Visual Commonsense Driven Knowledge Refinements for Scene Graph Generation
Pith reviewed 2026-06-28 01:49 UTC · model grok-4.3
The pith
A framework mines visual commonsense constraints from data to refine scene graph predictions at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a model-agnostic, semantically-guided knowledge refinement framework that systematically mines commonsense-grounded constraints from training data - capturing spatial, functional, and qualitative relational regularities - and uses general declarative commonsense reasoning to correct and refine ranked SGG predictions at inference time. The framework requires no manual rule authoring, no model retraining, and transfers across datasets and architectures. On three standard benchmarks, we obtain consistent improvements over strong baselines, demonstrating that structured visual commonsense reasoning over deep scene semantics is a practical and effective complement to purely learning-ba
What carries the argument
The model-agnostic knowledge refinement framework that mines commonsense-grounded constraints from training data and applies declarative commonsense reasoning to refine ranked predictions at inference.
If this is right
- Scene graph predictions improve consistently across three standard benchmarks without retraining.
- The same mined constraints work on different scene graph models and datasets.
- Annotation sparsity effects are mitigated through post-hoc application of relational constraints.
- No manual authoring of rules is needed since constraints are derived automatically from data.
Where Pith is reading between the lines
- The refinement step could be inserted into existing pipelines as a lightweight post-processor.
- Mining constraints from training data alone may limit coverage of rare but valid relations not seen in the data.
- The approach points toward hybrid systems where learned predictions are adjusted by explicit relational knowledge.
