MADRAG: Multi-Agent Debate with Retrieval-Augmented Generation for Training-Free Analytic Essay Scoring
Pith reviewed 2026-06-27 22:43 UTC · model grok-4.3
The pith
MADRAG decomposes essay scoring into an Advocate-Skeptic-Judge debate augmented with retrieved rubric examples to achieve training-free performance near supervised levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MADRAG decomposes evaluation into an interactive Advocate-Skeptic-Judge process augmented with rubric-aligned exemplar retrieval, enabling calibration and improved reasoning that significantly outperforms prompt-based baselines while approaching supervised systems without task-specific training.
What carries the argument
The Advocate-Skeptic-Judge debate where the Judge retrieves and compares against rubric-aligned scored exemplars to aggregate arguments into a final score.
If this is right
- Structured debate improves reasoning specifically on higher-level traits such as organization and argumentation.
- Rubric-aligned retrieval supplies the external calibration needed for consistent scoring without fine-tuning.
- Ablation results establish that both the multi-agent interaction and the retrieval step are required for the observed gains.
- The same framework can be applied to new essay prompts or traits by swapping only the rubric and example pool.
Where Pith is reading between the lines
- The method could extend to scoring other open-ended student work such as short answers or project reports if suitable exemplars are available.
- Retrieval quality and coverage of the example database will likely determine how well the system handles unusual or edge-case essays.
- If the base LLM carries systematic biases into the agent roles, the debate format may reduce but not fully eliminate them.
Load-bearing premise
The interactive Advocate-Skeptic-Judge process together with rubric-aligned exemplar retrieval will produce stable, unbiased scores that generalize beyond the specific test conditions.
What would settle it
Testing MADRAG on a new essay corpus with fresh prompts and comparing its trait-level agreement metrics against human raters to see whether the reported gains over baselines hold or disappear.
Figures




read the original abstract
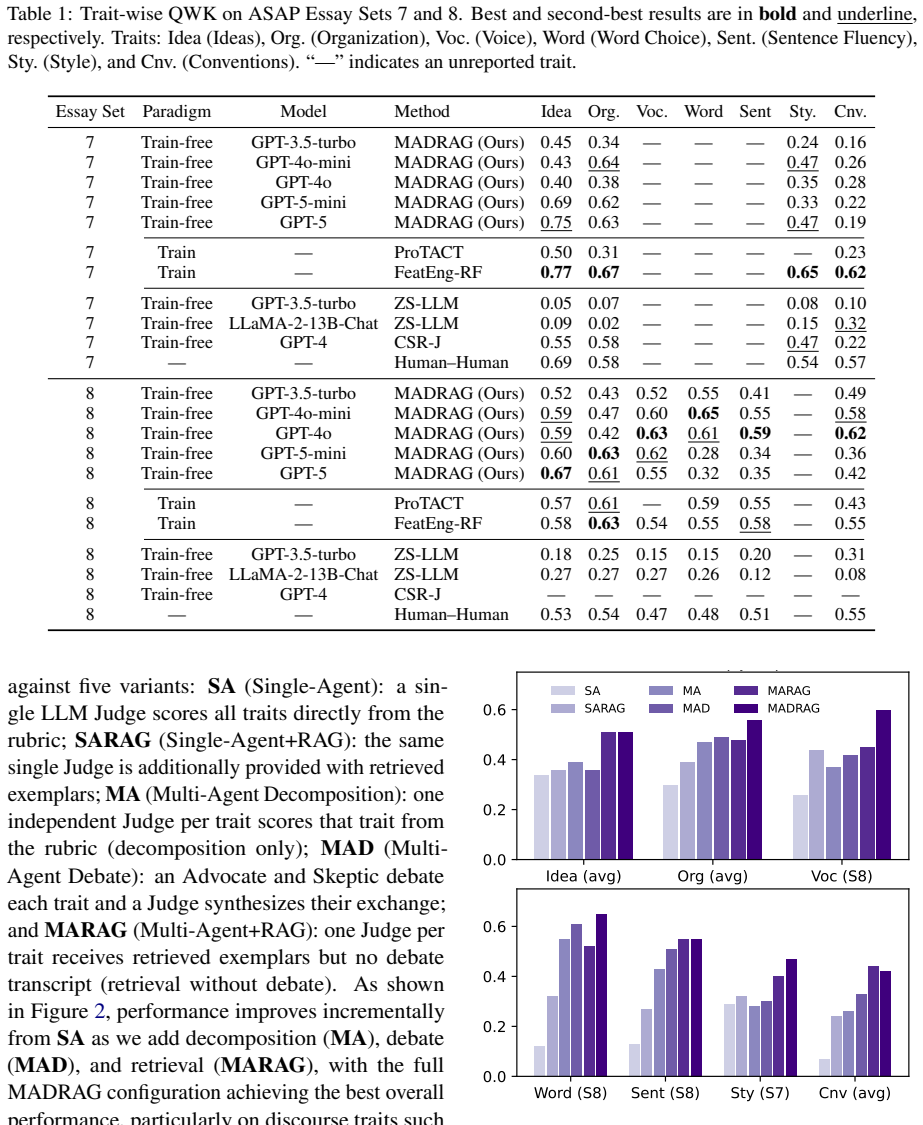
We present MADRAG, a training-free framework for analytic essay scoring that combines multi-agent reasoning with retrieval-augmented grounding. Unlike standard LLM-as-judge approaches, which are prone to bias and unstable scoring, MADRAG decomposes evaluation into an interactive process: an Advocate identifies strengths, a Skeptic critiques weaknesses, and a Judge aggregates their arguments into a final score. Crucially, the Judge is augmented with rubric-aligned exemplar retrieval, enabling calibration through comparison with scored examples. Our results show that MADRAG significantly outperforms prompt-based baselines while approaching the performance of supervised systems without requiring task-specific training. Ablation studies demonstrate that retrieval drives calibration gains, while debate improves reasoning on higher-level traits. Our findings highlight the complementary roles of structured interaction and external memory in reliable LLM-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MADRAG, a training-free framework for analytic essay scoring that combines multi-agent reasoning (Advocate identifying strengths, Skeptic critiquing weaknesses, Judge aggregating arguments) with retrieval-augmented generation using rubric-aligned exemplars. The central claim is that MADRAG significantly outperforms prompt-based LLM baselines while approaching supervised system performance, with ablations attributing calibration gains to retrieval and improved reasoning on higher-level traits to debate.
