TALAN: Task-Aligned Latent Adaptation Networks for Targeted Post-Training of Large Language Models
Pith reviewed 2026-06-27 22:16 UTC · model grok-4.3
The pith
TALAN inserts a co-trained latent side path that raises LoRA and DoRA performance on math and code by 1.4-1.85 points on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
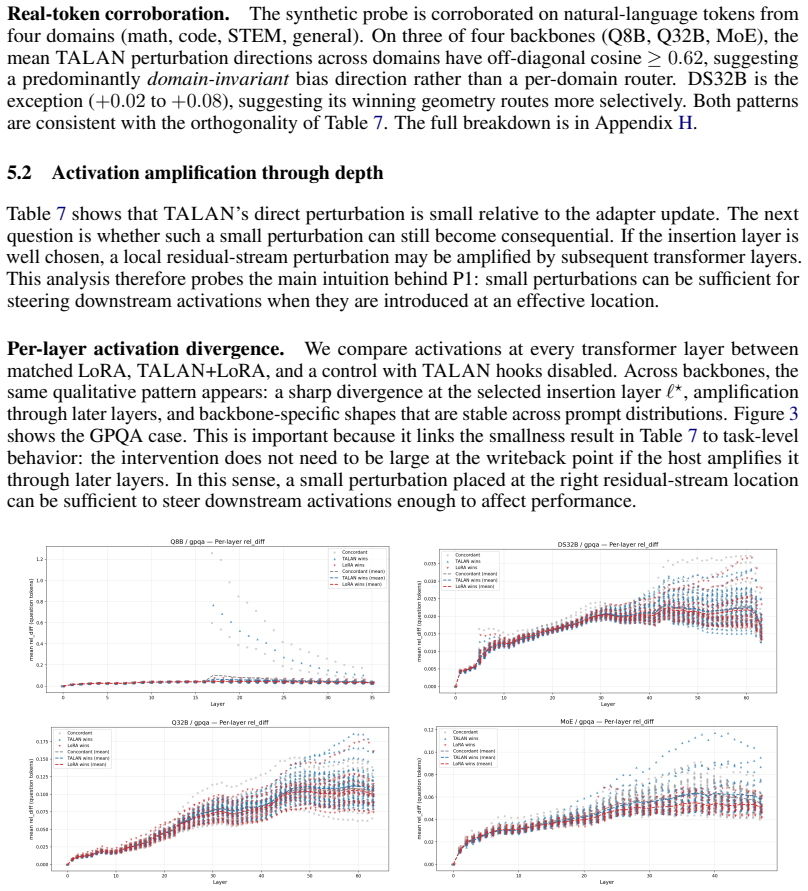
TALAN yields a +1.41 point cross-model mean gain with LoRA and +1.85 with DoRA; the gains are positive on all four backbones and non-negative on all sixteen model-benchmark cells under LoRA. Internal measurements show the TALAN perturbation is 80-1,700 times smaller than the matched adapter update yet nearly orthogonal to it in direction, and the perturbation propagates and amplifies through network depth. The same pattern appears in a Llama-3.2-1B transfer probe under two adapter variants.
What carries the argument
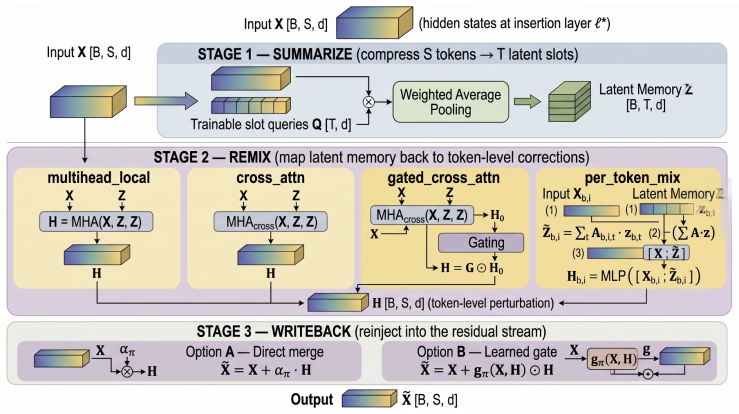
Sequence-conditioned latent side path that compresses the active sequence into latent memory, remixes it into token-level perturbations, and applies them via controlled residual update while co-trained with a low-rank adapter.