- Similar constraint mining might apply to other relational vision tasks such as action recognition or visual question answering.
Load-bearing premise
Automatically mined commonsense constraints from the training data capture reliable relational regularities that remain valid and beneficial when applied to predictions from models trained on different data or architectures.
What would settle it
Applying the mined constraints to refine predictions from a new scene graph model on a different benchmark dataset and measuring no gain or a loss in standard metrics such as mean recall would falsify the transfer and improvement claims.
Figures
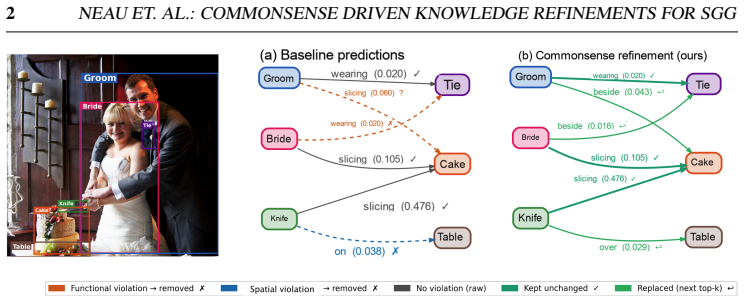
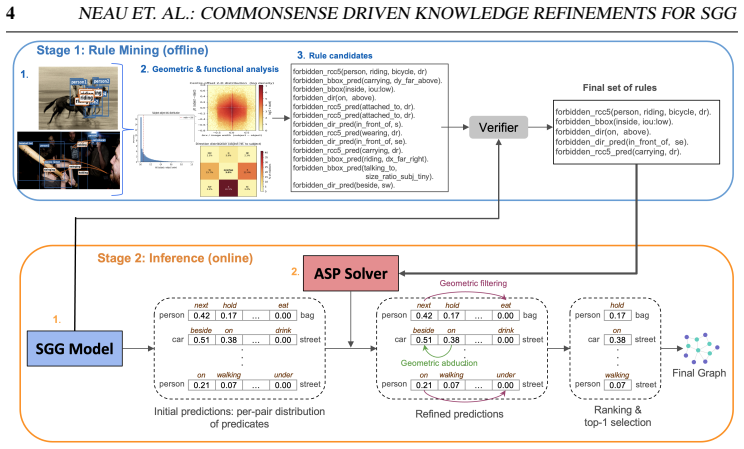
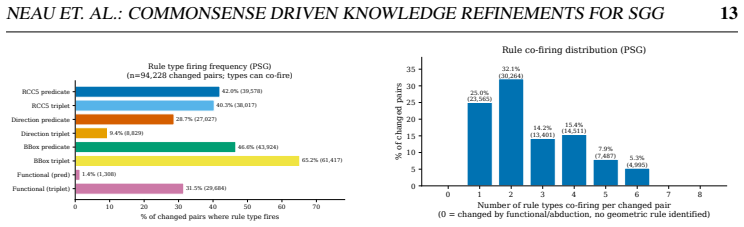
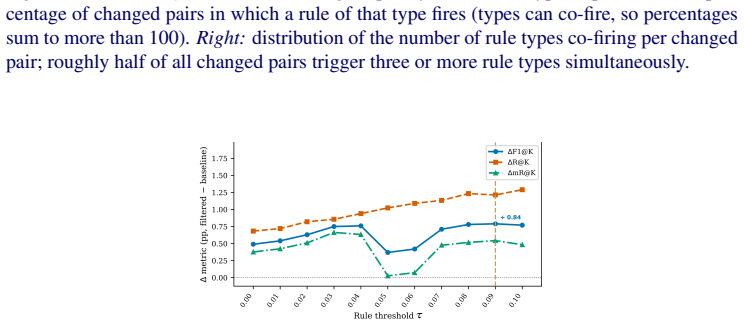


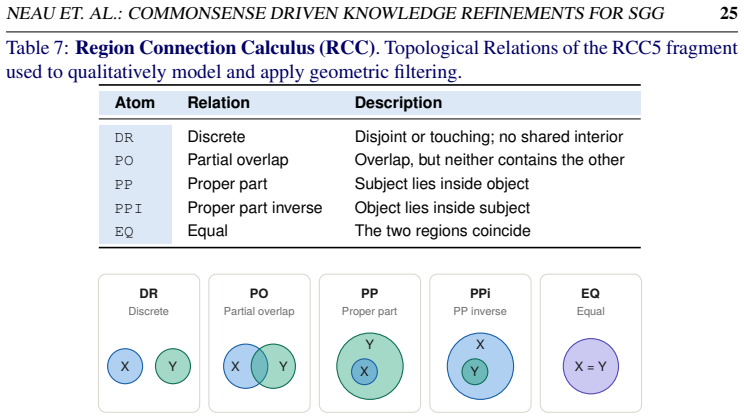
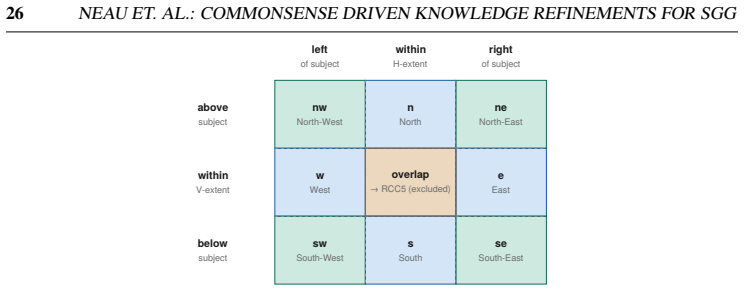
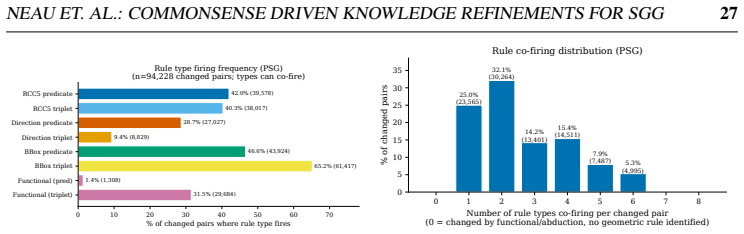
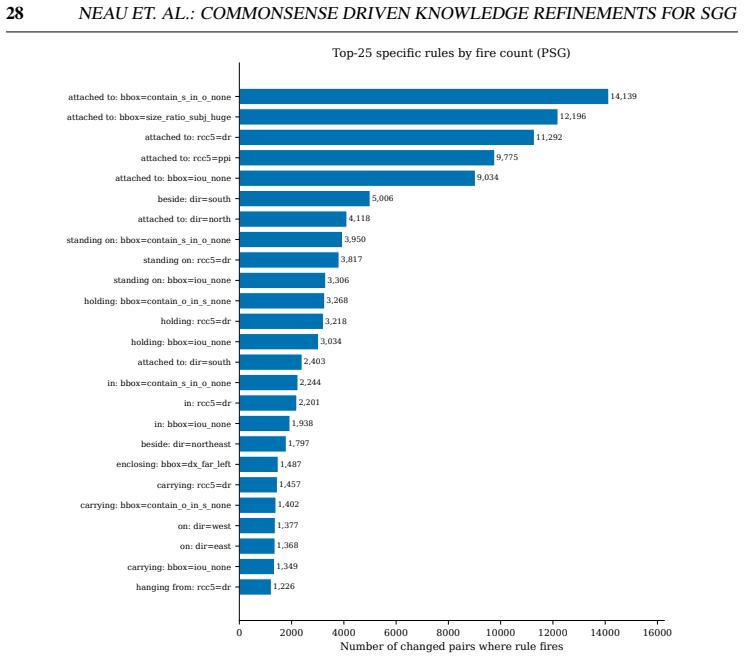
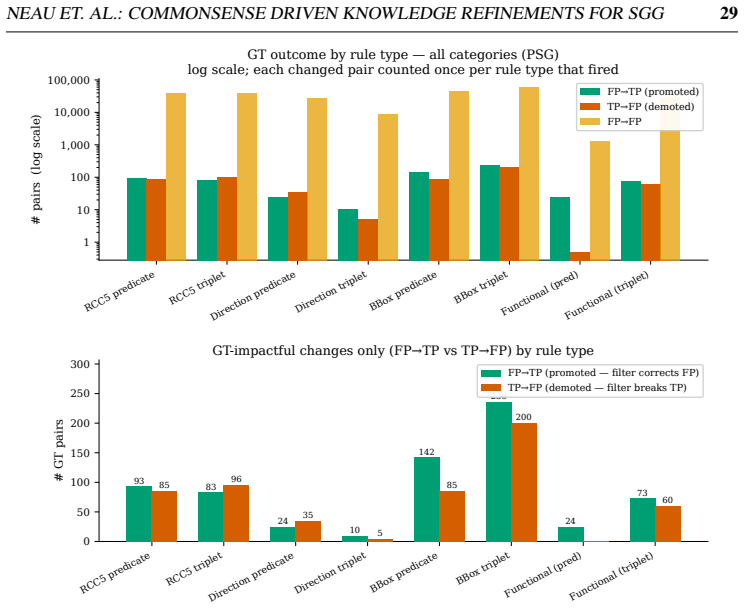
