Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Pith reviewed 2026-06-28 00:57 UTC · model grok-4.3
The pith
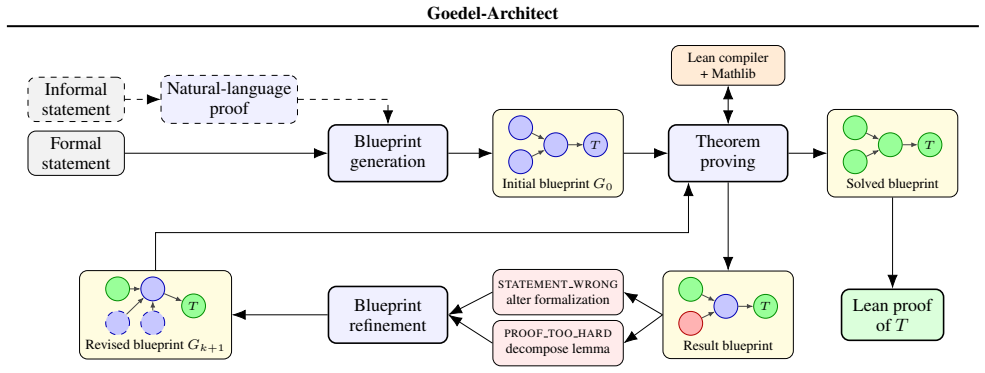
Goedel-Architect generates a dependency graph of lemmas called a blueprint to structure and close formal proofs in Lean 4.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
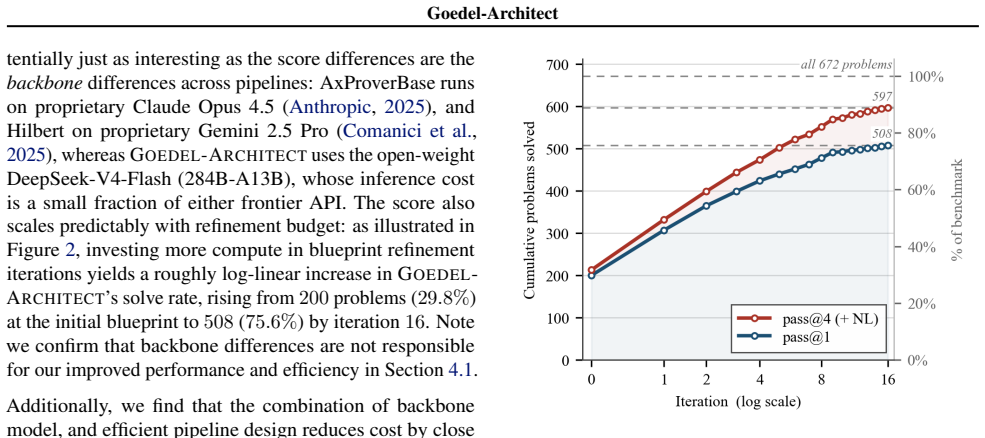
Goedel-Architect generates a blueprint as a dependency graph of formally stated definitions and lemmas with declared dependencies, optionally guided by a natural language proof. A tool-equipped Lean prover closes each open lemma node in parallel using relevant dependencies, and failed lemmas drive refinement of the global blueprint, yielding 99.2 percent pass@1 on MiniF2F-test, 75.6 percent on PutnamBench, and further gains to full coverage on MiniF2F-test plus 88.8 percent on PutnamBench with natural language seeding.
What carries the argument
The blueprint, a dependency graph of definitions and lemmas that builds up to the main theorem.
If this is right
- Parallel closure of individual lemma nodes succeeds when the blueprint supplies relevant dependencies.
- Failure signals from closed lemmas can be used to refine the global graph without restarting from scratch.
- The approach attains 99.2 percent pass@1 on MiniF2F-test and 75.6 percent pass@1 on PutnamBench.
- Natural language proof seeding lifts performance to 100 percent on MiniF2F-test and 88.8 percent on PutnamBench while solving multiple recent competition problems.
