Reinforcement Learning Elicits Contextual Learning of Unseen Language Translation
Pith reviewed 2026-06-28 01:17 UTC · model grok-4.3
The pith
Reinforcement learning with a simple translation metric teaches models to extract and apply linguistic knowledge from context for completely unseen languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training with reinforcement learning using chrF as the reward enables models to utilize rich linguistic context for translating languages never seen before, outperforming both in-context learning and supervised fine-tuning by acquiring a general meta-skill instead of memorizing particular languages.
What carries the argument
Reinforcement learning optimized against the chrF surface-level translation metric to elicit extraction and application of in-context linguistic knowledge.
If this is right
- RL models generalize to new languages by applying linguistic information from context instead of language-specific memorization.
- Outcome-based RL serves as a method for language learning from context beyond conventional reasoning tasks.
- Surface-level metrics like chrF can be sufficient to train contextual meta-skills in translation.
- This approach reduces reliance on methods that overfit to specific languages during continued training.
Where Pith is reading between the lines
- The same RL recipe could be tested on other contextual adaptation tasks such as code generation from documentation or few-shot reasoning with rules.
- If the approach scales, it suggests a path to handle hundreds of low-resource languages without per-language fine-tuning.
- Future work could replace chrF with learned rewards to check whether the meta-skill strengthens or if metric hacking increases.
Load-bearing premise
Optimizing for the chrF reward produces genuine meta-learning of linguistic knowledge extraction rather than reward hacking or superficial pattern matching.
What would settle it
Test the RL models on unseen languages after removing or replacing the linguistic context with unrelated text; if translation quality remains high, the claim that context extraction drives the gains would not hold.
Figures
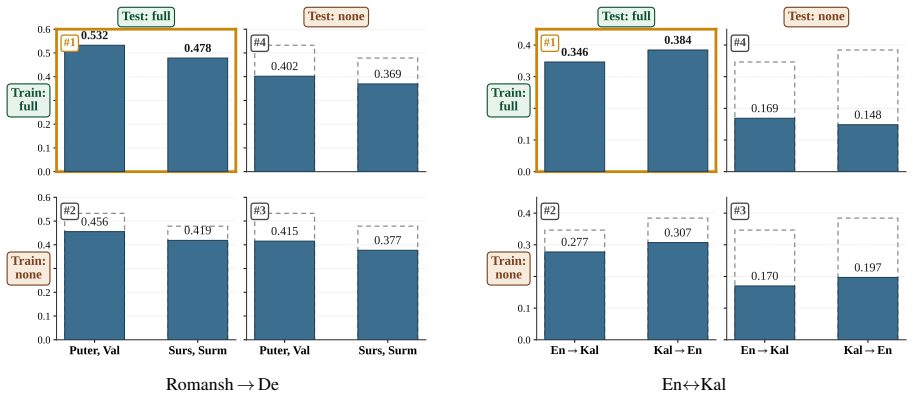
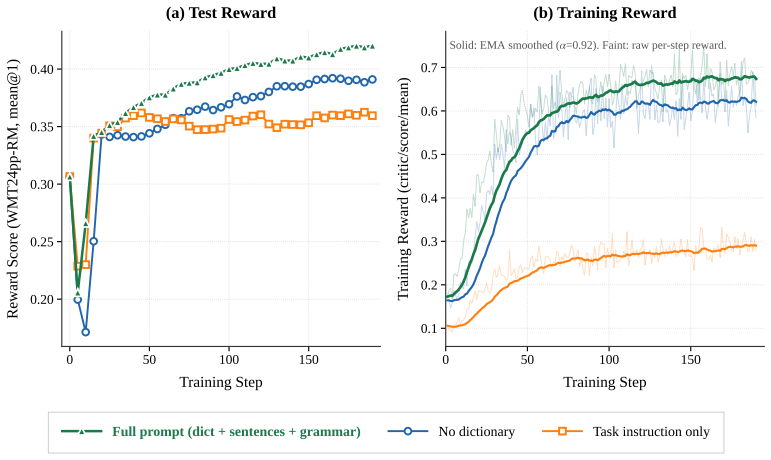
read the original abstract
Prior work has shown that large language models (LLMs) can translate unseen or low-resource languages by undergoing continued training or even by encoding a grammar book in their context. However, both methods typically overfit specific languages, with limited zero-shot transfer at test time. To translate extremely low-resource languages at scale, we argue that LLMs must acquire the meta-skill of utilizing in-context linguistic knowledge rather than memorizing specific languages. In this paper, we propose a reinforcement learning (RL) approach to unseen language translation given rich linguistic context, using a surface-level translation metric (chrF) as the reward. Empirically, despite the lightweight reward, our RL-trained models effectively extract and apply relevant linguistic information from the provided context, leading to better translations on completely unseen languages than in-context learning or supervised fine-tuning. Our analyses suggest that outcome-based RL can extend beyond conventional reasoning tasks like math and coding to serve as a recipe for language learning from context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reinforcement learning with a lightweight chrF reward on rich linguistic context trains LLMs to acquire a meta-skill of extracting and applying linguistic knowledge, yielding better zero-shot translations on completely unseen languages than in-context learning or supervised fine-tuning; analyses suggest outcome-based RL extends to language learning from context.
