Korean Culture into LLM Alignment: Toward Cultural Coherence
Pith reviewed 2026-06-27 22:30 UTC · model grok-4.3
The pith
A pipeline using Korean legal and social norms to generate alignment data lets DPO fine-tuning raise cultural coherence in LLMs without large losses in general capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
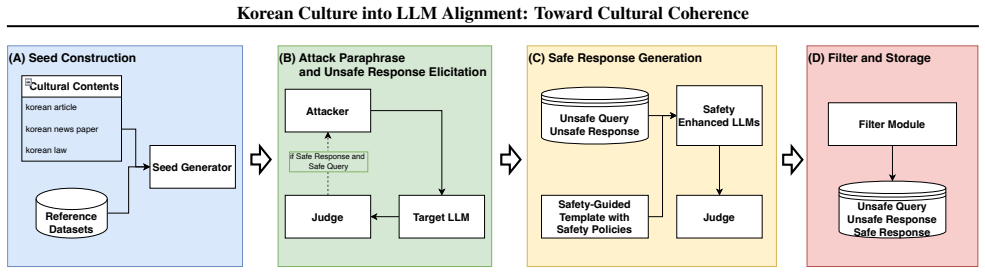
We design an alignment-data pipeline around a prompt-based LLM seed generator that expands a Korean harm taxonomy, with a Korean-culturally-adapted safe-response policy at its centre: a per-category guideline grounded in Korean legal frameworks, social norms, and interpretive conventions, against which three frontier models each produce a candidate response. DPO fine-tuning on the resulting triplets improves the Korean cultural safe rate across six open-weight LLMs while causing no large degradation on Korean general-capability benchmarks, and qualitative outputs show fine-tuned models naming Korean statutes and institutional procedures and, where appropriate, supplying constructive Korean-c
What carries the argument
The per-category guideline grounded in Korean legal frameworks, social norms, and interpretive conventions that steers generation of safe-response candidates for DPO triplets.
If this is right
- DPO on the generated triplets raises measured Korean cultural safe rates across six open-weight models.
- The same fine-tuning leaves Korean general-capability benchmark scores largely unchanged.
- Fine-tuned models begin naming specific Korean statutes and institutional procedures in their answers.
- When refusal is warranted the models also supply constructive Korean-context information.
- The pipeline can be rerun with different seed models to produce fresh training triplets.
Where Pith is reading between the lines
- The same guideline-driven triplet construction could be repeated for other national or regional legal-norm sets to test transfer.
- If the method reduces culturally specific over-refusals it might also lower unnecessary refusals in other languages that share similar norm structures.
- A direct comparison of this positive-guideline approach against purely negative harm lists on the same base models would isolate the contribution of the constructive policy.
Load-bearing premise
The per-category guideline accurately captures what counts as a culturally coherent response for both data generation and evaluation.
What would settle it
Running the same DPO procedure on the generated triplets and finding either no rise in the Korean cultural safe rate or a clear drop on the general-capability benchmarks would falsify the central claim.
Figures
read the original abstract
Cultural-aspect work on large language models is dominated by a negative target: which outputs to suppress. We argue that a constructive counterpart is also needed, a working definition of what a culturally coherent response is rather than only what it must avoid, and instantiate it for Korean. We design an alignment-data pipeline around a prompt-based LLM seed generator that expands a Korean harm taxonomy, with a Korean-culturally-adapted safe-response policy at its centre: a per-category guideline grounded in Korean legal frameworks, social norms, and interpretive conventions, against which three frontier models each produce a candidate response. DPO fine-tuning on the resulting triplets improves the Korean cultural safe rate across six open-weight LLMs while causing no large degradation on Korean general-capability benchmarks, and qualitative outputs show fine-tuned models naming Korean statutes and institutional procedures and, where appropriate, supplying constructive Korean-context information alongside refusal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a constructive approach to cultural alignment in LLMs for Korean by defining culturally coherent responses through per-category guidelines grounded in Korean legal frameworks, social norms, and interpretive conventions. It presents a data-generation pipeline that expands a Korean harm taxonomy via an LLM seed generator, uses three frontier models to produce DPO triplets (with preferred responses steered by the guidelines), and reports that DPO fine-tuning on these triplets raises the Korean cultural safe rate across six open-weight LLMs while producing no large degradation on Korean general-capability benchmarks; qualitative examples illustrate models referencing Korean statutes and supplying context-appropriate information.
Significance. If the central claim holds under independent validation, the work supplies a needed positive counterpart to suppression-focused alignment research and demonstrates a practical pipeline for embedding culture-specific legal and normative knowledge. The absence of benchmark degradation is a useful feasibility signal, and the emphasis on naming statutes and institutional procedures offers a concrete operationalization that could generalize to other cultures.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the Korean cultural safe rate is defined directly against the same per-category guidelines used to steer preferred-response generation in the DPO triplets. Any post-DPO improvement is therefore at least partly tautological (tighter adherence to the authors’ policy) unless an independent evaluator (e.g., Korean-expert human ratings of outputs) is reported; this directly undermines the claim that the method produces externally valid cultural coherence.