Where Pith is reading between the lines
- The same blueprint structure could be tested on theorem proving tasks in formal systems other than Lean 4 to check transfer.
- If blueprint quality scales with model size, the method might further reduce the need for broad search on harder problems.
- The parallel closure plus refinement loop might be combined with existing search-based provers to handle cases where initial blueprints contain gaps.
Load-bearing premise
The initial blueprint generation produces a dependency graph whose lemmas are both formally correct and sufficiently connected that parallel closure plus failure-driven refinement can reach the target theorem without exhaustive search or dead-end loops.
What would settle it
A concrete run on MiniF2F-test or PutnamBench where the generated blueprints repeatedly produce lemmas that remain unclosed after multiple refinement rounds, with no path to the target theorem, would falsify the central claim.
Figures
read the original abstract
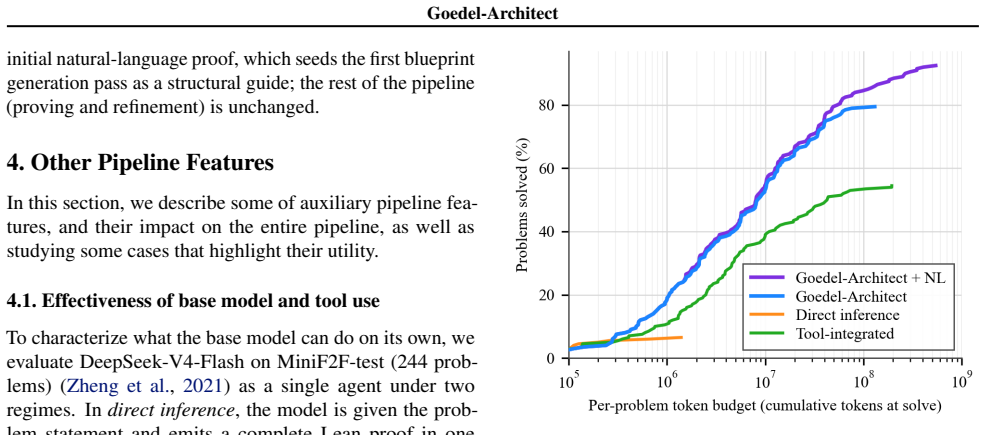
We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Goedel-Architect, an agentic framework for Lean 4 theorem proving centered on generating a blueprint (a dependency graph of formally stated definitions and lemmas, optionally seeded by a natural-language proof), followed by parallel closure of lemma nodes via a tool-equipped prover and failure-driven global refinement. Using DeepSeek-V4-Flash, it reports 99.2% pass@1 on MiniF2F-test (100% with NL seeding), 75.6% on PutnamBench (88.8% with seeding), plus solutions on IMO 2025, Putnam 2025, and USAMO 2026, claiming SOTA for open-source pipelines at substantially lower cost than alternatives.
Significance. If the blueprint generation step reliably emits type-checkable, connected Lean statements whose declared dependencies suffice for parallel closure, the framework could meaningfully reduce dead-end search compared with recursive decomposition methods while delivering high pass rates on established and contest benchmarks. The use of an open-weight model and explicit cost comparison are positive factors for reproducibility and accessibility.
major comments (2)
- [Abstract / Blueprint Generation description] The central performance claims (Abstract) rest on the assumption that the initial blueprint step produces formally correct, acyclic, and sufficiently connected dependency graphs of Lean statements. No results, tables, or sections demonstrate that generated lemmas were independently type-checked in Lean 4 or that the emitted graphs were verified for acyclicity and connectivity; without this, the 99.2%/75.6% figures could be driven primarily by the refinement loop rather than the blueprint architecture itself.
