FOXGLOVE: Understanding Goal-Oriented and Anchored Writing Feedback from Experts and LLMs on Argumentative Essays
Pith reviewed 2026-06-28 01:41 UTC · model grok-4.3
The pith
Instructors and LLMs distribute feedback similarly across goals and essay positions but diverge on the specific sentences targeted and on feedback style.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
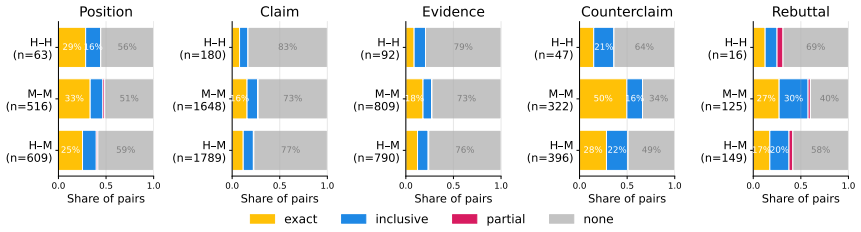
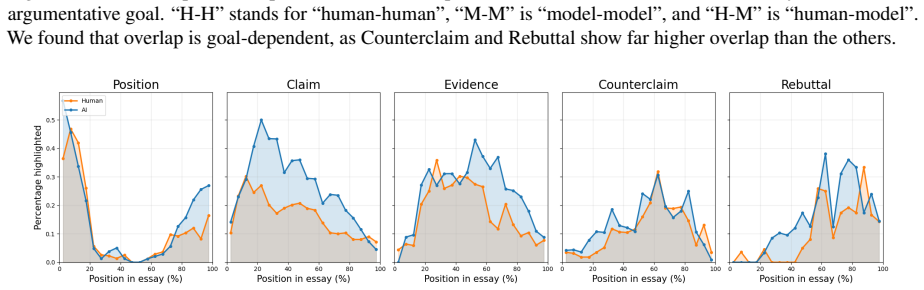
Using the FOXGLOVE dataset of paired expert and LLM feedback, the authors establish that while human instructors and frontier LLMs allocate feedback comments similarly across writing goals and positions in the essay, they select different individual sentences for commentary. Models generate more complex comments and ask fewer questions, and their feedback scores higher on quality ratings from instructors, an advantage largely explained by greater comment length.
What carries the argument
The FOXGLOVE dataset of goal-oriented and anchored feedback comments, used to compare distribution, specificity, complexity, and quality between instructors and LLMs.
If this is right
- Feedback systems can use LLMs to cover similar goal distributions as humans.
- Anchoring remains a point of divergence requiring human oversight or better prompting.
- LLM comments tend toward greater complexity and fewer questions than instructor comments.
- Quality advantages of LLM feedback largely trace to comment length rather than other factors.
Where Pith is reading between the lines
- Future tools might combine LLM volume with human precision on sentence selection.
- Length as a quality factor suggests prompts could be adjusted to match human brevity if desired.
- This comparison framework could extend to other writing genres or feedback types.
Load-bearing premise
The shared prompting protocol creates LLM feedback that is comparable in intent and utility to feedback from trained instructors.
What would settle it
A study measuring actual student revision outcomes after receiving instructor versus LLM feedback would show whether the quality ratings translate to better revisions.
Figures



read the original abstract
While large language models (LLMs) are increasingly used to generate writing feedback, there remains no systematic comparison of LLM and expert feedback on the dimensions that writing research identifies as central to revision: goal-orientation, anchoring to specific sentences, and prioritization. We introduce FOXGLOVE, a dataset of 696 feedback comments written by trained writing instructors on 69 twelfth-grade argumentative essays, paired with 1,644 comments generated from four frontier LLMs under a shared protocol, totaling 2,340 comments. We provide expert quality ratings on a subset of both instructor and LLM comments. We find that instructors and LLMs distribute feedback similarly across goals and essay positions, yet instructors and models diverge on the specific sentences on which to provide feedback. Additionally, we find that models tend to write more complex feedback and use fewer questions than instructors. LLM feedback also receives higher ratings on most dimensions of quality, as rated by instructors, but much of this advantage appears to be attributable to lengthier comments. FOXGLOVE enables systematic comparison of where human and LLM feedback align, diverge, and differ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the FOXGLOVE dataset comprising 696 feedback comments from trained writing instructors on 69 twelfth-grade argumentative essays, paired with 1,644 comments generated by four frontier LLMs under a shared prompting protocol. It reports that instructors and LLMs show similar distributions of feedback across goals and essay positions but diverge on the specific sentences targeted; LLMs produce more complex feedback with fewer questions; and LLM comments receive higher instructor ratings on most quality dimensions, though much of this is linked to greater comment length.
