Quantifying the Privacy of Counterfactuals by Leveraging Membership Inference Attacks Against Synthetic Data
Pith reviewed 2026-06-28 02:00 UTC · model grok-4.3
The pith
Counterfactual explanations can reveal whether a record was in a model's training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Membership inference attacks designed for synthetic data succeed when applied to counterfactuals generated by a model, and the attacks remain effective when the attacker has access only to the set of counterfactuals and no access to the model.
What carries the argument
Direct transfer of membership inference attacks from synthetic data, treating counterfactuals as realistic substitutes for training records.
If this is right
- Releasing counterfactuals can produce a privacy breach comparable to releasing synthetic data.
- The attacks apply across multiple counterfactual generation methods.
- Model developers must consider privacy when sharing counterfactuals with users or the public.
Where Pith is reading between the lines
- Other forms of model explanations may carry similar membership leakage risks.
- Organizations releasing explanations might need new privacy safeguards or access controls.
Load-bearing premise
Counterfactuals function as realistic substitutes for real training data in the same way synthetic data does.
What would settle it
An experiment in which the membership inference attack's success rate on counterfactuals equals its success rate on randomly chosen non-training records.
Figures
read the original abstract
Counterfactuals are typically used in high-stakes decision areas to explain a machine learning model by showing how changes to the user profiles result in the desired outcome. However, explaining the model's decisions through counterfactuals can also be exploited by an adversary to conduct privacy attacks against the model or its training data. Drawing on the analogy that counterfactuals provide realistic substitutes for real training data, similar to synthetic data, we demonstrate in this paper how it is possible to successfully perform privacy attacks on counterfactuals by drawing on the attacks developed against synthetic data. More precisely, we investigate the effectiveness of the membership inference attacks designed for synthetic data on various types of counterfactuals. Additionally, while existing membership inference attacks against counterfactuals usually require to be able to query the model, we show how it is possible to perform successful membership inference attacks using only a set of counterfactuals, with no access to the model from which they are generated. Our results demonstrate that model developers should be more cautious when releasing counterfactuals to various users, as it can lead to a privacy breach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that counterfactual explanations can leak membership information about training data in a manner analogous to synthetic datasets. It asserts that membership inference attacks originally developed for synthetic data can be directly applied to sets of counterfactuals, achieving successful attacks even without query access to the underlying model. The work investigates this across various counterfactual types and concludes that model developers should exercise caution when releasing counterfactuals due to privacy risks.
Significance. If the empirical transfer of synthetic-data MIA techniques to counterfactuals is valid, the result would extend documented privacy vulnerabilities from data synthesis to the explainable-AI setting, providing a concrete reason to treat released counterfactual sets as potentially sensitive. The analogy itself is a useful framing, but the manuscript supplies no quantitative evidence, baselines, or controls in the visible text, preventing assessment of whether the claimed success is robust or merely an artifact of untested assumptions about sampling regimes.
major comments (2)
- [Abstract] Abstract and introduction: the central premise that counterfactuals 'provide realistic substitutes for real training data, similar to synthetic data' is asserted without any ablation, density comparison, or feature-distribution analysis showing that MIA signals (density ratios, reconstruction error, shadow-model outputs) remain discriminative when the data are sparse, validity-constrained, and instance-specific rather than drawn from a model's marginal.
- [Abstract] The manuscript states that attacks succeed 'with no access to the model' yet supplies no metrics, attack success rates, baseline comparisons, dataset descriptions, or statistical controls in the provided text, rendering the empirical claim impossible to evaluate for soundness.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one quantitative result (e.g., attack accuracy or AUC) and the datasets used.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment point by point below, clarifying the empirical content of the full manuscript while agreeing to strengthen certain aspects in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central premise that counterfactuals 'provide realistic substitutes for real training data, similar to synthetic data' is asserted without any ablation, density comparison, or feature-distribution analysis showing that MIA signals (density ratios, reconstruction error, shadow-model outputs) remain discriminative when the data are sparse, validity-constrained, and instance-specific rather than drawn from a model's marginal.
