FS-DVS: A Frequency-Selective Dynamic Visual Sensing Paradigm for Enhancing Information Completeness
Pith reviewed 2026-06-27 22:45 UTC · model grok-4.3
The pith
A learnable spatial filter placed before event generation in dynamic vision sensors evolves into center-surround patterns that match human contrast sensitivity and boost detection and recognition tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
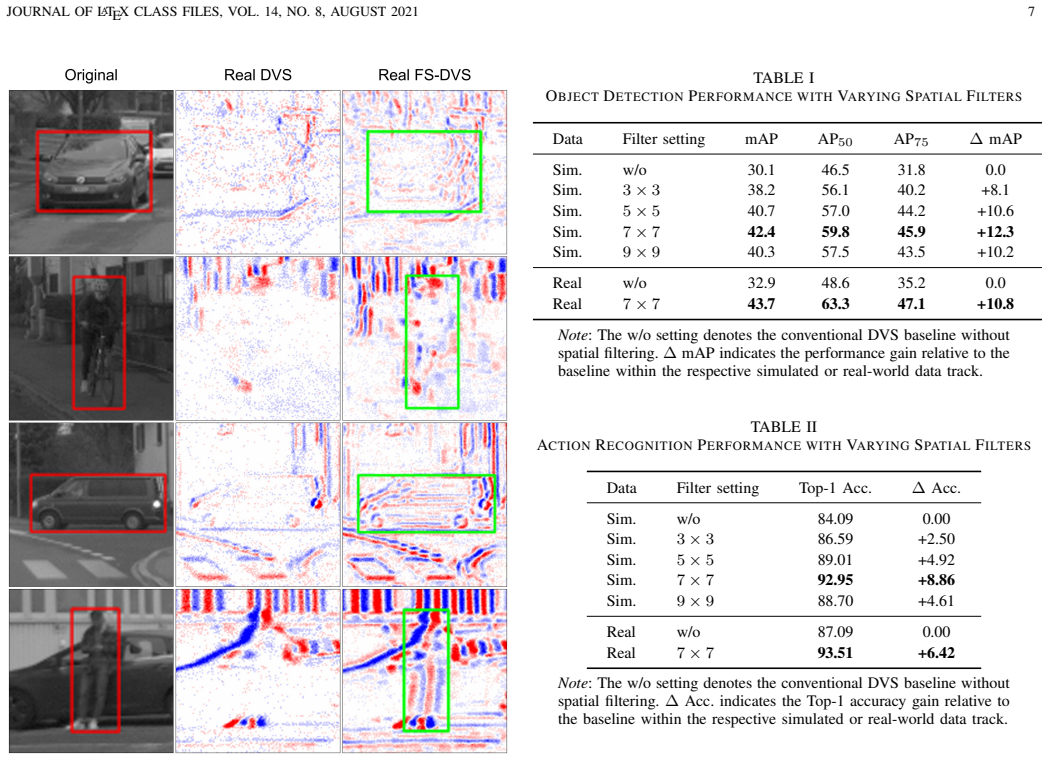
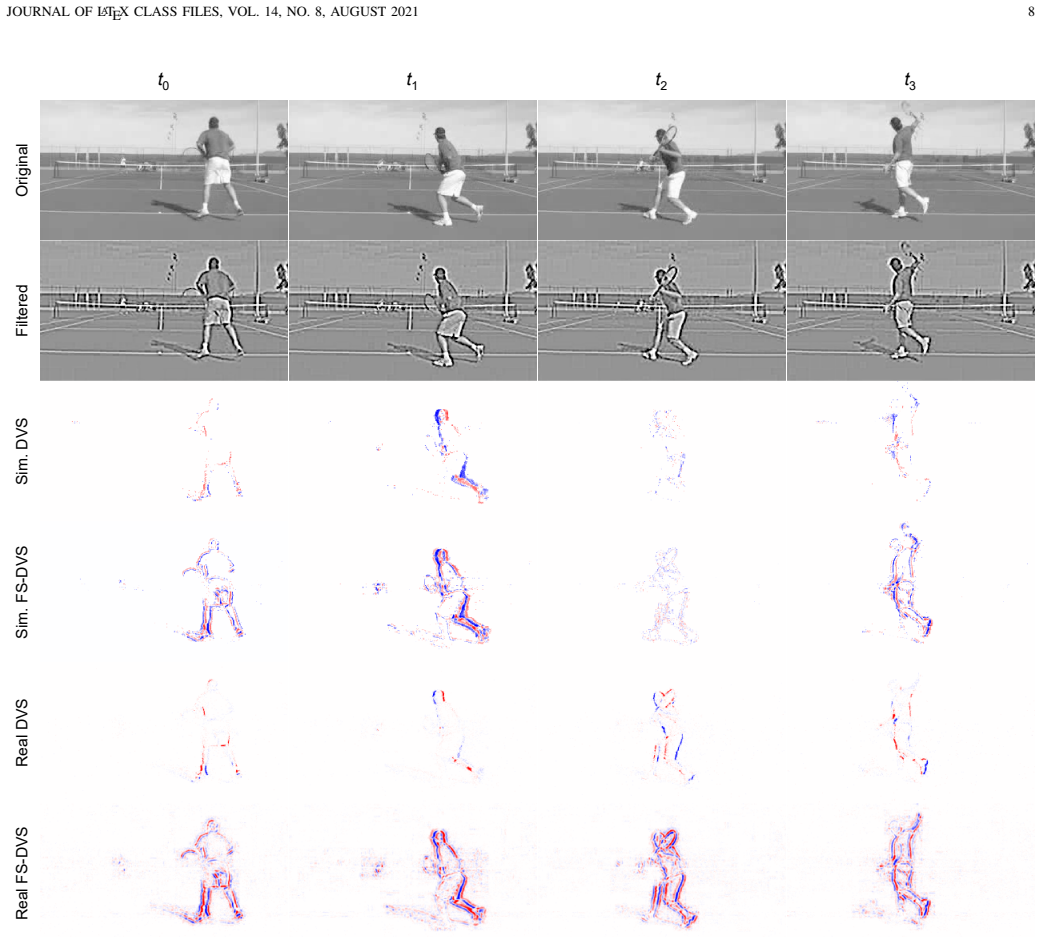
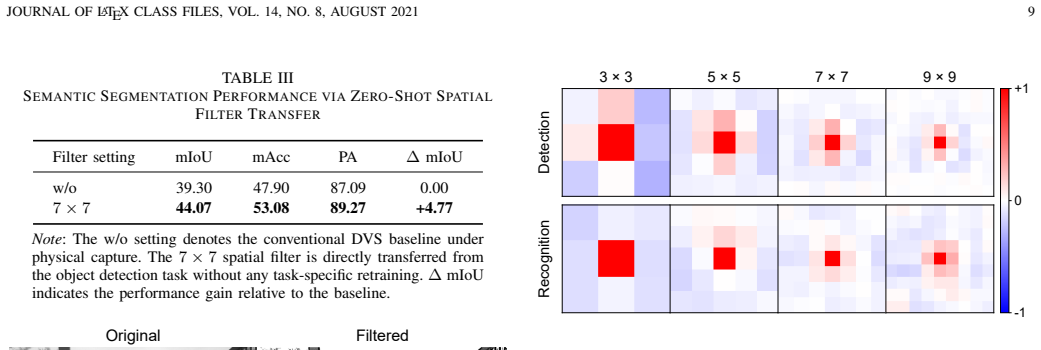
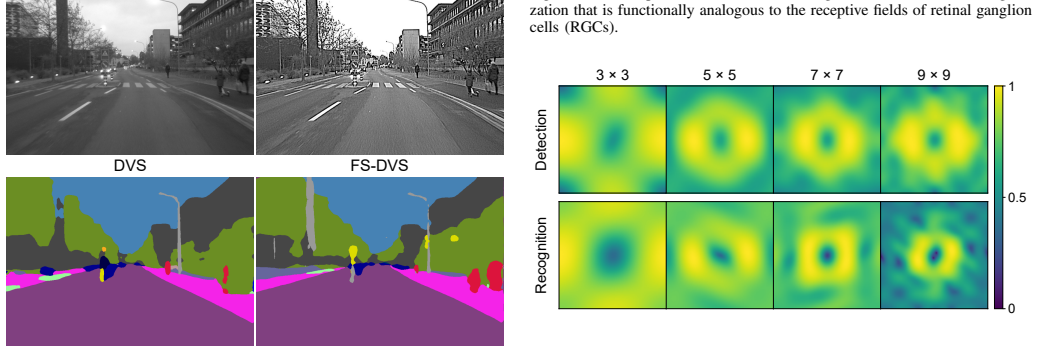
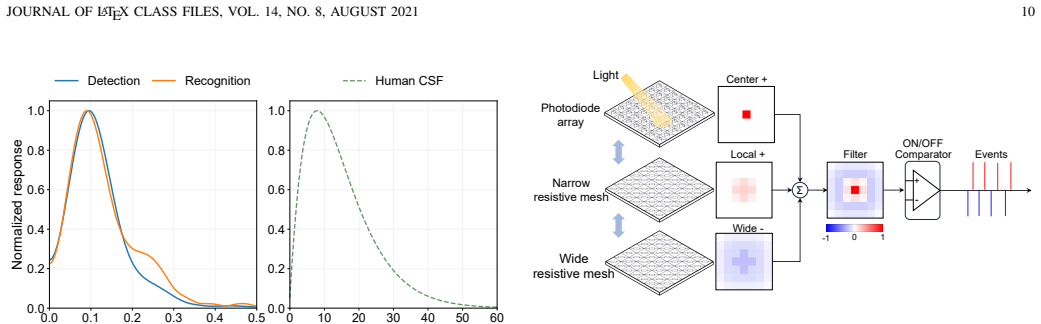
Starting from a delta function, the learned spatial filters spontaneously evolve into center-surround patterns that emphasize mid-frequency components, consistently