Amortizing Federated Adaptation: Hypernetwork Driven LoRA for Personalized Foundation Models
Pith reviewed 2026-06-28 01:24 UTC · model grok-4.3
The pith
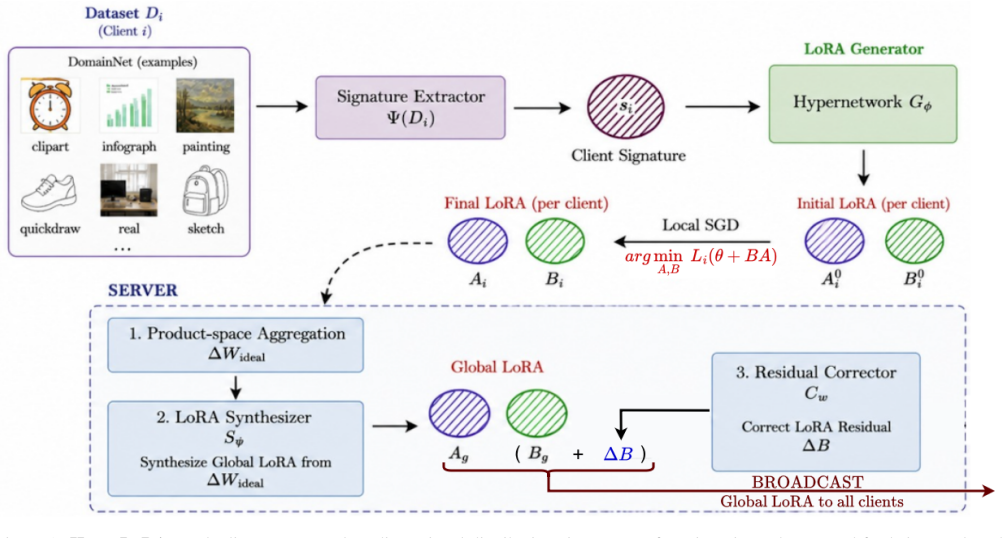
HyperLoRA replaces iterative per-client optimization and factor-wise averaging in federated LoRA with hypernetwork-generated initializations and product-space aggregation to remove structural bias and speed convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HyperLoRA employs a learned generator that maps client distribution signatures to LoRA initializations, amortizing per-client adaptation, and introduces a learned aggregation module that directly synthesizes updates in the low-rank product space, eliminating inconsistencies of factor-wise averaging, with a lightweight residual correction for non-IID distributions.
What carries the argument
Hypernetwork that generates client-specific LoRA initializations from distribution signatures together with a learned product-space aggregation module that operates on the combined low-rank update.
If this is right
- Per-client adaptation cost drops because the hypernetwork produces usable initializations without iterative optimization on each client.
- Aggregation bias disappears when updates are synthesized directly in the low-rank product space instead of averaged factor by factor.
- Convergence accelerates because clients no longer reinitialize LoRA parameters at the start of every communication round.
- Stability improves on heterogeneous data through the addition of a lightweight residual correction term.
- Personalization performance rises on both vision and vision-language federated tasks relative to earlier LoRA federated baselines.
Where Pith is reading between the lines
- The same hypernetwork-plus-product-space pattern could be applied to other parameter-efficient adapters beyond LoRA in distributed settings.
- Learned aggregation operators may transfer to non-federated distributed training where low-rank updates are combined across nodes.
- Because initialization is amortized, the approach could reduce total communication volume when scaling to very large foundation models.
- The residual correction module suggests a route for combining learned operators with existing techniques for handling client drift.
Load-bearing premise
A hypernetwork can map client distribution signatures to effective LoRA initializations and a learned aggregation module can synthesize updates in the low-rank product space that eliminate the structural inconsistencies of factor-wise averaging.
What would settle it
On the same federated vision benchmarks, replace the product-space aggregation module with standard factor-wise averaging while keeping the hypernetwork generator, then measure whether convergence speed and personalization metrics fall back to the levels of prior federated LoRA methods.