Significance. If the central empirical comparisons hold after addressing methodological gaps, the dataset offers a reusable benchmark for systematic analysis of goal-oriented and anchored feedback, enabling targeted improvements in LLM writing assistants for education. The work's strength lies in its focus on revision-relevant dimensions (goals, anchoring, prioritization) drawn from writing research rather than generic metrics.
major comments (2)
- [Methods (prompting protocol)] Methods section on data collection and prompting: The shared protocol for LLM comment generation is presented without evidence of derivation from or validation against actual instructor rubrics, workflows, or revision goals used by the human experts. This is load-bearing for the central claim of meaningful comparability, as unvalidated prompt structures (e.g., explicit goal lists or sentence-level instructions) could artifactually produce the reported aggregate similarities while driving the observed divergences in specific anchors.
- [Results (quality analysis)] Results section on quality ratings: Claims that LLM feedback receives higher ratings on most quality dimensions are presented without statistical tests for significance, inter-rater reliability coefficients, sample-size justification for the rated subset, or explicit controls for length beyond the acknowledgment that length contributes to the advantage. These omissions weaken support for the quality comparison as a core finding.
minor comments (1)
- [Abstract] Abstract and introduction: The total comment counts (696 + 1,644) and essay count (69) are stated clearly, but the abstract could briefly note the number of raters or rating dimensions to improve standalone readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key opportunities to improve methodological transparency and statistical support. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods (prompting protocol)] Methods section on data collection and prompting: The shared protocol for LLM comment generation is presented without evidence of derivation from or validation against actual instructor rubrics, workflows, or revision goals used by the human experts. This is load-bearing for the central claim of meaningful comparability, as unvalidated prompt structures (e.g., explicit goal lists or sentence-level instructions) could artifactually produce the reported aggregate similarities while driving the observed divergences in specific anchors.
Authors: The prompting protocol was constructed from writing research on goal-oriented and anchored feedback to enable a standardized, comparable generation process across models. It was not derived from or validated against the specific rubrics or workflows of the participating instructors, as the study design prioritizes a general benchmark rather than instructor-specific replication. We agree this limits strong claims of equivalence and will revise the Methods section to detail the protocol's grounding in prior literature, append the full prompts, and explicitly discuss this as a limitation affecting interpretation of divergences in anchoring. revision: partial
-
Referee: [Results (quality analysis)] Results section on quality ratings: Claims that LLM feedback receives higher ratings on most quality dimensions are presented without statistical tests for significance, inter-rater reliability coefficients, sample-size justification for the rated subset, or explicit controls for length beyond the acknowledgment that length contributes to the advantage. These omissions weaken support for the quality comparison as a core finding.
Authors: We accept that the quality analysis requires additional statistical detail. In revision we will add significance tests for rating differences, report inter-rater reliability (or clarify the single-rater process if applicable), justify the rated subset size, and include explicit length-controlled analyses (e.g., regression or matched comparisons). These changes will be incorporated without altering the existing observation that length explains much of the advantage. revision: yes
Circularity Check
No circularity: purely empirical dataset comparison with no derivations or self-referential claims
full rationale
The paper collects instructor feedback, generates LLM feedback under a shared protocol, rates subsets, and compares distributions of goals, anchoring, complexity, and quality. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described structure. All claims reduce to direct measurement rather than any definitional or citation-based reduction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Allen, Zack van and Forgues-Martel, Sylvie and Venables, Maddie J. and Ghanney, Yosr and Villeneuve, Alexandre and Dongmo, Jarvis and Ahmed, Meherin and Archibald, Douglas and Jolin-Dahel, Kheira , month = mar, year =. Can. doi:10.64898/2026.03.04.26346878 , abstract =
-
[2]
Behzad, Shabnam and Kashefi, Omid and Somasundaran, Swapna , editor =. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.naacl-short.36 , abstract =
-
[3]
Assessing
Behzad, Shabnam and Kashefi, Omid and Somasundaran, Swapna , editor =. Assessing. Proceedings of the 2024. 2024 , pages =
2024
-
[4]
Beyond Excess and Deficiency: Adaptive Length Bias Mitigation in Reward Models for RLHF
