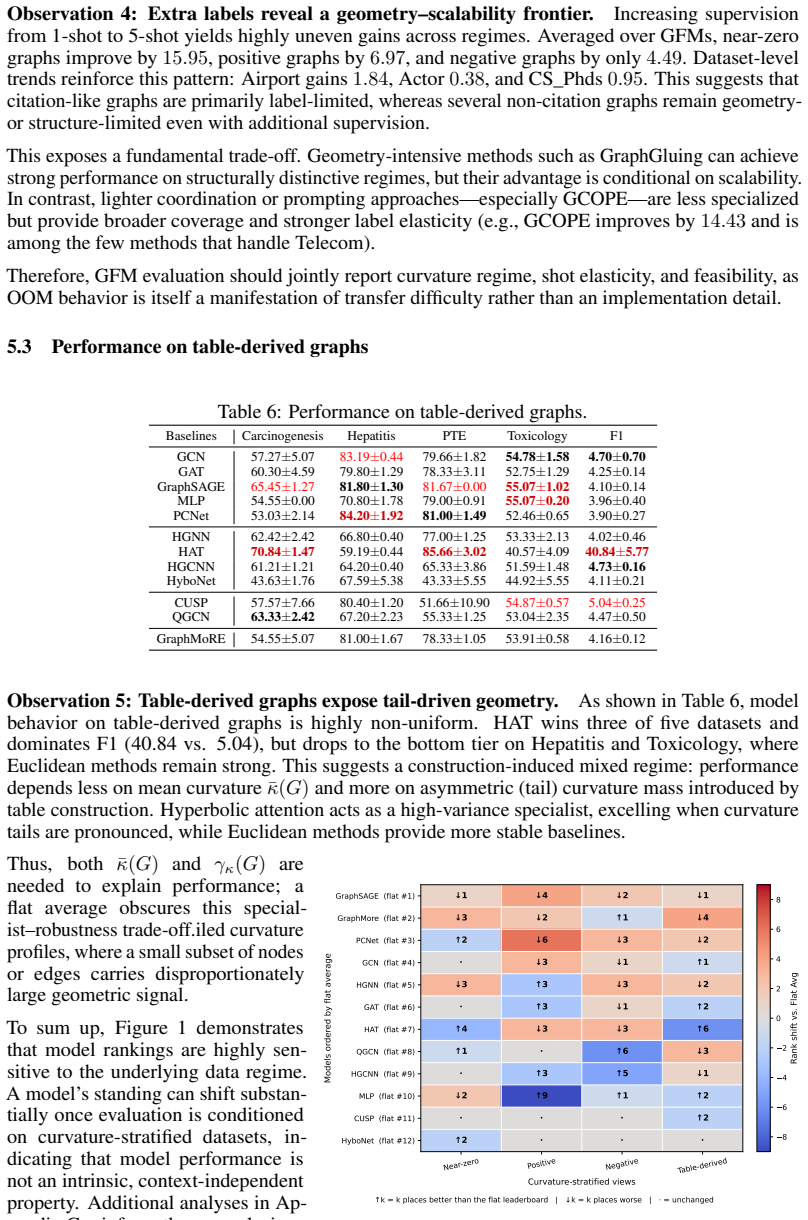
The Post-GCN Decade Revisited: Curvature-Stratified Evaluation of Relational Learning
Pith reviewed 2026-06-28 02:37 UTC · model grok-4.3
The pith
Relational learning model rankings depend on dataset curvature rather than being universal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Model rankings are highly stable within each curvature regime but shift significantly across regimes, indicating that performance is fundamentally geometry-dependent rather than universally transferable.
What carries the argument
Curvature-stratified evaluation framework that partitions datasets into positive, negative, and near-zero curvature regimes.
If this is right
- Model rankings remain consistent when datasets share the same curvature regime.
- Performance comparisons across different curvature regimes can lead to misleading conclusions about model superiority.
- Graph foundation models show diminishing returns in certain curvature regimes compared to geometry-aligned graph neural networks.
- Geometry-aware evaluation provides more interpretable and reliable model assessments than aggregated benchmarks.
Where Pith is reading between the lines
- Future model development could benefit from explicitly incorporating curvature awareness in architectures.
- Dataset selection for benchmarks should prioritize diversity in geometric properties to avoid biased evaluations.
- Similar stratification approaches might apply to other latent structural factors beyond curvature.
Load-bearing premise
Curvature serves as the primary latent geometric factor that governs model effectiveness across datasets.