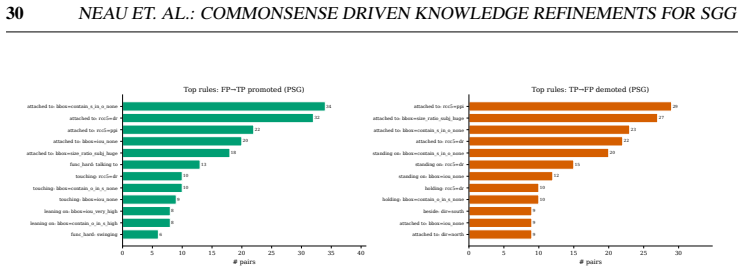
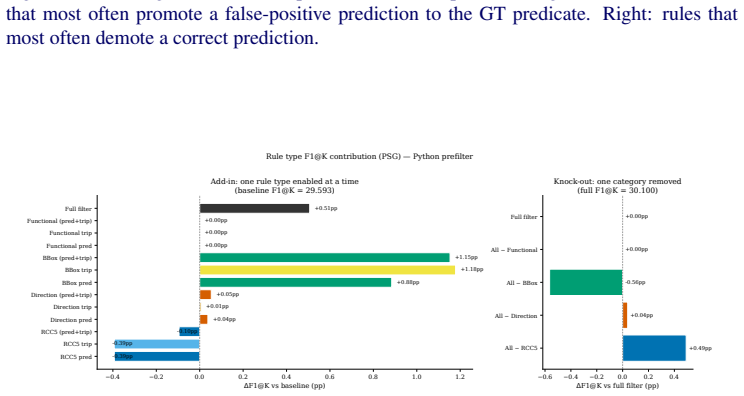
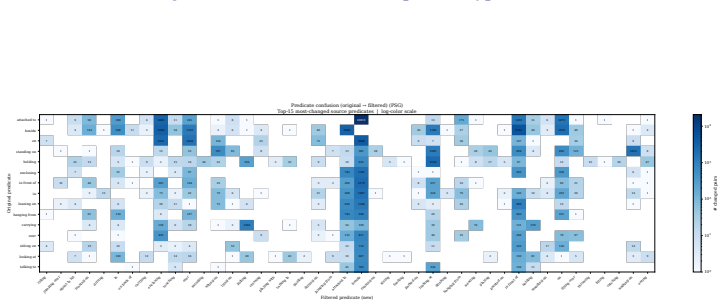

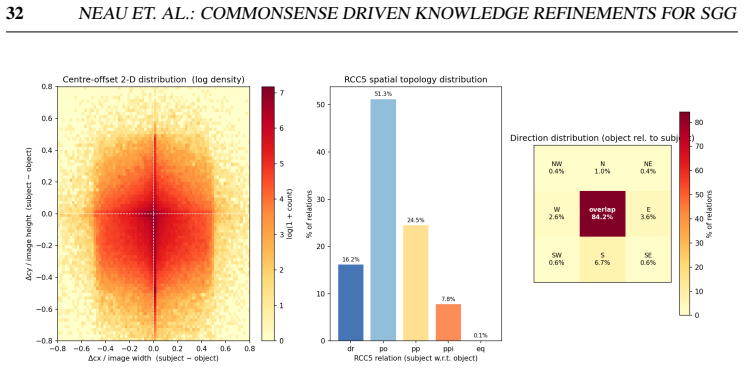
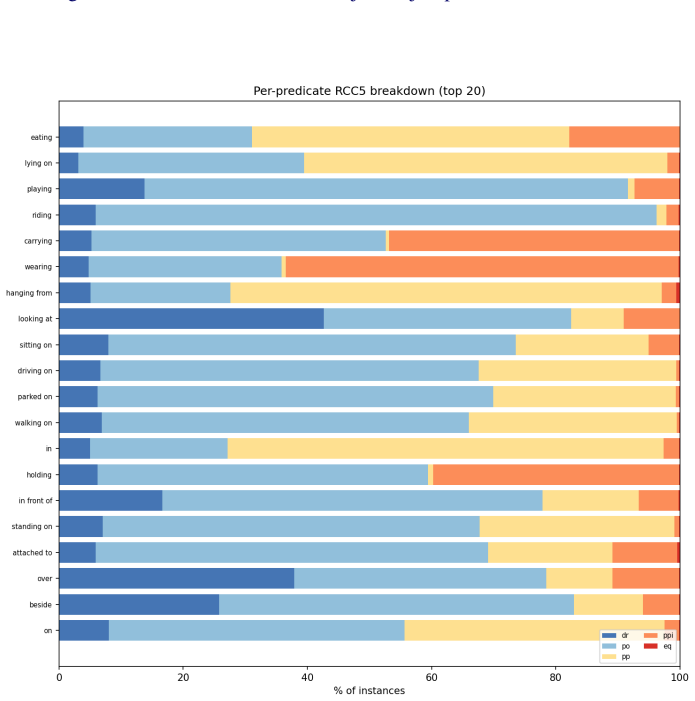
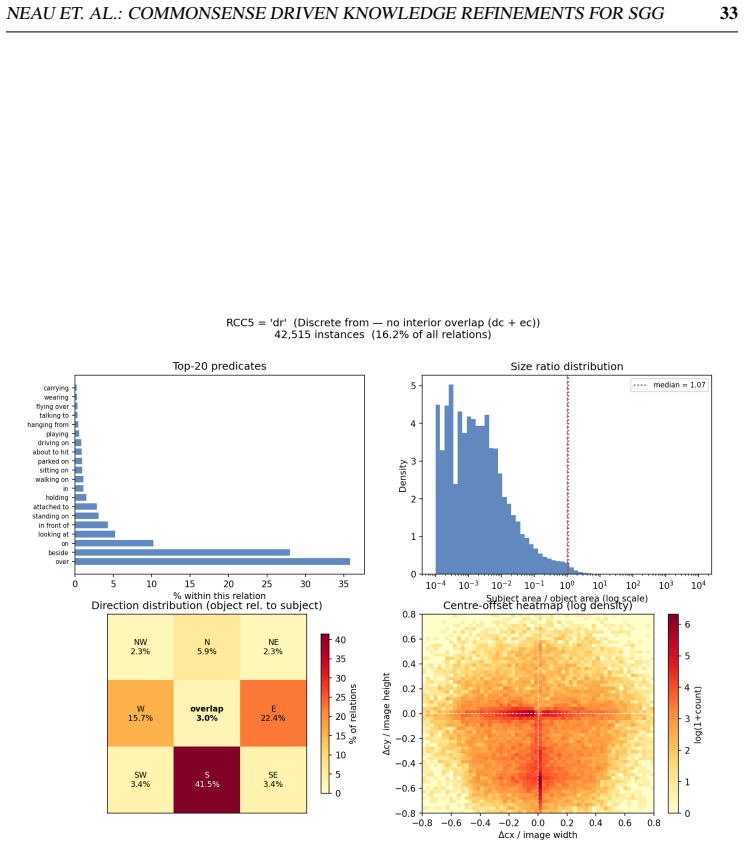
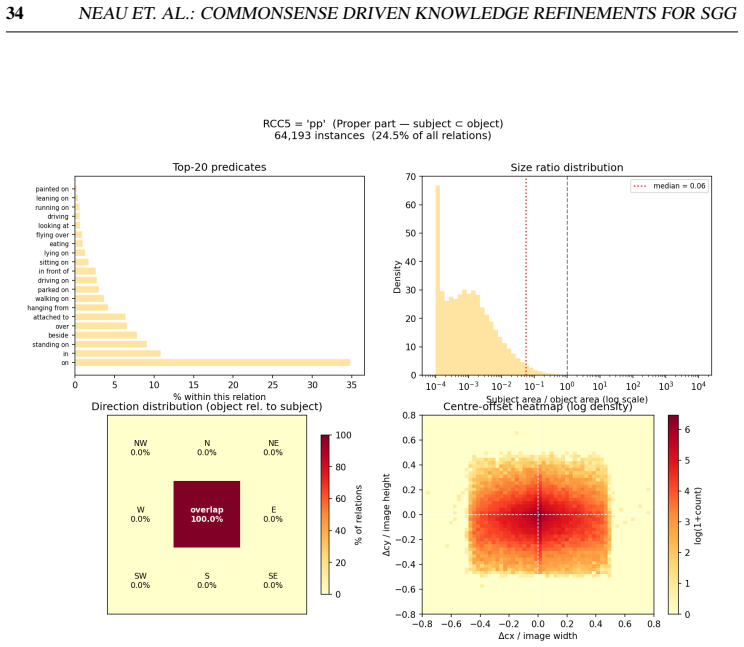
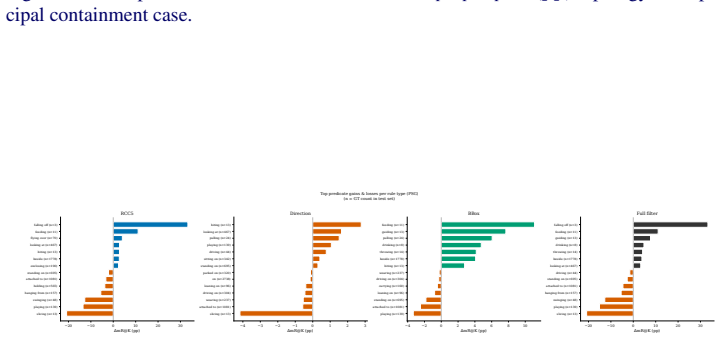
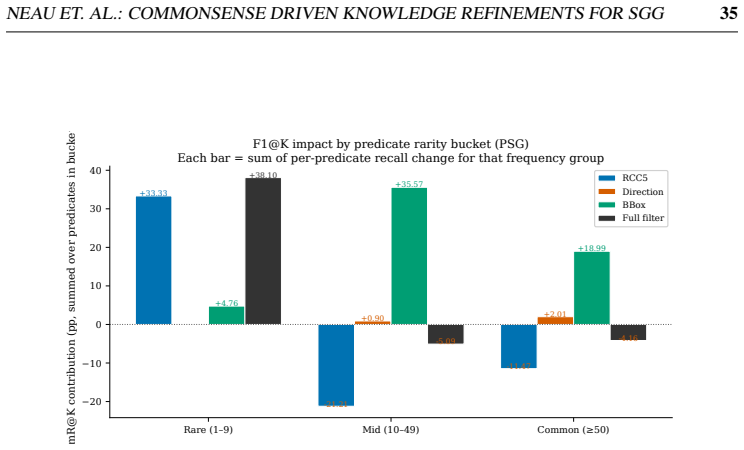
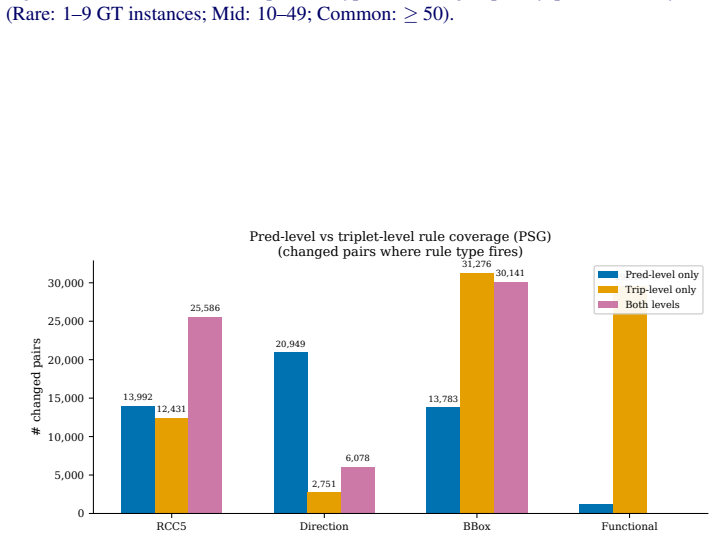
read the original abstract
Learning-driven Scene Graph Generation (SGG) models excel on frequent relation types but degrade sharply under annotation sparsity, failing to capture reliable visual commonsense knowledge. We propose a model-agnostic, semantically-guided knowledge refinement framework that systematically mines commonsense-grounded constraints from training data - capturing spatial, functional, and qualitative relational regularities - and uses general declarative commonsense reasoning to correct and refine ranked SGG predictions at inference time. The framework requires no manual rule authoring, no model retraining, and transfers across datasets and architectures. On three standard benchmarks, we obtain consistent improvements over strong baselines, demonstrating that structured visual commonsense reasoning over deep scene semantics is a practical and effective complement to purely learning-based scene graph generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a model-agnostic, semantically-guided knowledge refinement framework for Scene Graph Generation (SGG). It automatically mines commonsense-grounded constraints from training data that capture spatial, functional, and qualitative relational regularities, then applies general declarative commonsense reasoning to correct and refine ranked SGG predictions at inference time. The framework requires no manual rule authoring or model retraining and is claimed to transfer across datasets and architectures, yielding consistent improvements over strong baselines on three standard benchmarks.
