CRAFT: A Unified Counterfactual Reasoning Framework for Tabular Question Answering and Fact Verification
Pith reviewed 2026-06-27 22:18 UTC · model grok-4.3
The pith
CRAFT improves tabular QA and fact verification by constructing counterfactual statement variants and weighting evidence from both original and alternative reasoning paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
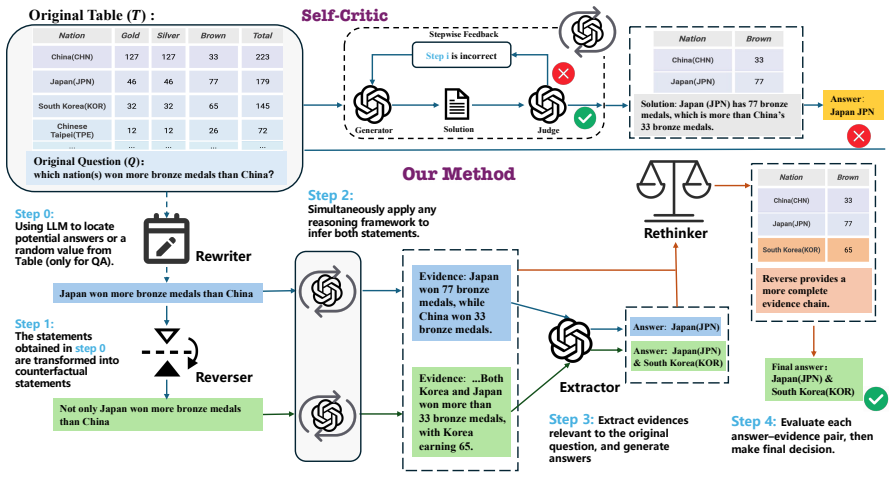
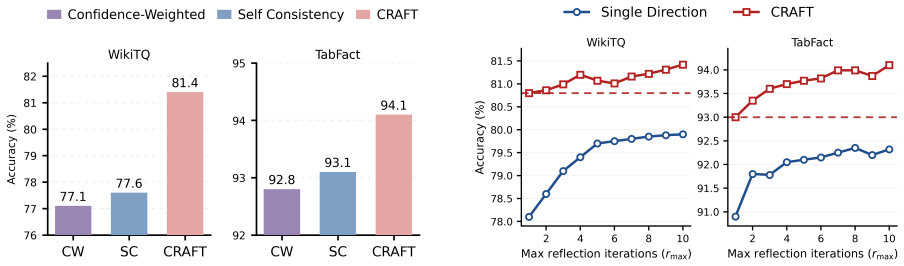
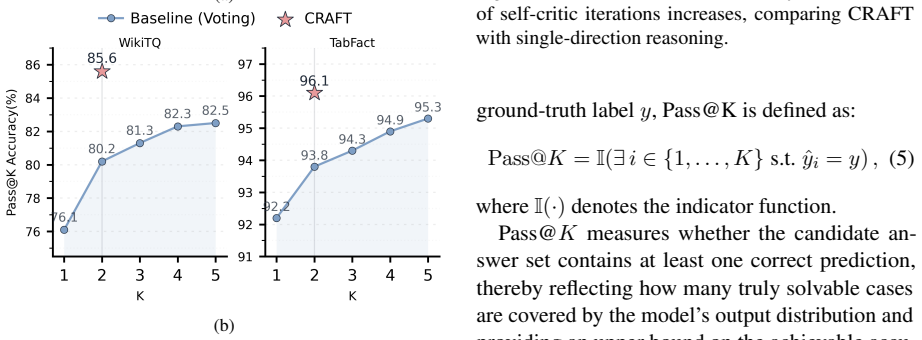
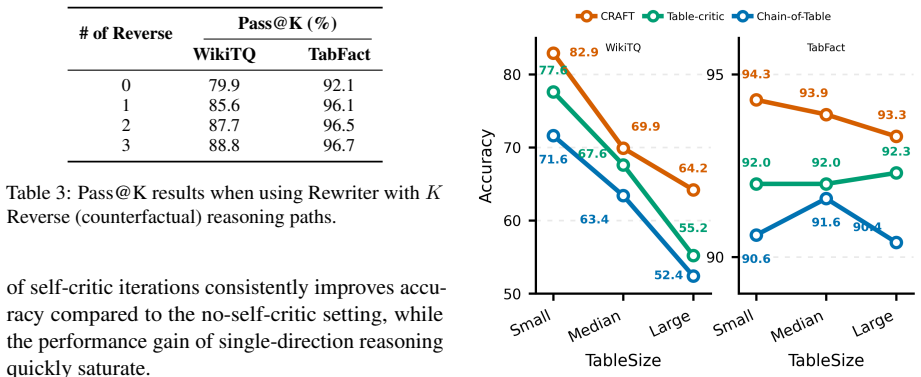
CRAFT reformulates tabular question answering and fact verification as a general bidirectional verification process. Declarative statements and their counterfactual variants are constructed explicitly; evidence is extracted from reasoning along both the original and counterfactual paths; and the two streams are integrated by a weighted mechanism to produce the final answer. This process is shown to outperform single-direction baselines on WikiTQ and TabFact while narrowing gaps between different backbone LLMs.
