Neuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints
Pith reviewed 2026-06-27 22:02 UTC · model grok-4.3
The pith
Object-importance learning for long-horizon robot planning is solved by casting it as a bilevel optimization problem whose lower level is stabilized by parallel Repair, Restart and Rollback recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
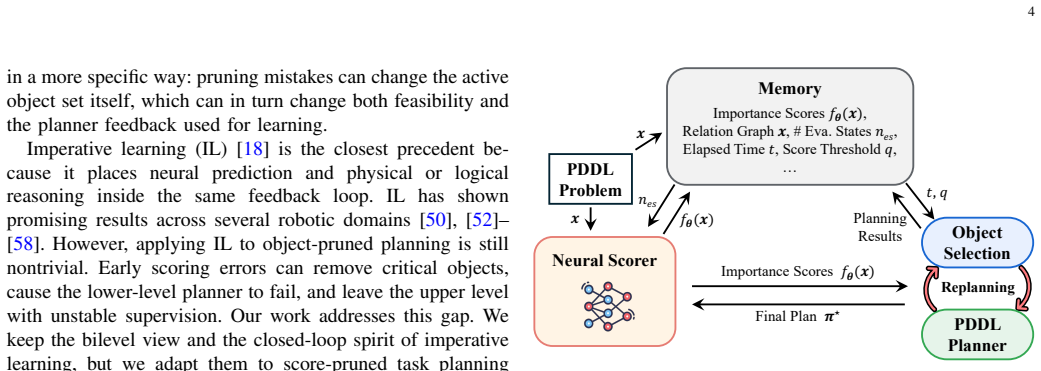
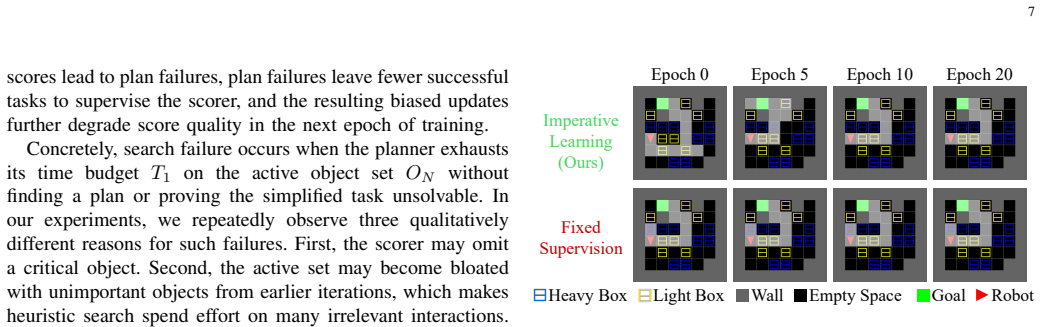
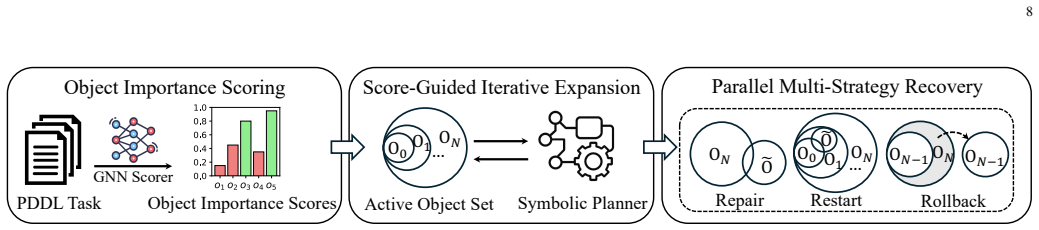
Object-importance learning for task planning is formulated as an imperative learning-based bilevel optimization problem in which the upper level optimizes a neural scorer and the lower level solves the symbolic planning problem inside the score-pruned search space; a 3R strategy of parallel Repair, Restart and Rollback recovery is added to the lower level to furnish reliable adaptive feedback to the upper level.
What carries the argument
Bilevel optimization whose lower-level symbolic planner is augmented with a 3R (Repair, Restart, Rollback) recovery mechanism that returns usable feedback even when the current pruning is imperfect.