If this is right
- The adapter update and the TALAN perturbation remain nearly orthogonal in direction even though the adapter update is orders of magnitude larger.
- The small TALAN perturbation still propagates and amplifies through successive layers.
- The improvement pattern transfers at least to a Llama-3.2-1B model under both LoRA and rsLoRA.
- Inference overhead stays between 1.01x and 1.02x relative to the matched adapter baseline.
Where Pith is reading between the lines
- The same latent-side-path construction could be attached to other adapter families or to full-parameter fine-tuning without changing the core training loop.
- Because the perturbation remains small and orthogonal, TALAN may serve as a diagnostic tool for measuring how activation-level changes interact with weight-level updates.
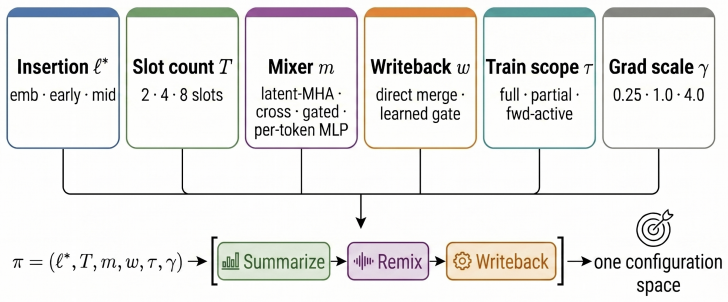
- The six-axis configuration space offers a controlled testbed for studying which insertion points and write-back rules most affect downstream reasoning tasks.
Load-bearing premise
The measured gains are produced by the TALAN mechanism itself rather than by chance variation across training seeds or by the particular choices among the six configuration axes.
What would settle it
A set of twenty or more paired training runs across the same backbones and benchmarks in which the average TALAN advantage falls to zero or reverses.
Figures

read the original abstract
Targeted post-training aims to improve reasoning, math, and code without degrading strengths. Low-rank adapters are efficient but task-global; activation interventions are input-aware but often require separate probes, vectors, or inference-time steering. We introduce TALAN (Task-Aligned Latent Adaptation Networks), a sequence-conditioned latent side path inserted into a transformer's residual stream and co-trained with a low-rank adapter in one SFT loop. TALAN compresses the active sequence into latent memory, remixes it into token-level perturbations, and writes them back through a controlled residual update. It is configured along six axes: insertion location, memory size, mixer, writeback rule, trainability scope, and gradient scale. Across four Qwen3-family backbones and four STEM/code benchmarks, TALAN improves matched LoRA and DoRA baselines. With LoRA, it yields a +1.41 point cross-model mean gain, positive on all four backbones and non-negative on all 16 model-benchmark cells. With DoRA, it yields a +1.85 point mean gain, positive on all backbones and on 13 of 16 cells. Paired seed checks support positive average effects but show nontrivial variance, so we treat them as sensitivity checks. Cost is small: <1% trainable parameters relative to the backbone and 1.01-1.02x inference overhead versus matched LoRA. A Llama-3.2-1B transfer probe is also positive under LoRA and rsLoRA across seven paired seeds, supporting a transfer beyond Qwen. Internal-state analyses suggest TALAN is a small complementary activation intervention. The matched adapter update is 80-1,700x larger than the TALAN perturbation, yet their directions have near-zero cosine; per-layer measurements show this small orthogonal perturbation propagates and amplifies through depth. TALAN offers a practical platform for studying steerable activation-level adaptation within standard adapter-based post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TALAN, a sequence-conditioned latent side path inserted into a transformer's residual stream and co-trained with a low-rank adapter (LoRA or DoRA) in a single SFT loop. It is configured along six axes (insertion location, memory size, mixer, writeback rule, trainability scope, gradient scale) and claims to deliver targeted post-training gains on reasoning/math/code tasks. Across four Qwen3 backbones and four STEM/code benchmarks, TALAN reports a +1.41 mean gain over matched LoRA (positive on all 4 backbones, non-negative on all 16 cells) and +1.85 over DoRA (positive on all backbones, non-negative on 13/16 cells), with <1% extra parameters and 1.01-1.02x inference cost. Internal analyses indicate the TALAN perturbation is small, orthogonal to the adapter update (near-zero cosine), yet propagates through depth. A Llama-3.2-1B transfer probe is also reported positive.