Bu, Yuyan and Huo, Liangyu and Jing, Yi and Yang, Qing. Beyond Excess and Deficiency: Adaptive Length Bias Mitigation in Reward Models for RLHF. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.169
-
[5]
and Dale, E
Chall, J.S. and Dale, E. , year =. Readability
-
[6]
doi:10.1002/j.2333-8504.2004.tb01931.x , abstract =
ETS Research Report Series , author =. doi:10.1002/j.2333-8504.2004.tb01931.x , abstract =
-
[7]
and Trevor, Jonathan and Bly, Sara and Nelson, Les and Cubranic, Davor , month = apr, year =
Churchill, Elizabeth F. and Trevor, Jonathan and Bly, Sara and Nelson, Les and Cubranic, Davor , month = apr, year =. Anchored conversations: chatting in the context of a document , isbn =. Proceedings of the. doi:10.1145/332040.332475 , language =
-
[8]
Annotating Errors in English Learners' Written Language Production: Advancing Automated Written Feedback Systems
Coyne, Steven and Galvan-Sosa, Diana and Spring, Ryan and Guerraoui, Cam \'e lia and Zock, Michael and Sakaguchi, Keisuke and Inui, Kentaro. Annotating Errors in English Learners' Written Language Production: Advancing Automated Written Feedback Systems. Artificial Intelligence in Education. 2025
2025
-
[9]
A large-scale corpus for assessing written argumentation:. Assessing Writing , author =. 2024 , pages =. doi:10.1016/j.asw.2024.100865 , abstract =
-
[10]
Fine-Grained Analysis of Propaganda in News Articles
Da San Martino, Giovanni and Yu, Seunghak and Barr \'o n-Cede \ n o, Alberto and Petrov, Rostislav and Nakov, Preslav. Fine-Grained Analysis of Propaganda in News Articles. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. d...
-
[11]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Dubois, Yann and Galambosi, Balázs and Liang, Percy and Hashimoto, Tatsunori B. , month = mar, year =. Length-. doi:10.48550/arXiv.2404.04475 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.04475
-
[12]
A new readability yardstick. , volume=. Journal of Applied Psychology , author=. 1948 , pages=. doi:https://doi.org/10.1037/h0057532 , number=
-
[13]
College Composition and Communication , author =
A. College Composition and Communication , author =. 1981 , note =. doi:10.2307/356600 , number =
-
[14]
XDAC : XAI -Driven Detection and Attribution of LLM -Generated News Comments in K orean
Go, Wooyoung and Kim, Hyoungshick and Oh, Alice and Kim, Yongdae. XDAC : XAI -Driven Detection and Attribution of LLM -Generated News Comments in K orean. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1108
-
[15]
Guerraoui, Camelia and Reisert, Paul and Inoue, Naoya and Mim, Farjana Sultana and Singh, Keshav and Choi, Jungmin and Robbani, Irfan and Naito, Shoichi and Wang, Wenzhi and Inui, Kentaro , editor =. Teach. Proceedings of the 10th. 2023 , pages =. doi:10.18653/v1/2023.argmining-1.3 , abstract =
-
[16]
Zyska, Dennis and Rozovskaya, Alla and Kuznetsov, Ilia and Gurevych, Iryna , year =. Exposía:. doi:10.48550/ARXIV.2601.06536 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.06536
-
[17]
What do they mean? Questions in academic writing , pages =
Ken Hyland , url =. What do they mean? Questions in academic writing , pages =. Text & Talk , doi =
-
[18]
Discourse Studies , volume =
Ken Hyland , title =. Discourse Studies , volume =. 2005 , doi =
2005
-
[19]
Jiang, Feng Kevin and Hyland, Ken , journal =. Does. 2025 , doi =
2025
-
[20]
Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =
Afrin, Tazin and Kashefi, Omid and Olshefski, Christopher and Litman, Diane and Hwa, Rebecca and Godley, Amanda , title =. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =. 2021 , isbn =. doi:10.1145/3411764.3445683 , abstract =
-
[21]
2025 , url =
Khan Academy Annual Report:. 2025 , url =
2025
-
[22]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[23]
Weixin Liang and Yuhui Zhang and Hancheng Cao and Binglu Wang and Daisy Yi Ding and Xinyu Yang and Kailas Vodrahalli and Siyu He and Daniel Scott Smith and Yian Yin and Daniel A. McFarland and James Zou , title =. NEJM AI , volume =. 2024 , doi =. https://ai.nejm.org/doi/pdf/10.1056/AIoa2400196 , abstract =
-
[24]
Liu, Suqing and Simion, Bogdan and Eaton, Christopher and Liut, Michael , month = dec, year =. A. doi:10.48550/arXiv.2601.11541 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.11541
-
[25]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =
Liu, Yijun and Gallagher, John and Sterman, Sarah and August, Tal , title =. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =. 2026 , isbn =. doi:10.1145/3772318.3790292 , abstract =
-
[26]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =
Lu, Xinyi and Phyllis Ju, Kexin and Dudley, Mitchell and Sano, Larissa and Wang, Xu , title =. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =. 2026 , isbn =. doi:10.1145/3772318.3791121 , abstract =
-
[27]
Mah, Christopher and Tan, Mei and Phalen, Lena and Sparks, Alexa and Demszky, Dorottya , note =. From. 2025 , shorttitle =. doi:10.26300/P397-2P46 , abstract =
-
[28]
Liebenow and Marlene Steinbach and Andrea Horbach and Johanna Fleckenstein , keywords =
Jennifer Meyer and Thorben Jansen and Ronja Schiller and Lucas W. Liebenow and Marlene Steinbach and Andrea Horbach and Johanna Fleckenstein , keywords =. Using LLMs to bring evidence-based feedback into the classroom: AI-generated feedback increases secondary students’ text revision, motivation, and positive emotions , journal =. 2024 , issn =. doi:https...