What carries the argument
Bidirectional verification that generates counterfactual variants of declarative statements and integrates weighted evidence from both original and alternative reasoning paths.
If this is right
- Accuracy rises on WikiTQ and TabFact, especially for complex multi-step questions.
- Performance differences shrink across different LLM backbones.
- Single-direction inference limits are reduced by explicit alternative-hypothesis testing.
- The same framework applies to both question answering and fact verification without task-specific redesign.
Where Pith is reading between the lines
- The weighting step could be replaced by learned fusion to test whether hand-designed weights are necessary.
- Counterfactual construction might transfer to non-table structured sources such as knowledge graphs or code repositories.
- The method could be combined with self-consistency sampling to further increase robustness on long tables.
Load-bearing premise
Constructing and reasoning over counterfactual variants, followed by weighted integration, will produce more accurate answers than single-direction reasoning without adding new errors or biases.
What would settle it
Running the full CRAFT pipeline on WikiTQ or TabFact with a fixed LLM backbone and finding that accuracy is equal to or lower than the single-direction baseline.
Figures

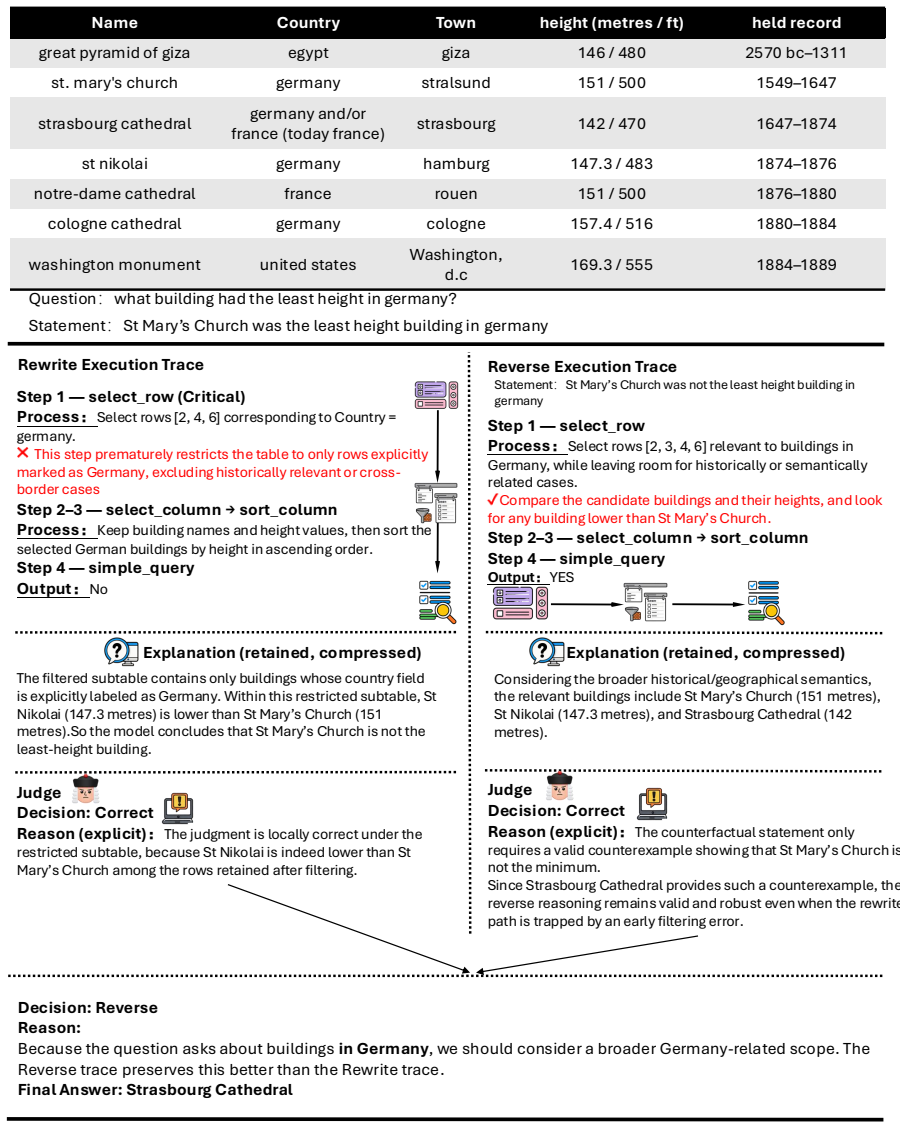




read the original abstract
Table reasoning remains challenging for large language models (LLMs), particularly in tasks that require multi-step inference over long and structured tables. Existing approaches predominantly rely on single-direction reasoning, which limits their ability to explore alternative hypotheses across tasks. In this work, we propose CRAFT, a unified Counterfactual Reasoning Framework that reformulates Tabular question answering and fact verification into a general bidirectional verification process. Our method explicitly constructs both declarative statements and their counterfactual variants. Evidence is then extracted from reasoning along both the original and counterfactual paths, and integrated via a weighted mechanism to arrive at the final answer. Experimental results show that our approach consistently surpasses representative baselines on table reasoning datasets such as WikiTQ and TabFact, achieving especially large improvements on complex question answering. Our framework also significantly mitigates performance gaps between different backbone LLMs. This indicates that counterfactual reasoning effectively overcomes the limitations of single-direction inference, guiding LLMs toward more discerning reasoning and establishing a more principled paradigm for structured reasoning tasks. Our code will be made publicly available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CRAFT, a unified counterfactual reasoning framework for tabular question answering and fact verification. It reformulates the tasks