If this is right
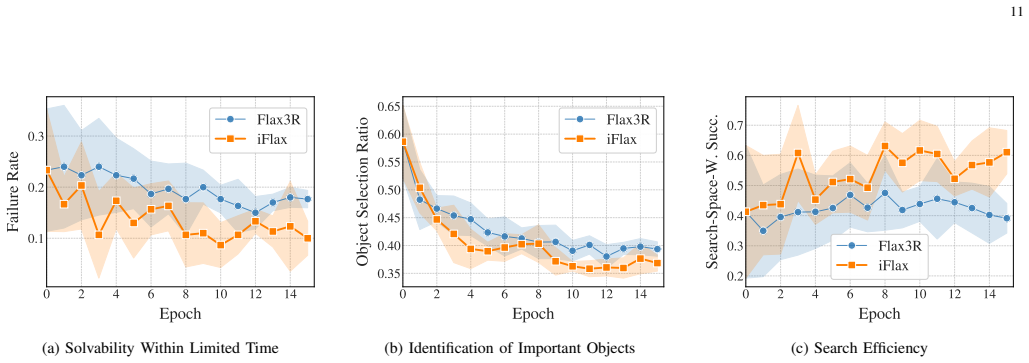
- The neural scorer improves directly from the planner's own mistakes rather than from static offline labels.
- Planning time and failure rate both drop because the search space stays pruned yet the scorer stays calibrated to the spaces it actually creates.
- The same bilevel structure can be used on any symbolic planner that accepts object subsets as input.
- The framework transfers from simulation to a physical quadruped-based mobile manipulator without additional retraining.
Where Pith is reading between the lines
- The bilevel formulation could be applied to any setting where a learned component must be trained inside the output distribution it itself induces.
- If the 3R overhead scales linearly with the number of objects, the method may become less attractive for very large scenes unless the recovery steps are themselves learned.
- The approach suggests that exposure bias in other neuro-symbolic pipelines can be closed by making the symbolic component supply the training signal rather than by collecting more offline data.
Load-bearing premise
The 3R recovery procedures inside the symbolic planner always return feedback that is both reliable enough and unbiased enough for the neural upper level to improve.
What would settle it
Train the same neural scorer with the 3R strategy disabled and measure whether the failure rate on the three benchmarks returns to the level of the offline-supervised baselines.
Figures

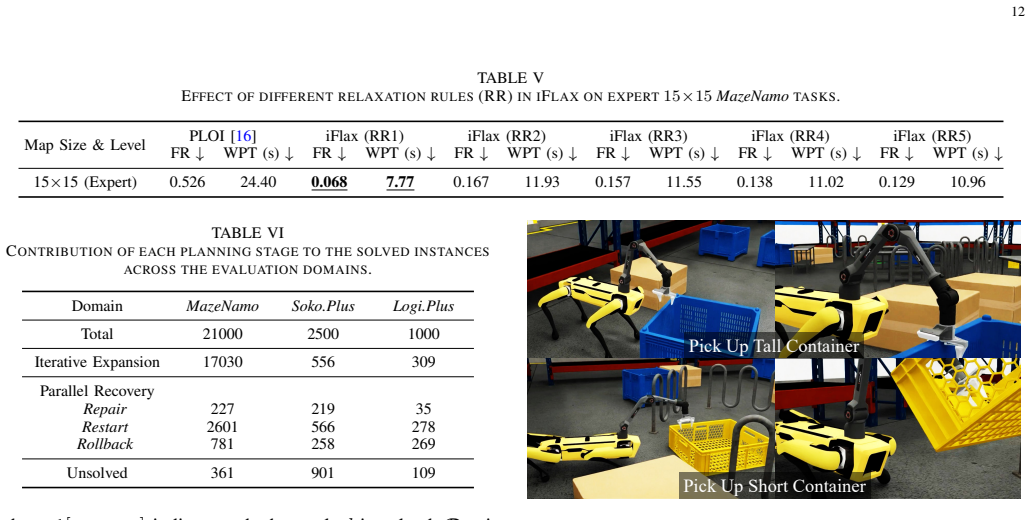




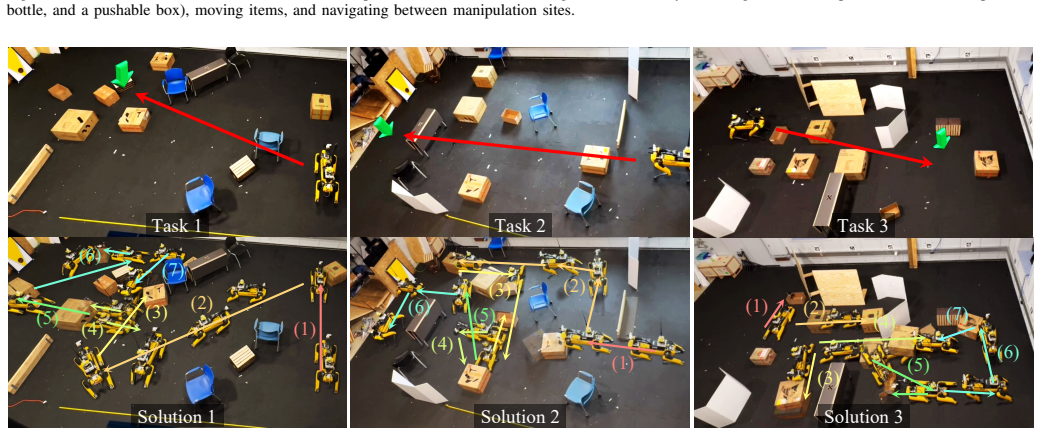
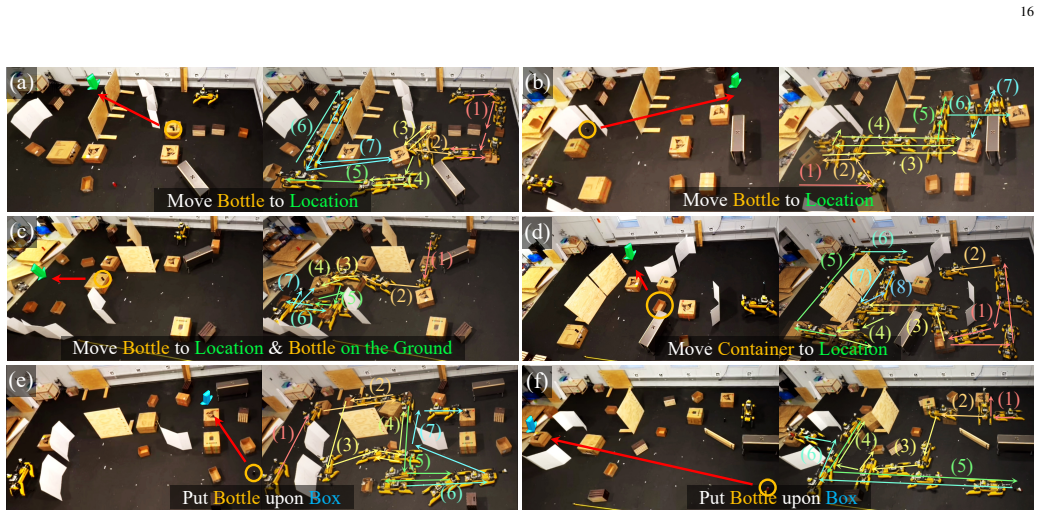
read the original abstract
Task planning often suffers from severe efficiency bottlenecks when robots must reason over long-horizon action sequences under complex logical constraints, including object affordances, spatial relationships, and sequential action dependencies. Recent neuro-symbolic methods improve planning efficiency by learning object-importance scores to prune task-irrelevant objects, but they typically rely on fixed offline supervision generated from full search spaces. This creates a train-test mismatch: at deployment, the planner operates in pruned search spaces induced by the model's own imperfect predictions, leading to exposure bias and degraded planning performance. To address this challenge, we formulate object-importance learning for task