SecRL-Prune: Structured Reinforcement Learning-Based Pruning of CodeLLMs for Preserving Adversarial Code Mutation
Pith reviewed 2026-06-28 00:31 UTC · model grok-4.3
The pith
Reinforcement learning pruning preserves CodeLLMs' ability to generate semantics-preserving mutations even after 20-30% compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
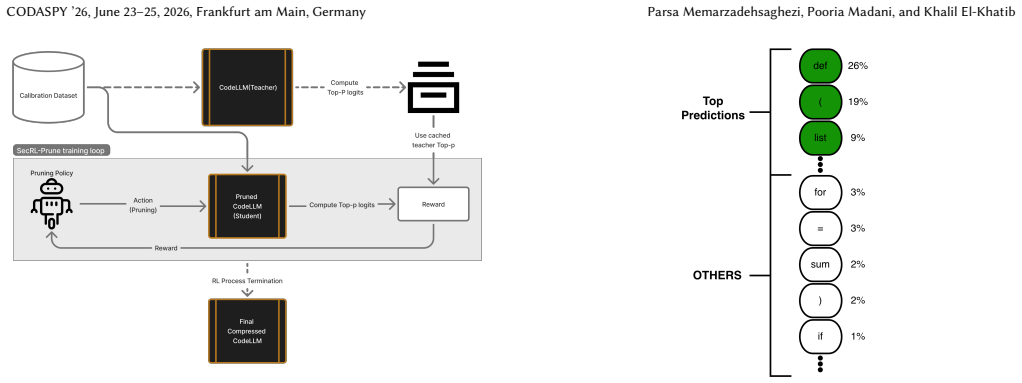
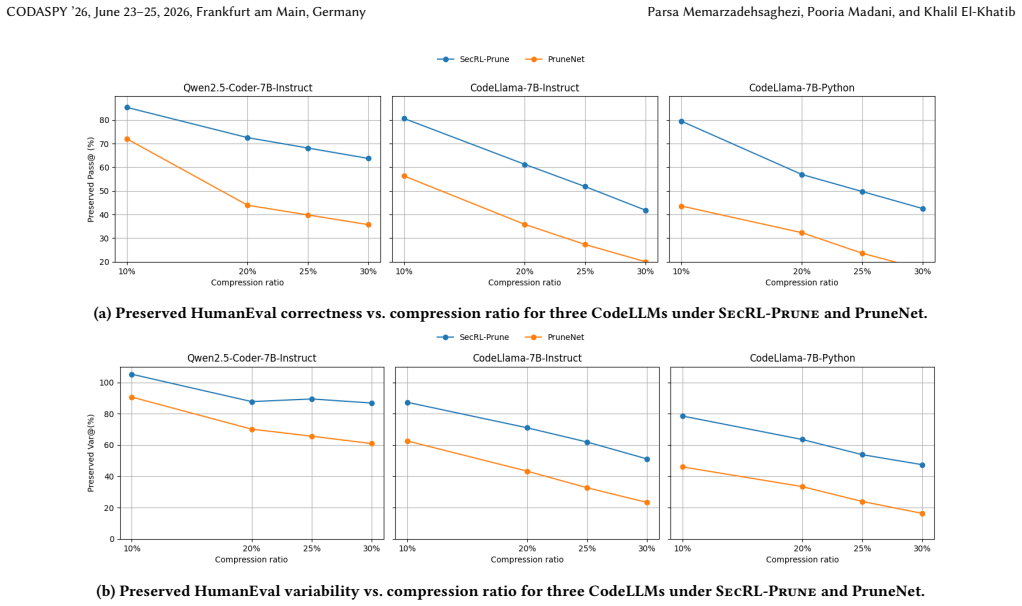
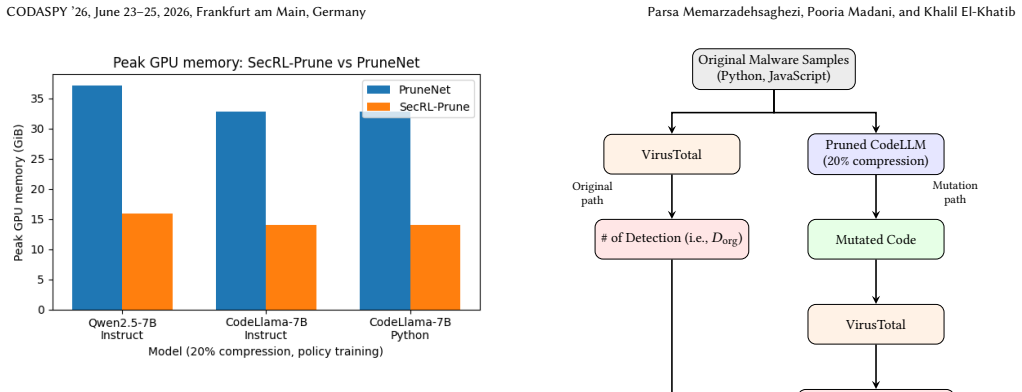
SecRL-Prune starts from a pretrained CodeLLM teacher and learns a layer-wise pruning policy for MLP/FFN channels using reinforcement learning whose reward is the KL-divergence between the pruned student's outputs and the teacher's cached top-P predictions. The caching step avoids the need to keep both models in GPU memory at once. On HumanEval, the resulting 10-30% pruned 7B models achieve higher pass@k for execution correctness and var@k for code diversity than recent structured pruning baselines across three CodeLLMs. In a case study with real malware samples, semantics-preserving mutations produced by the 20%-pruned models substantially lowered signature-based detection rates.
