Diffusion Models Observe Only Gradients: A Geometric Perspective on Score Matching Errors
Pith reviewed 2026-06-30 10:57 UTC · model grok-4.3
The pith
A diffusion model can perfectly match the target distribution while incurring arbitrarily large L² score error because only the gradient part of the error affects the marginal dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
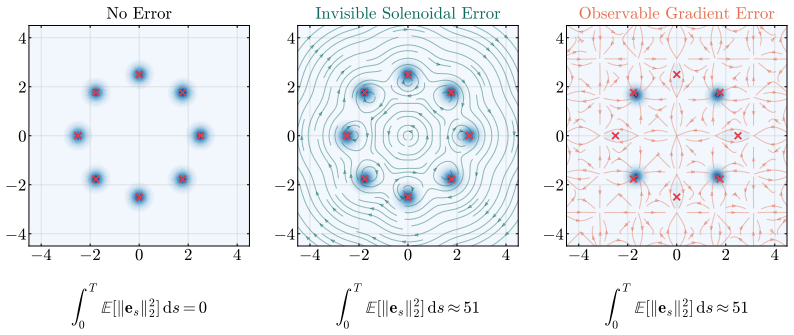
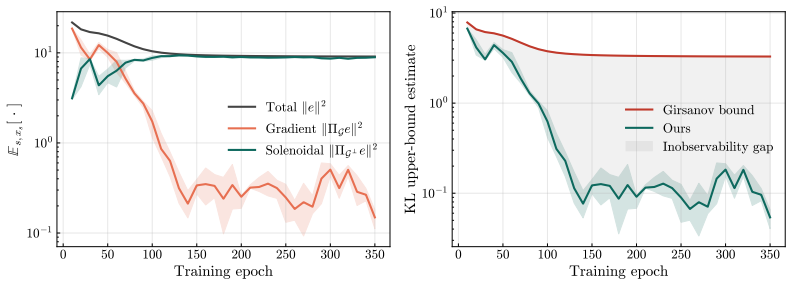
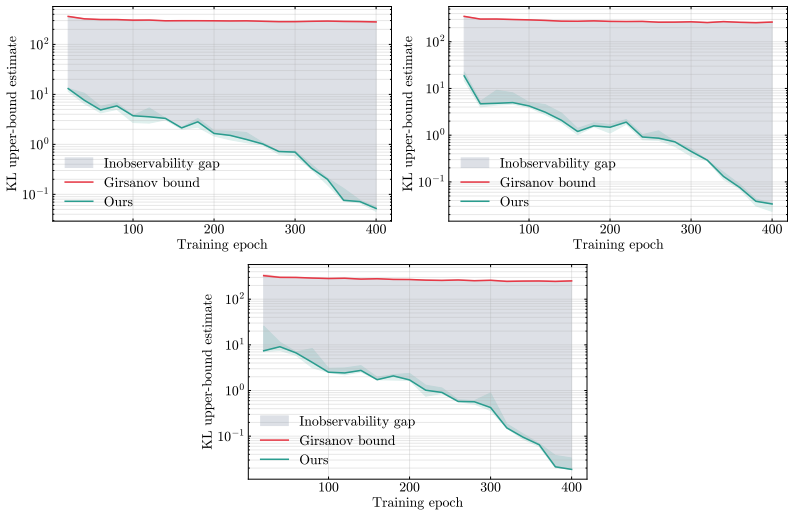
Applying the Helmholtz-Hodge decomposition to the difference between the learned and true score functions isolates a gradient component that alone enters the marginal Fokker-Planck equation; the orthogonal solenoidal component is invisible to the evolution of the probability measure. Consequently no monotone function of the L² score error can serve as a uniform lower bound on any divergence between the learned and target distributions, while an upper bound on the KL divergence can be stated using only the gradient component.
What carries the argument
Helmholtz-Hodge decomposition of the score error vector field, which isolates the gradient component that governs marginal Fokker-Planck dynamics from the solenoidal component that does not.
If this is right
- No monotone function of the L² score error can uniformly lower-bound any divergence between learned and target distributions.
- The KL divergence between learned and target distributions admits an upper bound that depends only on the gradient component of the score error.