Authors: We agree that the analogy benefits from explicit supporting analysis. The full manuscript reports empirical transfer of MIA techniques with attack success rates on counterfactual sets, but does not include dedicated density or feature-distribution ablations. We will add these comparisons (e.g., KL divergence between counterfactual and training distributions, plus ablation on sparsity/validity constraints) to the revised version. revision: yes
-
Referee: [Abstract] The manuscript states that attacks succeed 'with no access to the model' yet supplies no metrics, attack success rates, baseline comparisons, dataset descriptions, or statistical controls in the provided text, rendering the empirical claim impossible to evaluate for soundness.
Authors: The full manuscript contains these elements in the experimental evaluation (attack success rates, baseline comparisons against random and shadow-model attacks, dataset details, and statistical significance). The referee's observation correctly notes their absence from the abstract alone. We will incorporate a concise summary of key quantitative results into the abstract during revision. revision: partial
Circularity Check
No circularity: empirical attack transfer with no derivations or self-referential reductions.
full rationale
The paper is an empirical demonstration that applies pre-existing membership inference attacks (designed for synthetic data) directly to released counterfactual sets. No equations, fitted parameters, or derivations appear in the provided text. The central claim rests on experimental transfer of attack success rates rather than any self-definition, fitted-input prediction, or load-bearing self-citation chain. The analogy between counterfactuals and synthetic data is stated as a premise for the experiments but is not used to derive results by construction; results are measured outcomes. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2016. Machine Bias: Risk Assessments in Criminal Sentencing. https: //github.com/propublica/compas-analysis. Accessed 2025-05-15
2016
-
[3]
Arthur Asuncion and David Newman. 2007. UCI machine learning repository
2007
- [4]
-
[5]
Brett K Beaulieu-Jones, Zhiwei Steven Wu, Chris Williams, Ran Lee, Sanjeev P Bhavnani, James Brian Byrd, and Casey S Greene. 2019. Privacy-preserving generative deep neural networks support clinical data sharing.Circulation: Cardiovascular Quality and Outcomes12, 7 (2019), e005122
2019
-
[6]
Dieter Brughmans, Pieter Leyman, and David Martens. 2023. Nice: an algorithm for nearest instance counterfactual explanations.Data Mining and Knowledge Discovery(2023), 1–39
2023
-
[7]
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. 2020. Gan-leaks: A taxonomy of membership inference attacks against generative models. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security. 343–362
2020
-
[8]