Significance. If the reported gains prove robust to seed variance and statistical testing, TALAN would provide a lightweight, co-trainable mechanism for adding input-aware activation-level steering inside standard adapter pipelines, with potential value for studying complementary adaptation directions in post-training.
major comments (3)
- [Abstract] Abstract: The central claim of non-negative deltas on all 16 (LoRA) and 13/16 (DoRA) model-benchmark cells is not supported by the provided evidence. The abstract itself states that paired seed checks exhibit nontrivial variance and are treated only as sensitivity checks; no standard deviations, number of seeds per cell, confidence intervals, or statistical tests are reported, so it is impossible to assess whether the mean gains of +1.41 / +1.85 are distinguishable from zero once variance is accounted for.
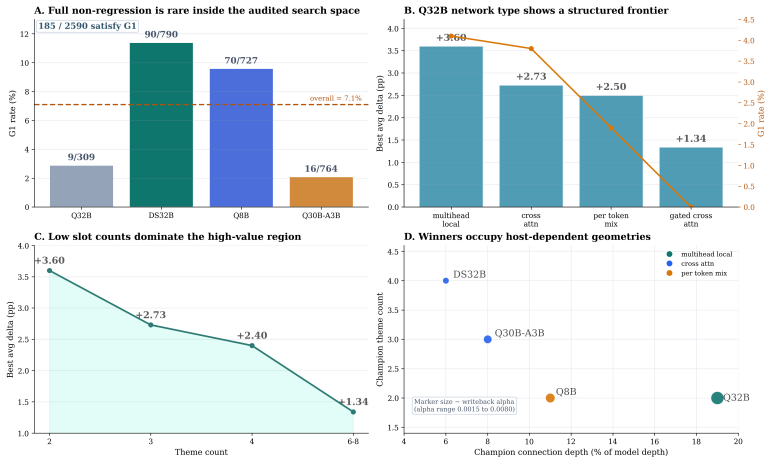
- [Abstract] Abstract and experimental protocol: The six configuration axes (insertion location, memory size, mixer, writeback rule, trainability scope, gradient scale) are introduced without an ablation isolating which axes drive the gains versus which are incidental; the reported improvements could therefore be attributable to the particular hyperparameter choices rather than the TALAN mechanism itself.
- [Abstract] Internal-state analyses: The claims that the matched adapter update is 80-1,700x larger than the TALAN perturbation yet their directions have near-zero cosine, and that the perturbation propagates and amplifies through depth, lack sufficient methodological detail (e.g., exact layers measured, cosine computation, propagation metric) to evaluate whether the orthogonality is load-bearing for the performance gains.
minor comments (2)
- [Abstract] The abstract states 'positive on all four backbones and non-negative on all 16 model-benchmark cells' for LoRA but does not define the exact benchmarks or models, making it difficult to interpret the scope of the result.
- [Abstract] The Llama-3.2-1B transfer probe is mentioned as positive under LoRA and rsLoRA across seven paired seeds, but no quantitative deltas or comparison to the Qwen3 results are supplied.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the points raised identify areas where the manuscript can be strengthened through additional reporting and experiments. We address each major comment below and will incorporate the suggested changes in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of non-negative deltas on all 16 (LoRA) and 13/16 (DoRA) model-benchmark cells is not supported by the provided evidence. The abstract itself states that paired seed checks exhibit nontrivial variance and are treated only as sensitivity checks; no standard deviations, number of seeds per cell, confidence intervals, or statistical tests are reported, so it is impossible to assess whether the mean gains of +1.41 / +1.85 are distinguishable from zero once variance is accounted for.
Authors: We acknowledge that the abstract's phrasing of non-negative deltas across all cells relies on observed means without full statistical apparatus. The paired seed checks were explicitly described as sensitivity checks due to the noted variance. In revision we will (i) report the exact number of seeds per cell, (ii) include standard deviations for the reported means where computed, and (iii) rephrase the abstract and results to present the gains as observed average improvements accompanied by the sensitivity analysis rather than as statistically tested effects. revision: yes
-
Referee: [Abstract] Abstract and experimental protocol: The six configuration axes (insertion location, memory size, mixer, writeback rule, trainability scope, gradient scale) are introduced without an ablation isolating which axes drive the gains versus which are incidental; the reported improvements could therefore be attributable to the particular hyperparameter choices rather than the TALAN mechanism itself.