as a bidirectional verification process by explicitly constructing declarative statements and their counterfactual variants, extracting evidence along both original and counterfactual reasoning paths, and integrating the evidence via a weighted mechanism to produce the final answer. The central empirical claims are that this approach consistently outperforms representative baselines on WikiTQ and TabFact (with especially large gains on complex QA) and significantly reduces performance gaps across different LLM backbones.
Significance. If the empirical results hold and are supported by proper ablations and error analysis, the work could be moderately significant for table reasoning, as it offers a concrete mechanism to move beyond single-direction inference and potentially improve robustness and consistency across LLMs. The promised public code release would strengthen reproducibility.
major comments (2)
- [Abstract] Abstract: the abstract asserts performance improvements, gap reduction, and superiority on complex QA but supplies no quantitative results, implementation details, ablation studies, or error analysis, so it is impossible to determine whether the data actually support the stated claims.
- [Abstract] The central claim depends on the premise that bidirectional counterfactual construction plus weighted integration produces more accurate answers without introducing new sources of error or bias; no evidence is provided to evaluate whether this premise holds or whether the weighting step is robust.
Simulated Author's Rebuttal
We thank the referee for their review and comments. We address the two major comments on the abstract below, noting that the abstract provides a high-level summary while the supporting quantitative results, ablations, and analyses appear in the main manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts performance improvements, gap reduction, and superiority on complex QA but supplies no quantitative results, implementation details, ablation studies, or error analysis, so it is impossible to determine whether the data actually support the stated claims.
Authors: Abstracts are designed to be concise overviews and conventionally omit detailed numbers, implementation specifics, ablations, and error analyses. The manuscript supplies these in full: Section 4 reports the performance gains on WikiTQ and TabFact (including larger gains on complex questions), Section 5 contains the ablation studies on each component, and Section 6 presents the error analysis and LLM-gap reduction results. These sections directly support the claims summarized in the abstract. revision: no
-
Referee: [Abstract] The central claim depends on the premise that bidirectional counterfactual construction plus weighted integration produces more accurate answers without introducing new sources of error or bias; no evidence is provided to evaluate whether this premise holds or whether the weighting step is robust.