Figures
read the original abstract
Federated fine-tuning of foundation models using Low-Rank Adaptation (LoRA) offers a communication efficient solution for distributed learning. However, existing federated LoRA methods suffer from two fundamental limitations: (1) structural aggregation bias, where independently averaging low rank factors fails to approximate the true combined update, and (2) client side initialization lag, as clients repeatedly reinitialize LoRA parameters across communication rounds, slowing convergence. We propose HyperLoRA, a unified framework that addresses both issues through amortized federated adaptation through hypernetwork-driven LoRA generation and product space aggregation. Instead of iterative per-client optimization, HyperLoRA employs a learned generator that maps client distribution signatures to LoRA initializations, effectively amortizing per client adaptation. On the server side, we introduce a learned aggregation module that directly synthesizes updates in the low-rank product space, eliminating the inconsistencies of factor-wise averaging. A lightweight residual correction module further improves stability under heterogenous (non-IID) client distributions.By replacing iterative optimization and heuristic averaging with learned operators, HyperLoRA jointly enables efficient personalization, unbiased aggregation, and faster convergence. Experiments on federated vision and vision-language benchmarks show that HyperLoRA achieves improved convergence speed, greater robustness to distribution shift, and stronger personalization performance compared to prior federated LoRA methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyperLoRA, a unified framework for federated fine-tuning of foundation models via LoRA. It targets two limitations of existing methods—structural aggregation bias from independent averaging of low-rank factors and client-side initialization lag—by employing a hypernetwork that maps client distribution signatures to LoRA initializations (amortizing per-client adaptation), a learned aggregation module that synthesizes updates directly in the low-rank product space, and a lightweight residual correction module for non-IID stability. The approach claims to replace iterative optimization and heuristic averaging with learned operators, yielding efficient personalization, unbiased aggregation, and faster convergence, supported by experiments on federated vision and vision-language benchmarks.
Significance. If the empirical claims hold and the learned operators deliver the stated benefits, the work would advance federated adaptation of foundation models by substituting heuristics with amortized, learned components, potentially improving communication efficiency, convergence, and personalization under heterogeneity. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract (framework description)] Abstract (framework description): the assertion that the learned aggregation module 'directly synthesizes updates in the low-rank product space, eliminating the inconsistencies of factor-wise averaging' is load-bearing for the unbiased-aggregation claim yet supplies no error bound, proof that the module output is closer to mean(BA) than avg(B)avg(A), or characterization of the function class needed to learn the product operation.
- [Abstract] Abstract: no equations, derivations, quantitative results, or experimental details (e.g., datasets, baselines, metrics, or tables) are provided, preventing verification of the claimed gains in convergence speed, robustness to distribution shift, and personalization performance.
minor comments (1)
- [Abstract] Abstract: the phrase 'amortizing federated adaptation' is used without a formal definition or citation to prior amortization literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and note planned revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract (framework description)] Abstract (framework description): the assertion that the learned aggregation module 'directly synthesizes updates in the low-rank product space, eliminating the inconsistencies of factor-wise averaging' is load-bearing for the unbiased-aggregation claim yet supplies no error bound, proof that the module output is closer to mean(BA) than avg(B)avg(A), or characterization of the function class needed to learn the product operation.
Authors: We acknowledge that the manuscript provides no theoretical error bounds, proofs, or function-class characterization for the learned aggregation module. The approach is presented as an empirical alternative to factor-wise averaging, with the full paper demonstrating performance gains on federated benchmarks. We will revise the abstract to qualify the claim, indicating that the module mitigates inconsistencies via learned synthesis in the product space, as validated empirically rather than through formal guarantees. revision: yes
-
Referee: [Abstract] Abstract: no equations, derivations, quantitative results, or experimental details (e.g., datasets, baselines, metrics, or tables) are provided, preventing verification of the claimed gains in convergence speed, robustness to distribution shift, and personalization performance.
Authors: Abstracts are intentionally concise and omit detailed equations or results. The full manuscript contains the requested elements, including derivations of the hypernetwork and aggregation modules, experimental protocols, datasets, baselines, metrics, and quantitative tables in the methods and experiments sections. We will revise the abstract to include a brief statement summarizing the observed improvements in convergence and personalization on the reported benchmarks. revision: yes
- Theoretical error bound or proof that the learned aggregation module output is closer to mean(BA) than factor-wise averaging, or characterization of the required function class.