planning as an imperative learning-based bilevel optimization problem. The upper level optimizes a neural scorer, while the lower level solves a symbolic planning problem in the score-pruned search space. To stabilize this learning process, we introduce a 3R strategy into the lower-level planning, using parallel Repair, Restart, and Rollback recovery to provide reliable and adaptive feedback for upper-level learning. Experiments on three challenging benchmarks demonstrate state-of-the-art performance, including an 80.04% reduction in failure rate and a 57.14% reduction in planning time. We further validate the framework on a quadruped-based mobile manipulator in simulation and the real world, demonstrating its potential for efficient and deployable neuro-symbolic task planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a neuro-symbolic framework for long-horizon robotic task planning under complex logical constraints (object affordances, spatial relations, action dependencies). It formulates object-importance learning as an imperative learning-based bilevel optimization problem, with a neural scorer at the upper level and symbolic planning in the score-pruned space at the lower level. A 3R recovery strategy (parallel Repair, Restart, Rollback) is introduced to stabilize learning by supplying reliable feedback and mitigating exposure bias. Experiments on three benchmarks report state-of-the-art results, including an 80.04% reduction in failure rate and 57.14% reduction in planning time, with additional validation on a quadruped mobile manipulator in simulation and the real world.
Significance. If the empirical gains and stabilization properties hold under rigorous verification, the bilevel formulation and 3R mechanism could meaningfully advance neuro-symbolic planning by closing the train-test mismatch that arises from offline supervision. The approach combines symbolic pruning with adaptive recovery in a way that may generalize to other constrained planning domains.
major comments (2)
- [Abstract] Abstract: the central performance claims (80.04% failure-rate reduction, 57.14% planning-time reduction, SOTA status) are stated without derivation details, convergence arguments for the bilevel problem, ablation studies on the 3R components, or error analysis; the soundness of these quantitative results therefore cannot be assessed from the given text.