aligning with human CSF and yielding substantial performance gains in object detection and action recognition.
What carries the argument
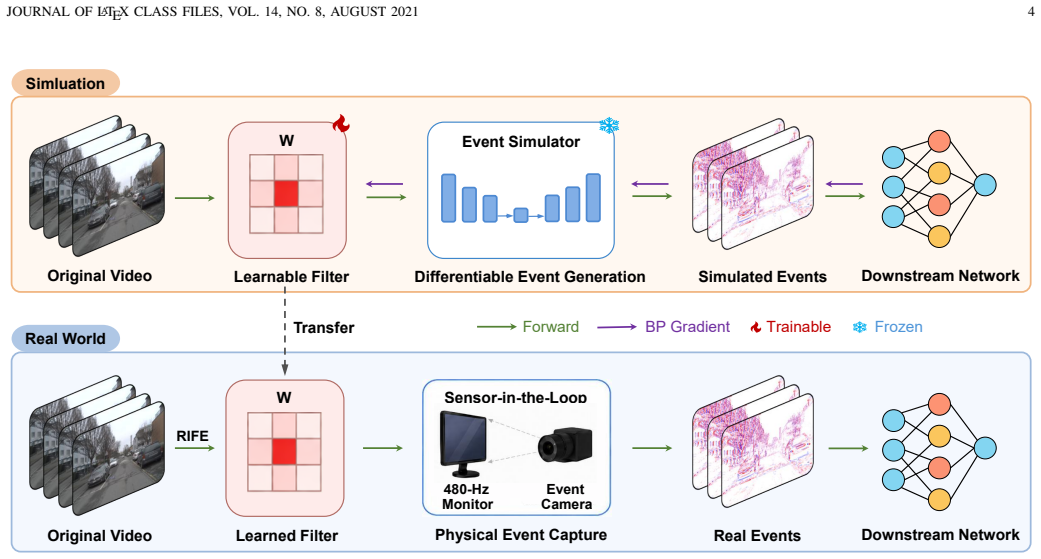
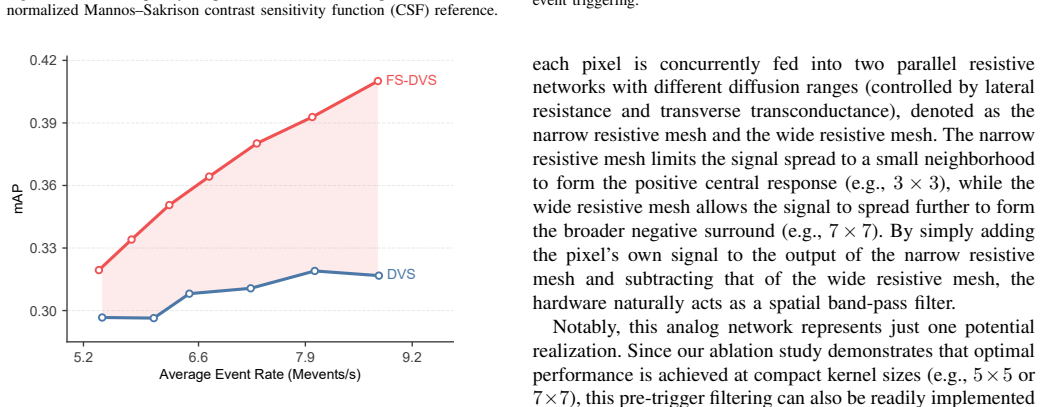
The learnable spatial filter placed strictly before the event triggering process and optimized end-to-end through a differentiable event simulation framework.