Significance. If the results hold after verification, the work would demonstrate that RL can elicit contextual meta-learning in language tasks, offering a scalable approach for low-resource translation without language-specific overfitting. The lightweight reward and empirical comparison to ICL/SFT would be notable strengths if shown to reflect genuine linguistic reasoning rather than surface optimization.
major comments (2)
- [Abstract] Abstract: The central empirical claim of superior performance on unseen languages rests on reported gains, but the abstract (and apparent manuscript) provides no details on training setup, number of languages, baselines, evaluation protocol, or statistical significance. This is load-bearing because the meta-learning interpretation cannot be assessed without these elements.
- [Abstract] Abstract: No result or analysis demonstrates that chrF gains depend on linguistic structure (grammar, lexicon) in the context rather than n-gram overlap or surface copying. This is load-bearing for the claim that RL elicits 'contextual learning of unseen language translation' rather than reward hacking on a surface metric.
minor comments (1)
- [Abstract] The abstract refers to 'our analyses' without specifying which sections contain the supporting experiments or controls.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's clarity and the need to substantiate the meta-learning claim. We address each point below and have revised the manuscript to strengthen the presentation of experimental details and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of superior performance on unseen languages rests on reported gains, but the abstract (and apparent manuscript) provides no details on training setup, number of languages, baselines, evaluation protocol, or statistical significance. This is load-bearing because the meta-learning interpretation cannot be assessed without these elements.
Authors: The full manuscript details the training setup (PPO-based RL with chrF reward on rich linguistic contexts), number of languages (training on data from 5 languages, evaluation on 4 completely unseen languages), baselines (ICL with the same linguistic context and SFT on parallel data), evaluation protocol (chrF primary metric plus BLEU, on held-out test sets), and statistical significance (results averaged over 3 random seeds with standard deviations). These appear in Sections 3 (method), 4 (experiments), and 5 (analyses). To make the central claim more self-contained, we have expanded the abstract with a concise summary of these elements. revision: yes
-
Referee: [Abstract] Abstract: No result or analysis demonstrates that chrF gains depend on linguistic structure (grammar, lexicon) in the context rather than n-gram overlap or surface copying. This is load-bearing for the claim that RL elicits 'contextual learning of unseen language translation' rather than reward hacking on a surface metric.