Circularity Check
No derivations or equations present; claims rest on empirical validation without self-referential structure
full rationale
The abstract and framework description contain no equations, derivations, or self-citations. Central claims about hypernetwork-driven initialization and product-space aggregation are presented as design choices whose effectiveness is asserted via experiments, not derived from prior results or fitted parameters renamed as predictions. No self-definitional mappings, uniqueness theorems, or ansatzes smuggled via citation appear. The skeptic concern addresses missing formal bounds, which is a correctness issue rather than circularity. The derivation chain is self-contained against external benchmarks in the sense that no internal reduction to inputs is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
Communication-Efficient Learning of Deep Networks from Decentralized Data , author =. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
-
[2]
Proceedings of Machine Learning and Systems (MLSys) , year =
Federated Optimization in Heterogeneous Networks , author =. Proceedings of Machine Learning and Systems (MLSys) , year =
-
[3]
International Conference on Machine Learning (ICML) , year =
Ditto: Fair and Robust Federated Learning Through Personalization , author =. International Conference on Machine Learning (ICML) , year =
-
[4]
Personalized Cross-Silo Federated Learning on Non-
Huang, Yutao and Chu, Lingyang and Zhou, Zirui and Wang, Lanjun and Liu, Jiangchuan and Pei, Jian and Zhang, Yong , booktitle =. Personalized Cross-Silo Federated Learning on Non-
-
[5]
Li, Xiaoxiao and Jiang, Meirui and Zhang, Xiaofei and Kamp, Michael and Dou, Qi , booktitle =. Fed
-
[6]
Karimireddy, Sai Praneeth and Kale, Satyen and Mohri, Mehryar and Reddi, Sashank and Stich, Sebastian and Suresh, Ananda Theertha , booktitle =
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[8]
International Conference on Learning Representations (ICLR) , year =
Federated Learning Based on Dynamic Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[9]
Federated Learning with Non-
Zhao, Yue and Li, Meng and Lai, Liangzhen and Suda, Naveen and Civin, Damon and Chandra, Vikas , journal =. Federated Learning with Non-
-
[10]
Federated Learning on Non-
Li, Qinbin and Diao, Yiqun and Chen, Quan and He, Bingsheng , booktitle =. Federated Learning on Non-
-
[11]
Foundations and Trends in Machine Learning , volume =
Advances and Open Problems in Federated Learning , author =. Foundations and Trends in Machine Learning , volume =
-
[12]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. Lo
-
[13]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , booktitle =. Ada
-
[14]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle =. Do
-
[15]
, booktitle =
Kopiczko, Dawid Jan and Blankevoort, Tijmen and Asano, Yuki M. , booktitle =. Ve
-
[16]
Meng, Fanxu and Wang, Zhaohui and Zhang, Muhan , journal =. Pi
-
[17]
Tian, Chunlin and Shi, Zhan and Guo, Zhijiang and Li, Li and Xu, Cheng-Zhong , journal =. Hydra
-
[18]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle =. Parameter-Efficient Transfer Learning for
-
[19]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
The Power of Scale for Parameter-Efficient Prompt Tuning , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[20]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[21]
Ben Zaken, Elad and Goldberg, Yoav and Ravfogel, Shauli , booktitle =. Bit
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[23]
European Conference on Computer Vision (ECCV) , year =
Visual Prompt Tuning , author =. European Conference on Computer Vision (ECCV) , year =
-
[24]
International Journal of Computer Vision (IJCV) , volume =
Learning to Prompt for Vision-Language Models , author =. International Journal of Computer Vision (IJCV) , volume =
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Conditional Prompt Learning for Vision-Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[26]
Khattak, Muhammad Uzair and Rasheed, Hanoona and Maaz, Muhammad and Khan, Salman and Khan, Fahad Shahbaz , booktitle =. Ma