- [Evaluation / Results] Evaluation (implied in Abstract and results paragraphs) reports raw pass@1 numbers without error bars, ablation isolating the contribution of blueprint generation versus refinement, or details on failure selection criteria for refinement. These omissions make it impossible to determine whether the reported gains are robust or sensitive to post-hoc choices.
minor comments (1)
- [Abstract] Notation for the backbone model (DeepSeek-V4-Flash, 284B-A13B) should be clarified with an explicit citation or model card reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Blueprint Generation description] The central performance claims (Abstract) rest on the assumption that the initial blueprint step produces formally correct, acyclic, and sufficiently connected dependency graphs of Lean statements. No results, tables, or sections demonstrate that generated lemmas were independently type-checked in Lean 4 or that the emitted graphs were verified for acyclicity and connectivity; without this, the 99.2%/75.6% figures could be driven primarily by the refinement loop rather than the blueprint architecture itself.
Authors: We agree that explicit verification of blueprint properties is needed to isolate their contribution. The generation process aims to output formally stated Lean statements, but the manuscript does not report independent type-checking success rates, acyclicity checks (e.g., via topological sort), or connectivity metrics. In the revised version, we will add a dedicated subsection reporting these statistics on generated blueprints across benchmarks, clarifying the role of the initial blueprint versus refinement. revision: yes
-
Referee: [Evaluation / Results] Evaluation (implied in Abstract and results paragraphs) reports raw pass@1 numbers without error bars, ablation isolating the contribution of blueprint generation versus refinement, or details on failure selection criteria for refinement. These omissions make it impossible to determine whether the reported gains are robust or sensitive to post-hoc choices.
Authors: We acknowledge these evaluation gaps. The current results lack error bars, ablations, and explicit failure criteria details. The revised manuscript will add error bars from repeated runs, an ablation comparing full pipeline versus blueprint-only or refinement-only variants, and a precise description of failure selection (e.g., criteria based on error types and dependency impact). This will better demonstrate robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a methodological framework for generating and refining blueprints (dependency graphs of lemmas) in Lean 4, followed by empirical measurement of pass@1 rates on fixed external benchmarks (MiniF2F-test, PutnamBench) using an independently released model. No equations, fitted parameters, or derived quantities are defined in terms of the target performance metrics. The reported results are direct experimental outcomes rather than tautological predictions or self-referential constructions. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided material to justify the central claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alexeev, B., Barreto, K., Li, Y ., Lichtman, J. D., Price, L., Shah, J. I., Tang, Q., and Tao, T. Primitive sets and von Mangoldt chains: Erd ˝os Problem #1196 and beyond. arXiv preprint arXiv:2605.00301,
-
[2]
Chen, J., Chen, W., Du, J., Hu, J., Jiang, Z., Jie, A., Jin, X., Jin, X., Li, C., Shi, W., et al. Seed-prover 1.5: Mastering undergraduate-level theorem proving via learning from experience.arXiv preprint arXiv:2512.17260, 2025a. Chen, L., Gu, J., Huang, L., Huang, W., Jiang, Z., Jie, A., Jin, X., Jin, X., Li, C., Ma, K., Ren, C., Shen, J., Shi, W., Sun, ...
-
[3]
URL https://deepmind.google/ blog/advanced-version-of-gemini-with- deep-think-officially-achieves-gold- medal-standard-at-the-international- mathematical-olympiad/. Jiang, A. Q., Welleck, S., Zhou, J. P., Li, W., Liu, J., Jamnik, M., Lacroix, T., Wu, Y ., and Lample, G. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs.arXiv pr...
-
[4]
Li, Y ., Du, D., Song, L., Li, C., Wang, W., Yang, T., and Mi, H. Hunyuanprover: A scalable data synthesis framework and guided tree search for automated theorem proving. arXiv preprint arXiv:2412.20735,
-
[5]
Lean-STaR: Learning to interleave thinking and proving.arXiv preprint arXiv:2407.10040,
Lin, H., Sun, Z., Yang, Y ., and Welleck, S. Lean-STaR: Learning to interleave thinking and proving.arXiv preprint arXiv:2407.10040,
-
[6]
Goedel-Prover: A fron- tier model for open-source automated theorem proving
Lin, Y ., Tang, S., Lyu, B., Wu, J., Lin, H., Yang, K., Li, J., Xia, M., Chen, D., Arora, S., et al. Goedel-Prover: A fron- tier model for open-source automated theorem proving. arXiv preprint arXiv:2502.07640, 2025a. Lin, Y ., Tang, S., Lyu, B., Yang, Z., Chung, J.-H., Zhao, H., Jiang, L., Geng, Y ., Ge, J., Sun, J., et al. Goedel- prover-v2: Scaling for...
