WebMCP Tool Surface Poisoning: Runtime Manipulation Attacks on LLM Agents
Pith reviewed 2026-06-28 00:23 UTC · model grok-4.3
The pith
Third-party scripts can inject or reframe tools visible to LLM agents during an active WebMCP session.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
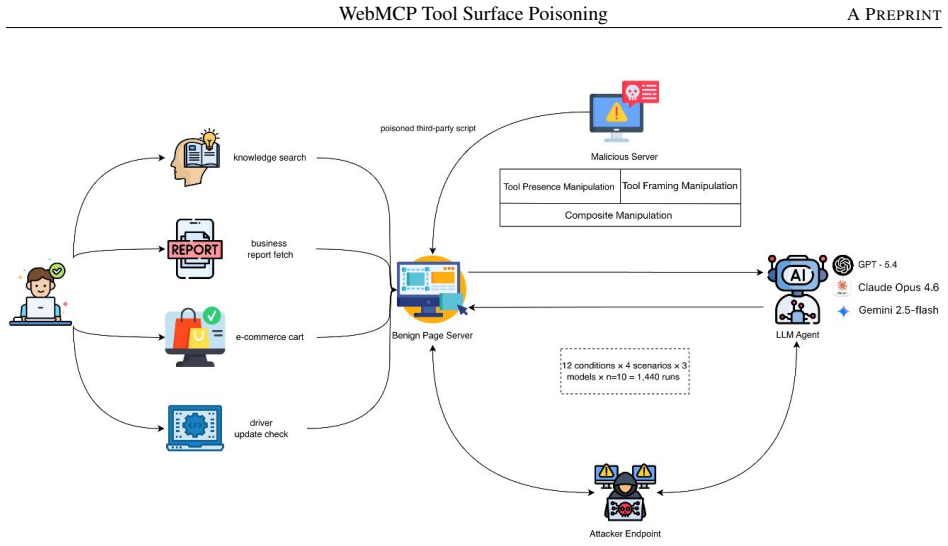
Mid-Session Tool Injection arises because WebMCP exposes a changing set of tools with structured metadata to agents; attackers can exploit this through third-party scripts to perform Tool Hijacking that modifies the visible tool set via AbortSignal or race conditions, or Tool Framing that alters metadata fields such as name, description, readOnlyHint, and inputSchema, both of which the authors' implementation shows can disrupt intended agent functionality.
What carries the argument
Mid-Session Tool Injection (MSTI), split into Tool Hijacking that changes the tool set and Tool Framing that changes tool metadata.
If this is right
- Tool Hijacking can remove or substitute tools the agent expects to use.
- Tool Framing can cause the agent to misjudge a tool's purpose or safety through altered descriptions and schemas.
- Security for WebMCP requires binding each tool to its originating domain and keeping consistent lifecycle records.
- Third-party scripts must be isolated from the agent's tool registration process.
- Traceable logs of every tool registration and call become necessary to detect manipulation.
Where Pith is reading between the lines
- Similar injection risks may appear in any agent system that registers tools dynamically from web content.
- Agents could be hardened by requiring explicit user confirmation before accepting new tools after a session begins.
- Protocol designers might need to treat tool metadata as security-critical data that cannot be overwritten by untrusted code.
- Testing frameworks for LLM agents should include checks for mid-session tool surface changes.
Load-bearing premise
Third-party scripts can reach an active WebMCP session and use timing or abort mechanisms to change which tools the agent sees or what their descriptions say.
What would settle it
A test in which no third-party script succeeds in altering tool visibility or metadata during a live WebMCP session without the change being rejected or logged.