- [Abstract] The weakest assumption—that the 3R strategy supplies reliable, unbiased feedback to the upper-level neural scorer without introducing excessive overhead or new biases—is stated but not accompanied by any supporting analysis or sensitivity experiments in the provided manuscript.
minor comments (1)
- The manuscript would benefit from explicit pseudocode or algorithmic listing for the bilevel optimization loop and the parallel 3R recovery procedures to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, agreeing that the abstract can be strengthened for better context while noting that supporting details appear in the body of the paper. We commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (80.04% failure-rate reduction, 57.14% planning-time reduction, SOTA status) are stated without derivation details, convergence arguments for the bilevel problem, ablation studies on the 3R components, or error analysis; the soundness of these quantitative results therefore cannot be assessed from the given text.
Authors: The performance metrics are computed directly from the benchmark comparisons in Section 5, with SOTA status established via direct numerical comparison to prior neuro-symbolic and symbolic planners. The bilevel formulation appears in Section 3, the 3R mechanism and its role in mitigating exposure bias are derived in Section 4, ablation studies isolating each 3R component are reported in Section 5.3, and error analysis (including failure modes and planning-time distributions) is provided in Section 6. We agree the abstract is too terse to convey these locations. We will revise the abstract to add one sentence referencing the experimental sections and the 3R stabilization analysis. revision: yes
-
Referee: [Abstract] The weakest assumption—that the 3R strategy supplies reliable, unbiased feedback to the upper-level neural scorer without introducing excessive overhead or new biases—is stated but not accompanied by any supporting analysis or sensitivity experiments in the provided manuscript.
Authors: We acknowledge that the manuscript would be strengthened by explicit sensitivity analysis of the 3R components with respect to feedback reliability, bias introduction, and runtime overhead. While the overall results and component ablations in Section 5 demonstrate empirical stabilization, dedicated sensitivity experiments (e.g., varying recovery thresholds and measuring bias metrics) are absent. We will add a new paragraph and accompanying table in Section 5.3 (or an appendix) that reports these measurements on the three benchmarks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper formulates object-importance learning as a bilevel optimization problem with an upper-level neural scorer and lower-level symbolic planner, stabilized by a novel 3R (Repair, Restart, Rollback) recovery strategy. No equations, derivations, or claims in the provided abstract reduce a result to its own inputs by construction, rename fitted parameters as predictions, or rely on load-bearing self-citations for uniqueness. The central contribution is presented as an independent optimization formulation with external experimental validation on benchmarks, making the derivation self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Home service robot task planning using semantic knowledge and probabilistic inference,
Z. Wang, G. Tian, and X. Shao, “Home service robot task planning using semantic knowledge and probabilistic inference,”Knowledge- Based Systems, vol. 204, p. 106174, 2020. 17
2020
-
[2]
Following natural language instructions for household tasks with landmark guided search and reinforced pose adjustment,
M. Murray and M. Cakmak, “Following natural language instructions for household tasks with landmark guided search and reinforced pose adjustment,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6870–6877, 2022
2022
-
[3]
Efficient task planning for heterogeneous agvs in warehouses,
Y . Li and H. Huang, “Efficient task planning for heterogeneous agvs in warehouses,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 8, pp. 10 005–10 019, 2024
2024
-
[4]
Task assignment, scheduling, and motion planning for automated warehouses for million product workloads,
C. Leet, C. Oh, M. Lora, S. Koenig, and P. Nuzzo, “Task assignment, scheduling, and motion planning for automated warehouses for million product workloads,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 7362–7369