-
[7]
Ren, Z., Shao, Z., Song, J., Xin, H., Wang, H., Zhao, W., Zhang, L., Fu, Z., Zhu, Q., Yang, D., et al. Deepseek- prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801,
-
[8]
Requena, B., Letson, A., Nowakowski, K., Ferreiro, I. B., and Sarra, L. A minimal agent for automated theorem proving.arXiv preprint arXiv:2602.24273,
-
[9]
Hilbert: Recursively building formal proofs with informal reasoning.arXiv preprint arXiv:2509.22819,
8 Goedel-Architect Varambally, S., V oice, T., Sun, Y ., Chen, Z., Yu, R., and Ye, K. Hilbert: Recursively building formal proofs with informal reasoning.arXiv preprint arXiv:2509.22819,
-
[10]
D., Sung, F., Vinyes, M., Ying, Z., Zhu, Z., et al
Wang, H., Unsal, M., Lin, X., Baksys, M., Liu, J., Santos, M. D., Sung, F., Vinyes, M., Ying, Z., Zhu, Z., et al. Kimina-prover preview: Towards large formal reason- ing models with reinforcement learning.arXiv preprint arXiv:2504.11354,
-
[11]
Wang, J., Zhang, J., Guo, Q., Guo, L., Li, R., Zhang, C., Peng, C., Wang, C., Zhao, D., Shi, J., et al. Longcat-flash- prover: Advancing native formal reasoning via agentic tool-integrated reinforcement learning.arXiv preprint arXiv:2603.21065,
-
[12]
Theoremllama: Transforming general-purpose llms into lean4 experts.arXiv preprint arXiv:2407.03203,
Wang, R., Zhang, J., Jia, Y ., Pan, R., Diao, S., Pi, R., and Zhang, T. Theoremllama: Transforming general-purpose llms into lean4 experts.arXiv preprint arXiv:2407.03203,
-
[13]
Openai achievement of gold medal standard at the 2025 international mathe- matical olympiad, July
Wei, A., Brown, N., and Hsu, S. Openai achievement of gold medal standard at the 2025 international mathe- matical olympiad, July
2025
-
[14]
Xin, H., Guo, D., Shao, Z., Ren, Z., Zhu, Q., Liu, B., Ruan, C., Li, W., and Liang, X
URL https://x.com/ alexwei_/status/1946477753194484181. Xin, H., Guo, D., Shao, Z., Ren, Z., Zhu, Q., Liu, B., Ruan, C., Li, W., and Liang, X. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data.arXiv preprint arXiv:2405.14333, 2024a. Xin, H., Ren, Z., Song, J., Shao, Z., Zhao, W., Wang, H., Liu, B., Zhang, L., Lu, X., Du...
-
[16]
URL https://arxiv.org/abs/2601.22554. 9 Goedel-Architect A. Compute details blueprint generationBy default, the blueprint generation phase emits a single blueprint to work with. The model’s maximum total token length is set to 262,144 tokens, and it retries up to 8 times if it fails to produce a compiling Lean 4 blueprint. Lean provingBy default, the prov...
arXiv 1971
-
[17]
multiply by four
The recorded diagnosis isolates the gap precisely — complete multiplicativity only forces f(1) =f(1) 2, so f(1) may be 0 or 1, and monotonicity does not exclude the zero solution — and proposes the fix of adding the hypothesis f(1) = 1 . The next iteration’s revision adopts this fix directly: it rewrites the lemma with the extra hypothesis f(1) = 1 and re...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.