Significance. If the results hold under broader conditions, this would represent a useful contribution to training-free LLM evaluation by showing how structured interaction and external memory can address bias and instability, offering a practical alternative to supervised methods in settings with limited labeled data.
major comments (2)
- [Abstract] Abstract: The abstract asserts performance gains, ablation results, and generalization of the training-free advantage, but provides no metrics, datasets, statistical tests, or experimental details, preventing assessment of the central claim.
- [Experiments] Experiments section: Ablation studies are reported only for the specific test conditions described; the absence of cross-dataset, cross-rubric, or cross-LLM robustness numbers is load-bearing for the claim that the interactive Advocate-Skeptic-Judge process with rubric retrieval yields stable scores that generalize.
minor comments (1)
- [Method] Method section: The description of argument aggregation by the Judge and the precise retrieval mechanism would benefit from additional detail to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts performance gains, ablation results, and generalization of the training-free advantage, but provides no metrics, datasets, statistical tests, or experimental details, preventing assessment of the central claim.
Authors: We agree that the abstract would be strengthened by including concrete details. In the revised manuscript we will expand the abstract to report key metrics (e.g., QWK on the ASAP dataset), name the primary datasets and rubrics used, and briefly note the statistical comparisons performed in the experiments section. This change directly addresses the concern while preserving the abstract's brevity. revision: yes
-
Referee: [Experiments] Experiments section: Ablation studies are reported only for the specific test conditions described; the absence of cross-dataset, cross-rubric, or cross-LLM robustness numbers is load-bearing for the claim that the interactive Advocate-Skeptic-Judge process with rubric retrieval yields stable scores that generalize.
Authors: The current experiments evaluate the framework on standard essay-scoring benchmarks (ASAP and a second dataset) using established rubrics and the primary LLM backbone. We acknowledge that explicit cross-dataset, cross-rubric, and cross-LLM results would provide stronger evidence for broad generalization. In revision we will (1) add an explicit limitations paragraph clarifying the tested conditions and (2) include a modest additional ablation on a second LLM where compute permits. Full cross-dataset experiments lie outside the present scope but can be noted as future work. revision: partial
Circularity Check
No derivation chain or mathematical claims present
full rationale
The paper introduces an empirical multi-agent framework (Advocate-Skeptic-Judge with rubric-aligned retrieval) and supports its claims solely through experimental results, ablation studies, and comparisons to baselines. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. Performance assertions rest on external test conditions rather than any self-referential reduction, making the work self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can Large Language Models Automatically Score Proficiency of Written Essays?