Authors: The six axes constitute the design space explored during development. The submitted results reflect a single well-performing configuration rather than an exhaustive search. Because full factorial ablations on four backbones would be computationally prohibitive, we omitted them from the initial submission. In the revision we will add a targeted ablation on a smaller backbone (Qwen3-0.5B) that isolates the contribution of the two most salient axes—insertion location and memory size—while holding the remaining axes fixed at the values used in the main experiments. revision: yes
-
Referee: [Abstract] Internal-state analyses: The claims that the matched adapter update is 80-1,700x larger than the TALAN perturbation yet their directions have near-zero cosine, and that the perturbation propagates and amplifies through depth, lack sufficient methodological detail (e.g., exact layers measured, cosine computation, propagation metric) to evaluate whether the orthogonality is load-bearing for the performance gains.
Authors: We agree that the internal analyses section lacks the precise implementation details needed for evaluation. In the revised manuscript we will expand the relevant subsection to specify: the exact transformer layers at which measurements were taken, the precise formula and normalization used for the cosine-similarity computation between adapter and TALAN updates, and the definition of the propagation/amplification metric (including how per-layer norms were aggregated across depth). revision: yes
Circularity Check
No circularity: empirical method proposal with direct benchmark comparisons
full rationale
The paper introduces TALAN as a new adapter architecture configured along six explicit axes and evaluates it via standard SFT training and held-out benchmark comparisons against matched LoRA/DoRA baselines. No equations, derivations, or first-principles predictions are present that reduce to fitted parameters or self-definitions. All reported gains (+1.41 / +1.85 mean) are direct empirical deltas; internal-state analyses are post-hoc measurements, not load-bearing for the central claim. Self-citations are absent from the provided text. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
free parameters (2)
- memory size
- gradient scale
invented entities (1)
-
latent memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DELIFT: Data efficient language model instruction fine-tuning
Ishika Agarwal, Krishnateja Killamsetty, Lucian Popa, and Marina Danilevsky. DELIFT: Data efficient language model instruction fine-tuning. InInternational Conference on Learning Representations, 2025. URLhttps://iclr.cc/virtual/2025/poster/30319
2025
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Mariber Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkows...
2022
-
[3]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[4]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 11
Pith/arXiv arXiv 2021
-
[5]
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. URL https://arxiv.org/abs/2501. 12948
Pith/arXiv arXiv 2025
-
[7]
URLhttps://arxiv.org/abs/2601.19847
-
[8]
To- wards a unified view of parameter-efficient transfer learning
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. To- wards a unified view of parameter-efficient transfer learning. InInternational Conference on Learning Representations, 2022
2022
-
[9]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[10]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InProceedings of the 36th International Conference on Machine Learning, 2019
2019
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[12]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InProceedings of the 38th International Conference on Machine Learning, 2021
2021
-
[13]
Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M. Asano. VeRA: Vector-based random matrix adaptation.International Conference on Learning Representations, 2024
2024
-
[14]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021
2021
-
[15]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, 2021
2021
-
[16]
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. InAdvances in Neural Information Processing Systems, 2022
2022
-
[17]
DoRA: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024
Pith/arXiv arXiv 2024
-
[18]
AdapterFusion: Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. AdapterFusion: Non-destructive task composition for transfer learning. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021
2021
-
[19]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URL https: //arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[20]
GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2023
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, Samuel Bowman, and Ethan Perez. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2023
Pith/arXiv arXiv 2023
-
[21]
Sainbayar Sukhbaatar, Olga Golovneva, Vasu Sharma, Hu Xu, Xi Victoria Lin, Baptiste Roziere, Jacob Kahn, Daniel Li, Wen-tau Yih, Jason Weston, and Xian Li. Branch-train-MiX: Mixing expert LLMs into a mixture-of-experts LLM.arXiv preprint arXiv:2403.07816, 2024. URL https://arxiv.org/abs/2403.07816. 12
arXiv 2024
-
[22]
Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J
Alexander M. Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
Pith/arXiv arXiv 2023
-
[23]
Xintong Wang, Jingheng Pan, Liang Ding, Longyue Wang, Longqin Jiang, Xingshan Li, and Chris Biemann. CogSteer: Cognition-inspired selective layer intervention for efficiently steering large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 25507–25522, 2025. doi: 10.18653/v1/2025.findings-acl.1308. URL https: //...