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. 2017. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. InProceedings of the 10th ACM workshop on artificial intelligence and security. 15–26
2017
-
[9]
Cynthia Dwork, Aaron Roth, et al. 2014. The algorithmic foundations of differential privacy.Foundations and Trends®in Theoretical Computer Science9, 3–4 (2014), 211–407
2014
-
[10]
Sofie Goethals, Kenneth Sörensen, and David Martens. 2023. The Privacy Issue of Counterfactual Explanations: Explanation Linkage Attacks.ACM Trans. Intell. Syst. Technol.14, 5, Article 83 (aug 2023), 24 pages. doi:10.1145/3608482
-
[11]
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
-
[12]
Generative adversarial nets.Advances in neural information processing systems27 (2014)
2014
-
[13]
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. 2017. Logan: Membership inference attacks against generative models.arXiv preprint arXiv:1705.07663(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. 2019. Monte carlo and reconstruction membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies(2019)
2019
- [15]
-
[16]
Aoting Hu, Renjie Xie, Zhigang Lu, Aiqun Hu, and Minhui Xue. 2021. Tablegan-mca: Evaluating membership collisions of gan-synthesized tabular data releasing. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. 2096–2112
2021
- [17]
-
[18]
Ling Huang, Anthony D Joseph, Blaine Nelson, Benjamin IP Rubinstein, and J Doug Tygar. 2011. Adversarial machine learning. In Proceedings of the 4th ACM workshop on Security and artificial intelligence. 43–58
2011
-
[19]
Amir-Hossein Karimi, Gilles Barthe, Bernhard Schölkopf, and Isabel Valera. 2022. A survey of algorithmic recourse: contrastive explanations and consequential recommendations.Comput. Surveys55, 5 (2022), 1–29
2022
-
[20]
Aditya Kuppa and Nhien-An Le-Khac. 2021. Adversarial XAI methods in cybersecurity.IEEE transactions on information forensics and security16 (2021), 4924–4938
2021
-
[21]
Thibault Laugel, Marie-Jeanne Lesot, Christophe Marsala, Xavier Renard, and Marcin Detyniecki. 2019. The dangers of post-hoc interpretability: unjustified counterfactual explanations. InProceedings of the 28th International Joint Conference on Artificial Intelligence (Macao, China)(IJCAI’19). 2801–2807
2019
- [22]
-
[23]
Ryan McKenna, Brett Mullins, Daniel Sheldon, and Gerome Miklau. 2022. AIM: an adaptive and iterative mechanism for differentially private synthetic data.Proc. VLDB Endow.15, 11 (July 2022), 2599–2612. doi:10.14778/3551793.3551817
-
[24]
Ramaravind K Mothilal, Amit Sharma, and Chenhao Tan. 2020. Explaining machine learning classifiers through diverse counterfactual explanations. InProceedings of the 2020 conference on fairness, accountability, and transparency. 607–617
2020
-
[25]
2022.Privacy-preserving counterfactual explanations to help humans contest AI-based decisions