If this is right
- Object detection and action recognition accuracy increase because mid-frequency signals that would otherwise fall below threshold are preserved.
- The same center-surround pattern emerges regardless of the downstream task, indicating a task-independent frequency selection principle.
- Performance gains occur without the noise penalty that accompanies simply raising sensor sensitivity.
- The design supplies a concrete, biologically motivated alternative to post-processing or uniform threshold adjustment.
Where Pith is reading between the lines
- Embedding the learned filter directly in silicon could reduce the volume of events that must be transmitted while retaining task-relevant information.
- The same pre-filter principle might be tested on other event-based modalities such as audio or tactile sensors.
- Measuring how closely the learned filter matches measured retinal ganglion cell responses on the same stimuli would test biological fidelity.
- If the mid-frequency emphasis holds across lighting conditions, the sensor could maintain performance where conventional DVS lose low-contrast detail.
Load-bearing premise
The differentiable event simulation accurately reproduces the statistics and noise of physical DVS pixels so that gradients from simulation transfer to real hardware.
What would settle it
Running the trained filters on physical DVS hardware and finding that they neither produce center-surround patterns nor improve task accuracy relative to a standard sensor.
Figures

read the original abstract
Dynamic vision sensors (DVS) offer exceptional temporal resolution and dynamic range by asynchronously reporting pixel-level intensity changes. However, conventional DVS rely on a per-pixel independent triggering mechanism, ignoring the spatial integration performed by biological retinal ganglion cells (RGCs). Consequently, they lack the contrast sensitivity function (CSF) and its inherent sensitivity to mid-spatial frequencies, which inevitably leads to information incompleteness due to sub-threshold signal loss. To bridge this gap, we propose FS-DVS (Frequency-Selective Dynamic Vision Sensor), a novel paradigm that integrates a learnable spatial filter strictly preceding the event triggering process to mimic the RGC aggregation mechanism. By developing a differentiable event simulation framework, the spatial filter can be optimized end-to-end with downstream tasks. Our study reveals that starting from a delta function, the learned spatial filters spontaneously evolve into center-surround patterns that emphasize mid-frequency components, consistently aligning with human CSF. Beyond achieving substantial performance gains in object detection and action recognition, the consistent convergence to human-like CSF characteristics across different tasks underscores the universality of this mid-frequency selective mechanism. Compared to naively increasing sensor sensitivity or relying on post-processing, our paradigm achieves selective information enhancement with high noise resilience, providing a robust, biologically plausible blueprint for next-generation neuromorphic sensors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FS-DVS, a frequency-selective dynamic vision sensor that prepends a learnable spatial filter to the conventional per-pixel DVS event triggering process in order to emulate retinal ganglion cell spatial integration. A differentiable event simulation framework enables end-to-end optimization of the filter jointly with downstream tasks; the authors report that filters initialized as delta functions spontaneously converge to center-surround patterns whose frequency response aligns with the human contrast sensitivity function (CSF), producing performance gains on object detection and action recognition while remaining robust to noise.
Significance. If the simulation fidelity and independence of the CSF alignment can be established, the work would supply a concrete, task-driven route to biologically motivated sensor design that selectively enhances mid-frequency information without simply raising sensitivity. The reported consistency of filter convergence across tasks is a notable strength, as is the use of a fully differentiable pipeline that permits gradient-based exploration of neuromorphic front-end architectures.
major comments (3)
- [Differentiable Event Simulation section] Differentiable Event Simulation section: no quantitative validation (event-rate histograms, noise power spectra, or contrast-threshold curves) is shown comparing simulated DVS output to real hardware recordings on identical stimuli. Because the central claim—that learned filters and downstream gains will transfer to physical sensors—rests on the simulator reproducing shot noise, dark current, and triggering statistics, this omission is load-bearing.