Authors: Section 5 presents multiple analyses addressing this distinction, including (i) ablations that replace grammatical rules and lexical entries in the context with randomized or scrambled versions, resulting in large performance drops, and (ii) direct comparisons against n-gram copying baselines that achieve high surface overlap but low chrF on unseen languages. These results indicate the model utilizes structural information rather than pure surface matching. We have added a new quantitative breakdown correlating chrF improvements with linguistic feature usage (vs. n-gram overlap) to make the evidence more explicit. revision: partial
Circularity Check
No circularity; purely empirical claims with no derivation chain
full rationale
The paper advances an empirical claim that RL with a chrF reward elicits contextual meta-learning for unseen-language translation, supported by experimental comparisons to ICL and SFT. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central argument rests on outcome measurements rather than any reduction of a result to its own inputs by construction, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, and 1 others. 2024. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930--76966
2024
-
[2]
Ahmed Attia and Alham Fikri Aji. 2026. https://arxiv.org/abs/2601.12535 Improving low-resource machine translation via round-trip reinforcement learning . Preprint, arXiv:2601.12535
arXiv 2026
-
[3]
Seth Aycock, David Stap, Di Wu, Christof Monz, and Khalil Sima'an. 2025. https://openreview.net/forum?id=aMBSY2ebPw Can LLM s really learn to translate a low-resource language from one grammar book? In The Thirteenth International Conference on Learning Representations
2025
-
[4]
Russell Barlow. 2023. https://doi.org/10.5281/zenodo.8094859 A grammar of Ulwa ( Papua New Guinea ) . Number 6 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[5]
Hale, and Hannah Rose Kirk
Andrew Michael Bean, Simeon Hellsten, Harry Mayne, Jabez Magomere, Ethan A Chi, Ryan Andrew Chi, Scott A. Hale, and Hannah Rose Kirk. 2024. https://openreview.net/forum?id=cLga8GStdk LINGOLY : A benchmark of olympiad-level linguistic reasoning puzzles in low resource and extinct languages . In The Thirty-eight Conference on Neural Information Processing S...
2024
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://arxiv.org/abs/2005.14165 Lan...
Pith/arXiv arXiv 2020
-
[7]
Gabriela Caballero. 2022. https://doi.org/10.5281/zenodo.7189161 A grammar of Choguita Rarámuri . Number 5 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[8]
Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. 2022. https://doi.org/10.18653/v1/2022.acl-long.53 Meta-learning via language model in-context tuning . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 719--730. Association for Computational Linguistics
-
[9]
Jared Coleman, Bhaskar Krishnamachari, Ruben Rosales, and Khalil Iskarous. 2024. https://doi.org/10.18653/v1/2024.americasnlp-1.9 LLM -assisted rule based machine translation for low/no-resource languages . In Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024), pages 67--87. Associati...
-
[10]
Jared Coleman, Ruben Rosales, Kira Toal, Diego Cuadros, Nicholas Leeds, Bhaskar Krishnamachari, and Khalil Iskarous. 2026. https://doi.org/10.18653/v1/2026.loresmt-1.4 Comparing LLM -based translation approaches for extremely low-resource languages . In Proceedings for the Ninth Workshop on Technologies for Machine Translation of Low Resource Languages ( ...
-
[11]
Zhaopeng Feng, Shaosheng Cao, Jiahan Ren, Jiayuan Su, Ruizhe Chen, Yan Zhang, Jian Wu, and Zuozhu Liu. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1015 MT -r1-zero: Advancing LLM -based machine translation via r1-zero-like reinforcement learning . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 18685--18702, Suzho...
-
[12]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, page 1126–1135. JMLR.org
2017
-
[13]
Fischer, Zachary Hopton, and Jannis Vamvas
Dominic P. Fischer, Zachary Hopton, and Jannis Vamvas. 2026. https://aclanthology.org/2026.swisstext-1.11/ RUMLEM : A dictionary-based lemmatizer for R omansh . In Proceedings of the 11th Edition of the S wiss Text Analytics Conference , pages 125--132, Zurich, Switzerland. Association for Computational Linguistics
2026
-
[14]
Gian Paul Ganzoni. 1983. Grammatica Ladina: Grammatica sistematica dal rumauntsch d'Engiadin'Ota per scolars e creschieus da lingua rumauntscha e tudais-cha. Lia Rumantscha, Chur
1983
-
[15]
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. 2022. https://openreview.net/forum?id=flNZJ2eOet What can transformers learn in-context? a case study of simple function classes . In Advances in Neural Information Processing Systems
2022
-
[16]
Marjan Ghazvininejad, Hila Gonen, and Luke Zettlemoyer. 2023. Dictionary-based phrase-level prompting of large language models for machine translation. arXiv preprint arXiv:2302.07856
arXiv 2023
-
[17]
Nadine Grimm. 2021. https://doi.org/10.5281/zenodo.4737370 A grammar of Gyeli . Number 2 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[18]
Jiatao Gu, Yong Wang, Yun Chen, Victor O. K. Li, and Kyunghyun Cho. 2018. https://doi.org/10.18653/v1/D18-1398 Meta-learning for low-resource neural machine translation . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3622--3631. Association for Computational Linguistics
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement lear...