-
[27]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author =. arXiv preprint arXiv:2403.14608 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Nature Machine Intelligence , volume =
Parameter-Efficient Fine-Tuning of Large-Scale Pre-trained Language Models , author =. Nature Machine Intelligence , volume =
-
[29]
Towards Building the Federated
Zhang, Jianyi and Vahidian, Saeed and Kuo, Martin and Li, Chunyuan and Zhang, Ruiyi and Yu, Tong and Wang, Guoyin and Chen, Yiran , booktitle =. Towards Building the Federated
-
[30]
arXiv preprint arXiv:2403.12313 , year =
Improving LoRA in Privacy-Preserving Federated Learning , author =. arXiv preprint arXiv:2403.12313 , year =
-
[31]
arXiv preprint arXiv:2409.05976 , year =
Flora: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations , author =. arXiv preprint arXiv:2409.05976 , year =
-
[32]
arXiv preprint arXiv:2402.11505 , year =
Federated Fine-Tuning of Large Language Models under Heterogeneous Language Tasks and Client Resources , author =. arXiv preprint arXiv:2402.11505 , year =
-
[33]
Bian, Jieming and Wang, Lei and Zhang, Letian and Xu, Jie , booktitle =. Lo
-
[34]
International Workshop on Federated Learning in the Age of Foundation Models, NeurIPS , year =
Heterogeneous LoRA for Federated Fine-Tuning of On-Device Foundation Models , author =. International Workshop on Federated Learning in the Age of Foundation Models, NeurIPS , year =
-
[35]
Zhang, Zhuo and Yang, Yuanhang and Dai, Yong and Wang, Qifan and Yu, Yue and Qu, Lizhen and Xu, Zenglin , booktitle =. Fed
-
[36]
Kuang, Weirui and Qian, Bingchen and Li, Zitao and Chen, Daoyuan and Gao, Dawei and Pan, Xuchen and Xie, Yuexiang and Li, Yaliang and Ding, Bolin and Zhou, Jingren , booktitle =
-
[37]
arXiv preprint arXiv:2308.06522 , year =
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models , author =. arXiv preprint arXiv:2308.06522 , year =
-
[38]
Yi, Liping and Yu, Han and Wang, Gang and Liu, Xiaoguang and Li, Xiaoxiao , journal =
-
[39]
Wu, Feijie and Li, Zitao and Li, Yaliang and Ding, Bolin and Gao, Jing , booktitle =. Fed
-
[40]
and Le, Quoc V
Ha, David and Dai, Andrew M. and Le, Quoc V. , booktitle =. Hyper
-
[41]
International Conference on Learning Representations (ICLR) , year =
Continual Learning with Hypernetworks , author =. International Conference on Learning Representations (ICLR) , year =
-
[42]
4th Workshop on Meta-Learning, NeurIPS , year =
Meta-Learning via Hypernetworks , author =. 4th Workshop on Meta-Learning, NeurIPS , year =
-
[43]
International Conference on Machine Learning (ICML) , year =
Personalized Federated Learning Using Hypernetworks , author =. International Conference on Machine Learning (ICML) , year =
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Layer-Wised Model Aggregation for Personalized Federated Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[45]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Parameter-Efficient Multi-Task Fine-Tuning for Transformers via Shared Hypernetworks , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[46]
, booktitle =
He, Yun and Zheng, Steven and Tay, Yi and Gupta, Jai and Du, Yu and Aribandi, Vamsi and Zhao, Zhe and Li, Yaguang and Chen, Zhao and Metzler, Donald and Cheng, Heng-Tze and Chi, Ed H. , booktitle =. Hyper
-
[47]
, booktitle =
Ivison, Hamish and Peters, Matthew E. , booktitle =. Hyperdecoders: Instance-Specific Decoders for Multi-Task
-
[48]
, booktitle =
Ivison, Hamish and Bhagia, Akshita and Wang, Yizhong and Hajishirzi, Hannaneh and Peters, Matthew E. , booktitle =
-
[49]
International Conference on Machine Learning (ICML) , year =
Hypertuning: Toward Adapting Large Language Models without Backpropagation , author =. International Conference on Machine Learning (ICML) , year =
-
[50]
Lv, Chuanyang and Li, Liang and Zhang, Shuai and Chen, Gehui and Qi, Fanchao and Zhang, Ningyu and Zheng, Hai-Tao , booktitle =. Hyper
-
[51]
, booktitle =
Charakorn, Rujikorn and Cetin, Edoardo and Tang, Yujin and Lange, Robert T. , booktitle =. Text-to-Lo
-
[52]
, journal =
Charakorn, Rujikorn and Cetin, Edoardo and Uesaka, Shinnosuke and Lange, Robert T. , journal =. Doc-to-Lo