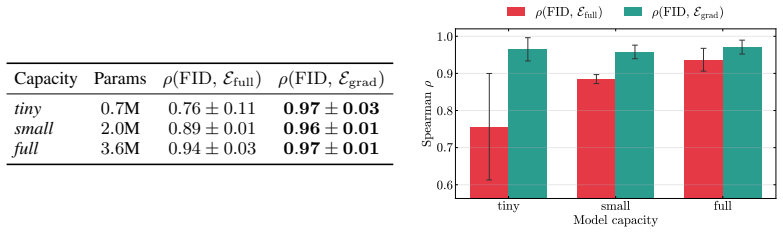
- A dual Sobolev identity yields a tractable estimator of the gradient component that correlates more strongly with sample quality than the full L² error.
Where Pith is reading between the lines
- Training objectives could be redesigned to penalize only the gradient component rather than the full L² norm.
- The same decomposition may apply to other generative models that rely on estimated vector fields or scores.
- Monitoring the size of the solenoidal component during training could diagnose unnecessary model capacity without harming distributional accuracy.
Load-bearing premise
The Helmholtz-Hodge decomposition of the score error correctly identifies a gradient component that alone controls the marginal probability evolution.
What would settle it
Train a score network whose error vector field has a large solenoidal component yet produces samples whose empirical distribution converges to the target; if the samples fail to match whenever the full L² error is large, the claim is falsified.
Figures
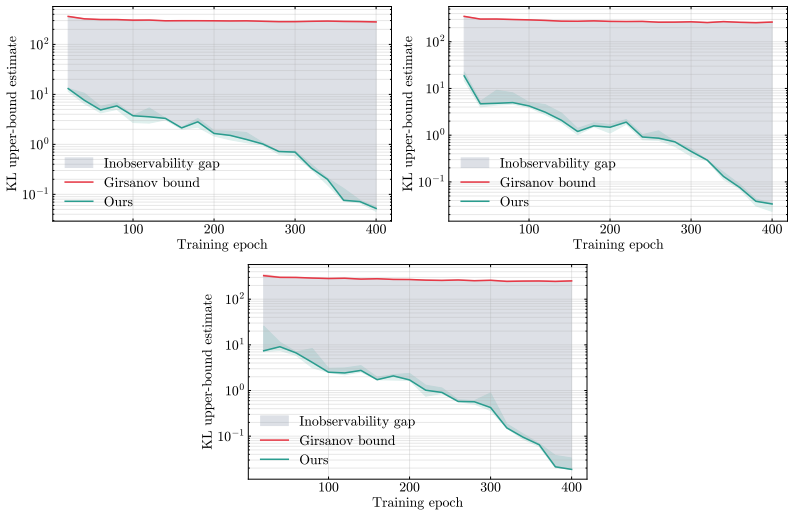
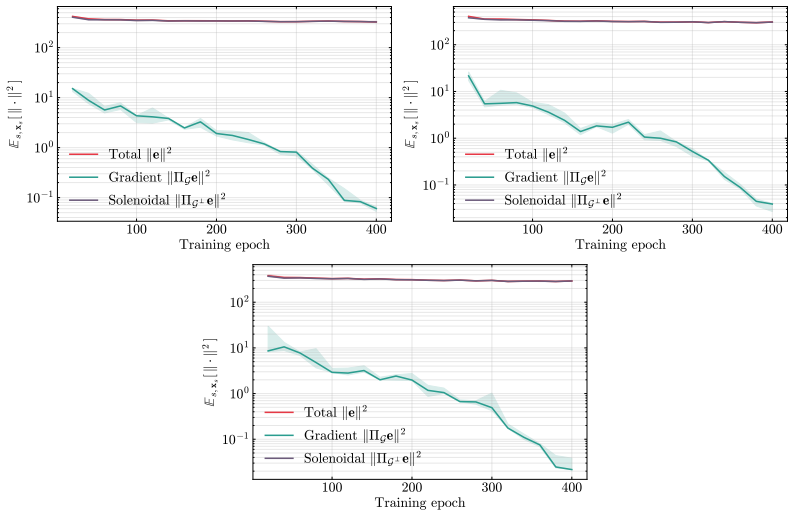
read the original abstract
Score-based diffusion models are typically trained by minimizing the $L^2$ score matching error, and standard theoretical analyses rely on this quantity to bound the sampling discrepancy between the learned and target distributions. We show the $L^2$ score error is not the right intrinsic measure of marginal distributional quality: a learned diffusion model can incur arbitrarily large $L^2$ score error while perfectly matching the target distribution. By decomposing score errors into a gradient and a solenoidal component (a Helmholtz-Hodge decomposition), we identify the geometric reason behind this: only the gradient component enters the marginal Fokker-Planck dynamics, while the solenoidal component is structurally invisible. We make this precise in three results. First, building on the corrected geometry, we prove an impossibility result: no monotone function of the $L^2$ score error can uniformly lower bound any divergence between the learned and target distributions. Second, we derive an upper bound on the Kullback-Leibler divergence that depends only on the observable gradient component of the error, tightening the standard Girsanov bound for generic score networks, and identifying its looseness as the cost of operating on path-space rather than marginal-space dynamics. Third, we give a tractable estimator of the gradient component via a dual Sobolev identity, which is shown to empirically correlate substantially better with sample quality than the full $L^2$ error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the L² score-matching objective is not the right intrinsic measure of marginal quality for learned diffusion models: via a Helmholtz-Hodge decomposition of the score error into gradient and solenoidal components, only the gradient part enters the marginal Fokker-Planck dynamics while the solenoidal part is invisible to them. This geometry is used to prove (i) an impossibility result that no monotone function of the L² error can uniformly lower-bound any divergence between learned and target marginals, (ii) a tightened KL upper bound that depends only on the observable gradient component (improving the standard Girsanov bound), and (iii) a tractable estimator of the gradient component via a dual Sobolev identity that empirically correlates better with sample quality than the full L² error.
