TailLoR: Protecting Principal Components in Parameter-Efficient Continual Learning
Pith reviewed 2026-06-28 01:57 UTC · model grok-4.3
The pith
TailLoR keeps singular vector bases U and V fixed while applying low-rank updates to singular values under a soft penalty on dominant directions to limit task interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
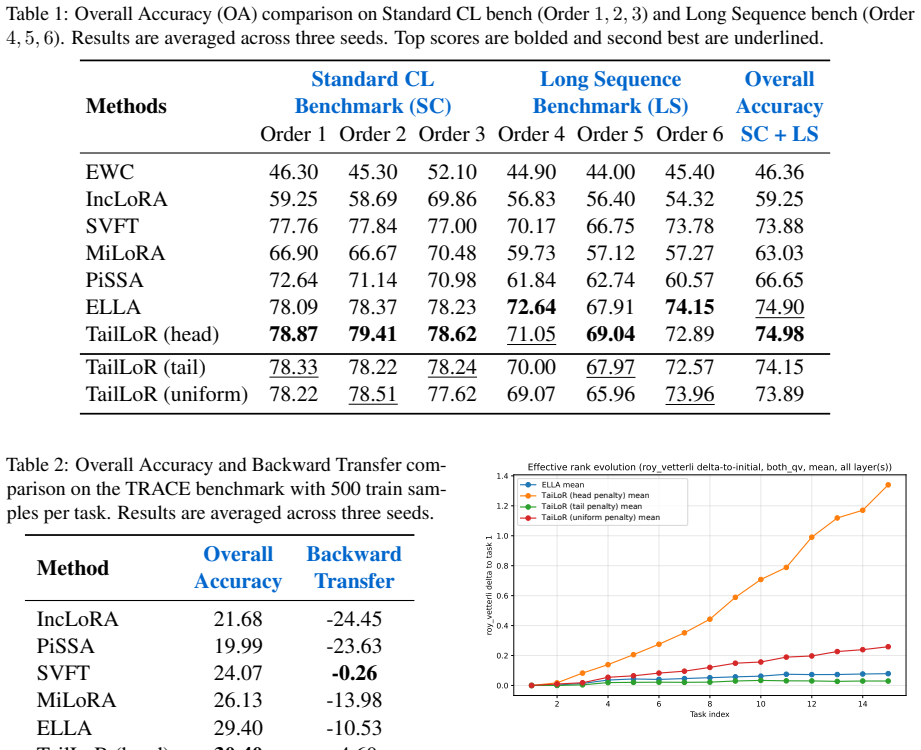
TailLoR utilizes the singular bases U and V of the pre-trained weights as a fixed reference frame to learn a low-rank update applied to the singular value matrix. A soft spectral penalty discourages updates aligned with dominant singular directions, reducing interference while routing fine-grained adaptation into the highly flexible, long-tail spectral coordinates.
What carries the argument
Fixed singular bases U and V used as reference frame for low-rank updates to the singular value matrix, controlled by a soft spectral penalty that protects dominant directions.
If this is right
- Principal components of earlier tasks remain protected, lowering interference on subsequent tasks.
- Fine-grained adaptation occurs mainly in the long-tail singular directions that tolerate change more readily.
- Parameter count stays low because only low-rank factors update the singular values.
- The method supports sequential learning without storing previous task data or full model copies.
Where Pith is reading between the lines
- The same fixed-basis idea might extend to other matrix factorizations used in adaptation techniques.
- Combining the penalty with replay or regularization methods could further stabilize performance across many tasks.
- The approach suggests a way to prioritize spectral coordinates for updates that could apply beyond continual learning to other fine-tuning scenarios.
Load-bearing premise
Fixing the singular vectors and applying a soft penalty only to dominant singular values reduces task interference enough without restricting the model's ability to learn new tasks.
What would settle it
A sequence of tasks where models trained with the spectral penalty show no measurable reduction in forgetting rates compared to the same low-rank method without the penalty would falsify the central claim.
Figures
read the original abstract
Parameter-efficient finetuning methods based on spectral decomposition have enabled progress in Continual Learning. In this paper we introduce TailLoR, which utilizes the singular bases U and V of the pre-trained weights as a fixed reference frame to learn a low-rank update applied to the singular value matrix. A soft spectral penalty discourages updates aligned with dominant singular directions, reducing interference while routing fine-grained adaptation into the highly flexible, long-tail spectral coordinates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TailLoR, a parameter-efficient continual learning method that fixes the singular vectors U and V from pre-trained weights as a reference frame, applies a low-rank update exclusively to the singular-value matrix, and employs a soft spectral penalty to discourage updates along dominant singular directions while routing adaptation into long-tail spectral coordinates.