Authors: The manuscript evaluates this premise through controlled experiments. Main results show consistent accuracy gains from the bidirectional paths and weighted integration over single-direction baselines. Ablations isolate the contribution of counterfactual construction and the weighting mechanism, while error analysis and cross-LLM consistency metrics demonstrate that the approach reduces rather than introduces errors or bias. These evaluations appear in Sections 4–6. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper introduces CRAFT as an empirical framework that constructs counterfactual variants, extracts bidirectional evidence, and applies weighted integration for tabular QA and fact verification. All central claims rest on reported experimental gains versus baselines on WikiTQ and TabFact rather than any mathematical derivation, self-referential definition, or fitted parameter renamed as a prediction. No equations, uniqueness theorems, or self-citation chains appear in the abstract or method description that would reduce the target result to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sengamedu and Christos Faloutsos , journal=
Xi Fang and Weijie Xu and Fiona Anting Tan and Ziqing Hu and Jiani Zhang and Yanjun Qi and Srinivasan H. Sengamedu and Christos Faloutsos , journal=. Large Language Models (. 2024 , url=
2024
-
[2]
Transformers for Tabular Data Representation: A Survey of Models and Applications
Badaro, Gilbert and Saeed, Mohammed and Papotti, Paolo. Transformers for Tabular Data Representation: A Survey of Models and Applications. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00544
-
[3]
LLM s instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern \'a ndez, Raquel and Gatt, Albert and Ghaleb, Esam and Giulianelli, Mario and Hanna, Michael and Koller, Alexander and Martins, Andre and Mondorf, Philipp and Neplenbroek, Vera and Pezzelle, Sandro and Plank, Barbara and Schlangen, David and Suglia, Alessandro a...
-
[4]
2025 , howpublished =
OpenAI , title =. 2025 , howpublished =
2025
-
[5]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[6]
2020 , eprint=
TabFact: A Large-scale Dataset for Table-based Fact Verification , author=. 2020 , eprint=
2020
-
[7]
F in QA : A Dataset of Numerical Reasoning over Financial Data
Chen, Zhiyu and Chen, Wenhu and Smiley, Charese and Shah, Sameena and Borova, Iana and Langdon, Dylan and Moussa, Reema and Beane, Matt and Huang, Ting-Hao and Routledge, Bryan and Wang, William Yang. F in QA : A Dataset of Numerical Reasoning over Financial Data. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021...
-
[8]
2023 , eprint=
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. 2023 , eprint=
2023
-
[9]
2023 , eprint=
Binding Language Models in Symbolic Languages , author=. 2023 , eprint=
2023
-
[10]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[11]
Empowering Language Understanding with Counterfactual Reasoning
Feng, Fuli and Zhang, Jizhi and He, Xiangnan and Zhang, Hanwang and Chua, Tat-Seng. Empowering Language Understanding with Counterfactual Reasoning. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.196
-
[12]
T a P as: Weakly Supervised Table Parsing via Pre-training
Herzig, Jonathan and Nowak, Pawel Krzysztof and M. T a P as: Weakly Supervised Table Parsing via Pre-training. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.398
-
[13]
Jeong, Jiwon and Jang, Hyeju and Park, Hogun. Large Language Models Are Better Logical Fallacy Reasoners with Counterargument, Explanation, and Goal-Aware Prompt Formulation. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.384
-
[14]
2024 , eprint=
Tree-of-Table: Unleashing the Power of LLMs for Enhanced Large-Scale Table Understanding , author=. 2024 , eprint=
2024
-
[15]
Counterfactual-Consistency Prompting for Relative Temporal Understanding in Large Language Models
Kim, Jongho and Hwang, Seung-won. Counterfactual-Consistency Prompting for Relative Temporal Understanding in Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.acl-short.97
-
[16]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[17]
Counterfactual reasoning: Testing language models' understanding of hypothetical scenarios
Li, Jiaxuan and Yu, Lang and Ettinger, Allyson. Counterfactual reasoning: Testing language models' understanding of hypothetical scenarios. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.70
-
[18]
G raph OTTER : Evolving LLM -based Graph Reasoning for Complex Table Question Answering
Li, Qianlong and Huang, Chen and Li, Shuai and Xiang, Yuanxin and Xiong, Deng and Lei, Wenqiang. G raph OTTER : Evolving LLM -based Graph Reasoning for Complex Table Question Answering. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[19]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[20]