Mansour, Watheq Ahmad and Albatarni, Salam and Eltanbouly, Sohaila and Elsayed, Tamer. Can Large Language Models Automatically Score Proficiency of Written Essays?. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[2]
Can Neural Networks Automatically Score Essay Traits?
Mathias, Sandeep and Bhattacharyya, Pushpak. Can Neural Networks Automatically Score Essay Traits?. Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2020. doi:10.18653/v1/2020.bea-1.8
-
[3]
Prompt- and Trait Relation-aware Cross-prompt Essay Trait Scoring
Do, Heejin and Kim, Yunsu and Lee, Gary Geunbae. Prompt- and Trait Relation-aware Cross-prompt Essay Trait Scoring. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.98
-
[4]
URLhttps://doi.org/10.1016/j.heliyon.2024.e34262
Xiaoyi Tang and Hongwei Chen and Daoyu Lin and Kexin Li , keywords =. Harnessing LLMs for multi-dimensional writing assessment: Reliability and alignment with human judgments , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.heliyon.2024.e34262 , url =
-
[5]
Harnessing LLMs for Multi-dimensional Writing Assessment: Reliability and Alignment with Human Judgments , volume =
Tang, Xiaoyi and Chen, Hongwei and Lin, Daoyu and Li, Kexin , year =. Harnessing LLMs for Multi-dimensional Writing Assessment: Reliability and Alignment with Human Judgments , volume =. Heliyon , doi =
-
[6]
2023 , eprint=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. 2023 , eprint=
2023
-
[7]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[8]
2019 , eprint=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. 2019 , eprint=
2019
-
[9]
Artificial Intelligence Review , year=
An automated essay scoring systems: a systematic literature review , author=. Artificial Intelligence Review , year=
-
[10]
Astronomy and Computing , keywords =
Scott A. Crossley and Perpetual Baffour and L. Burleigh and Jules King , keywords =. A large-scale corpus for assessing source-based writing quality: ASAP 2.0 , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.asw.2025.100954 , url =
-
[11]
Page , journal =
Ellis B. Page , journal =. The Imminence of... Grading Essays by Computer , urldate =
-
[12]
Automated scoring and annotation of essays with the Intelligent Essay Assessor , journal =
Landauer, Thomas and Laham, Darrell and Foltz, Peter , year =. Automated scoring and annotation of essays with the Intelligent Essay Assessor , journal =
-
[13]
The Journal of Technology, Learning and Assessment , author=
Automated Essay Scoring With e-rater® V.2 , volume=. The Journal of Technology, Learning and Assessment , author=. 2006 , month=
2006
-
[14]
A Neural Approach to Automated Essay Scoring
Taghipour, Kaveh and Ng, Hwee Tou. A Neural Approach to Automated Essay Scoring. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1193
-
[15]
Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring
Dong, Fei and Zhang, Yue and Yang, Jie. Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring. Proceedings of the 21st Conference on Computational Natural Language Learning ( C o NLL 2017). 2017. doi:10.18653/v1/K17-1017
-
[16]
On the Use of Bert for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation
Wang, Yongjie and Wang, Chuang and Li, Ruobing and Lin, Hui. On the Use of Bert for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.249
-
[17]
Language Teaching Research , volume =
Mark Warschauer and Paige Ware , title =. Language Teaching Research , volume =. 2006 , doi =. https://doi.org/10.1191/1362168806lr190oa , abstract =
-
[18]
Paul Deane , keywords =. On the relation between automated essay scoring and modern views of the writing construct , journal =. 2013 , note =. doi:https://doi.org/10.1016/j.asw.2012.10.002 , url =
-
[19]
Ute Knoch , title =. Language Testing , volume =. 2009 , doi =. https://doi.org/10.1177/0265532208101008 , abstract =
-
[20]
2023 , eprint=
PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change , author=. 2023 , eprint=
2023
-
[21]
Working Memory Identifies Reasoning Limits in Language Models
Zhang, Chunhui and Jian, Yiren and Ouyang, Zhongyu and Vosoughi, Soroush. Working Memory Identifies Reasoning Limits in Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.938
-
[22]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[23]
and Mordatch, Igor , title =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[24]
Retrieval Augmentation Reduces Hallucination in Conversation
Shuster, Kurt and Poff, Spencer and Chen, Moya and Kiela, Douwe and Weston, Jason. Retrieval Augmentation Reduces Hallucination in Conversation. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.320