Significance. If the decomposition is valid under the paper's conditions, the work supplies a geometric explanation for the frequent mismatch between L² score error and generative performance, supplies a strictly tighter marginal-space bound, and introduces a practical estimator whose empirical superiority is a concrete strength. The dual-Sobolev construction for the estimator is a technically clean contribution.
major comments (2)
- [Section stating the decomposition and the three results] The Helmholtz-Hodge decomposition of the score error e = s_θ − ∇log p is applied on R^d (abstract and the section stating the three results) without any stated decay or integrability conditions at infinity. On unbounded domains the decomposition e = ∇ϕ + ∇×A is unique and the boundary terms vanish in ∫ div(p e) only under assumptions such as |e(x)| = o(1/|x|) or e belonging to a suitable weighted L² space; absent these, the solenoidal component can contribute to the marginal evolution and the impossibility result plus the tightened KL bound both fail.
- [Proof of the impossibility result] The impossibility result (that no monotone function of the L² error uniformly lower-bounds divergences) is load-bearing on the claim that the solenoidal component can be made arbitrarily large while leaving the marginal Fokker-Planck equation unchanged. The construction must explicitly verify that the chosen vector field satisfies the decay conditions needed for the decomposition to isolate a purely invisible solenoidal part; otherwise the counter-example is not rigorous.
minor comments (1)
- [Empirical evaluation of the estimator] The empirical section reports that the gradient-component estimator correlates substantially better with sample quality, but does not state the precise datasets, number of runs, or statistical tests used; adding these details would strengthen reproducibility without affecting the central claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the precise identification of the technical conditions required for the Helmholtz-Hodge decomposition on unbounded domains. We address both major comments below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: The Helmholtz-Hodge decomposition of the score error e = s_θ − ∇log p is applied on R^d (abstract and the section stating the three results) without any stated decay or integrability conditions at infinity. On unbounded domains the decomposition e = ∇ϕ + ∇×A is unique and the boundary terms vanish in ∫ div(p e) only under assumptions such as |e(x)| = o(1/|x|) or e belonging to a suitable weighted L² space; absent these, the solenoidal component can contribute to the marginal evolution and the impossibility result plus the tightened KL bound both fail.
