Ros- tamizadeh, Sanjiv Kumar, Jean-François Kagy, and Rishabh Agarwal. Distillspec: Improving speculative decoding via knowledge distillation.arXiv preprint arXiv:2310.08461, 2023. 14 A Supplementary In this supplementary material, we provide additional details and results for VAR...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.