- [Filter evolution and CSF alignment (abstract and results)] Filter evolution and CSF alignment (abstract and results): the claim that alignment with human CSF occurs 'spontaneously' from a delta-function initialization depends on the precise task loss, any auxiliary terms, and the absence of implicit biases in the event model. Without an explicit statement of the objective, initialization protocol, or ablation removing task-specific gradients, it is impossible to assess whether the mid-frequency emphasis is independent of the fitting process.
- [Experimental evaluation] Experimental evaluation: performance improvements on object detection and action recognition are presented without an ablation that isolates the spatial filter from other pipeline changes (e.g., overall event rate or post-processing). This makes it difficult to attribute gains specifically to the frequency-selective mechanism rather than to increased information throughput.
minor comments (1)
- [Figure captions] Figure captions and axis labels in the filter visualization panels would benefit from explicit indication of spatial frequency units and direct overlay of the human CSF curve for immediate visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications and committing to revisions that strengthen the claims regarding simulator fidelity, filter convergence, and attribution of performance gains.
read point-by-point responses
-
Referee: [Differentiable Event Simulation section] Differentiable Event Simulation section: no quantitative validation (event-rate histograms, noise power spectra, or contrast-threshold curves) is shown comparing simulated DVS output to real hardware recordings on identical stimuli. Because the central claim—that learned filters and downstream gains will transfer to physical sensors—rests on the simulator reproducing shot noise, dark current, and triggering statistics, this omission is load-bearing.
Authors: We agree that explicit quantitative validation of the simulator against real DVS hardware is necessary to support transferability claims. The simulator follows established models for shot noise, dark current, and per-pixel triggering, but no direct side-by-side comparison with hardware recordings on matched stimuli was included. In the revised manuscript we will add event-rate histograms, noise spectra, and contrast-threshold curves using publicly available DVS datasets with controlled stimuli to quantify fidelity. revision: yes
-
Referee: [Filter evolution and CSF alignment (abstract and results)] Filter evolution and CSF alignment (abstract and results): the claim that alignment with human CSF occurs 'spontaneously' from a delta-function initialization depends on the precise task loss, any auxiliary terms, and the absence of implicit biases in the event model. Without an explicit statement of the objective, initialization protocol, or ablation removing task-specific gradients, it is impossible to assess whether the mid-frequency emphasis is independent of the fitting process.
Authors: The objective is strictly the downstream task loss with no auxiliary frequency-regularization terms. Initialization is a centered delta function, and the event model contains no explicit frequency bias. To demonstrate that mid-frequency emphasis arises independently of task-specific gradients, the revision will include an ablation that detaches gradients from the filter or substitutes a non-task loss; we will also state the full objective and initialization protocol more explicitly in the methods. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: performance improvements on object detection and action recognition are presented without an ablation that isolates the spatial filter from other pipeline changes (e.g., overall event rate or post-processing). This makes it difficult to attribute gains specifically to the frequency-selective mechanism rather than to increased information throughput.