Authors: We agree that explicit decay and integrability conditions are necessary for the uniqueness of the decomposition and the vanishing of boundary terms on R^d. In the revised manuscript we will add a new subsection (placed immediately before the three main results) that states the precise assumptions: the score error e belongs to a weighted L² space with weight (1+|x|)^{d+ε} for some ε>0, which implies |e(x)|=o(1/|x|) at infinity. Under these conditions the solenoidal component is divergence-free with respect to the weighted measure and does not enter the Fokker-Planck equation. We will also verify that all densities and score networks considered in the paper (smooth, sub-Gaussian tails) satisfy the required integrability, so the three results remain valid. These additions make the geometric argument fully rigorous. revision: yes
-
Referee: The impossibility result (that no monotone function of the L² error uniformly lower-bounds divergences) is load-bearing on the claim that the solenoidal component can be made arbitrarily large while leaving the marginal Fokker-Planck equation unchanged. The construction must explicitly verify that the chosen vector field satisfies the decay conditions needed for the decomposition to isolate a purely invisible solenoidal part; otherwise the counter-example is not rigorous.
Authors: We accept that the counter-example construction must be accompanied by an explicit verification of the decay conditions. In the revision we will replace the current sketch with a fully detailed construction: we take a compactly supported, divergence-free vector field A (hence e=∇×A) that is C^∞ and identically zero outside a large ball. Compact support immediately satisfies |e(x)|=o(1/|x|) and all weighted integrability requirements. We then show that the corresponding score perturbation leaves the marginal Fokker-Planck equation invariant while making the L² norm arbitrarily large. The revised proof will cite the new subsection on decay conditions to confirm that the decomposition isolates a purely solenoidal, invisible component. revision: yes
Circularity Check
No circularity: derivation relies on external mathematical identities
full rationale
The paper's central results—the impossibility theorem, the tightened KL bound, and the gradient-component estimator—are obtained by applying the standard Helmholtz-Hodge decomposition and a dual Sobolev identity to the score error vector field. These are external, well-known facts from vector calculus and functional analysis; the derivations do not reduce any claimed prediction or bound to a fitted parameter, a self-citation chain, or a quantity defined in terms of the target result. No load-bearing step is shown to be equivalent to its inputs by construction, and the manuscript does not invoke uniqueness theorems or ansatzes traceable only to the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Helmholtz-Hodge decomposition applies to score error vector fields and separates components with distinct effects on marginal dynamics
Reference graph
Works this paper leans on
-
[1]
Lectures in Mathematics ETH Zürich
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré.Gradient Flows in Metric Spaces and in the Space of Probability Measures. Lectures in Mathematics ETH Zürich. Birkhäuser, 2008
2008
-
[2]
Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
Brian DO Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
1982
-
[3]
Donald G. Aronson. Bounds for the fundamental solution of a parabolic equation.Bulletin of the American Mathematical Society, 73(6):890–896, 1967
1967
-
[4]
Donald G. Aronson. Non-negative solutions of linear parabolic equations.Annali della Scuola Normale Superiore di Pisa, 22(4):607–694, 1968
1968
-
[5]
A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem.Numerische Mathematik, 84:375–393, 2000
Jean-David Benamou and Yann Brenier. A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem.Numerische Mathematik, 84:375–393, 2000
2000
-
[6]
V . E. Beneš. Existence of optimal stochastic control laws.SIAM Journal on Control, 9(3):446– 472, 1971
1971
-
[7]
Nearly d-linear convergence bounds for diffusion models via stochastic localization
Joe Benton, Valentin De Bortoli, Arnaud Doucet, and George Deligiannidis. Nearly d-linear convergence bounds for diffusion models via stochastic localization. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
The Helmholtz- Hodge decomposition—a survey.IEEE Transactions on Visualization and Computer Graphics, 19(8):1386–1404, 2013