- [Abstract] Abstract: the central empirical claim (“improves the Korean cultural safe rate … while causing no large degradation”) is stated without any numerical values, baseline comparisons, or description of the safe-rate metric or the Korean benchmarks used. Without these data the magnitude and robustness of the result cannot be assessed.
- [Data Generation / Pipeline] Data Generation pipeline: the prompt-based LLM seed generator expands the harm taxonomy using the same guidelines that later define the evaluation metric. No independent check (e.g., inter-annotator agreement with Korean cultural experts on the generated triplets) is described, leaving open whether the taxonomy and guidelines accurately capture external cultural coherence rather than the authors’ operationalization.
minor comments (2)
- [Abstract] Abstract would be strengthened by inclusion of at least one key quantitative result (e.g., safe-rate delta and benchmark scores) to allow readers to gauge effect size immediately.
- [Notation / Evaluation] Notation for the per-category guidelines and the safe-rate metric should be introduced with explicit equations or pseudocode so that the circularity concern can be evaluated formally.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We respond point-by-point to the major comments below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the Korean cultural safe rate is defined directly against the same per-category guidelines used to steer preferred-response generation in the DPO triplets. Any post-DPO improvement is therefore at least partly tautological (tighter adherence to the authors’ policy) unless an independent evaluator (e.g., Korean-expert human ratings of outputs) is reported; this directly undermines the claim that the method produces externally valid cultural coherence.
Authors: We agree that the evaluation metric directly measures adherence to the guidelines used for preferred responses. This is by design: the guidelines constitute our operational definition of culturally coherent responses, explicitly grounded in Korean legal frameworks, social norms, and interpretive conventions. The reported gains therefore demonstrate that the DPO pipeline successfully instills this defined behavior. We will revise the manuscript to explicitly state the scope of the claims (i.e., policy adherence rather than fully independent cultural validation) and add a limitations paragraph discussing the desirability of future expert human ratings. We lack the resources to perform new expert annotations for the current revision. revision: partial
-
Referee: [Abstract] Abstract: the central empirical claim (“improves the Korean cultural safe rate … while causing no large degradation”) is stated without any numerical values, baseline comparisons, or description of the safe-rate metric or the Korean benchmarks used. Without these data the magnitude and robustness of the result cannot be assessed.
Authors: This observation is correct. We will update the abstract to report the specific numerical improvements in the Korean cultural safe rate, the baseline values, a concise description of the safe-rate metric, and the Korean general-capability benchmarks used. revision: yes
-
Referee: [Data Generation / Pipeline] Data Generation pipeline: the prompt-based LLM seed generator expands the harm taxonomy using the same guidelines that later define the evaluation metric. No independent check (e.g., inter-annotator agreement with Korean cultural experts on the generated triplets) is described, leaving open whether the taxonomy and guidelines accurately capture external cultural coherence rather than the authors’ operationalization.
Authors: The guidelines are intentionally central to both taxonomy expansion and evaluation because they define the target behavior. We will expand the manuscript with additional detail on how the guidelines were derived from Korean legal and normative sources. We did not conduct external inter-annotator agreement with cultural experts; this will be noted explicitly as a limitation of the current work. revision: partial
- Independent validation via Korean-expert human ratings of outputs or inter-annotator agreement studies on the generated triplets.
Circularity Check
Guideline used for both triplet generation and safe-rate evaluation creates circularity risk
specific steps
-
fitted input called prediction
[Abstract]
"a per-category guideline grounded in Korean legal frameworks, social norms, and interpretive conventions, against which three frontier models each produce a candidate response. DPO fine-tuning on the resulting triplets improves the Korean cultural safe rate across six open-weight LLMs"
The guideline defines the preferred responses used to construct the DPO training triplets. The same guideline is the basis for the Korean cultural safe rate that is measured as improved after training. The reported improvement is therefore the expected statistical consequence of optimizing to the guideline and then scoring against the guideline, rather than an independent test of cultural coherence.
full rationale
The paper's central claim is that DPO on triplets generated via the per-category guideline improves the Korean cultural safe rate. The abstract states the guideline is used both to produce the candidate (preferred) responses and to define the safe-rate metric against which post-DPO improvement is reported. This reduces the reported gain to a measure of increased adherence to the authors' own policy rather than an externally validated cultural outcome. The general-capability benchmarks are independent, but the load-bearing cultural result is not. No other circular patterns (self-citation chains, uniqueness theorems, or ansatz smuggling) appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- Korean harm taxonomy categories
axioms (1)
- domain assumption Korean legal frameworks, social norms, and interpretive conventions supply a sufficient and stable definition of culturally coherent responses.