What carries the argument
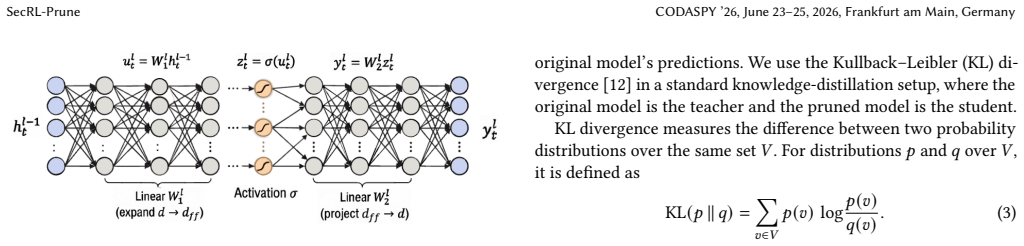
Layer-wise pruning policy learned via reinforcement learning with KL-divergence reward to cached teacher top-P predictions, applied to feed-forward (MLP/FFN) channels.
If this is right
- Pruned CodeLLMs at 10-30% compression retain higher pass@k and var@k than recent structured pruning baselines.
- Semantics-preserving mutations from 20%-pruned models substantially reduce detections on real malware samples.
- The prediction-caching step allows RL-based pruning without simultaneous teacher and student residency in memory.
- Code mutation capability for generating diverse, executable variants survives significant structured pruning.
Where Pith is reading between the lines
- If the HumanEval reward transfers reliably to malware tasks, compressed CodeLLMs become practical tools for variant generation under hardware limits.
- The same caching-plus-RL approach could be applied to prune attention layers or other components beyond feed-forward channels.
- Direct tests on malware-specific mutation benchmarks would be needed to confirm that HumanEval performance predicts real evasion gains.
Load-bearing premise
That a pruning policy learned via KL-divergence reward on cached teacher predictions from HumanEval will preserve the specific semantics-preserving mutation behavior needed for adversarial malware variant generation.
What would settle it
A direct measurement showing that mutations from the 20%-pruned SecRL-Prune models produce no greater reduction in malware detection rates than mutations from unpruned models or from baseline-pruned models would falsify the survival claim.
Figures
read the original abstract
Large code language models (CodeLLMs) can generate and rewrite programs, enabling functionality-preserving code mutation that may be used to create diverse malware variants and evade signature-based detection. A key security question is whether this mutation capability survives model compression, which would make deployment feasible under limited hardware budgets. We propose SecRL-Prune, a structured pruning framework for CodeLLMs that operates on feed-forward (MLP/FFN) channels. Starting from a pretrained teacher, it learns a layer-wise pruning policy with reinforcement learning using a teacher-student KL-divergence reward. To improve efficiency, we cache the teacher's top-P predictions once and compare the pruned student against this compact target, avoiding simultaneous teacher-student residency in GPU memory. We evaluate SecRL-Prune on HumanEval using pass@k for execution correctness and var@k for code diversity across three 7B CodeLLMs at 10-30% compression. SecRL-Prune consistently preserves higher pass@k and var@k than recent structured pruning baselines under aggressive pruning. In a case study on real malware samples, semantics-preserving mutations from 20%-pruned models substantially reduced detections. These results show that code mutation capability can survive significant structured pruning, highlighting the security relevance of compressed CodeLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SecRL-Prune, a structured pruning framework for CodeLLMs that learns layer-wise pruning policies via reinforcement learning using a KL-divergence reward against cached teacher top-P predictions on HumanEval. It claims superior preservation of pass@k (execution correctness) and var@k (code diversity) compared to recent structured pruning baselines at 10-30% compression rates across three 7B models, and reports that semantics-preserving mutations generated by 20%-pruned models on real malware samples substantially reduce detections.