Harsh Bhatia, Gregory Norgard, Valerio Pascucci, and Peer-Timo Bremer. The Helmholtz- Hodge decomposition—a survey.IEEE Transactions on Visualization and Computer Graphics, 19(8):1386–1404, 2013
2013
-
[9]
Bogachev, Nicolai V
Vladimir I. Bogachev, Nicolai V . Krylov, Michael Röckner, and Stanislav V . Shaposhnikov. Fokker–Planck–Kolmogorov Equations, volume 207 ofMathematical Surveys and Monographs. American Mathematical Society, 2015
2015
-
[10]
Convergence of denoising diffusion models under the manifold hypothesis
Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis. Transactions on Machine Learning Research, 2022
2022
-
[11]
Springer, 2010
Haim Brezis.Functional Analysis, Sobolev Spaces and Partial Differential Equations. Springer, 2010
2010
-
[12]
R. H. Cameron and W. T. Martin. Transformations of weiner integrals under translations.Annals of Mathematics, 45(2):386–396, 1944
1944
-
[13]
Time reversal of diffusion processes under a finite entropy condition.Annales de l’Institut Henri Poincaré, Probabilités et Statistiques, 59(4):1844 – 1881, 2023
Patrick Cattiaux, Giovanni Conforti, Ivan Gentil, and Christian Léonard. Time reversal of diffusion processes under a finite entropy condition.Annales de l’Institut Henri Poincaré, Probabilités et Statistiques, 59(4):1844 – 1881, 2023
2023
-
[14]
On investigating the conservative property of score-based generative models
Chen-Hao Chao, Wei-Fang Sun, Bo-Wun Cheng, and Chun-Yi Lee. On investigating the conservative property of score-based generative models. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[15]
Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions
Hongrui Chen, Holden Lee, and Jianfeng Lu. Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. InProceedings of the 40th International Conference on Machine Learning, volume 202, 2023. 11
2023
-
[16]
Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data.40th International Conference on Machine Learning, ICML, 2023
Minshuo Chen, Kaixuan Huang, Tuo Zhao, and Mengdi Wang. Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data.40th International Conference on Machine Learning, ICML, 2023
2023
-
[17]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. International Conference on Learning Representations, 2023
2023
-
[18]
Springer, 2025
Sinho Chewi, Jonathan Niles-Weed, and Philippe Rigollet.Statistical optimal transport. Springer, 2025
2025
-
[19]
Perception prioritized training of diffusion models
Jooyoung Choi, Jungbeom Lee, Chaehun Shin, Sungwon Kim, Hyunwoo Kim, and Sungroh Yoon. Perception prioritized training of diffusion models. InInternational Conference on Computer Vision, 2022
2022
-
[20]
Doléans-Dade
C. Doléans-Dade. Quelques applications de la formule de changement de variables pour les semimartingales.Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, 16(3):181– 194, 1970
1970
- [21]
-
[22]
Springer Nature, 2021
Weinan E, Jiequn Han, and Arnulf Jentzen.Algorithms for Solving High Dimensional PDEs: From Nonlinear Monte Carlo to Machine Learning. Springer Nature, 2021
2021
-
[23]
H. Föllmer. An entropy approach to the time reversal of diffusion processes. InStochastic Differential Systems Filtering and Control. Springer Berlin Heidelberg, 1985
1985
-
[24]
Divergence-free diffusion models for incompressible fluid flows, 2026
Wilfried Genuist, Éric Savin, Filippo Gatti, and Didier Clouteau. Divergence-free diffusion models for incompressible fluid flows, 2026
2026
-
[25]
On transforming a certain class of stochastic processes by absolutely con- tinuous substitution of measures.Theory of Probability & Its Applications, 5(3):285–301, 1960
Igor V Girsanov. On transforming a certain class of stochastic processes by absolutely con- tinuous substitution of measures.Theory of Probability & Its Applications, 5(3):285–301, 1960
1960
-
[26]
Solving high-dimensional partial differential equations using deep learning.Proceedings of the National Academy of Sciences, 115(34):8505– 8510, 2018
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning.Proceedings of the National Academy of Sciences, 115(34):8505– 8510, 2018
2018
-
[27]
Maddix, Shima Alizadeh, Gaurav Gupta, and Michael W
Derek Hansen, Danielle C. Maddix, Shima Alizadeh, Gaurav Gupta, and Michael W. Mahoney. Learning physical models that can respect conservation laws. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[28]
U. G. Haussmann and E. Pardoux. Time Reversal of Diffusions.The Annals of Probability, 14(4), 1986
1986
-
[29]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017
2017
-
[30]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, 2020
2020
-
[31]