-
[25]
URLhttps://arxiv.org/abs/2503.24370
-
[26]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. ReFT: Representation finetuning for language models.arXiv preprint arXiv:2404.03592, 2024
arXiv 2024
-
[27]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to A...
Pith/arXiv arXiv 2023
-
[28]
For Q32B the lift is at layer 12, for Q8B at layer 4, for DS32B and MoE at the embedding (layer 0)
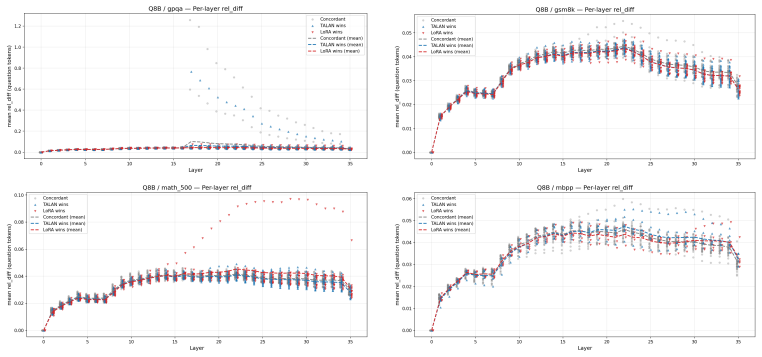
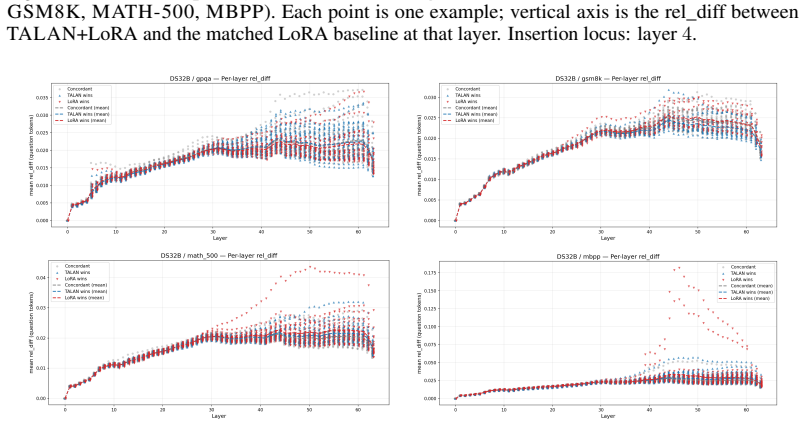
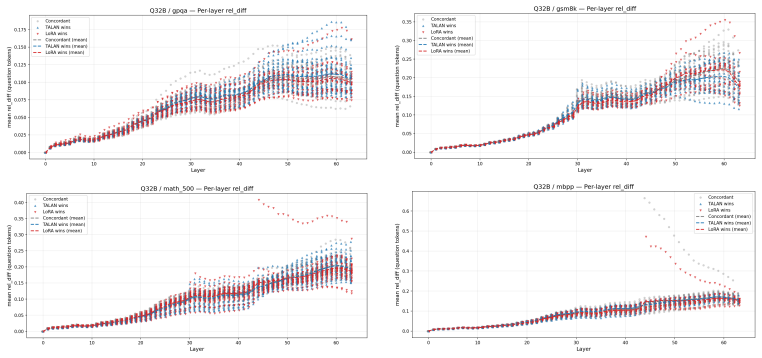
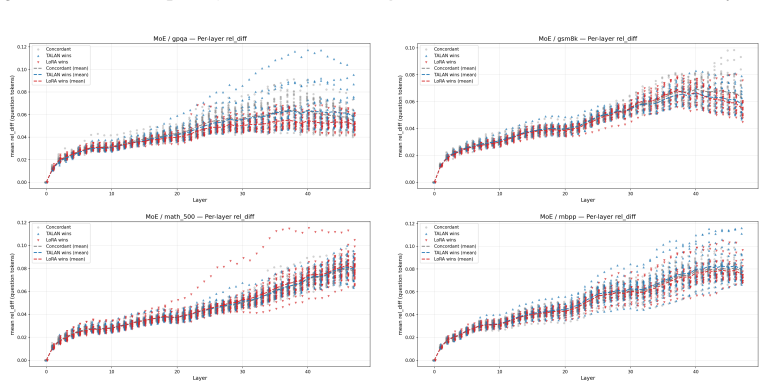