-
[20]
Ximena Gutierrez, Mikel Segura Elizalde, and Victor Mijangos. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.867 FST s vs ICL : Generalisation in LLM s for an under-resourced language . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 15998--16006, Suzhou, China. Association for Computational Linguistics
-
[21]
Minggui He, Yilun Liu, Shimin Tao, Yuanchang Luo, Hongyong Zeng, Chang Su, Li Zhang, Hongxia Ma, Daimeng Wei, Weibin Meng, Hao Yang, Boxing Chen, and Osamu Yoshie. 2025. https://arxiv.org/abs/2502.19735 R1-t1: Fully incentivizing translation capability in llms via reasoning learning . Preprint, arXiv:2502.19735
arXiv 2025
-
[22]
Zhiwei He, Xing Wang, Wenxiang Jiao, Zhuosheng Zhang, Rui Wang, Shuming Shi, and Zhaopeng Tu. 2024. https://doi.org/10.18653/v1/2024.naacl-long.451 Improving machine translation with human feedback: An exploration of quality estimation as a reward model . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computatio...
-
[23]
Jonathan Hus and Antonios Anastasopoulos. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1127 Back to school: Translation using grammar books . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20207--20219. Association for Computational Linguistics
-
[24]
Vivek Iyer, Bhavitvya Malik, Wenhao Zhu, Pavel Stepachev, Pinzhen Chen, Barry Haddow, and Alexandra Birch. 2024. https://doi.org/10.18653/v1/2024.americasnlp-1.25 Exploring very low-resource translation with LLM s: The U niversity of E dinburgh ' s submission to A mericas NLP 2024 translation task . In Proceedings of the 4th Workshop on Natural Language P...
-
[25]
Guillaume Jacques. 2025. https://doi.org/10.5281/zenodo.16811879 A grammar of Japhug . Number 1 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[26]
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. https://doi.org/10.18653/v1/2020.acl-main.560 The state and fate of linguistic diversity and inclusion in the NLP world . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6282--6293. Association for Computational Linguistics
-
[27]
Tom Kocmi, Sweta Agrawal, Ekaterina Artemova, Eleftherios Avramidis, Eleftheria Briakou, Pinzhen Chen, Marzieh Fadaee, Markus Freitag, Roman Grundkiewicz, Yupeng Hou, Philipp Koehn, Julia Kreutzer, Saab Mansour, Stefano Perrella, Lorenzo Proietti, Parker Riley, Eduardo S \'a nchez, Patricia Schmidtova, Mariya Shmatova, and Vil \'e m Zouhar. 2025. https://...
-
[28]
Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, and 4 others
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, and 4 others. 2025. https://openreview.net/forum?id=i1uGb...
2025
-
[29]
Malik Marmonier, Rachel Bawden, and Beno \^i t Sagot. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1599 Explicit learning and the LLM in machine translation . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31372--31422, Suzhou, China. Association for Computational Linguistics
-
[30]
Philippe Maurer-Cecchini. 2021. https://doi.org/10.5281/zenodo.5137647 A grammar of Tuatschin . Number 3 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[31]
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2022. https://doi.org/10.18653/v1/2022.naacl-main.201 M eta ICL : Learning to learn in context . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2791--2809. Association for Computational...
-
[32]
Manuel Mosquera, Melissa Robles, Johan Rodriguez, and Ruben Manrique. 2025. https://arxiv.org/abs/2508.19481 Improving low-resource translation with dictionary-guided fine-tuning and rl: A spanish-to-wayuunaiki study . Preprint, arXiv:2508.19481
arXiv 2025
-
[33]
OpenAI. 2026. https://arxiv.org/abs/2412.16720 Openai o1 system card . Preprint, arXiv:2412.16720
Pith/arXiv arXiv 2026
-
[34]
Carol J. Pebley and Thomas E. Payne. 2024. https://doi.org/10.5281/zenodo.12755278 A grammar of Kagayanen . Number 8 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[35]
Renhao Pei, Yihong Liu, Peiqin Lin, Fran c ois Yvon, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.acl-long.429 Understanding in-context machine translation for low-resource languages: A case study on M anchu . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8767--878...