Authors: We acknowledge that the current experiments do not fully isolate the learned filter from changes in event rate or post-processing. The revision will add controlled ablations that (i) match event rates between FS-DVS and baselines by threshold adjustment, (ii) compare against fixed/random spatial filters, and (iii) include post-processing baselines, thereby attributing gains specifically to the frequency-selective front-end. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical outcome from end-to-end optimization of a learnable spatial filter in a differentiable simulator, where filters starting from a delta function are observed to converge to center-surround shapes. This is presented as an emergent result of task-driven training rather than any definitional equivalence, fitted parameter renamed as prediction, or self-citation chain that reduces the claim to its inputs by construction. No equations or sections in the provided text exhibit a reduction of the CSF alignment or performance gains to a tautology or prior self-cited result; the simulator fidelity is an unverified modeling assumption but does not create circularity in the derivation. The central claim retains independent content from the optimization process itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- spatial filter kernel weights
axioms (1)
- domain assumption Differentiable event simulation accurately models real DVS triggering statistics
Reference graph
Works this paper leans on
-
[1]
A128×128120 dB15µs latency asynchronous temporal contrast vision sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A128×128120 dB15µs latency asynchronous temporal contrast vision sensor,”IEEE Journal of Solid-State Circuits, vol. 43, no. 2, pp. 566–576, 2008
2008
-
[2]
Event- based vision: A survey,
G. Gallego, T. Delbr ¨uck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidiset al., “Event- based vision: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 1, pp. 154–180, 2020
2020
-
[3]
B. A. Wandell,Foundations of Vision: Behavior, Neuroscience, and Computation. Sunderland, MA, USA: Sinauer Associates, 1995
1995
-
[4]
Discharge patterns and functional organization of mam- malian retina,
S. W. Kuffler, “Discharge patterns and functional organization of mam- malian retina,”Journal of neurophysiology, vol. 16, no. 1, pp. 37–68, 1953
1953
-
[5]
Application of fourier analysis to the visibility of gratings,
F. W. Campbell and J. G. Robson, “Application of fourier analysis to the visibility of gratings,”The Journal of physiology, vol. 197, no. 3, p. 551, 1968
1968
-
[6]
Feedback control of event cameras,
T. Delbruck, R. Graca, and M. Paluch, “Feedback control of event cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1324–1332
2021
-
[7]
Vlsi analogs of neuronal visual processing: a synthesis of form and function,
M. Mahowald, “Vlsi analogs of neuronal visual processing: a synthesis of form and function,” Ph.D. dissertation, California Institute of Tech- nology Pasadena, 1992
1992
-
[8]
Retinomorphic event-based vision sensors: bioinspired cameras with spiking output,
C. Posch, T. Serrano-Gotarredona, B. Linares-Barranco, and T. Del- bruck, “Retinomorphic event-based vision sensors: bioinspired cameras with spiking output,”Proceedings of the IEEE, vol. 102, no. 10, pp. 1470–1484, 2014
2014
-
[9]
Neuromorophic vision sensing and processing,
T. Delbruck, “Neuromorophic vision sensing and processing,” in2016 46Th european solid-state device research conference (ESSDERC). IEEE, 2016, pp. 7–14
2016
-
[10]
A qvga 143 db dynamic range frame-free pwm image sensor with lossless pixel-level video com- pression and time-domain cds,
C. Posch, D. Matolin, and R. Wohlgenannt, “A qvga 143 db dynamic range frame-free pwm image sensor with lossless pixel-level video com- pression and time-domain cds,”IEEE Journal of Solid-State Circuits, vol. 46, no. 1, pp. 259–275, 2010
2010
-
[11]
A 240× 180 130 db 3µs latency global shutter spatiotemporal vision sensor,
C. Brandli, R. Berner, M. Yang, S.-C. Liu, and T. Delbruck, “A 240× 180 130 db 3µs latency global shutter spatiotemporal vision sensor,” IEEE Journal of Solid-State Circuits, vol. 49, no. 10, pp. 2333–2341, 2014
2014
-
[12]
Utility and feasi- bility of a center surround event camera,
T. Delbruck, C. Li, R. Graca, and B. Mcreynolds, “Utility and feasi- bility of a center surround event camera,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 381–385
2022
-
[13]
Neural ganglion sensors: Learning task- specific event cameras inspired by the neural circuit of the human retina,
H. M. So and G. Wetzstein, “Neural ganglion sensors: Learning task- specific event cameras inspired by the neural circuit of the human retina,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4616–4626
2025
-
[14]
Esim: an open event camera simulator,