-
[53]
International Conference on Learning Representations (ICLR) , year =
Generative Adapter: Contextualizing Language Models in Parameters with a Single Forward Pass , author =. International Conference on Learning Representations (ICLR) , year =
-
[54]
arXiv preprint arXiv:2506.06266 , year =
Cartridges: Lightweight and General-Purpose Long Context Representations via Self-Study , author =. arXiv preprint arXiv:2506.06266 , year =
-
[55]
Li, Yichuan and Ma, Xiyao and Lu, Sichao and Lee, Kyumin and Liu, Xiaohu and Guo, Chenlei , booktitle =
-
[56]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Learning to Compress Prompts with Gist Tokens , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[57]
2016 , eprint=
HyperNetworks , author=. 2016 , eprint=
2016
-
[58]
International Conference on Machine Learning (ICML) , year =
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author =. International Conference on Machine Learning (ICML) , year =
-
[59]
On First-Order Meta-Learning Algorithms
On First-Order Meta-Learning Algorithms , author =. arXiv preprint arXiv:1803.02999 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Fast and Flexible Multi-Task Classification Using Conditional Neural Adaptive Processes , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[61]
International Conference on Machine Learning (ICML) , year =
Perceiver: General Perception with Iterative Attention , author =. International Conference on Machine Learning (ICML) , year =
-
[62]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Personalized Federated Learning with Moreau Envelopes , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[64]
International Conference on Machine Learning (ICML) , year =
Exploiting Shared Representations for Personalized Federated Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[65]
Oh, Jaehoon and Kim, SangMook and Yun, Se-Young , booktitle =. Fed
-
[66]
Federated Learning with Personalization Layers
Federated Learning with Personalization Layers , author =. arXiv preprint arXiv:1912.00818 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[67]
IEEE Transactions on Neural Networks and Learning Systems , year =
Towards Personalized Federated Learning , author =. IEEE Transactions on Neural Networks and Learning Systems , year =
-
[68]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Federated Learning from Pre-trained Models: A Contrastive Learning Approach , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[69]
Tian, Yuanyishu and Wan, Yao and Lyu, Lingjuan and Yao, Dezhong and Jin, Hai and Sun, Lichao , journal =. Fed
-
[70]
arXiv preprint arXiv:2210.01708 , year =
Conquering the Communication Constraints to Enable Large Pre-Trained Models in Federated Learning , author =. arXiv preprint arXiv:2210.01708 , year =
-
[71]
arXiv preprint arXiv:2402.06954 , year =
Federated Learning of Foundation Models: A Survey , author =. arXiv preprint arXiv:2402.06954 , year =
-
[72]
arXiv preprint arXiv:2305.11414 , year =
Federated Foundation Models: Privacy-Preserving and Collaborative Learning for Large Models , author =. arXiv preprint arXiv:2305.11414 , year =
-
[73]
Transactions on Machine Learning Research (TMLR) , year =
Personalization of Large Language Models: A Survey , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[74]
A General Language Assistant as a Laboratory for Alignment
A General Language Assistant as a Laboratory for Alignment , author =. arXiv preprint arXiv:2112.00861 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Propagating Knowledge Updates to
Padmanabhan, Shankar and Onoe, Yasumasa and Zhang, Michael and Durrett, Greg and Choi, Eunsol , booktitle =. Propagating Knowledge Updates to
-
[76]
arXiv preprint arXiv:2209.15189 , year =
Learning by Distilling Context , author =. arXiv preprint arXiv:2209.15189 , year =
-
[77]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
1985
-
[78]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
2001
-
[79]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[80]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.