Significance. If the transfer results hold under rigorous cross-distribution testing, the work would demonstrate a practical, training-free mechanism for injecting structured visual commonsense into learning-based SGG pipelines. This hybrid approach could meaningfully address annotation sparsity without retraining costs, offering a reusable complement to purely data-driven methods in relational scene understanding tasks.
major comments (1)
- [Abstract and experiments section] Abstract and experiments section: the central claim that automatically mined constraints encode transferable visual commonsense (rather than source-dataset annotation biases) is load-bearing for the transfer assertion. The manuscript must report explicit cross-dataset and cross-architecture quantitative results showing that constraints mined from one training distribution improve predictions from models trained on different distributions; without such controls, the reported gains may not generalize beyond the source statistics.
minor comments (1)
- Clarify in the method description whether the declarative reasoning step uses any dataset-specific thresholds or post-processing that could affect reproducibility across new architectures.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of rigorous controls to support the transferability claim. We agree that explicit cross-dataset and cross-architecture experiments are required to distinguish visual commonsense from source-specific annotation biases, and we will incorporate them in the revision.
read point-by-point responses
-
Referee: [Abstract and experiments section] Abstract and experiments section: the central claim that automatically mined constraints encode transferable visual commonsense (rather than source-dataset annotation biases) is load-bearing for the transfer assertion. The manuscript must report explicit cross-dataset and cross-architecture quantitative results showing that constraints mined from one training distribution improve predictions from models trained on different distributions; without such controls, the reported gains may not generalize beyond the source statistics.
Authors: We concur that the current experiments, while showing gains across three benchmarks, do not include the precise controls requested (constraints mined from distribution A applied to a model trained on distribution B). In the revised version we will add: (1) cross-dataset tests mining constraints from Visual Genome and applying them to models trained on GQA and Open Images; (2) cross-architecture tests using the same mined constraints on multiple SGG backbones (e.g., Motifs, VCTree, and a transformer-based model). These results will be reported in a new subsection of the experiments with quantitative tables and analysis of whether improvements persist under distribution shift. revision: yes
Circularity Check
No circularity detected; derivation is self-contained empirical claim
full rationale
The provided abstract and description contain no equations, fitting procedures, or self-citations that reduce any claimed result to its inputs by construction. The framework is presented as mining constraints from training data and applying them at inference time to obtain empirical improvements on benchmarks, with the transfer property asserted as an observed outcome rather than a definitional or fitted necessity. No load-bearing step equates a prediction to a parameter fit or renames an input as output. This is the expected non-finding for a high-level methods description lacking mathematical reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Og-sgg: ontology-guided scene graph generation—a case study in transfer learning for telepresence robotics.IEEE Access, 10:132564–132583, 2022
Fernando Amodeo, Fernando Caballero, Natalia Díaz-Rodríguez, and Luis Merino. Og-sgg: ontology-guided scene graph generation—a case study in transfer learning for telepresence robotics.IEEE Access, 10:132564–132583, 2022
2022
-
[2]
3d scene graph: A structure for unified semantics, 3d space, and camera
Iro Armeni, Zhi-Yang He, JunYoung Gwak, Amir R Zamir, Martin Fischer, Jitendra Malik, and Silvio Savarese. 3d scene graph: A structure for unified semantics, 3d space, and camera. InProceedings of the IEEE/CVF international conference on computer vision, pages 5664–5673, 2019
2019
-
[3]
Artificial visual intelligence - perceptual common- sense for human-centred cognitive technologies
Mehul Bhatt and Jakob Suchan. Artificial visual intelligence - perceptual common- sense for human-centred cognitive technologies. In Mohamed Chetouani, Virginia Dignum, Paul Lukowicz, and Carles Sierra, editors,Human-Centered Artificial In- telligence - Advanced Lectures, 18th European Advanced Course on AI, ACAI 2021, Berlin, Germany, October 11-15, 2021...