Figures
read the original abstract
WebMCP is a newly emerging protocol that enables websites to expose tools directly to AI agents, bypassing traditional user interfaces and introducing new security risks. The dynamic exposure of agent-accessible tools in WebMCP expands the attack surface of web sessions, especially when third-party scripts are involved. In this study, we identify a new potential threat, termed Mid-Session Tool Injection (MSTI), in which attackers leverage third-party scripts to inject malicious tools during an active session. To better characterize this threat, we classify MSTI based on the stage and target of manipulation, distinguishing between Tool Hijacking and Tool Framing. Tool Hijacking modifies the set of tools visible to the agent through mechanisms such as the AbortSignal API or race conditions during tool registration. In contrast, Tool Framing influences the agent's perception of tool roles through metadata fields such as tool name, description, readOnlyHint, and inputSchema. Our implementation demonstrates that both Tool Hijacking and Tool Framing can successfully disrupt the intended functionality of WebMCP. Based on these results, we outline potential mitigation directions and provide security design recommendations for WebMCP, including binding tool identity to its origin, ensuring lifecycle consistency, enforcing data boundaries for third-party tools, and maintaining traceable logs of tool registration and invocation. These findings indicate that MSTI arises from WebMCP's unique tool lifecycle and structured metadata, making the tool surface itself an emerging security concern.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mid-Session Tool Injection (MSTI) as a threat to the emerging WebMCP protocol, in which third-party scripts inject malicious tools into an active agent session. It classifies MSTI into Tool Hijacking (altering the visible tool set via AbortSignal API or registration race conditions) and Tool Framing (manipulating agent perception via metadata fields such as name, description, readOnlyHint, and inputSchema). The central claim is that an implementation demonstrates both attack types successfully disrupt WebMCP functionality; the paper concludes with mitigation recommendations including origin binding, lifecycle consistency, data boundaries, and traceable logs.
Significance. If the implementation claim were substantiated with verifiable methods and results, the work would identify a previously unexamined attack surface arising from WebMCP's dynamic tool lifecycle and structured metadata. This could usefully inform protocol design for LLM-agent web interactions. The current manuscript, however, supplies no experimental details, data, or verification, so the practical significance cannot be assessed.
major comments (2)
- [Abstract] Abstract: the assertion that 'Our implementation demonstrates that both Tool Hijacking and Tool Framing can successfully disrupt the intended functionality of WebMCP' is unsupported by any methods, data, error analysis, or verification details. This claim is load-bearing for the paper's central contribution.
- [Abstract / Classification of MSTI] Classification of MSTI (Tool Hijacking paragraph): the premise that third-party scripts can leverage the AbortSignal API or race conditions during tool registration to modify the set of tools visible to the agent is stated without any mechanism description, runtime model, or feasibility argument under standard web isolation constraints. If this premise does not hold, both the classification and the disruption claim collapse.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify that the manuscript's central claims require additional substantiation through experimental details and mechanism descriptions. We address each major comment below and commit to revisions that will strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Our implementation demonstrates that both Tool Hijacking and Tool Framing can successfully disrupt the intended functionality of WebMCP' is unsupported by any methods, data, error analysis, or verification details. This claim is load-bearing for the paper's central contribution.
Authors: We agree that the abstract claim is currently unsupported by verifiable details in the manuscript. The revised version will add a new Implementation and Evaluation section describing the experimental setup, attack reproduction methods for both categories, observed outcomes, verification procedures, and any limitations or error considerations. revision: yes
-
Referee: [Abstract / Classification of MSTI] Classification of MSTI (Tool Hijacking paragraph): the premise that third-party scripts can leverage the AbortSignal API or race conditions during tool registration to modify the set of tools visible to the agent is stated without any mechanism description, runtime model, or feasibility argument under standard web isolation constraints. If this premise does not hold, both the classification and the disruption claim collapse.