What would settle it
If model rankings do not shift when comparing performance across datasets from different curvature regimes, the claim of geometry-dependent performance would be falsified.
Figures

read the original abstract
Current evaluation practices in relational learning rely heavily on flat leaderboards that average performance across heterogeneous datasets, implicitly assuming a uniform underlying structure. We show that this assumption introduces systematic bias: it obscures geometry-dependent performance variations and can lead to misleading conclusions about model generalization. In this work, we identify intrinsic geometry as a key latent factor governing model effectiveness. We demonstrate that conventional aggregated metrics mask critical performance trade-offs that only become visible when datasets are stratified by their geometric properties. To address this issue, we introduce a curvature-stratified evaluation framework that partitions datasets into positive, negative, and near-zero curvature regimes. Our benchmark evaluates 18 representative models including Graph Convolutional Networks (GCNs), Graph Foundation Models (GFMs), and tabular learning methods across 14 datasets. We find that model rankings are highly stable within each curvature regime but shift significantly across regimes, indicating that performance is fundamentally geometry-dependent rather than universally transferable. Notably, we identify regimes where GFMs offer diminishing returns compared to geometry-aligned GNNs. Based on these findings, we propose a geometry-aware evaluation protocol that yields more reliable and interpretable comparisons than standard aggregated benchmarks. We release all code, curvature-stratified dataset splits, and evaluation tools to support reproducible and rigorous assessment of future relational learning methods. Code and datasets are provided in our project homepage: https://sirbabbage.github.io/CurvBench_HOME/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that conventional aggregated leaderboards in relational learning introduce systematic bias by averaging over heterogeneous datasets and ignoring intrinsic geometry. It introduces a curvature-stratified evaluation framework that partitions 14 datasets into positive, negative, and near-zero curvature regimes, evaluates 18 models (including GCNs, GFMs, and tabular methods), and reports that model rankings are stable within each regime but shift significantly across regimes. This is taken to indicate that performance is fundamentally geometry-dependent; the work proposes a geometry-aware evaluation protocol and releases code, curvature-stratified splits, and tools.
Significance. If the stratification isolates curvature as the primary factor, the results would support a shift from flat leaderboards toward geometry-aware benchmarks, with practical implications for model selection (e.g., regimes where GFMs yield diminishing returns). The release of code, splits, and evaluation tools is a clear strength that enables reproducibility and extension by others.
major comments (3)
- [Abstract and §4] Abstract and §4: the claim that rankings 'shift significantly across regimes' is presented without any statistical tests (e.g., rank-correlation p-values, permutation tests on rank differences, or bootstrap intervals), so it is impossible to determine whether the observed changes exceed sampling variability.
- [§3] §3 (Curvature Stratification) and methods: the partitioning into positive/negative/near-zero regimes depends on unspecified thresholds that are free parameters; no sensitivity analysis or justification is provided, so the reported within-regime stability and cross-regime shifts may be artifacts of these cutoffs.
- [§4] §4 (Experiments): no controls, matching, or multivariate regression are described for potential confounders (node/edge count, density, average degree, homophily, task type) that may covary with curvature regime; without such checks the attribution of ranking changes specifically to geometry rather than these covariates remains unverified.
minor comments (2)
- [§4] A summary table listing each of the 14 datasets, its computed curvature, assigned regime, and basic statistics (size, density) would make the stratification transparent.
- [§3] The precise discrete curvature formula employed (e.g., Forman, Ollivier, or other) and any implementation details or verification steps should be stated explicitly in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify opportunities to strengthen the statistical support for our claims and to verify that curvature, rather than correlated dataset properties, drives the observed ranking shifts. We respond to each point below and will incorporate the suggested analyses in the revision.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: the claim that rankings 'shift significantly across regimes' is presented without any statistical tests (e.g., rank-correlation p-values, permutation tests on rank differences, or bootstrap intervals), so it is impossible to determine whether the observed changes exceed sampling variability.
Authors: We agree that formal statistical tests are required. In the revised manuscript we will add Kendall’s tau rank correlations (with p-values) between the model orderings obtained in each curvature regime. We will also report bootstrap confidence intervals on both per-model performance and on the rank positions themselves, computed over 1000 resamples of the test splits within each regime. These results will appear in Section 4 and will be referenced from the abstract. revision: yes
-
Referee: [§3] §3 (Curvature Stratification) and methods: the partitioning into positive/negative/near-zero regimes depends on unspecified thresholds that are free parameters; no sensitivity analysis or justification is provided, so the reported within-regime stability and cross-regime shifts may be artifacts of these cutoffs.