Multilayer feedforward networks are universal approximators.Neural Networks, 2, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural Networks, 2, 1989
1989
-
[32]
On gauge freedom, conservativity and intrinsic dimensionality estimation in diffusion models
Christian Horvat and Jean-Pascal Pfister. On gauge freedom, conservativity and intrinsic dimensionality estimation in diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005. 12
2005
-
[34]
Some extensions of score matching
Aapo Hyvärinen. Some extensions of score matching. InComputational Statistics & Data Analysis, pages 2499–2512. Elsevier, 2007
2007
-
[35]
The variational formulation of the fokker– planck equation.SIAM Journal on Mathematical Analysis, 29(1):1–17, 1998
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the fokker– planck equation.SIAM Journal on Mathematical Analysis, 29(1):1–17, 1998
1998
-
[36]
Springer, 2014
Ioannis Karatzas and Steven Shreve.Brownian motion and stochastic calculus. Springer, 2014
2014
-
[37]
Quantifying Error Propagation and Model Collapse in Diffusion Models
Nail B. Khelifa, Richard E. Turner, and Ramji Venkataramanan. Quantifying error propagation and model collapse in diffusion models, 2026. arXiv:2602.16601
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Understanding diffusion objectives as the ELBO with simple data augmentation
Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[39]
Variational diffusion models
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. In Advances in neural information processing systems, 2021
2021
-
[40]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.CoRR, 2014
2014
-
[41]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical Report 0, University of Toronto, 2009
2009
-
[42]
Springer Publishing Company, Incorporated, 2018
Jean-Francois Le Gall.Brownian Motion, Martingales, and Stochastic Calculus. Springer Publishing Company, Incorporated, 2018
2018
-
[43]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11), 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11), 1998
1998
-
[44]
A tutorial on energy-based learning.Predicting Structured Data, 1(0), 2006
Yann LeCun, Sumit Chopra, Raia Hadsell, Marc’Aurelio Ranzato, and Fu Jie Huang. A tutorial on energy-based learning.Predicting Structured Data, 1(0), 2006
2006
-
[45]
Beta Sampling is All You Need: Efficient Image Generation Strategy for Diffusion Models Using Stepwise Spectral Analysis
Haeil Lee, Hansang Lee, Seoyeon Gye, and Junmo Kim. Beta Sampling is All You Need: Efficient Image Generation Strategy for Diffusion Models Using Stepwise Spectral Analysis. In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[46]
Convergence for score-based generative modeling with polynomial complexity
Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence for score-based generative modeling with polynomial complexity. InProceedings of the 36th International Conference on Neural Information Processing Systems, 2022
2022
-
[47]
Rebecca M. Lewis, Oliver Y . Feng, Henry W. J. Reeve, Min Xu, and Richard J. Samworth. Learning the score under shape constraints, 2025. arXiv:2512.14624
-
[48]
Project and generate: Divergence-free neural operators for incompress- ible flows, 2026
Xigui Li, Hongwei Zhang, Ruoxi Jiang, Deshu Chen, Chensen Lin, Limei Han, Yuan Qi, Xin Guo, and Yuan Cheng. Project and generate: Divergence-free neural operators for incompress- ible flows, 2026. arXiv:2603.24500
-
[49]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[50]
The expressive power of neural networks: A view from the width
Zhou Lu, Hongming Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. The expressive power of neural networks: A view from the width. InAdvances in neural information processing systems, 2017
2017
-
[51]
A. A. Novikov. On an identity for stochastic integrals.Theory of Probability & Its Applications, 17(4):717–720, 1973
1973
-
[52]
Diffusion models are minimax optimal distribution estimators.International Conference on Machine Learning, 2023
Kazusato Oko, Shunta Akiyama, and Taiji Suzuki. Diffusion models are minimax optimal distribution estimators.International Conference on Machine Learning, 2023
2023
-
[53]
The geometry of dissipative evolution equations: The porous medium equation
Felix Otto. The geometry of dissipative evolution equations: The porous medium equation. Communications in Partial Differential Equations, 26(1-2):101–174, 2001
2001
-
[54]
Pavliotis.Stochastic Processes and Applications: Diffusion Processes, the Fokker- Planck and Langevin Equations
Grigorios A. Pavliotis.Stochastic Processes and Applications: Diffusion Processes, the Fokker- Planck and Langevin Equations. Springer, New York, NY , 2014. 13