2023
-
[5]
Real time task planning for order picking in intelligent logistics warehousing,
S. Zhang, Q. Han, H. Zhu, H. Wang, H. Li, and K. Wang, “Real time task planning for order picking in intelligent logistics warehousing,” Scientific Reports, vol. 15, no. 1, p. 7331, 2025
2025
-
[6]
Joint or decoupled optimization: Multi-uav path planning for search and rescue,
E. Yanmaz, “Joint or decoupled optimization: Multi-uav path planning for search and rescue,”Ad Hoc Networks, vol. 138, p. 103018, 2023
2023
-
[7]
A multi-robot task assignment framework for search and rescue with heterogeneous teams,
H. Osooli, “A multi-robot task assignment framework for search and rescue with heterogeneous teams,” Master’s thesis, University of Mas- sachusetts Lowell, 2024
2024
-
[8]
Cellular-enabled collaborative robots planning and operations for search-and-rescue scenarios,
A. Romero, C. Delgado, L. Zanzi, R. Su ´arez, and X. Costa-P ´erez, “Cellular-enabled collaborative robots planning and operations for search-and-rescue scenarios,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5942–5948
2024
-
[9]
PDDL: The planning domain definition language,
D. McDermott, M. Ghallab, A. Howe, C. Knoblock, A. Ram, M. Veloso, D. Weld, and D. Wilkins, “PDDL: The planning domain definition language,” Yale Center for Computational Vision and Control, Tech. Rep. CVC TR-98-003/DCS TR-1165, 1998
1998
-
[10]
Pddl2.2: The language for the classical part of the 4th international planning competition,
S. Edelkamp and J. Hoffmann, “Pddl2.2: The language for the classical part of the 4th international planning competition,” Technical Report 195, University of Freiburg, Tech. Rep., 2004
2004
-
[11]
Strips: A new approach to the application of theorem proving to problem solving,
R. E. Fikes and N. J. Nilsson, “Strips: A new approach to the application of theorem proving to problem solving,”Artificial intelligence, vol. 2, no. 3-4, pp. 189–208, 1971
1971
-
[12]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P ´erez, “Integrated task and motion planning,”Annual review of control, robotics, and autonomous systems, vol. 4, no. 1, pp. 265–293, 2021
2021
-
[13]
The computational complexity of propositional strips planning,
T. Bylander, “The computational complexity of propositional strips planning,”Artificial Intelligence, vol. 69, no. 1-2, pp. 165–204, 1994
1994
-
[14]
The lama planner: Guiding cost-based anytime planning with landmarks,
S. Richter and M. Westphal, “The lama planner: Guiding cost-based anytime planning with landmarks,”Journal of Artificial Intelligence Research, vol. 39, pp. 127–177, 2010
2010
-
[15]
Fast task planning with neuro-symbolic relaxation,
Q. Du, B. Li, Y . Du, S. Su, T. Fu, Z. Zhan, Z. Zhao, and C. Wang, “Fast task planning with neuro-symbolic relaxation,”IEEE Robotics and Automation Letters, 2026
2026
-
[16]
Planning with learned object importance in large problem instances using graph neural networks,
T. Silver, R. Chitnis, A. Curtis, J. B. Tenenbaum, T. Lozano-P ´erez, and L. P. Kaelbling, “Planning with learned object importance in large problem instances using graph neural networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 13, 2021, pp. 11 962–11 971
2021
-
[17]
Sequence level train- ing with recurrent neural networks,
M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level train- ing with recurrent neural networks,”arXiv preprint arXiv:1511.06732, 2015
Pith/arXiv arXiv 2015
-
[18]
Imperative learning: A self-supervised neuro- symbolic learning framework for robot autonomy,
C. Wang, K. Ji, J. Geng, Z. Ren, T. Fu, F. Yang, Y . Guo, H. He, X. Chen, Z. Zhan, Q. Du, S. Su, B. Li, Y . Qiu, Y . Du, Q. Li, Y . Yang, X. Lin, and Z. Zhao, “Imperative learning: A self-supervised neuro- symbolic learning framework for robot autonomy,”International Journal of Robotics Research (IJRR), 2025
2025
-
[19]
The fast downward planning system,
M. Helmert, “The fast downward planning system,”Journal of Artificial Intelligence Research, vol. 26, pp. 191–246, 2006
2006
-
[20]
The ff planning system: Fast plan generation through heuristic search,
J. Hoffmann and B. Nebel, “The ff planning system: Fast plan generation through heuristic search,”Journal of Artificial Intelligence Research, vol. 14, pp. 253–302, 2001
2001
-
[21]
Landmarks, critical paths and abstrac- tions: what’s the difference anyway?