Authors: We accept that the thresholds must be justified and tested. The revision will explicitly state the curvature cut-offs (chosen at the 33rd and 66th percentiles of the empirical distribution of Ollivier-Ricci curvatures across the 14 datasets) together with a geometric motivation. We will add a sensitivity study that re-partitions the data at ±10 % and ±20 % shifts of these thresholds and confirms that the within-regime stability and cross-regime rank changes remain qualitatively unchanged. The sensitivity results will be placed in the supplementary material. revision: yes
-
Referee: [§4] §4 (Experiments): no controls, matching, or multivariate regression are described for potential confounders (node/edge count, density, average degree, homophily, task type) that may covary with curvature regime; without such checks the attribution of ranking changes specifically to geometry rather than these covariates remains unverified.
Authors: This is a valid methodological concern. The revised Section 4 will include multivariate regressions of model performance on curvature regime while controlling for the listed covariates. We will report both the coefficient on the curvature-regime indicator and the associated partial R² after accounting for the covariates. Variance-inflation factors will be checked, and, where feasible, we will apply propensity-score matching on the continuous covariates to compare performance across regimes on matched subsets. Any remaining limitations on isolating curvature will be discussed explicitly. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent observations
full rationale
This paper presents an empirical benchmark study that partitions 14 datasets into curvature regimes (positive, negative, near-zero) and reports observed model performance rankings within and across strata. No equations, fitted parameters, or derivations are described that reduce to inputs by construction. The central claim rests on direct performance measurements rather than self-citation chains or ansatzes. Self-citations, if present, are not load-bearing for the reported results. This matches the default expectation of an honest non-finding for empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- curvature regime thresholds
axioms (1)
- domain assumption Curvature is a computable intrinsic geometric property that governs relational model performance differences
Reference graph
Works this paper leans on
-
[1]
Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, and Jure Leskovec. Relational deep learning: Graph representation learning on relational databases.arXiv preprint arXiv:2312.04615, 2023
arXiv 2023
-
[2]
Relbench: A benchmark for deep learning on relational databases
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan Eric Lenssen, Yiwen Yuan, Zecheng Zhang, Xinwei He, and Jure Leskovec. Relbench: A benchmark for deep learning on relational databases. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2024
2024
-
[3]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs.arXiv preprint arXiv:2007.08663, 2020
Pith/arXiv arXiv 2007
-
[4]
Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S
Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay Pande. Moleculenet: A benchmark for molecular machine learning.Chemical Science, 9(2):513–530, 2018
2018
-
[5]
Carte: Pretraining and transfer for tabular learning
Myung Jun Kim, Leo Grinsztajn, and Gael Varoquaux. Carte: Pretraining and transfer for tabular learning. InInternational Conference on Machine Learning, pages 23843–23866. PMLR, 2024
2024
-
[6]
Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c
Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
Pith/arXiv arXiv 2021
-
[7]
Ricci curvature of markov chains on metric spaces.Journal of Functional Analysis, 256(3):810–864, 2009
Yann Ollivier. Ricci curvature of markov chains on metric spaces.Journal of Functional Analysis, 256(3):810–864, 2009
2009
-
[8]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, 2017
2017
-
[9]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. InAdvances in Neural Information Processing Systems, 2017
2017
-
[10]
Graph attention networks
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, 2018
2018
-
[11]
Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling
Michael Schlichtkrull, Thomas N. Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. InEuropean Semantic Web Conference, pages 593–607. Springer, 2018
2018
-
[12]
Graph foundation models: A comprehensive survey.arXiv preprint arXiv:2505.15116, 2025
Zehong Wang, Zheyuan Liu, Tianyi Ma, Jiazheng Li, Zheyuan Zhang, Xingbo Fu, Yiyang Li, Zhengqing Yuan, Wei Song, Yijun Ma, Qingkai Zeng, Xiusi Chen, Jianan Zhao, Jundong Li, Meng Jiang, Pietro Liò, Nitesh Chawla, Chuxu Zhang, and Yanfang Ye. Graph foundation models: A comprehensive survey.arXiv preprint arXiv:2505.15116, 2025
arXiv 2025
-
[13]
All in one and one for all: A simple yet effective method towards cross-domain graph pretraining
Haihong Zhao, Aochuan Chen, Xiangguo Sun, Hong Cheng, and Jia Li. All in one and one for all: A simple yet effective method towards cross-domain graph pretraining. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024
2024
-
[14]
Xingtong Yu, Chang Zhou, Yuan Fang, and Xinming Zhang. Text-free multi-domain graph pre-training: Toward graph foundation models.arXiv preprint arXiv:2405.13934, 2024
arXiv 2024
-
[15]
Multi-domain graph foundation models: Robust knowledge transfer via topology alignment
Shuo Wang, Bokui Wang, Zhixiang Shen, Boyan Deng, and Zhao Kang. Multi-domain graph foundation models: Robust knowledge transfer via topology alignment. InInternational Conference on Machine Learning, 2025
2025
-
[16]
Poincaré embeddings for learning hierarchical represen- tations
Maximilian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical represen- tations. InAdvances in Neural Information Processing Systems, 2017
2017
-
[17]
Hyperbolic graph convolutional neural networks
Ines Chami, Zhitao Ying, Christopher Ré, and Jure Leskovec. Hyperbolic graph convolutional neural networks. InAdvances in Neural Information Processing Systems, 2019. 11
2019
-
[18]
Design space for graph neural networks
Jiaxuan You, Rex Ying, and Jure Leskovec. Design space for graph neural networks. In Advances in Neural Information Processing Systems, 2020
2020
-
[19]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. InAdvances in Neural Information Processing Systems, 2020
2020
-
[20]
Joshi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson
Vijay Prakash Dwivedi, Chaitanya K. Joshi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Benchmarking graph neural networks.Journal of Machine Learning Research, 24(43):1–48, 2023
2023
-
[21]
Bochner’s method for cell complexes and combinatorial ricci curvature.Discrete & Computational Geometry, 29(3):323–374, 2003
Robin Forman. Bochner’s method for cell complexes and combinatorial ricci curvature.Discrete & Computational Geometry, 29(3):323–374, 2003
2003
-
[22]
Ricci curvature of the internet topology
Chien-Chun Ni, Yu-Yao Lin, Jie Gao, Xianfeng David Gu, and Emil Saucan. Ricci curvature of the internet topology. InIEEE Conference on Computer Communications, pages 2758–2766. IEEE, 2015
2015
-
[23]
Hyperbolic neural networks
Octavian-Eugen Ganea, Gary Bécigneul, and Thomas Hofmann. Hyperbolic neural networks. InAdvances in Neural Information Processing Systems, 2018
2018
-
[24]
Hyperbolic graph neural networks
Qi Liu, Maximilian Nickel, and Douwe Kiela. Hyperbolic graph neural networks. InAdvances in Neural Information Processing Systems, 2019
2019
-
[25]
Mixed-curvature variational autoencoders
Ondrej Skopek, Octavian-Eugen Ganea, and Gary Bécigneul. Mixed-curvature variational autoencoders. InInternational Conference on Learning Representations, 2020
2020
-
[26]
Constant curvature graph convolutional networks.Proceedings of Machine Learning Research, 119:486–496, 2020
Gregor Bachmann, Gary Bécigneul, and Octavian-Eugen Ganea. Constant curvature graph convolutional networks.Proceedings of Machine Learning Research, 119:486–496, 2020
2020
-
[27]
Learning mixed-curvature rep- resentations in product spaces
Albert Gu, Frederic Sala, Beliz Gunel, and Christopher Ré. Learning mixed-curvature rep- resentations in product spaces. InInternational Conference on Learning Representations, 2019
2019
-
[28]
Pseudo- riemannian graph convolutional networks
Bo Xiong, Shichao Zhu, Nico Potyka, Shirui Pan, Chuan Zhou, and Steffen Staab. Pseudo- riemannian graph convolutional networks. InAdvances in Neural Information Processing Systems, 2022
2022
-
[29]
Ioannidis, and Christos Faloutsos