-
[4]
Cohn, Brandon Bennett, John Gooday, and Nicholas M
Anthony G. Cohn, Brandon Bennett, John Gooday, and Nicholas M. Gotts. Qualitative spatial representation and reasoning with the region connection calculus.GeoInformat- ica, 1(3):275–316, 1997
1997
-
[5]
Commonsense reasoning and commonsense knowledge in artificial intelligence.Communications of the ACM, 58(9):92–103, 2015
Ernest Davis and Gary Marcus. Commonsense reasoning and commonsense knowledge in artificial intelligence.Communications of the ACM, 58(9):92–103, 2015
2015
-
[6]
Explainable zero-shot visual question answering via logic-based reasoning
Thomas Eiter, Jan Hadl, Nelson Higuera Ruiz, Lukas Lange, Johannes Oetsch, Bileam Scheuvens, and Jannik Strötgen. Explainable zero-shot visual question answering via logic-based reasoning. In Leilani H. Gilpin, Eleonora Giunchiglia, Pascal Hitzler, and Emile van Krieken, editors,Proceedings of The 19th International Conference on Neu- rosymbolic Learning ...
2025
-
[7]
Clingo = ASP + control: Preliminary report.CoRR, abs/1405.3694, 2014
Martin Gebser, Roland Kaminski, Benjamin Kaufmann, and Torsten Schaub. Clingo = ASP + control: Preliminary report.CoRR, abs/1405.3694, 2014
Pith/arXiv arXiv 2014
-
[8]
Theory Solving Made Easy with Clingo 5
Martin Gebser, Roland Kaminski, Benjamin Kaufmann, Max Ostrowski, Torsten Schaub, and Philipp Wanko. Theory Solving Made Easy with Clingo 5. In Manuel Carro, Andy King, Neda Saeedloei, and Marina De V os, editors,Technical Communi- cations of the 32nd International Conference on Logic Programming (ICLP 2016), vol- ume 52 ofOpenAccess Series in Informatics...
-
[9]
Goyal and Max J
Roop K. Goyal and Max J. Egenhofer. Similarity of cardinal directions. In Christian S. Jensen, Markus Schneider, Bernhard Seeger, and Vassilis J. Tsotras, editors,Advances in Spatial and Temporal Databases, pages 36–55, Berlin, Heidelberg, 2001. Springer Berlin Heidelberg. ISBN 978-3-540-47724-2
2001
-
[10]
Enhancing scene graph generation with hierarchical relationships and commonsense knowledge
Bowen Jiang, Zhijun Zhuang, Shreyas S Shivakumar, and Camillo J Taylor. Enhancing scene graph generation with hierarchical relationships and commonsense knowledge. NEAU ET. AL.: COMMONSENSE DRIVEN KNOWLEDGE REFINEMENTS FOR SGG17 In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8883–8894. IEEE, 2025
2025
-
[11]
Image generation from scene graphs
Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image generation from scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1219–1228, 2018
2018
-
[12]
A survey of neu- rosymbolic visual reasoning with scene graphs and common sense knowledge.Neu- rosymbolic Artificial Intelligence, 1:NAI–240719, 2025
M Jaleed Khan, Filip Ilievski, John G Breslin, and Edward Curry. A survey of neu- rosymbolic visual reasoning with scene graphs and common sense knowledge.Neu- rosymbolic Artificial Intelligence, 1:NAI–240719, 2025
2025
-
[13]
Expressive scene graph generation using commonsense knowledge infusion for visual understanding and rea- soning
Muhammad Jaleed Khan, John G Breslin, and Edward Curry. Expressive scene graph generation using commonsense knowledge infusion for visual understanding and rea- soning. InEuropean Semantic Web Conference, pages 93–112. Springer, 2022
2022
-
[14]
Muhammad Jaleed Khan, John G. Breslin, and Edward Curry. Knowzrel: Common sense knowledge-based zero-shot relationship retrieval for generalized scene graph generation.IEEE Transactions on Artificial Intelligence, 6(12):3184–3194, 2025. doi: 10.1109/TAI.2025.3544177
-
[15]
Visual genome: Connecting language and vision using crowdsourced dense image annotations.Inter- national journal of computer vision, 123(1):32–73, 2017
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.Inter- national journal of computer vision, 123(1):32–73, 2017
2017
-
[16]
Visual question an- swering over scene graph
Soohyeong Lee, Ju-Whan Kim, Youngmin Oh, and Joo Hyuk Jeon. Visual question an- swering over scene graph. In2019 First International Conference on Graph Computing (GC), pages 45–50. IEEE, 2019
2019
-
[17]
Vladimir Lifschitz.Answer Set Programming. Springer, 2019. ISBN 978-3-030- 24657-0. doi: 10.1007/978-3-030-24658-7
-
[18]
Gerard Ligozat.Qualitative Spatial and Temporal Reasoning. Wiley, 2013. ISBN 9781118601457. doi: https://doi.org/10.1002/9781118601457.fmatter
-
[19]
Maëlic Neau and Zoe Falomir. React++: Efficient cross-attention for real-time scene graph generation.arXiv preprint arXiv:2603.06386, 2026
arXiv 2026
-
[20]