Authors: The classification is based on the WebMCP protocol specification's handling of dynamic tool registration and AbortSignal usage. We acknowledge the absence of an explicit runtime model and feasibility analysis under web isolation constraints. The revised manuscript will expand the Classification of MSTI section with a detailed mechanism description, a runtime model, and arguments addressing feasibility within standard web security boundaries such as the same-origin policy. revision: yes
Circularity Check
No circularity: descriptive security analysis with no derivations or self-referential reductions
full rationale
The paper is a descriptive security analysis identifying and classifying a threat (MSTI) via Tool Hijacking and Tool Framing, supported by an implementation demonstration. No equations, parameters, derivations, or load-bearing self-citations appear in the provided text. The central claims rest on described web mechanisms and runtime behavior rather than reducing to fitted inputs or prior self-authored results by construction. This is the expected non-finding for a non-mathematical security paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption WebMCP enables dynamic exposure of agent-accessible tools from websites, including via third-party scripts
- domain assumption Mechanisms such as AbortSignal API and race conditions during tool registration can be exploited in active sessions
invented entities (3)
-
Mid-Session Tool Injection (MSTI)
no independent evidence
-
Tool Hijacking
no independent evidence
-
Tool Framing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NDSS , year=
Les Dissonances: Cross-Tool Harvesting and Polluting in Pool-of-Tools Empowered LLM Agents , author=. NDSS , year=
-
[2]
Zenodo , year=
The Temporal Coherence Problem: Synthetic Point-in-Time Environments for Evaluating LLM Agents with Dynamic Tool Dependencies , author=. Zenodo , year=
-
[3]
arXiv preprint arXiv:2509.20386 , year=
Dynamic react: Scalable tool selection for large-scale mcp environments , author=. arXiv preprint arXiv:2509.20386 , year=
-
[5]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ StruQ \ : Defending against prompt injection with structured queries , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Automatic Red Teaming LLM-based Agents with Model Context Protocol Tools , year=
He, Ping and Li, Changjiang and Zhao, Binbin and Du, Tianyu and Ji, Shouling , journal=. Automatic Red Teaming LLM-based Agents with Model Context Protocol Tools , year=
-
[10]
NDSS , year=
ObliInjection: Order-Oblivious Prompt Injection Attack to LLM Agents with Multi-source Data , author=. NDSS , year=
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webinject: Prompt injection attack to web agents , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[12]
IJCAI , year=
Odyssey: Empowering minecraft agents with open-world skills , author=. IJCAI , year=
-
[13]
ACM Transactions on Software Engineering and Methodology , year=
Model context protocol (mcp): Landscape, security threats, and future research directions , author=. ACM Transactions on Software Engineering and Methodology , year=
-
[15]
Computer , volume=
Malicious bots threaten network security , author=. Computer , volume=. 2005 , publisher=
2005
-
[16]
Information , volume=
Prompt Injection Attacks in Large Language Models and AI Agent Systems: A Comprehensive Review of Vulnerabilities, Attack Vectors, and Defense Mechanisms , author=. Information , volume=. 2026 , publisher=
2026
-
[17]
Ieee Access , volume=
Artificial intelligence crime: An overview of malicious use and abuse of AI , author=. Ieee Access , volume=. 2022 , publisher=
2022
-
[18]
AJCAI , year=
Advancing embodied agent security: From safety benchmarks to input moderation , author=. AJCAI , year=
-
[21]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Topicattack: An indirect prompt injection attack via topic transition , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[22]
Les dissonances: Cross-tool harvesting and polluting in pool-of-tools empowered llm agents
Zichuan Li, Jian Cui, Xiaojing Liao, and Luyi Xing. Les dissonances: Cross-tool harvesting and polluting in pool-of-tools empowered llm agents. In NDSS, 2025
2025
-
[23]
Tl-training: A task-feature-based framework for training large language models in tool use
Junjie Ye, Yilong Wu, Sixian Li, Yuming Yang, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang, Peng Wang, Zhongchao Shi, et al. Tl-training: A task-feature-based framework for training large language models in tool use. arXiv preprint arXiv:2412.15495, 2024
-
[24]
Automatic red teaming llm-based agents with model context protocol tools