Significance. If the construction demonstrably reduces task interference without sacrificing new-task capacity, the approach would offer a targeted spectral mechanism for protecting principal components in PEFT-based continual learning, extending existing singular-value methods with an explicit penalty on dominant directions.
major comments (2)
- [Abstract] Abstract: the central claim that the soft spectral penalty reduces interference while preserving capacity rests on an unverified assumption; no derivation, update rule, or quantitative condition is supplied to show how the penalty interacts with the low-rank update on the singular-value matrix.
- [Abstract] No experimental section or results are referenced in the provided description to test whether the long-tail routing actually mitigates forgetting on prior tasks or enables sufficient adaptation on new tasks.
Simulated Author's Rebuttal
Thank you for the review. We address the two major comments on the abstract below. Both point to the need for greater specificity in the abstract, which we will address through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the soft spectral penalty reduces interference while preserving capacity rests on an unverified assumption; no derivation, update rule, or quantitative condition is supplied to show how the penalty interacts with the low-rank update on the singular-value matrix.
Authors: The full manuscript derives the soft spectral penalty, its interaction with the low-rank update on the singular-value matrix, and the associated update rules and quantitative conditions in Section 3. The abstract summarizes the high-level idea but omits these details due to length limits. We will revise the abstract to briefly note the penalty mechanism and direct readers to Section 3 for the derivation and analysis. revision: yes
-
Referee: [Abstract] No experimental section or results are referenced in the provided description to test whether the long-tail routing actually mitigates forgetting on prior tasks or enables sufficient adaptation on new tasks.
Authors: The abstract does not reference experiments or results. The full manuscript contains Section 4, which reports experiments on standard continual learning benchmarks showing that the long-tail routing reduces forgetting on prior tasks while supporting adaptation on new tasks. We will revise the abstract to include a concise statement of these empirical findings. revision: yes
Circularity Check
No significant circularity in method description
full rationale
The paper presents TailLoR as a direct construction: singular bases U and V are taken as fixed from pre-trained weights, a low-rank update is applied only to the singular-value matrix, and a soft spectral penalty is introduced to discourage dominant-direction updates. No equations, derivations, or quantitative predictions appear in the provided abstract or description that could reduce to their own inputs by construction. There are no fitted parameters renamed as predictions, no self-citation load-bearing steps, and no uniqueness theorems or ansatzes smuggled in. The central claim is the method definition itself, which is self-contained and does not rely on any internal reduction or circular justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.07097 , year=
Sculpting subspaces: Constrained full fine-tuning in llms for continual learning , author=. arXiv preprint arXiv:2504.07097 , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Svft: Parameter-efficient fine-tuning with singular vectors , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
M i L o RA : Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning
Wang, Hanqing and Li, Yixia and Wang, Shuo and Chen, Guanhua and Chen, Yun. M i L o RA : Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.1...
-
[4]
Advances in Neural Information Processing Systems , volume=
Pissa: Principal singular values and singular vectors adaptation of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yan. InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning , booktitle =. 2024 , url =. doi:10.1109/CVPR52733.2024.02231 , timestamp =
-
[6]
ELLA : Efficient Lifelong Learning for Adapters in Large Language Models
Das Biswas, Shristi and Zhang, Yue and Pal, Anwesan and Bhargava, Radhika and Roy, Kaushik. ELLA : Efficient Lifelong Learning for Adapters in Large Language Models. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.84
-
[7]
Orthogonal Subspace Learning for Language Model Continual Learning
Wang, Xiao and Chen, Tianze and Ge, Qiming and Xia, Han and Bao, Rong and Zheng, Rui and Zhang, Qi and Gui, Tao and Huang, Xuanjing. Orthogonal Subspace Learning for Language Model Continual Learning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.715
-
[8]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[9]
Parameter-Efficient Transfer Learning for