2014
-
[55]
Peebles and Saining Xie
William S. Peebles and Saining Xie. Scalable diffusion models with transformers.2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2022
2023
-
[56]
Score-based generative models detect manifolds
Jakiw Pidstrigach. Score-based generative models detect manifolds. InProceedings of the 36th International Conference on Neural Information Processing Systems, 2022
2022
-
[57]
Jack Richter-Powell, Yaron Lipman, and Ricky T. Q. Chen. Neural conservation laws: A divergence-free perspective. InAdvances in Neural Information Processing Systems, 2022
2022
-
[58]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, 2015
2015
-
[59]
Should EBMs model the energy or the score? InEnergy Based Models Workshop - ICLR 2021, 2021
Tim Salimans and Jonathan Ho. Should EBMs model the energy or the score? InEnergy Based Models Workshop - ICLR 2021, 2021
2021
-
[60]
Optimal Transport for Applied Mathematicians
Filippo Santambrogio. Optimal Transport for Applied Mathematicians. Calculus of Variations, PDEs and Modeling.Progress in Nonlinear Differential Equations and Their Applications, 1(87), 2015
2015
-
[61]
On approximating∇fwith neural networks, 2019
Saeed Saremi. On approximating∇fwith neural networks, 2019. arXiv:1910.12744
-
[62]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InProceedings of the 32nd International Conference on Machine Learning, 2015
2015
-
[63]
Maximum likelihood training of score-based diffusion models
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. InProceedings of the 35th International Conference on Neural Information Processing Systems, 2021
2021
-
[64]
Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[65]
Sliced score matching: A scalable approach to density and score estimation
Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. InProceedings of The 35th Uncertainty in Artificial Intelligence Conference, Proceedings of Machine Learning Research, 2020
2020
-
[66]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[67]
Stroock and S
Daniel W. Stroock and S. R. Srinivasa Varadhan.Multidimensional Diffusion Processes, volume 233 ofGrundlehren der mathematischen Wissenschaften. Springer, 1979
1979
-
[68]
Efficient diffusion training via min-snr weighting strategy
Hang Tiankai, Shuyang Gu, Chen Li, Jianmin Bao, Dong Chen, Han Hu, Xin Geng, and Baining Guo. Efficient diffusion training via min-snr weighting strategy. InInternational Conference on Computer Vision, 2023
2023
-
[69]
Learning flow distributions via projection- constrained diffusion on manifolds, 2026
Noah Trupin, Rahul Ghosh, and Aadi Jangid. Learning flow distributions via projection- constrained diffusion on manifolds, 2026. arXiv:2602.17773
-
[70]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural information processing systems, 2017
2017
-
[71]
Springer, 2009
Cédric Villani.Optimal transport: old and new, volume 338. Springer, 2009
2009
-
[72]
A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
2011
-
[73]
Santos, and Yen Ting Lin
An Vuong, Michael Thompson McCann, Javier E. Santos, and Yen Ting Lin. Are we really learning the score function? Reinterpreting diffusion models through Wasserstein gradient flow matching.Transactions on Machine Learning Research, 2025. 14
2025
-
[74]
An analytical theory of spectral bias in the learning dynamics of diffusion models
Binxu Wang and Cengiz Pehlevan. An analytical theory of spectral bias in the learning dynamics of diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[75]
Optimal score estimation via empirical Bayes smoothing
Andre Wibisono, Yihong Wu, and Kaylee Yingxi Yang. Optimal score estimation via empirical Bayes smoothing. InThe Thirty Seventh Annual Conference on Learning Theory, pages 4958–4991, 2024
2024
-
[76]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms, 2017. arXiv:1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
Yin, Feng Liang, and Jingbo Liu
Kaihong Zhang, Caitlyn H. Yin, Feng Liang, and Jingbo Liu. Minimax optimality of score-based diffusion models: beyond the density lower bound assumptions. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[78]
Z T t0 σs es ·d ¯BP⋆ s # + 1 2 EP⋆
Pengze Zhang, Hubery Yin, Chen Li, and Xiaohua Xie. Tackling the singularities at the endpoints of time intervals in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 15 A Proofs of Main Results A.1 Proof of Theorem 3.1 Proof. Proof of (i): Recall that the score estimation error fielde s is...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.