M. Helmert and C. Domshlak, “Landmarks, critical paths and abstrac- tions: what’s the difference anyway?” inProceedings of the International Conference on Automated Planning and Scheduling, vol. 19, 2009, pp. 162–169
2009
-
[22]
Ignoring irrelevant facts and operators in plan generation,
B. Nebel, Y . Dimopoulos, and J. Koehler, “Ignoring irrelevant facts and operators in plan generation,” inEuropean Conference on Planning. Springer, 1997, pp. 338–350
1997
-
[23]
Fast planning through planning graph analysis,
A. L. Blum and M. L. Furst, “Fast planning through planning graph analysis,”Artificial intelligence, vol. 90, no. 1-2, pp. 281–300, 1997
1997
-
[24]
Planning as satisfiability
H. A. Kautz, B. Selmanet al., “Planning as satisfiability.” inECAI, vol. 92, 1992, pp. 359–363
1992
-
[25]
Satplan: Planning as satisfia- bility,
H. Kautz, B. Selman, and J. Hoffmann, “Satplan: Planning as satisfia- bility,” in5th international planning competition, vol. 20, no. 49, 2006, p. 156
2006
-
[26]
Unifying sat-based and graph-based plan- ning,
H. Kautz and B. Selman, “Unifying sat-based and graph-based plan- ning,” inIJCAI, vol. 99, 1999, pp. 318–325
1999
-
[27]
Incremental task and motion planning: A constraint-based approach
N. T. Dantam, Z. K. Kingston, S. Chaudhuri, and L. E. Kavraki, “Incremental task and motion planning: A constraint-based approach.” inRobotics: Science and systems, vol. 12. Ann Arbor, MI, USA, 2016, p. 00052
2016
-
[28]
Shop2: An htn planning system,
D. S. Nau, T.-C. Au, O. Ilghami, U. Kuter, J. W. Murdock, D. Wu, and F. Yaman, “Shop2: An htn planning system,”Journal of artificial intelligence research, vol. 20, pp. 379–404, 2003
2003
-
[29]
Htn planning: Overview, comparison, and beyond,
I. Georgievski and M. Aiello, “Htn planning: Overview, comparison, and beyond,”Artificial Intelligence, vol. 222, pp. 124–156, 2015
2015
-
[30]
Rosplan: Planning in the robot operating system,
M. Cashmore, M. Fox, D. Long, D. Magazzeni, B. Ridder, A. Carrera, N. Palomeras, N. Hurtos, and M. Carreras, “Rosplan: Planning in the robot operating system,” inProceedings of the international conference on automated planning and scheduling, vol. 25, 2015, pp. 333–341
2015
-
[31]
Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning,
C. R. Garrett, T. Lozano-P ´erez, and L. P. Kaelbling, “Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning,” inProceedings of the international conference on automated planning and scheduling, vol. 30, 2020, pp. 440–448
2020
-
[32]
Embodied Active Learning of Relational State Abstractions for Bilevel Planning,
A. Li and T. Silver, “Embodied Active Learning of Relational State Abstractions for Bilevel Planning,” inProceedings of the Conference on Lifelong Learning Agents (CoLLAs), 2023, pp. 358–375
2023
-
[33]
Predicate invention for bilevel plan- ning,
T. Silver, R. Chitnis, N. Kumar, W. McClinton, T. Lozano-P ´erez, L. Kaelbling, and J. B. Tenenbaum, “Predicate invention for bilevel plan- ning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 10, 2023, pp. 12 120–12 129
2023
-
[34]
Bisimu- lation Makes Analogies in Goal-conditioned Reinforcement Learning,
P. Hansen-Estruch, A. Zhang, A. Nair, P. Yin, and S. Levine, “Bisimu- lation Makes Analogies in Goal-conditioned Reinforcement Learning,” inProceedings of the International Conference on Machine Learning (ICML), 2022, pp. 8407–8426
2022
-
[35]
Bilevel learning for bilevel planning,
B. Li, T. Silver, S. Scherer, and A. Gray, “Bilevel learning for bilevel planning,”arXiv preprint arXiv:2502.08697, 2025
arXiv 2025
-
[36]
Learning neuro-symbolic relational transition models for bilevel planning,
R. Chitnis, T. Silver, J. B. Tenenbaum, T. Lozano-Perez, and L. P. Kael- bling, “Learning neuro-symbolic relational transition models for bilevel planning,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 4166–4173
2022
-
[37]
Learning neuro-symbolic skills for bilevel planning,
T. Silver, A. Athalye, J. B. Tenenbaum, T. Lozano-P ´erez, and L. P. Kaelbling, “Learning neuro-symbolic skills for bilevel planning,”arXiv preprint arXiv:2206.10680, 2022
arXiv 2022
-
[38]
Practice makes perfect: Planning to learn skill parameter policies,
N. Kumar, T. Silver, W. McClinton, L. Zhao, S. Proulx, T. Lozano-P´erez, L. P. Kaelbling, and J. Barry, “Practice makes perfect: Planning to learn skill parameter policies,”arXiv preprint arXiv:2402.15025, 2024
arXiv 2024
-
[39]
From skills to symbols: Learning symbolic representations for abstract high-level planning,
G. Konidaris, L. P. Kaelbling, and T. Lozano-Perez, “From skills to symbols: Learning symbolic representations for abstract high-level planning,”Journal of Artificial Intelligence Research, vol. 61, pp. 215– 289, 2018