-
[29]
IEEE Access , author =. 2026 , keywords =. doi:10.1109/ACCESS.2025.3646052 , abstract =
-
[30]
Computers and Education Open , author =
Enhancing active learning through collaboration between human teachers and generative. Computers and Education Open , author =. 2024 , pages =. doi:10.1016/j.caeo.2024.100183 , abstract =
-
[31]
Pilan, Ildiko and Lee, John and Yeung, Chak Yan and Webster, Jonathan , editor =. A. Proceedings of the. 2020 , pages =
2020
-
[32]
Help Me Write a Story: Evaluating LLM s' Ability to Generate Writing Feedback
Rashkin, Hannah and Clark, Elizabeth and Huot, Fantine and Lapata, Mirella. Help Me Write a Story: Evaluating LLM s' Ability to Generate Writing Feedback. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1254
-
[33]
Sap, Maarten and Gabriel, Saadia and Qin, Lianhui and Jurafsky, Dan and Smith, Noah A. and Choi, Yejin. Social Bias Frames: Reasoning about Social and Power Implications of Language. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.486
-
[34]
Review of educational research , volume=
Focus on formative feedback , author=. Review of educational research , volume=. 2008 , publisher=
2008
-
[35]
Responding to Student Writing , urldate =
Nancy Sommers , journal =. Responding to Student Writing , urldate =
-
[36]
Learning and Instruction , author =
Comparing the quality of human and. Learning and Instruction , author =. 2024 , pages =. doi:10.1016/j.learninstruc.2024.101894 , abstract =
-
[37]
American Educational Research Journal , volume=
How readability factors are differentially associated with performance for students of different backgrounds when solving mathematics word problems , author=. American Educational Research Journal , volume=. 2018 , publisher=
2018
-
[38]
Wang, Zhengxiang and Makarova, Veronika and Li, Zhi and Kodner, Jordan and Rambow, Owen. LLM s can Perform Multi-Dimensional Analytic Writing Assessments: A Case Study of L 2 Graduate-Level Academic E nglish Writing. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025....
-
[39]
Weng, Chunhua and Gennari, John H. , month = nov, year =. Asynchronous collaborative writing through annotations , isbn =. Proceedings of the 2004. doi:10.1145/1031607.1031705 , language =
-
[40]
Contemporary Educational Psychology , author =
From feedback to revisions:. Contemporary Educational Psychology , author =. 2020 , pages =. doi:10.1016/j.cedpsych.2019.101826 , abstract =
-
[41]
Beyond grammar checking: the impact of
Zhang, Aoran and Jiang, Chunli , month = jan, year =. Beyond grammar checking: the impact of. Cogent Education , publisher =. doi:10.1080/2331186X.2025.2574333 , abstract =
-
[42]
and Bjerva, Johannes , month = feb, year =
Zhang, Mike and Dilling, Amalie Pernille and Gondelman, Léon and Lyngdorf, Niels Erik Ruan and Lindsay, Euan D. and Bjerva, Johannes , month = feb, year =. doi:10.48550/arXiv.2502.12927 , abstract =
-
[43]
Successful classroom deployment of a social document annotation system , isbn =
Zyto, Sacha and Karger, David and Ackerman, Mark and Mahajan, Sanjoy , month = may, year =. Successful classroom deployment of a social document annotation system , isbn =. Proceedings of the. doi:10.1145/2207676.2208326 , abstract =
-
[44]
Language Resources and Evaluation , author =. 2022 , pages =. doi:10.1007/s10579-021-09567-z , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.