Karish Grover, Haiyang Yu, Xiang Song, Qi Zhu, Han Xie, Vassilis N. Ioannidis, and Christos Faloutsos. Spectro-riemannian graph neural networks. InInternational Conference on Learning Representations, 2025
2025
-
[30]
American Mathematical Society, Providence, RI, 2001
Dmitri Burago, Yuri Burago, and Sergei Ivanov.A Course in Metric Geometry, volume 33 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2001
2001
-
[31]
Bridson and André Haefliger.Metric Spaces of Non-Positive Curvature, volume 319 ofGrundlehren der mathematischen Wissenschaften
Martin R. Bridson and André Haefliger.Metric Spaces of Non-Positive Curvature, volume 319 ofGrundlehren der mathematischen Wissenschaften. Springer, Berlin, Heidelberg, 1999
1999
-
[32]
D. N. Joanes and C. A. Gill. Comparing measures of sample skewness and kurtosis.Journal of the Royal Statistical Society: Series D (The Statistician), 47(1):183–189, 1998
1998
-
[33]
Revisiting semi-supervised learning with graph embeddings.arXiv (Cornell University), 2022
Zhilin Yang, William Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings.arXiv (Cornell University), 2022
2022
-
[34]
Geom-gcn: Geometric graph convolutional networks.ICLR, 2020
Hongbin Pei, Bingzhe Wei, Kevin Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks.ICLR, 2020
2020
-
[35]
Min Zhou, Bisheng Li, Menglin Yang, and Lujia Pan. Telegraph: A benchmark dataset for hierarchical link prediction.arXiv (Cornell University), abs/2204.07703, 2022
arXiv 2022
-
[36]
Rossi and Nesreen K
Ryan A. Rossi and Nesreen K. Ahmed. The network data repository with interactive graph analytics and visualization. InAAAI, 2015. 12
2015
-
[37]
The predictive toxicology evaluation challenge
SH Muggleton. The predictive toxicology evaluation challenge. InIJCAI-97: Proceedings of the Fifteenth International Joint Conference on Artificial Intelligence, Nagoya, Japan, August 23-29, 1997, volume 2, page 4. Morgan Kaufmann, 1997
1997
-
[38]
Policy-based memoization for ilp-based concept discovery systems.Journal of Intelligent Information Systems, 46(1):99–120, 2016
Alev Mutlu and Pinar Karagoz. Policy-based memoization for ilp-based concept discovery systems.Journal of Intelligent Information Systems, 46(1):99–120, 2016
2016
-
[39]
Pc-conv: Unifying homophily and heterophily with two-fold filtering
Bingheng Li, Erlin Pan, and Zhao Kang. Pc-conv: Unifying homophily and heterophily with two-fold filtering. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 13437–13445, 2024
2024
-
[40]
Hyperbolic graph attention network.IEEE Transactions on Big Data, 8(6):1690–1701, 2021
Yiding Zhang, Xiao Wang, Chuan Shi, Xunqiang Jiang, and Yanfang Ye. Hyperbolic graph attention network.IEEE Transactions on Big Data, 8(6):1690–1701, 2021
2021
-
[41]
Fully hyperbolic neural networks
Weize Chen, Xu Han, Yankai Lin, Hexu Zhao, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. Fully hyperbolic neural networks. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5672–5686, 2022
2022
-
[42]
Graphmore: Mitigating topological heterogeneity via mixture of riemannian experts
Zihao Guo, Qingyun Sun, Haonan Yuan, Xingcheng Fu, Min Zhou, Yisen Gao, and Jianxin Li. Graphmore: Mitigating topological heterogeneity via mixture of riemannian experts. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11754–11762, 2025
2025
-
[43]
Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation
Xingtong Yu, Zechuan Gong, Chang Zhou, Yuan Fang, and Hui Zhang. Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation. InProceedings of the ACM Web Conference, 2025
2025
-
[44]
Li Sun, Zhenhao Huang, Silei Chen, Lanxu Yang, Junda Ye, Sen Su, and Philip S. Yu. Multi- domain riemannian graph gluing for building graph foundation models. InInternational Conference on Learning Representations, 2026
2026
-
[45]
Sa2gfm: Enhancing robust graph foundation models with structure-aware semantic augmentation
Junhua Shi, Qingyun Sun, Haonan Yuan, and Xingcheng Fu. Sa2gfm: Enhancing robust graph foundation models with structure-aware semantic augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 15716–15724, 2026
2026
-
[46]
On lipschitz embedding of finite metric spaces in hilbert space.Israel Journal of Mathematics, 52(1-2):46–52, 1985
Jean Bourgain. On lipschitz embedding of finite metric spaces in hilbert space.Israel Journal of Mathematics, 52(1-2):46–52, 1985