H. Rebecq, D. Gehrig, and D. Scaramuzza, “Esim: an open event camera simulator,” inConference on robot learning. PMLR, 2018, pp. 969– 982
2018
-
[15]
v2e: From video frames to realistic dvs events,
Y . Hu, S.-C. Liu, and T. Delbruck, “v2e: From video frames to realistic dvs events,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1312–1321
2021
-
[16]
Eventgan: Leveraging large scale image datasets for event cameras,
A. Z. Zhu, Z. Wang, K. Khant, and K. Daniilidis, “Eventgan: Leveraging large scale image datasets for event cameras,” in2021 IEEE interna- tional conference on computational photography (ICCP). IEEE, 2021, pp. 1–11
2021
-
[17]
V2ce: Video to continuous events simulator,
Z. Zhang, S. Cui, K. Chai, H. Yu, S. Dasgupta, U. Mahbub, and T. Rahman, “V2ce: Video to continuous events simulator,” in2024 IEEE international conference on robotics and automation (ICRA). IEEE, 2024, pp. 12 455–12 461
2024
-
[18]
Spikformer: When spiking neural network meets transformer,
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Yan, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,”arXiv preprint arXiv:2209.15425, 2022
-
[19]
Deep directly- trained spiking neural networks for object detection,
Q. Su, Y . Chou, Y . Hu, J. Li, S. Mei, Z. Zhang, and G. Li, “Deep directly- trained spiking neural networks for object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 6555–6565
2023
-
[20]
Event-based video reconstruction via potential-assisted spiking neural network,
L. Zhu, X. Wang, Y . Chang, J. Li, T. Huang, and Y . Tian, “Event-based video reconstruction via potential-assisted spiking neural network,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3594–3604
2022
-
[21]
Learning to detect objects with a 1 megapixel event camera,
E. Perot, P. De Tournemire, D. Nitti, J. Masci, and A. Sironi, “Learning to detect objects with a 1 megapixel event camera,”Advances in Neural Information Processing Systems, vol. 33, pp. 16 639–16 652, 2020
2020
-
[22]
Unsupervised event- based learning of optical flow, depth, and egomotion,
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Unsupervised event- based learning of optical flow, depth, and egomotion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 989–997
2019
-
[23]
From chaos comes order: Ordering event representations for object recognition and detection,
N. Zubi ´c, D. Gehrig, M. Gehrig, and D. Scaramuzza, “From chaos comes order: Ordering event representations for object recognition and detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 846–12 856
2023
-
[24]
Evrepsl: Event-stream representation via self-supervised learning for event-based vision,
Q. Qu, X. Chen, Y . Ying Chung, and Y . Shen, “Evrepsl: Event-stream representation via self-supervised learning for event-based vision,”IEEE Transactions on Image Processing, vol. 33, pp. 6579–6591, 2024
2024
-
[25]
Spiking-yolo: spiking neural network for energy-efficient object detection,
S. Kim, S. Park, B. Na, and S. Yoon, “Spiking-yolo: spiking neural network for energy-efficient object detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 11 270–11 277
2020
-
[26]
Integer-valued training and spike-driven inference spiking neural network for high-performance and energy-efficient object detection,
X. Luo, M. Yao, Y . Chou, B. Xu, and G. Li, “Integer-valued training and spike-driven inference spiking neural network for high-performance and energy-efficient object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 253–272
2024
-
[27]
Recurrent vision transformers for object detection with event cameras,
M. Gehrig and D. Scaramuzza, “Recurrent vision transformers for object detection with event cameras,” inProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2023, pp. 13 884– 13 893
2023
-
[28]
Get: Group event transformer for event-based vision,
Y . Peng, Y . Zhang, Z. Xiong, X. Sun, and F. Wu, “Get: Group event transformer for event-based vision,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 6038–6048
2023
-
[29]
Scene adaptive sparse transformer for event-based object detection,
Y . Peng, H. Li, Y . Zhang, X. Sun, and F. Wu, “Scene adaptive sparse transformer for event-based object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 794–16 804
2024
-
[30]
Evrt-detr: Latent space adaptation of image detectors for event-based vision,
D. Torbunov, Y . Ren, A. Ghose, O. Dim, and Y . Cui, “Evrt-detr: Latent space adaptation of image detectors for event-based vision,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 9812–9821
2025
-
[31]
Vmv-gcn: V olumetric multi-view based graph cnn for event stream classification,
B. Xie, Y . Deng, Z. Shao, H. Liu, and Y . Li, “Vmv-gcn: V olumetric multi-view based graph cnn for event stream classification,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1976–1983, 2022
1976
-
[32]
Action recognition and benchmark using event cameras,