Neil Houlsby and Andrei Giurgiu and Stanislaw Jastrzebski and Bruna Morrone and Quentin de Laroussilhe and Andrea Gesmundo and Mona Attariyan and Sylvain Gelly , editor =. Parameter-Efficient Transfer Learning for. Proceedings of the 36th International Conference on Machine Learning,. 2019 , url =
2019
-
[10]
A Survey of Large Language Models
Wayne Xin Zhao and Kun Zhou and Junyi Li and Tianyi Tang and Xiaolei Wang and Yupeng Hou and Yingqian Min and Beichen Zhang and Junjie Zhang and Zican Dong and Yifan Du and Chen Yang and Yushuo Chen and Zhipeng Chen and Jinhao Jiang and Ruiyang Ren and Yifan Li and Xinyu Tang and Zikang Liu and Peiyu Liu and Jian. A Survey of Large Language Models , journ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223 2023
-
[11]
Large Language Models: A Survey
Shervin Minaee and Tom. Large Language Models:. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.06196 , eprinttype =. 2402.06196 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.06196 2024
-
[12]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models. CoRR , volume =. 2021 , url =. 2106.09685 , timestamp =
Pith/arXiv arXiv 2021
-
[13]
6th International Conference on Learning Representations (
Chunyuan Li and Heerad Farkhoor and Rosanne Liu and Jason Yosinski , title =. 6th International Conference on Learning Representations (. 2018 , url =
2018
-
[14]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , booktitle =
Armen Aghajanyan and Sonal Gupta and Luke Zettlemoyer , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing,. 2021 , url =. doi:10.18653/V1/2021.ACL-LONG.568 , timestamp =
-
[15]
Psychology of Learning and Motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of Learning and Motivation , volume=. 1989 , publisher=
1989
-
[16]
Trends in Cognitive Sciences , volume=
Catastrophic forgetting in connectionist networks , author=. Trends in Cognitive Sciences , volume=. 1999 , publisher=
1999
-
[17]
Rabinowitz and Joel Veness and Guillaume Desjardins and Andrei A
James Kirkpatrick and Razvan Pascanu and Neil C. Rabinowitz and Joel Veness and Guillaume Desjardins and Andrei A. Rusu and Kieran Milan and John Quan and Tiago Ramalho and Agnieszka Grabska. Overcoming catastrophic forgetting in neural networks , journal =. 2016 , url =. 1612.00796 , timestamp =
arXiv 2016
-
[18]
Gradient Episodic Memory for Continual Learning , booktitle =
David Lopez. Gradient Episodic Memory for Continual Learning , booktitle =. 2017 , url =
2017
-
[19]
Cyprien de Masson d'Autume and Sebastian Ruder and Lingpeng Kong and Dani Yogatama , title =. CoRR , volume =. 2019 , url =. 1906.01076 , timestamp =
arXiv 2019
-
[20]
7th International Conference on Learning Representations (
Matthew Riemer and Ignacio Cases and Robert Ajemian and Miao Liu and Irina Rish and Yuhai Tu and Gerald Tesauro , title =. 7th International Conference on Learning Representations (. 2019 , url =
2019
-
[21]
6th International Conference on Learning Representations (
Jaehong Yoon and Eunho Yang and Jeongtae Lee and Sung Ju Hwang , title =. 6th International Conference on Learning Representations (. 2018 , url =
2018
-
[22]
Proceedings of the 36th International Conference on Machine Learning (
Xilai Li and Yingbo Zhou and Tianfu Wu and Richard Socher and Caiming Xiong , title =. Proceedings of the 36th International Conference on Machine Learning (. 2019 , url =
2019
-
[23]
Andrei A. Rusu and Neil C. Rabinowitz and Guillaume Desjardins and Hubert Soyer and James Kirkpatrick and Koray Kavukcuoglu and Razvan Pascanu and Raia Hadsell , title =. CoRR , volume =. 2016 , url =. 1606.04671 , timestamp =
Pith/arXiv arXiv 2016
-
[24]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[25]
International Conference on Learning Representations , volume=
The truth is in there: Improving reasoning in language models with layer-selective rank reduction , author=. International Conference on Learning Representations , volume=
-
[26]
arXiv preprint arXiv:2602.21919 , year=
Learning in the Null Space: Small Singular Values for Continual Learning , author=. arXiv preprint arXiv:2602.21919 , year=
-
[27]
arXiv preprint arXiv:2310.06762 , year=
Trace: A comprehensive benchmark for continual learning in large language models , author=. arXiv preprint arXiv:2310.06762 , year=
-
[28]
Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015 , pages =
Xiang Zhang and Junbo Jake Zhao and Yann LeCun , title =. Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015 , pages =. 2015 , url =
2015
-
[29]
The Eleventh International Conference on Learning Representations (
Anastasia Razdaibiedina and Yuning Mao and Rui Hou and Madian Khabsa and Mike Lewis and Amjad Almahairi , title =. The Eleventh International Conference on Learning Representations (. 2023 , url =
2023
-
[30]
Zhicheng Wang and Yufang Liu and Tao Ji and Xiaoling Wang and Yuanbin Wu and Congcong Jiang and Ye Chao and Zhencong Han and Ling Wang and Xu Shao and Wenqiu Zeng , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.612 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.