DJ Nelson. 2022.Privacy-preserving counterfactual explanations to help humans contest AI-based decisions. Master’s thesis. University of Twente
2022
-
[26]
2021.Synthetic data for deep learning
Sergey I Nikolenko et al. 2021.Synthetic data for deep learning. Vol. 174. Springer
2021
-
[27]
OpenML. 2018. FICO-HELOC-cleaned Dataset. https://openml.org/d/45554. Accessed 2025-05-15
2018
-
[28]
Art B. Owen. 2013.Monte Carlo theory, methods and examples. https://artowen.su.domains/mc/. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Babaei et al
2013
-
[29]
Martin Pawelczyk, Himabindu Lakkaraju, and Seth Neel. 2023. On the privacy risks of algorithmic recourse. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 9680–9696
2023
- [30]
-
[31]
Reza Shokri, Martin Strobel, and Yair Zick. 2021. On the privacy risks of model explanations. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. 231–241
2021
-
[32]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP). IEEE, 3–18
2017
-
[33]
Marlon Tobaben, Hibiki Ito, Joonas Jälkö, Yuan He, and Antti Honkela. 2025. Impact of Dataset Properties on Membership Inference Vulnerability of Deep Transfer Learning. InAdvances in Neural Information Processing Systems, Vol. 38. 67486–67537
2025
-
[34]
Boris van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. 2023. Membership Inference Attacks against Synthetic Data through Overfitting Detection. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 3493–3514
2023
-
[35]
Giuseppe Vietri, Cedric Archambeau, Sergul Aydore, William Brown, Michael Kearns, Aaron Roth, Ankit Siva, Shuai Tang, and Steven Z Wu. 2022. Private synthetic data for multitask learning and marginal queries.Advances in Neural Information Processing Systems35 (2022), 18282–18295
2022
-
[36]
Sandra Wachter, Brent Mittelstadt, and Chris Russell. 2017. Counterfactual explanations without opening the black box: Automated decisions and the GDPR.Harv. JL & Tech.31 (2017), 841
2017
-
[37]
Yongjie Wang, Hangwei Qian, and Chunyan Miao. 2022. DualCF: Efficient Model Extraction Attack from Counterfactual Explanations. In2022 ACM Conference on Fairness, Accountability, and Transparency. 1318–1329
2022
- [38]
-
[39]
Joshua Ward, Chi-Hua Wang, and Guang Cheng. 2025. Privacy Auditing Synthetic Data Release through Local Likelihood Attacks. arXiv preprint arXiv:2508.21146(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
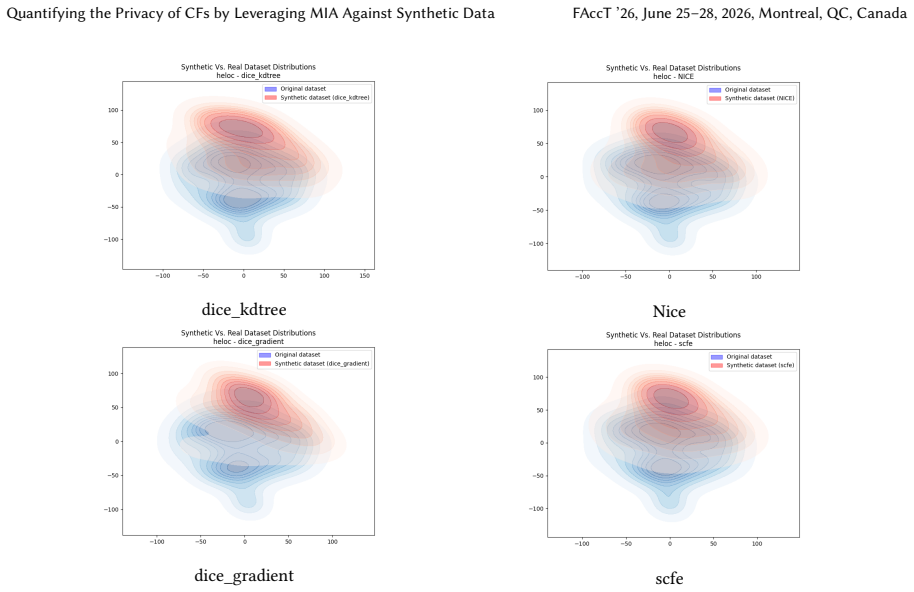
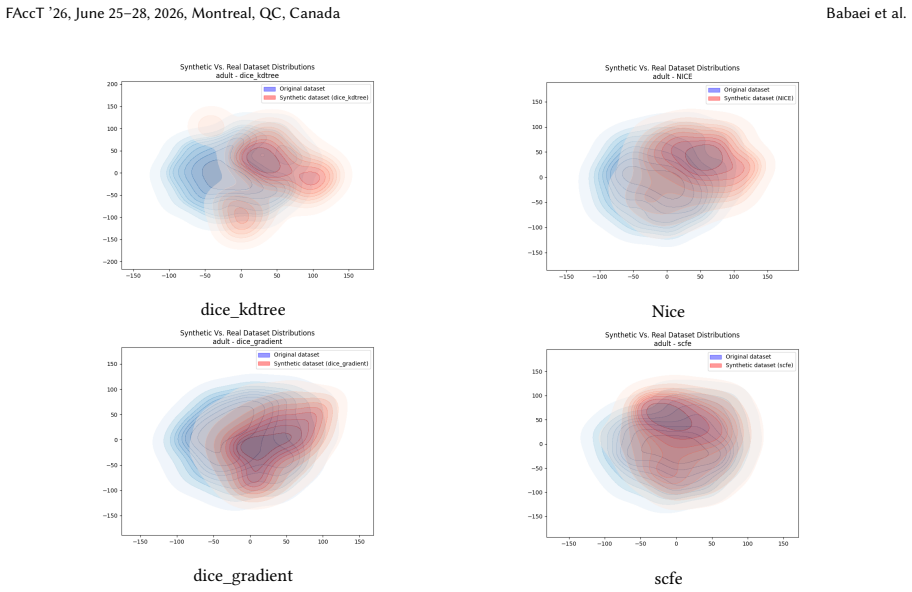
Joshua Ward, Yuxuan Yang, Chi-Hua Wang, and Guang Cheng. 2025. Ensembling Membership Inference Attacks Against Tabular Generative Models. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security (AISec ’25). Association for Computing Machinery, New York, NY, USA, 182–193. doi:10.1145/3733799.3762977 A Distribution comparison between ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.