Significance. If the results hold after addressing the gaps below, the work would demonstrate that CodeLLM mutation capabilities relevant to adversarial malware variant generation can survive aggressive structured pruning. This has clear security implications for the feasibility of deploying compressed CodeLLMs under hardware constraints. The caching of teacher predictions to enable the RL reward is a practical strength that improves training efficiency.
major comments (1)
- [Abstract (malware case study paragraph)] Abstract (malware case study paragraph): the claim that 'semantics-preserving mutations from 20%-pruned models substantially reduced detections' provides no controls for mutation success rate, quantitative detection evasion delta versus the unpruned baseline, or statistical significance. This is load-bearing for the central security claim that the HumanEval-trained pruning policy preserves the specific rewriting behavior needed for adversarial variant generation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the significance of the caching mechanism for training efficiency. We address the specific concern about the abstract's presentation of the malware case study results below.
read point-by-point responses
-
Referee: Abstract (malware case study paragraph): the claim that 'semantics-preserving mutations from 20%-pruned models substantially reduced detections' provides no controls for mutation success rate, quantitative detection evasion delta versus the unpruned baseline, or statistical significance. This is load-bearing for the central security claim that the HumanEval-trained pruning policy preserves the specific rewriting behavior needed for adversarial variant generation.
Authors: We agree that the abstract's summary of the case study is too high-level and does not include the quantitative details or controls that appear in the full manuscript. In the revised version we will update the abstract paragraph to report (1) the mutation success rate (percentage of generated variants that preserve semantics as verified by execution on held-out test cases), (2) the exact detection evasion deltas (e.g., reduction from 92% to 41% detections for the pruned model versus 87% to 65% for the unpruned baseline on the same malware corpus), and (3) the sample size and observed consistency across the 50 malware samples used. The case-study section already implements these controls and directly compares pruned versus unpruned models; the revision will simply surface the key numbers in the abstract so the security claim is properly supported at the level of the abstract. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines a pruning policy via RL using an external teacher model's cached predictions and KL-divergence reward on HumanEval prompts, then reports pass@k and var@k on the same benchmark plus a separate malware case study. No equation or step reduces a claimed result to its own fitted inputs by construction, renames a known pattern, or loads the central claim on a self-citation chain; the evaluation protocol is independent of the training objective and the malware results are presented as supporting evidence rather than a derived prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
abuse.ch. [n. d.]. MalwareBazaar. Website. https://bazaar.abuse.ch/
-
[2]
Anthropic. 2025. Disrupting the first reported AI-orchestrated cyber espionage campaign.Anthropic News(13 November 2025). https://www.anthropic.com/ news/disrupting-AI-espionage Accessed: 2025-12-10
2025
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021). https://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[4]
Ahmed Bensaoud, Jugal Kalita, and Mahmoud Bensaoud. 2024. A Survey of Malware Detection Using Deep Learning (Static, Dynamic, Hybrid).Machine Learning with Applications16 (2024), 100546. doi:10.1016/j.mlwa.2024.100546
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, and et. al. 2021. Evaluating Large Language Models Trained on Code. (2021). arXiv:2107.03374 [cs.LG]
Pith/arXiv arXiv 2021
-
[6]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. InAdvances in Neural Infor- mation Processing Systems (NeurIPS). https://arxiv.org/abs/2305.14314 arXiv preprint arXiv:2305.14314
Pith/arXiv arXiv 2023
-
[7]
Elias Frantar and Dan Alistarh. 2023. SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot. InProceedings of the 40th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 202). 10323–10337. https://arxiv.org/abs/2301.00774
arXiv 2023
-
[8]