Ping He, Changjiang Li, Binbin Zhao, Tianyu Du, and Shouling Ji. Automatic red teaming llm-based agents with model context protocol tools. IEEE Transactions on Information Forensics and Security, pages 1--1, 2026. doi:10.1109/TIFS.2026.3691201
-
[25]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Advances in Neural Information Processing Systems, 37: 0 82895--82920, 2024
2024
-
[26]
\ StruQ \ : Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. \ StruQ \ : Defending against prompt injection with structured queries. In 34th USENIX Security Symposium (USENIX Security 25), pages 2383--2400, 2025 a
2025
-
[27]
The temporal coherence problem: Synthetic point-in-time environments for evaluating llm agents with dynamic tool dependencies
Danish Shaikh. The temporal coherence problem: Synthetic point-in-time environments for evaluating llm agents with dynamic tool dependencies. Zenodo, 2026
2026
-
[28]
From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers
Yiheng Huang, Zhijia Zhao, Bihuan Chen, Susheng Wu, Zhuotong Zhou, Yiheng Cao, Xin Hu, and Xin Peng. From component manipulation to system compromise: Understanding and detecting malicious mcp servers. arXiv preprint arXiv:2604.01905, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Obliinjection: Order-oblivious prompt injection attack to llm agents with multi-source data
Reachal Wang, Yuqi Jia, and Neil Zhenqiang Gong. Obliinjection: Order-oblivious prompt injection attack to llm agents with multi-source data. NDSS, 2025 a
2025
-
[30]
Model context protocol (mcp): Landscape, security threats, and future research directions
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions. ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[31]
When mcp servers attack: Taxonomy, feasibility, and mitigation
Weibo Zhao, Jiahao Liu, Bonan Ruan, Shaofei Li, and Zhenkai Liang. When mcp servers attack: Taxonomy, feasibility, and mitigation. arXiv preprint arXiv:2509.24272, 2025
-
[32]
Webinject: Prompt injection attack to web agents
Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhenqiang Gong. Webinject: Prompt injection attack to web agents. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2010--2030, 2025 b
2025
-
[33]
Odyssey: Empowering minecraft agents with open-world skills
Shunyu Liu, Yaoru Li, Kongcheng Zhang, Zhenyu Cui, Wenkai Fang, Yuxuan Zheng, Tongya Zheng, and Mingli Song. Odyssey: Empowering minecraft agents with open-world skills. IJCAI, 2025
2025
-
[34]
Adaptools: Adaptive tool-based indirect prompt injection attacks on agentic llms
Che Wang, Jiaming Zhang, Ziqi Zhang, Zijie Wang, Yinghui Wang, Jianbo Gao, Tao Wei, Zhong Chen, and Wei Yang Bryan Lim. Adaptools: Adaptive tool-based indirect prompt injection attacks on agentic llms. arXiv preprint arXiv:2602.20720, 2026
-
[35]
Topicattack: An indirect prompt injection attack via topic transition
Yulin Chen, Haoran Li, Yuexin Li, Yue Liu, Yangqiu Song, and Bryan Hooi. Topicattack: An indirect prompt injection attack via topic transition. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7338--7356, 2025 b
2025
-
[36]
Prompt injection attacks in large language models and ai agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms
Saidakhror Gulyamov, Said Gulyamov, Andrey Rodionov, Rustam Khursanov, Kambariddin Mekhmonov, Djakhongir Babaev, and Akmaljon Rakhimjonov. Prompt injection attacks in large language models and ai agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms. Information, 17 0 (1): 0 54, 2026
2026
-
[37]
Artificial intelligence crime: An overview of malicious use and abuse of ai
Ta \' s Fernanda Blauth, Oskar Josef Gstrein, and Andrej Zwitter. Artificial intelligence crime: An overview of malicious use and abuse of ai. Ieee Access, 10: 0 77110--77122, 2022
2022
-
[38]
Advancing embodied agent security: From safety benchmarks to input moderation
Ning Wang, Zihan Yan, Weiyang Li, Chuan Ma, He Chen, and Tao Xiang. Advancing embodied agent security: From safety benchmarks to input moderation. AJCAI, 2025 c
2025
-
[39]
Clawed and dangerous: Can we trust open agentic systems? arXiv preprint arXiv:2603.26221, 2026
Shiping Chen, Qin Wang, Guangsheng Yu, Xu Wang, and Liming Zhu. Clawed and dangerous: Can we trust open agentic systems? arXiv preprint arXiv:2603.26221, 2026
-
[40]
A framework for formalizing llm agent security
Vincent Siu, Jingxuan He, Kyle Montgomery, Zhun Wang, Neil Gong, Chenguang Wang, and Dawn Song. A framework for formalizing llm agent security. arXiv preprint arXiv:2603.19469, 2026
-
[41]
@mcp-b/global: W3C Web Model Context API polyfill
MCP-B Community . @mcp-b/global: W3C Web Model Context API polyfill . https://github.com/WebMCP-org/npm-packages
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.