1985
-
[47]
The geometry of graphs and some of its algorithmic applications.Combinatorica, 15(2):215–245, 1995
Nathan Linial, Eran London, and Yuri Rabinovich. The geometry of graphs and some of its algorithmic applications.Combinatorica, 15(2):215–245, 1995
1995
-
[48]
The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
Charles Spearman. The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
1904
-
[49]
Maurice G. Kendall. A new measure of rank correlation.Biometrika, 30(1/2):81–93, 1938
1938
-
[50]
Étude comparative de la distribution florale dans une portion des alpes et du jura
Paul Jaccard. Étude comparative de la distribution florale dans une portion des alpes et du jura. Bulletin de la Société Vaudoise des Sciences Naturelles, 37:547–579, 1901
1901
-
[51]
Lorentzian graph convolu- tional networks
Yiding Zhang, Xiao Wang, Chuan Shi, Nian Liu, and Guojie Song. Lorentzian graph convolu- tional networks. InProceedings of The Web Conference, pages 1249–1261, 2021
2021
-
[52]
Curvature graph neural network.Information Sciences, 592:50–66, 2022
Haifeng Li, Jun Cao, Jiawei Zhu, Yu Liu, Qing Zhu, and Guohua Wu. Curvature graph neural network.Information Sciences, 592:50–66, 2022
2022
-
[53]
Position: Graph foundation models are already here
Haitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, and Jiliang Tang. Position: Graph foundation models are already here. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[54]
Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018. 13
Pith/arXiv arXiv 2018
-
[55]
A survey on foundation models for structured data: Tabular, time series, and graphs
Qingyun Sun, Haonan Yuan, Yi Huang, Ziwei Zhang, Xingcheng Fu, Ruijie Wang, Haoyi Zhou, Jia Wu, Jianxin Li, and Philip S Yu. A survey on foundation models for structured data: Tabular, time series, and graphs. 2026
2026
-
[56]
Turning tabular foundation models into graph foundation models.arXiv preprint arXiv:2508.20906, 2025
Dmitry Eremeev, Gleb Bazhenov, Oleg Platonov, Artem Babenko, and Liudmila Prokhorenkova. Turning tabular foundation models into graph foundation models.arXiv preprint arXiv:2508.20906, 2025
Pith/arXiv arXiv 2025
-
[57]
Graphoracle: Efficient fully-inductive knowledge graph reasoning via relation-dependency graphs
Enjun Du, Siyi Liu, and Yongqi Zhang. Graphoracle: Efficient fully-inductive knowledge graph reasoning via relation-dependency graphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 19055–19063, 2026
2026
-
[58]
Are we really making much progress? revisiting, benchmarking and refining heterogeneous graph neural networks
Qingsong Lv, Ming Ding, Qiang Liu, Yuxiang Chen, Wenzheng Feng, Siming He, Chang Zhou, Jianguo Jiang, Yuxiao Dong, and Jie Tang. Are we really making much progress? revisiting, benchmarking and refining heterogeneous graph neural networks. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pages 1150–1160, 2021
2021
-
[59]
Graph neural network: A comprehensive review on non-euclidean space.Ieee Access, 9:60588–60606, 2021
Nurul A Asif, Yeahia Sarker, Ripon K Chakrabortty, Michael J Ryan, Md Hafiz Ahamed, Dip K Saha, Faisal R Badal, Sajal K Das, Md Firoz Ali, Sumaya I Moyeen, et al. Graph neural network: A comprehensive review on non-euclidean space.Ieee Access, 9:60588–60606, 2021
2021
-
[60]
Junda Ye, Zhongbao Zhang, Li Sun, and Siqiang Luo. Mose: Unveiling structural patterns in graphs via mixture of subgraph experts.arXiv preprint arXiv:2509.09337, 2025
arXiv 2025
-
[61]
Cooperation of experts: Fusing heterogeneous information with large margin
Shuo Wang, Shunyang Huang, Jinghui Yuan, Zhixiang Shen, and Zhao Kang. Cooperation of experts: Fusing heterogeneous information with large margin. InInternational Conference on Machine Learning, pages 63169–63185. PMLR, 2025
2025
-
[62]
fatter”-than-Euclidean geometry, while negative values indicate locally “thinner
Zihao Guo, Qingyun Sun, Haonan Yuan, Xingcheng Fu, Min Zhou, Yisen Gao, and Jianxin Li. Graphmore: Mitigating topological heterogeneity via mixture of riemannian experts. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11754–11762, 2025. 14 Contents 1 Introduction 1 2 Graph Curvature 2 3 The Setup of CURVBENCH3 3.1 Datas...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.