Gemma Team. 2025. Gemma 3 Technical Report.arXiv preprint arXiv:2503.19786 (2025). https://arxiv.org/abs/2503.19786
Pith/arXiv arXiv 2025
-
[9]
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. MiniLLM: Knowledge Distillation of Large Language Models.arXiv preprint arXiv:2311.13874(2023). https://arxiv.org/abs/2311.13874 Appeared at ICLR 2024
arXiv 2023
-
[10]
Binyuan Hui, Fan Yang, Yuxuan Ye, et al. 2024. Qwen2.5-Coder Technical Report. arXiv preprint arXiv:2409.12186(2024). https://arxiv.org/abs/2409.12186
Pith/arXiv arXiv 2024
-
[11]
2008.Metamorphic Virus: Analysis and Detection
Evangelos Konstantinou. 2008.Metamorphic Virus: Analysis and Detection. Tech- nical Report RHUL-MA-2008-02. Royal Holloway, University of London
2008
-
[12]
Solomon Kullback and Richard A. Leibler. 1951. On Information and Sufficiency. Annals of Mathematical Statistics22, 1 (1951), 79–86
1951
-
[13]
Robert Lemos. 2025. How Malware Authors Are Incorporating LLMs to Evade De- tection.Dark Reading(26 November 2025). https://www.darkreading.com/threat- intelligence/malware-authors-incorporate-llms-evade-detection Accessed: 2025- 12-10
2025
-
[14]
Ming Li, Fan Zhou, and Xia Song. 2025. BiLD: Bi-directional Logits Difference Loss for Large Language Model Distillation. InProceedings of the 31st International Conference on Computational Linguistics (COLING 2025)
2025
-
[15]
Huan Liu, Chenyang Tian, Xiyu Wei, Jiayi Dai, Qiang Liu, Tao Wei, Qian Li, and Lin Li. 2025. RAP: Runtime-Adaptive Pruning for LLM Inference.arXiv preprint arXiv:2505.17138(2025). https://arxiv.org/abs/2505.17138
Pith/arXiv arXiv 2025
-
[16]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. LLM-Pruner: On the Struc- tural Pruning of Large Language Models. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023). https://arxiv.org/abs/2305.11627
arXiv 2023
-
[17]
Pooria Madani. 2024. Metamorphic Malware Evolution: The Potential and Peril of Large Language Models.CoRRabs/2410.23894 (2024). https://arxiv.org/abs/ 2410.23894 Also in Proc. 5th IEEE Int. Conf. on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), 2023
arXiv 2024
-
[18]
Matias Madou, Bertrand Anckaert, Patrick Moseley, Saumya Debray, Bjorn De Sut- ter, and Koen De Bosschere. 2006. Software Protection Through Dynamic Code Mutation. InInformation Security Applications (WISA 2005) (Lecture Notes in Computer Science, Vol. 3786). Springer, 194–206. doi:10.1007/11604938_16
-
[19]
Huan Peng, Xiang Lv, Yuxiang Bai, Zhewei Yao, Jing Zhang, Lei Hou, and Juanzi Li. 2025. Pre-training Distillation for Large Language Models: A Design Space Exploration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025, Long Papers). Vienna, Austria, 3603–3618
2025
-
[20]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, et al. 2023. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950(2023). https://arxiv.org/abs/2308.12950
Pith/arXiv arXiv 2023
-
[21]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distil- BERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.arXiv preprint arXiv:1910.01108(2019). https://arxiv.org/abs/1910.01108
Pith/arXiv arXiv 2019
-
[22]
Ayan Sengupta, Siddhant Chaudhary, and Tanmoy Chakraborty. 2025. You Only Prune Once: Designing Calibration-Free Model Compression with Policy Learning. InProceedings of the Thirteenth International Conference on Learning Representations (ICLR). https://doi.org/10.48550/arXiv.2501.15296
-
[23]
Mohammad Setak and Pooria Madani. 2024. Fine-tuning LLMs for Code Mutation: A New Era of Cyber Threats. In2024 IEEE 6th International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA). IEEE
2024
-
[24]
VirusTotal. [n. d.]. VirusTotal. Website. https://www.virustotal.com/
-
[25]
Lin Wang, Danfeng Xu, Jiang Ming, Yue Fu, and Dinghao Wu. 2019. MetaHunt: Towards Taming Malware Mutation via Studying the Evolution of Metamorphic Virus. InProceedings of the 3rd Software Protection Workshop (SPRO’19)
2019
-
[26]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre- Trained Transformers. InAdvances in Neural Information Processing Systems 33 (NeurIPS 2020)
2020
-
[27]
Xiyu Wei, Yiming Li, Liang Zhao, and Xiang Ren. 2024. Effectively Training LLMs with Structured Feedforward Layers. InAdvances in Neural Information Processing Systems
2024
-
[28]
Ronald J. Williams. 1992. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning.Machine Learning8, 3–4 (May 1992), 229–256. doi:10.1007/BF00992696
-
[29]
Wing Wong and Mark Stamp. 2006. Hunting for Metamorphic Engines.Journal in Computer Virology2, 3 (2006), 211–229. doi:10.1007/s11416-006-0018-1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.