Y . Gao, J. Lu, S. Li, N. Ma, S. Du, Y . Li, and Q. Dai, “Action recognition and benchmark using event cameras,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14 081–14 097, 2023
2023
-
[33]
Event transformer. a sparse-aware solution for efficient event data processing,
A. Sabater, L. Montesano, and A. C. Murillo, “Event transformer. a sparse-aware solution for efficient event data processing,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2022, pp. 2676–2685
2022
-
[34]
Eventtransact: A video transformer-based framework for event-camera based action recognition,
T. De Blegiers, I. R. Dave, A. Yousaf, and M. Shah, “Eventtransact: A video transformer-based framework for event-camera based action recognition,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 1–7
2023
-
[35]
Sstformer: Bridging spiking neural network and memory support transformer for frame-event based-recognition,
X. Wang, Y . Rong, Z. Wu, L. Zhu, B. Jiang, J. Tang, and Y . Tian, “Sstformer: Bridging spiking neural network and memory support transformer for frame-event based-recognition,”IEEE Transactions on Cognitive and Developmental Systems, vol. 17, no. 6, pp. 1488–1502, 2025
2025
-
[36]
E2(go)motion: Motion augmented event stream for egocentric action recognition,
C. Plizzari, M. Planamente, G. Goletto, M. Cannici, E. Gusso, M. Mat- teucci, and B. Caputo, “E2(go)motion: Motion augmented event stream for egocentric action recognition,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 19 903– 19 915
2022
-
[37]
Ess: Learning event-based semantic segmentation from still images,
Z. Sun, N. Messikommer, D. Gehrig, and D. Scaramuzza, “Ess: Learning event-based semantic segmentation from still images,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 341–357
2022
-
[38]
Event-based semantic segmentation with posterior attention,
Z. Jia, K. You, W. He, Y . Tian, Y . Feng, Y . Wang, X. Jia, Y . Lou, J. Zhang, G. Liet al., “Event-based semantic segmentation with posterior attention,”IEEE Transactions on Image Processing, vol. 32, pp. 1829– 1842, 2023
2023
-
[39]
Hierarchical neural memory network for low latency event processing,
R. Hamaguchi, Y . Furukawa, M. Onishi, and K. Sakurada, “Hierarchical neural memory network for low latency event processing,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 867–22 876
2023
-
[40]
Event-based semantic segmentation with posterior attention,
Z. Jia, K. You, W. He, Y . Tian, Y . Feng, Y . Wang, X. Jia, Y . Lou, J. Zhang, G. Li, and Z. Zhang, “Event-based semantic segmentation with posterior attention,”IEEE Transactions on Image Processing, vol. 32, pp. 1829–1842, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2023
-
[41]
Real-time intermediate flow estimation for video frame interpolation,
Z. Huang, T. Zhang, W. Heng, B. Shi, and S. Zhou, “Real-time intermediate flow estimation for video frame interpolation,” 2022. [Online]. Available: https://arxiv.org/abs/2011.06294
-
[42]
Dsec: A stereo event camera dataset for driving scenarios,
M. Gehrig, W. Aarents, D. Gehrig, and D. Scaramuzza, “Dsec: A stereo event camera dataset for driving scenarios,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4947–4954, 2021
2021
-
[43]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 16 965–16 974
2024
-
[44]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,” 2012. [Online]. Available: https://arxiv.org/abs/1212.0402
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[45]
Mvitv2: Improved multiscale vision transformers for classification and detection,
Y . Li, C.-Y . Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 4804–4814
2022
-
[46]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision (ECCV), 2014, pp. 740–755
2014
-
[47]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 1290–1299
2022
-
[48]
The effects of a visual fidelity criterion of the encoding of images,
J. Mannos and D. Sakrison, “The effects of a visual fidelity criterion of the encoding of images,”IEEE Transactions on Information Theory, vol. 20, no. 4, pp. 525–536, 1974
1974
-
[49]
Hypere2vid: Improving event-based video reconstruction via hypernetworks,
B. Ercan, O. Eker, C. Saglam, A. Erdem, and E. Erdem, “Hypere2vid: Improving event-based video reconstruction via hypernetworks,”IEEE Transactions on Image Processing, vol. 33, pp. 1826–1837, 2024
2024
-
[50]
Utility and feasi- bility of a center surround event camera,
T. Delbruck, C. Li, R. Graca, and B. Mcreynolds, “Utility and feasi- bility of a center surround event camera,” in2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 381–385
2022
-
[51]
Parallel photonic chip for nanosecond end-to-end image processing, transmission, and reconstruction,
W. Wu, T. Zhou, and L. Fang, “Parallel photonic chip for nanosecond end-to-end image processing, transmission, and reconstruction,”Optica, vol. 11, no. 6, pp. 831–837, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.