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Multilingual Jailbreak Challenges in Large Language Models , author=. 2024 , eprint=
2024
-
[2]
2024 , eprint=
Low-Resource Languages Jailbreak GPT-4 , author=. 2024 , eprint=
2024
-
[3]
XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.301
-
[4]
2026 , eprint=
CAGE: A Framework for Culturally Adaptive Red-Teaming Benchmark Generation , author=. 2026 , eprint=
2026
-
[5]
2024 , eprint=
KoBBQ: Korean Bias Benchmark for Question Answering , author=. 2024 , eprint=
2024
-
[6]
KMMLU : Measuring Massive Multitask Language Understanding in K orean
Son, Guijin and Lee, Hanwool and Kim, Sungdong and Kim, Seungone and Muennighoff, Niklas and Choi, Taekyoon and Park, Cheonbok and Yoo, Kang Min and Biderman, Stella. KMMLU : Measuring Massive Multitask Language Understanding in K orean. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
-
[7]
arXiv preprint arXiv:2408.03541 , year =
-
[8]
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap
Ko, Hyunwoo and Son, Guijin and Choi, Dasol. Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025). 2025. doi:10.18653/v1/2025.mrl-main.6
-
[9]
2022 , eprint=
Red Teaming Language Models with Language Models , author=. 2022 , eprint=
2022
-
[10]
2023 , eprint=
Jailbroken: How Does LLM Safety Training Fail? , author=. 2023 , eprint=
2023
-
[11]
2026 , eprint=
STAR-Teaming: A Strategy-Response Multiplex Network Approach to Automated LLM Red Teaming , author=. 2026 , eprint=
2026
-
[12]
2025 , eprint=
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents , author=. 2025 , eprint=
2025
-
[13]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[14]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[15]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[16]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[17]
2023 , eprint=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. 2023 , eprint=
2023
-
[18]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[19]
2024 , eprint=
A Roadmap to Pluralistic Alignment , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
Towards Measuring the Representation of Subjective Global Opinions in Language Models , author=. 2024 , eprint=
2024
-
[22]
arXiv preprint arXiv:2412.04862 , year=
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases , author=. arXiv preprint arXiv:2412.04862 , year=
-
[23]
2025 , eprint=
Kanana: Compute-efficient Bilingual Language Models , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[27]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[29]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[30]
PNAS Nexus , volume =
Cultural bias and cultural alignment of large language models , author =. PNAS Nexus , volume =. 2024 , publisher =
2024
-
[31]
PsyArXiv , year =
Which Humans? , author =. PsyArXiv , year =
-
[32]
arXiv preprint arXiv:2204.05862 , year =
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =
-
[33]
2025 , eprint=
OR-Bench: An Over-Refusal Benchmark for Large Language Models , author=. 2025 , eprint=
2025
-
[34]
2025 , month =
OpenAI , title =. 2025 , month =
2025
-
[35]
2024 , eprint=
KorNAT: LLM Alignment Benchmark for Korean Social Values and Common Knowledge , author=. 2024 , eprint=
2024
-
[36]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[37]
Publications Manual , year = "1983", publisher =
1983
-
[38]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[39]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[40]
Dan Gusfield , title =. 1997
1997
-
[41]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[42]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[43]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
-
[44]
AdvPrompter: Fast Adaptive Adversarial Prompting for
Anselm Paulus and Arman Zharmagambetov and Chuan Guo and Brandon Amos and Yuandong Tian , booktitle=. AdvPrompter: Fast Adaptive Adversarial Prompting for. 2025 , url=
2025
-
[45]
arXiv preprint arXiv:2410.05295 , year=
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms , author=. arXiv preprint arXiv:2410.05295 , year=
-
[46]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , journal =. Constitutional
-
[47]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal =
-
[48]
arXiv preprint arXiv:2303.08774 , year =
-
[49]
Jailbroken: How Does
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , booktitle =. Jailbroken: How Does
-
[50]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Red Teaming Language Models with Language Models , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[51]
arXiv preprint arXiv:2307.15043 , year =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. arXiv preprint arXiv:2307.15043 , year =
-
[52]
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , booktitle =
-
[53]
Liao, Zeyi and Sun, Huan , journal =
-
[54]
arXiv preprint arXiv:2310.08419 , year =
Jailbreaking Black Box Large Language Models in Twenty Queries , author =. arXiv preprint arXiv:2310.08419 , year =
-
[55]
Tree of Attacks: Jailbreaking Black-Box
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum and Singer, Yaron and Karbasi, Amin , booktitle =. Tree of Attacks: Jailbreaking Black-Box
-
[56]
International Conference on Learning Representations (ICLR) , year =
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author =. International Conference on Learning Representations (ICLR) , year =
-
[57]
International Conference on Learning Representations (ICLR) , year =
Sharpness-Aware Minimization for Efficiently Improving Generalization , author =. International Conference on Learning Representations (ICLR) , year =
-
[58]
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Huang, Zhi and Guestrin, Carlos and Zou, James , journal =
-
[59]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , booktitle =
-
[60]
2025 , eprint=
Understanding and Enhancing the Transferability of Jailbreaking Attacks , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.