Jixiong Liu and Yoan Chabot and Raphaël Troncy and Viet-Phi Huynh and Thomas Labbé and Pierre Monnin , keywords =. From tabular data to knowledge graphs: A survey of semantic table interpretation tasks and methods , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.websem.2022.100761 , url =
-
[21]
2022 , eprint=
TAPEX: Table Pre-training via Learning a Neural SQL Executor , author=. 2022 , eprint=
2022
-
[22]
Rethinking Tabular Data Understanding with Large Language Models
Liu, Tianyang and Wang, Fei and Chen, Muhao. Rethinking Tabular Data Understanding with Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.26
-
[23]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[24]
Large language model for table processing: a survey , journal =
Weizheng LU Jing ZHANG Ju FAN Zihao FU Yueguo CHEN Xiaoyong DU , keywords =. Large language model for table processing: a survey , journal =. 2025 , issn =. doi:https://doi.org/10.1007/s11704-024-40763-6 , url =
-
[25]
2025 , eprint=
PoTable: Towards Systematic Thinking via Stage-oriented Plan-then-Execute Reasoning on Tables , author=. 2025 , eprint=
2025
-
[26]
T ab SQL ify: Enhancing Reasoning Capabilities of LLM s Through Table Decomposition
Nahid, Md Mahadi Hasan and Rafiei, Davood. T ab SQL ify: Enhancing Reasoning Capabilities of LLM s Through Table Decomposition. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.320
-
[27]
F e T a QA : Free-form Table Question Answering
Nan, Linyong and Hsieh, Chiachun and Mao, Ziming and Lin, Xi Victoria and Verma, Neha and Zhang, Rui and Kry \'s ci \'n ski, Wojciech and Schoelkopf, Hailey and Kong, Riley and Tang, Xiangru and Mutuma, Mutethia and Rosand, Ben and Trindade, Isabel and Bandaru, Renusree and Cunningham, Jacob and Xiong, Caiming and Radev, Dragomir. F e T a QA : Free-form T...
-
[28]
2023 , eprint=
LEVER: Learning to Verify Language-to-Code Generation with Execution , author=. 2023 , eprint=
2023
-
[29]
2026 , eprint=
ReasonTabQA: A Comprehensive Benchmark for Table Question Answering from Real World Industrial Scenarios , author=. 2026 , eprint=
2026
-
[30]
F a VIQ : FA ct Verification from Information-seeking Questions
Park, Jungsoo and Min, Sewon and Kang, Jaewoo and Zettlemoyer, Luke and Hajishirzi, Hannaneh. F a VIQ : FA ct Verification from Information-seeking Questions. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.354
-
[31]
Compositional Semantic Parsing on Semi-Structured Tables
Pasupat, Panupong and Liang, Percy. Compositional Semantic Parsing on Semi-Structured Tables. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015. doi:10.3115/v1/P15-1142
-
[32]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[33]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[34]
2024 , eprint=
Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution , author=. 2024 , eprint=
2024
-
[35]
2024 , eprint=
TableGPT2: A Large Multimodal Model with Tabular Data Integration , author=. 2024 , eprint=
2024
-
[36]
Sui, Yuan and Zou, Jiaru and Zhou, Mengyu and He, Xinyi and Du, Lun and Han, Shi and Zhang, Dongmei. TAP 4 LLM : Table Provider on Sampling, Augmenting, and Packing Semi-structured Data for Large Language Model Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.603
-
[37]
2025 , eprint=
Exchange of Perspective Prompting Enhances Reasoning in Large Language Models , author=. 2025 , eprint=
2025
-
[38]
Rating Roulette: Self-Inconsistency in LLM -As-A-Judge Frameworks
Haldar, Rajarshi and Hockenmaier, Julia. Rating Roulette: Self-Inconsistency in LLM -As-A-Judge Frameworks. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1361
-
[39]
QA - N at V er: Question Answering for Natural Logic-based Fact Verification
Aly, Rami and Strong, Marek and Vlachos, Andreas. QA - N at V er: Question Answering for Natural Logic-based Fact Verification. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.521
-
[40]
Is LLM -as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment
Raina, Vyas and Liusie, Adian and Gales, Mark. Is LLM -as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.427
-
[41]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[42]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[43]
On Positional Bias of Faithfulness for Long-form Summarization
Wan, David and Vig, Jesse and Bansal, Mohit and Joty, Shafiq. On Positional Bias of Faithfulness for Long-form Summarization. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.442
-
[44]
PNAS Nexus , volume =
Evidence from counterfactual tasks supports emergent analogical reasoning in large language models , author =. PNAS Nexus , volume =. 2025 , month =
2025