2018
-
[40]
SLAP: Shortcut Learning for Abstract Planning,
Y . I. Liu, B. Li, B. Eysenbach, and T. Silver, “SLAP: Shortcut Learning for Abstract Planning,”arXiv preprint arXiv:2511.01107, 2025
arXiv 2025
-
[41]
Learning efficient abstract planning models that choose what to predict,
N. Kumar, W. McClinton, R. Chitnis, T. Silver, T. Lozano-P ´erez, and L. P. Kaelbling, “Learning efficient abstract planning models that choose what to predict,” inConference on Robot Learning. PMLR, 2023, pp. 2070–2095
2023
-
[42]
Learning heuristic functions for large state spaces,
S. J. Arfaee, S. Zilles, and R. C. Holte, “Learning heuristic functions for large state spaces,”Artificial Intelligence, vol. 175, no. 16-17, pp. 2075–2098, 2011
2075
-
[43]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanctotet al., “Mastering the game of go with deep neural networks and tree search,”nature, vol. 529, no. 7587, pp. 484–489, 2016
2016
-
[44]
Learning how to ground a plan–partial grounding in classical planning,
D. Gnad, A. Torralba, M. Dom ´ınguez, C. Areces, and F. Bustos, “Learning how to ground a plan–partial grounding in classical planning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 7602–7609
2019
-
[45]
Exact combinatorial optimization with graph convolutional neural networks,
M. Gasse, D. Ch ´etelat, N. Ferroni, L. Charlin, and A. Lodi, “Exact combinatorial optimization with graph convolutional neural networks,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[46]
Graph learning for numeric planning,
D. Chen and S. Thi ´ebaux, “Graph learning for numeric planning,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 91 156– 91 183, 2024
2024
-
[47]
Optnet: Differentiable optimization as a layer in neural networks,
B. Amos and J. Z. Kolter, “Optnet: Differentiable optimization as a layer in neural networks,” inInternational conference on machine learning. PMLR, 2017, pp. 136–145
2017
-
[48]
Differentiation of blackbox combinatorial solvers,
M. V . Pogan ˇci´c, A. Paulus, V . Musil, G. Martius, and M. Rolinek, “Differentiation of blackbox combinatorial solvers,” inInternational Conference on Learning Representations, 2019
2019
-
[49]
Smart “predict, then optimize
A. N. Elmachtoub and P. Grigas, “Smart “predict, then optimize”,” Management Science, vol. 68, no. 1, pp. 9–26, 2022. 18
2022
-
[50]
ia*: Imperative learning-based a* search for path planning,
X. Chen, F. Yang, and C. Wang, “ia*: Imperative learning-based a* search for path planning,”IEEE Robotics and Automation Letters, 2025
2025
-
[51]
Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver,
P.-W. Wang, P. Donti, B. Wilder, and Z. Kolter, “Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 6545–6554
2019
-
[52]
ikap: Kinematics-aware planning with imperative learning,
Q. Li, Z. Chen, H. Zheng, H. He, Z. Zhan, S. Su, J. Geng, and C. Wang, “ikap: Kinematics-aware planning with imperative learning,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 164–10 170
2025
-
[53]
iwalker: Imperative visual planning for walking humanoid robot,
X. Lin, Y . Huang, T. Fu, X. Xiong, and C. Wang, “iwalker: Imperative visual planning for walking humanoid robot,” in2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2865–2872
2025
-
[54]
imatching: Imperative correspondence learning,
Z. Zhan, D. Gao, Y .-J. Lin, Y . Xia, and C. Wang, “imatching: Imperative correspondence learning,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 183–200
2024
-
[55]
imtsp: Solving min-max multiple traveling salesman problem with imperative learning,
Y . Guo, Z. Ren, and C. Wang, “imtsp: Solving min-max multiple traveling salesman problem with imperative learning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 10 245–10 252
2024
-
[56]
islam: Imperative slam,
T. Fu, S. Su, Y . Lu, and C. Wang, “islam: Imperative slam,”IEEE Robotics and Automation Letters, vol. 9, no. 5, pp. 4607–4614, 2024
2024
-
[57]
iplanner: Imperative path planning,
F. Yang, C. Wang, C. Cadena, and M. Hutter, “iplanner: Imperative path planning,”arXiv preprint arXiv:2302.11434, 2023
arXiv 2023
-
[58]
Resilient odometry via hierarchical adaptation,
S. Zhao, S. Zhou, Y . Zhang, J. Zhang, C. Wang, W. Wang, and S. Scherer, “Resilient odometry via hierarchical adaptation,”Science Robotics, vol. 10, no. 109, p. eadv1818, 2025
2025
-
[59]
Plan stability: Replanning versus plan repair
M. Fox, A. Gerevini, D. Long, I. Serinaet al., “Plan stability: Replanning versus plan repair.” inICAPS, vol. 6, 2006, pp. 212–221
2006
-
[60]