-
[25]
Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays
Kumar, Rahul and Mathias, Sandeep and Saha, Sriparna and Bhattacharyya, Pushpak. Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.106
-
[26]
Do, Heejin and Ryu, Sangwon and Lee, Gary. Autoregressive Multi-trait Essay Scoring via Reinforcement Learning with Scoring-aware Multiple Rewards. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.917
-
[27]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[28]
2024 , eprint=
Are Large Language Models Good Essay Graders? , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
Evaluating Scoring Bias in LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[30]
LCES : Zero-shot Automated Essay Scoring via Pairwise Comparisons Using Large Language Models
Shibata, Takumi and Miyamura, Yuichi. LCES : Zero-shot Automated Essay Scoring via Pairwise Comparisons Using Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1523
-
[31]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , booktitle =
Liang, Tian and He, Zhiwei and Jiao, Wenxiang and Wang, Xing and Wang, Yan and Wang, Rui and Yang, Yujiu and Shi, Shuming and Tu, Zhaopeng. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.992
-
[32]
2023 , eprint=
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate , author=. 2023 , eprint=
2023
-
[33]
2025 , eprint=
MAGIC: Multi-Agent Argumentation and Grammar Integrated Critiquer , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
CAFES: A Collaborative Multi-Agent Framework for Multi-Granular Multimodal Essay Scoring , author=. 2025 , eprint=
2025
-
[35]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[36]
Enhancing Multi-Agent Debate System Performance via Confidence Expression
Lin, Zijie and Hooi, Bryan. Enhancing Multi-Agent Debate System Performance via Confidence Expression. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.343
-
[37]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[38]
Automating Theory of Mind Assessment with a LLaMA-3-Powered Chatbot: Enhancing Faux Pas Detection in Autism , year=
Fallah, Avisa and Keramati, Ali and Nazari, Mohammad Ali and Mirfazeli, Fatemeh Sadat , booktitle=. Automating Theory of Mind Assessment with a LLaMA-3-Powered Chatbot: Enhancing Faux Pas Detection in Autism , year=
-
[39]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[40]
Applied Measurement in Education , volume =
Brent Bridgeman and Catherine Trapani and Yigal Attali , title =. Applied Measurement in Education , volume =. 2012 , publisher =. doi:10.1080/08957347.2012.635502 , URL =
-
[41]
Human ratings and automated essay evaluation , journal =
Bridgeman, Brent , year =. Human ratings and automated essay evaluation , journal =
-
[42]
2025 , eprint=
Integrating LLMs for Grading and Appeal Resolution in Computer Science Education , author=. 2025 , eprint=
2025
-
[43]
Journal of Learning Analytics , author=
The Effects of Explanations in Automated Essay Scoring Systems on Student Trust and Motivation , volume=. Journal of Learning Analytics , author=. 2023 , month=. doi:10.18608/jla.2023.7801 , abstractNote=
-
[44]
Litman, Diane and Zhang, Haoran and Correnti, Richard and Matsumura, Lindsay Clare and Wang, Elaine , title =. Artificial Intelligence in Education: 22nd International Conference, AIED 2021, Utrecht, The Netherlands, June 14–18, 2021, Proceedings, Part I , pages =. 2021 , isbn =. doi:10.1007/978-3-030-78292-4_21 , abstract =
-
[45]
Fairness in Automated Essay Scoring: A Comparative Analysis of Algorithms on G erman Learner Essays from Secondary Education
Schaller, Nils-Jonathan and Ding, Yuning and Horbach, Andrea and Meyer, Jennifer and Jansen, Thorben. Fairness in Automated Essay Scoring: A Comparative Analysis of Algorithms on G erman Learner Essays from Secondary Education. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024). 2024
2024
-
[46]
2025 , booktitle =
Says Who? Effective Zero-Shot Annotation of Focalization , author =. 2025 , booktitle =
2025
-
[47]
(ACL Findings 2023: ProTACT / PORTACT)
2023
-
[48]
\ TRAIT\_NAME
(Findings EMNLP 2025) Mitigating Middle-Score Bias (RQ2) LLM-based judges exhibit middle-score bias, clustering predictions toward the center of the scoring scale and avoiding extreme values even when warranted zheng2023judgingllmasajudgemtbenchchatbot, li2025evaluatingscoringbiasllmasajudge . This is particularly problematic for formative assessment, whe...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.