In defense of scene graph generation for human-robot open-ended interaction in service robotics
Maëlic Neau, Paulo Santos, Anne-Gwenn Bosser, and Cédric Buche. In defense of scene graph generation for human-robot open-ended interaction in service robotics. In Robot World Cup, pages 299–310. Springer, 2023
2023
-
[21]
React: Real-time efficiency and accuracy compromise for tradeoffs in scene graph generation
Maëlic Neau, Paulo Eduardo Santos, Anne-Gwenn Bosser, Akihiro Sugimoto, and Cedric Buche. React: Real-time efficiency and accuracy compromise for tradeoffs in scene graph generation. In36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMV A, 2025
2025
-
[22]
Parth Padalkar and Gopal Gupta. Symbolic rule extraction from attention-guided sparse representations in vision transformers.Theory and Practice of Logic Programming, 25 (4):722–738, 2025. doi: 10.1017/S1471068425100318. 18NEAU ET. AL.: COMMONSENSE DRIVEN KNOWLEDGE REFINEMENTS FOR SGG
-
[23]
Semantic question-answering with video and eye- tracking data: AI foundations for human visual perception driven cognitive film studies
Jakob Suchan and Mehul Bhatt. Semantic question-answering with video and eye- tracking data: AI foundations for human visual perception driven cognitive film studies. In Subbarao Kambhampati, editor,Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9-15 July 2016, pages 2633–2639. IJC...
2016
-
[24]
Jakob Suchan, Mehul Bhatt, and Srikrishna Varadarajan. Commonsense visual sense- making for autonomous driving - on generalised neurosymbolic online abduction inte- grating vision and semantics.Artif. Intell., 299:103522, 2021. doi: 10.1016/J.ARTINT. 2021.103522
-
[25]
Jakob Suchan, Mehul Bhatt, and Julius Monsen. ASP-driven visual commonsense: a general framework for reasoning about embodied interaction in the wild. InProceed- ings of the 22nd International Conference on Principles of Knowledge Representation and Reasoning, KR ’25, 2025. ISBN 978-1-956792-08-9. doi: 10.24963/kr.2025/61
-
[26]
Unbi- ased scene graph generation from biased training
Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. Unbi- ased scene graph generation from biased training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3716–3725, 2020
2020
-
[27]
Yolov12: Attention-centric real-time object detectors.Advances in neural information processing systems, 38:78433–78457, 2026
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors.Advances in neural information processing systems, 38:78433–78457, 2026
2026
-
[28]
Scene graph generation by iterative message passing
Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5410–5419, 2017
2017
-
[29]
Panoptic scene graph generation
Jingkang Yang, Yi Zhe Ang, Zujin Guo, Kaiyang Zhou, Wayne Zhang, and Ziwei Liu. Panoptic scene graph generation. InEuropean conference on computer vision, pages 178–196. Springer, 2022
2022
-
[30]
Auto-encoding scene graphs for image captioning
Xu Yang, Kaihua Tang, Hanwang Zhang, and Jianfei Cai. Auto-encoding scene graphs for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10685–10694, 2019
2019
-
[31]
Neurasp: Embracing neural networks into answer set programming
Zhun Yang, Adam Ishay, and Joohyung Lee. Neurasp: Embracing neural networks into answer set programming. In Christian Bessiere, editor,Proceedings of the Twenty- Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pages 1755–
-
[32]
International Joint Conferences on Artificial Intelligence Organization, 7 2020. doi: 10.24963/ijcai.2020/243. Main track
-
[33]
Generative visual commonsense reasoning with scene graphs
Fan Yuan, Xiaoyuan Fang, Rong Quan, Jing Li, Wei Bi, Xiaogang Xu, and Piji Li. Generative visual commonsense reasoning with scene graphs. Preprint, 2025
2025
-
[34]
Learning visual commonsense for robust scene graph generation
Alireza Zareian, Zhecan Wang, Haoxuan You, and Shih-Fu Chang. Learning visual commonsense for robust scene graph generation. InEuropean Conference on Computer Vision, pages 642–657. Springer, 2020
2020
-
[35]
Neural motifs: Scene graph parsing with global context
Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5831–5840, 2018. NEAU ET. AL.: COMMONSENSE DRIVEN KNOWLEDGE REFINEMENTS FOR SGG19
2018
-
[36]
From recognition to cog- nition: Visual commonsense reasoning
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cog- nition: Visual commonsense reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6720–6731, 2019. doi: 10.1109/CVPR.2019.00688. 20NEAU ET. AL.: COMMONSENSE DRIVEN KNOWLEDGE REFINEMENTS FOR SGG Contents This supplement p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.