Plan repair as an extension of planning
R. Van Der Krogt and M. De Weerdt, “Plan repair as an extension of planning.” inICAPS, vol. 5, 2005, pp. 161–170
2005
-
[61]
Portfolio-based planning: State of the art, common practice and open challenges,
M. Vallati, L. Chrpa, and D. Kitchin, “Portfolio-based planning: State of the art, common practice and open challenges,”AI Communications, vol. 28, no. 4, pp. 717–733, 2015
2015
-
[62]
Fast downward stone soup: A baseline for building planner portfolios,
M. Helmert, G. R ¨oger, and E. Karpas, “Fast downward stone soup: A baseline for building planner portfolios,” inICAPS 2011 Workshop on Planning and Learning, vol. 2835, no. 8, 2011
2011
-
[63]
Arvandherd: Parallel planning with a portfolio,
R. Valenzano, H. Nakhost, M. M ¨uller, J. Schaeffer, and N. Sturtevant, “Arvandherd: Parallel planning with a portfolio,” inECAI 2012. IOS Press, 2012, pp. 786–791
2012
-
[64]
Type-based exploration with multiple search queues for satisficing planning,
F. Xie, M. M ¨uller, R. Holte, and T. Imai, “Type-based exploration with multiple search queues for satisficing planning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 28, no. 1, 2014
2014
-
[65]
Relational inductive biases, deep learning, and graph networks,
P. W. Battaglia, J. B. Hamrick, V . Bapst, A. Sanchez-Gonzalez, V . Zam- baldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner et al., “Relational inductive biases, deep learning, and graph networks,” arXiv preprint arXiv:1806.01261, 2018
Pith/arXiv arXiv 2018
-
[66]
Landmarks revisited
S. Richter, M. Helmert, and M. Westphal, “Landmarks revisited.” in AAAI, vol. 8, 2008, pp. 975–982
2008
-
[67]
The 1998 ai planning systems competition,
D. M. McDermott, “The 1998 ai planning systems competition,”AI magazine, vol. 21, no. 2, pp. 35–35, 2000
1998
-
[68]
Sokoban variants,
J. Schiøtt, “Sokoban variants,” https://sokoban.dk/sokoban-variants/, 2016, accessed: 2025-11-29
2016
-
[69]
Sokoban is pspace-complete,
J. Culberson, “Sokoban is pspace-complete,” 1997
1997
-
[70]
Isaac Sim
NVIDIA, “Isaac Sim.” [Online]. Available: https://github.com/isaac-sim/ IsaacSim
-
[71]
How behavior trees modularize hybrid control systems and generalize sequential behavior compositions, the subsumption architecture, and decision trees,
M. Colledanchise and P. ¨Ogren, “How behavior trees modularize hybrid control systems and generalize sequential behavior compositions, the subsumption architecture, and decision trees,”IEEE Transactions on robotics, vol. 33, no. 2, pp. 372–389, 2016
2016
-
[72]
Openxrlab visual-inertial slam toolbox and bench- mark,
X. Contributors, “Openxrlab visual-inertial slam toolbox and bench- mark,” https://github.com/openxrlab/xrslam, 2022
2022
-
[73]
Rd-vio: Robust visual-inertial odometry for mobile augmented reality in dynamic environments,
J. Li, X. Pan, G. Huang, Z. Zhang, N. Wang, H. Bao, and G. Zhang, “Rd-vio: Robust visual-inertial odometry for mobile augmented reality in dynamic environments,”IEEE transactions on visualization and computer graphics, vol. 30, no. 10, pp. 6941–6955, 2024
2024
-
[74]
Hydra: A real-time spatial perception system for 3D scene graph construction and optimization,
N. Hughes, Y . Chang, and L. Carlone, “Hydra: A real-time spatial perception system for 3D scene graph construction and optimization,” inRobotics: Science and Systems (RSS), 2022
2022
-
[75]
Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone, “Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,”The International Journal of Robotics Research, 2024
2024
-
[76]
Pypose: A library for robot learning with physics-based optimization,
C. Wang, D. Gao, K. Xu, J. Geng, Y . Hu, Y . Qiu, B. Li, F. Yang, B. Moon, A. Pandeyet al., “Pypose: A library for robot learning with physics-based optimization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 024–22 034
2023
-
[77]
Wilddet3d: Scaling promptable 3d detection in the wild,
W. Huang, J. Zhang, S. Li, T. Jia, J. Duan, Y . Cheng, J. Cho, M. Walling- ford, R. Soraki, C. D. Kimet al., “Wilddet3d: Scaling promptable 3d detection in the wild,”arXiv preprint arXiv:2604.08626, 2026
Pith/arXiv arXiv 2026
-
[78]
Reducing the barrier to entry of complex robotic software: a moveit! case study,
D. Coleman, I. Sucan, S. Chitta, and N. Correll, “Reducing the barrier to entry of complex robotic software: a moveit! case study,”Journal of Software Engineering for Robotics, vol. 5, no. 1, pp. 3–16, 2014
2014
-
[79]
Kdl: Kinematics and dynamics library,
R. Smitset al., “Kdl: Kinematics and dynamics library,” http://www. orocos.org/kdl, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.