-
[45]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[46]
Factual Consistency Evaluation for Text Summarization via Counterfactual Estimation
Xie, Yuexiang and Sun, Fei and Deng, Yang and Li, Yaliang and Ding, Bolin. Factual Consistency Evaluation for Text Summarization via Counterfactual Estimation. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.10
-
[47]
Proceedings of INTERSPEECH 2023 , year =
Relation-based Counterfactual Data Augmentation and Contrastive Learning for Robustifying Natural Language Inference Models , author =. Proceedings of INTERSPEECH 2023 , year =
2023
-
[48]
Ye, Yunhu and Hui, Binyuan and Yang, Min and Li, Binhua and Huang, Fei and Li, Yongbin , title =. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2023 , isbn =. doi:10.1145/3539618.3591708 , abstract =
-
[49]
Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication
Yin, Zhangyue and Sun, Qiushi and Chang, Cheng and Guo, Qipeng and Dai, Junqi and Huang, Xuanjing and Qiu, Xipeng. Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.936
-
[50]
Table-Critic: A Multi-Agent Framework for Collaborative Criticism and Refinement in Table Reasoning
Yu, Peiying and Chen, Guoxin and Wang, Jingjing. Table-Critic: A Multi-Agent Framework for Collaborative Criticism and Refinement in Table Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.853
-
[51]
Zhang, Yunjia and Henkel, Jordan and Floratou, Avrilia and Cahoon, Joyce and Deep, Shaleen and Patel, Jignesh M. , title =. Proc. VLDB Endow. , month = apr, pages =. 2024 , issue_date =. doi:10.14778/3659437.3659452 , abstract =
-
[52]
ALTER : Augmentation for Large-Table-Based Reasoning
Zhang, Han and Ma, Yuheng and Yang, Hanfang. ALTER : Augmentation for Large-Table-Based Reasoning. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.9
-
[53]
Narrative-of-Thought: Improving Temporal Reasoning of Large Language Models via Recounted Narratives
Zhang, Xinliang Frederick and Beauchamp, Nick and Wang, Lu. Narrative-of-Thought: Improving Temporal Reasoning of Large Language Models via Recounted Narratives. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.963
-
[54]
T able LLM : Enabling Tabular Data Manipulation by LLM s in Real Office Usage Scenarios
Zhang, Xiaokang and Luo, Sijia and Zhang, Bohan and Ma, Zeyao and Zhang, Jing and Li, Yang and Li, Guanlin and Yao, Zijun and Xu, Kangli and Zhou, Jinchang and Zhang-Li, Daniel and Yu, Jifan and Zhao, Shu and Li, Juanzi and Tang, Jie. T able LLM : Enabling Tabular Data Manipulation by LLM s in Real Office Usage Scenarios. Findings of the Association for C...
-
[55]
Large Language Models as an Indirect Reasoner: Contrapositive and Contradiction for Automated Reasoning
Zhang, Yanfang and Sun, Yiliu and Zhan, Yibing and Tao, Dapeng and Tao, Dacheng and Gong, Chen. Large Language Models as an Indirect Reasoner: Contrapositive and Contradiction for Automated Reasoning. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[56]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[57]
Context-faithful Prompting for Large Language Models
Zhou, Wenxuan and Zhang, Sheng and Poon, Hoifung and Chen, Muhao. Context-faithful Prompting for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.968
-
[58]
Critic- C o T : Boosting the Reasoning Abilities of Large Language Model via Chain-of-Thought Critic
Zheng, Xin and Lou, Jie and Cao, Boxi and Wen, Xueru and Ji, Yuqiu and Lin, Hongyu and Lu, Yaojie and Han, Xianpei and Zhang, Debing and Sun, Le. Critic- C o T : Boosting the Reasoning Abilities of Large Language Model via Chain-of-Thought Critic. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.89
-
[59]
2025 , eprint=
Table-R1: Region-based Reinforcement Learning for Table Understanding , author=. 2025 , eprint=
2025
-
[60]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[61]
High-Quality Complex Text-to- SQL Data Generation through Chain-of-Verification
Zhang, Yuchen and Gao, Yuze and Chen, Bin and Li, Wenfeng and Sun, Shuo and Su, Jian. High-Quality Complex Text-to- SQL Data Generation through Chain-of-Verification. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 2025
2025
-
[62]
R e P anda: Pandas-powered Tabular Verification and Reasoning
Chegini, Atoosa and Rezaei, Keivan and Eghbalzadeh, Hamid and Feizi, Soheil. R e P anda: Pandas-powered Tabular Verification and Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1549
-
[63]
2025 , eprint=
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , author=. 2025 , eprint=
2025
-
[64]
Vicinagearth , volume=
TableZoomer: a collaborative agent framework for large-scale table question answering , author=. Vicinagearth , volume=. 2025 , doi=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.