-
[36]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395. Association for Computational Linguistics
-
[37]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: memory optimizations toward training trillion parameter models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1--16
2020
-
[38]
Jean Rohleder. 2024. https://doi.org/10.5281/zenodo.126060 A grammar of Vamale . Number 9 in Comprehensive Grammar Library. Language Science Press, Berlin
-
[39]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[40]
Garrett Tanzer, Mirac Suzgun, Eline Visser, Dan Jurafsky, and Luke Melas-Kyriazi. 2024. https://openreview.net/forum?id=tbVWug9f2h A benchmark for learning to translate a new language from one grammar book . In The Twelfth International Conference on Learning Representations
2024
-
[41]
Gion Peder Th \"o ny. 1969. Rumantsch-Surmeir: Grammatica per igl idiom surmiran. Lia Rumantscha, Chur
1969
-
[42]
Jannis Vamvas, Ignacio P \'e rez Prat, Not Soliva, Sandra Baltermia-Guetg, Andrina Beeli, Simona Beeli, Madlaina Capeder, Laura Decurtins, Gian Peder Gregori, Flavia Hobi, Gabriela Holderegger, Arina Lazzarini, Viviana Lazzarini, Walter Rosselli, Bettina Vital, Anna Rutkiewicz, and Rico Sennrich. 2025. https://doi.org/10.18653/v1/2025.wmt-1.79 Expanding t...
-
[43]
Fischer, Sina Ahmadi, and Rico Sennrich
Jannis Vamvas, Ignacio Pérez Prat, Angela Heldstab, Dominic P. Fischer, Sina Ahmadi, and Rico Sennrich. 2026. https://arxiv.org/abs/2603.25489 Translation asymmetry in llms as a data augmentation factor: A case study for 6 romansh language varieties . Preprint, arXiv:2603.25489
arXiv 2026
-
[44]
Eline Visser. 2022. https://doi.org/10.5281/zenodo.6499927 A grammar of Kalamang . Language Science Press
-
[45]
Jiaan Wang, Fandong Meng, and Jie Zhou. 2026. https://doi.org/10.1162/tacl.a.65 D eep T rans: Deep reasoning translation via reinforcement learning . Transactions of the Association for Computational Linguistics, 14:47--63
-
[46]
Wenjie Yang, Mao Zheng, Mingyang Song, Zheng Li, and Sitong Wang. 2026. https://arxiv.org/abs/2505.16637 Ssr-zero: Simple self-rewarding reinforcement learning for machine translation . Preprint, arXiv:2505.16637
Pith/arXiv arXiv 2026
-
[47]
Zheng Xin Yong, Hailey Schoelkopf, Niklas Muennighoff, Alham Fikri Aji, David Ifeoluwa Adelani, Khalid Almubarak, M Saiful Bari, Lintang Sutawika, Jungo Kasai, Ahmed Baruwa, Genta Winata, Stella Biderman, Edward Raff, Dragomir Radev, and Vassilina Nikoulina. 2023. https://doi.org/10.18653/v1/2023.acl-long.653 BLOOM +1: Adding language support to BLOOM for...
-
[48]
Chen Zhang, Jiuheng Lin, Xiao Liu, Zekai Zhang, and Yansong Feng. 2025. https://doi.org/10.18653/v1/2025.acl-long.202 Read it in two steps: Translating extremely low-resource languages with code-augmented grammar books . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3977--3997. As...
-
[49]
Chen Zhang, Xiao Liu, Jiuheng Lin, and Yansong Feng. 2024 a . https://doi.org/10.18653/v1/2024.findings-acl.519 Teaching large language models an unseen language on the fly . In Findings of the Association for Computational Linguistics: ACL 2024, pages 8783--8800. Association for Computational Linguistics
-
[50]
Kexun Zhang, Yee Choi, Zhenqiao Song, Taiqi He, William Yang Wang, and Lei Li. 2024 b . https://doi.org/10.18653/v1/2024.findings-acl.925 Hire a linguist!: Learning endangered languages in LLM s with in-context linguistic descriptions . In Findings of the Association for Computational Linguistics: ACL 2024, pages 15654--15669. Association for Computationa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.