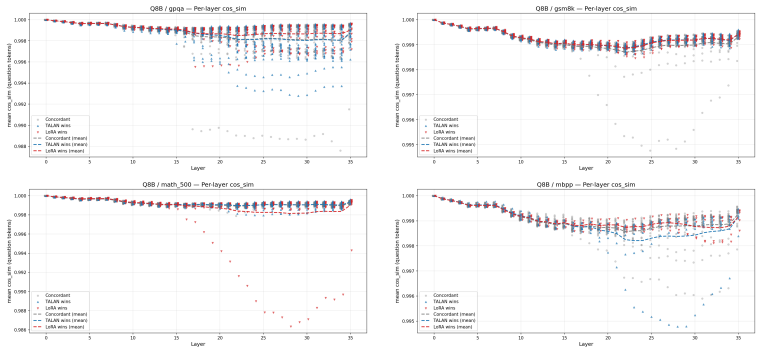
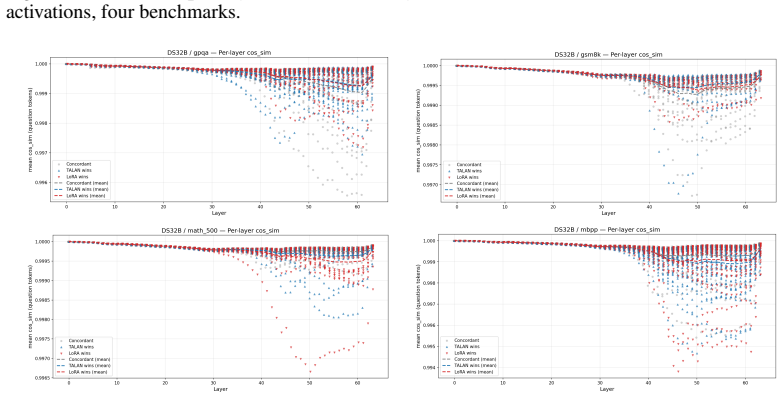
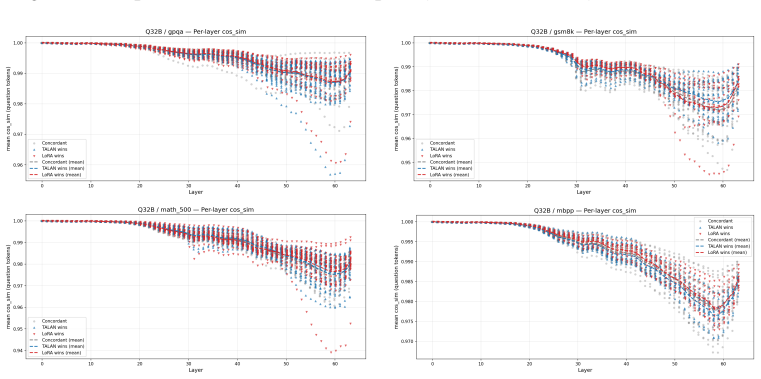
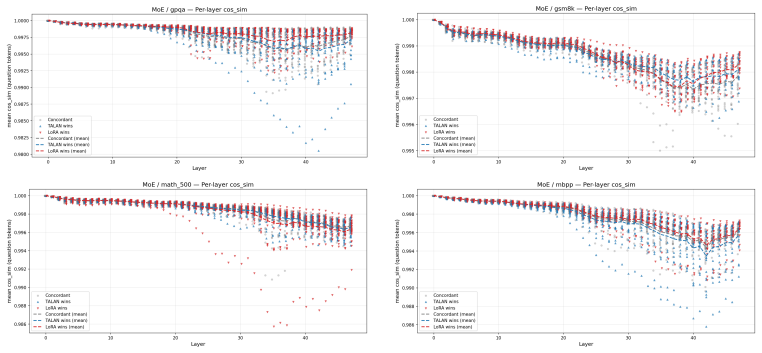
Insertion-layer step.The TALAN module’s insertion locus is visible as the layer at which the rel_diff curve first lifts off zero. For Q32B the lift is at layer 12, for Q8B at layer 4, for DS32B and MoE at the embedding (layer 0). This confirms that the configured insertion point is the actual source of the divergence
-
[29]
Persistence (not absorption).The rel_diff grows monotonically through the network rather than being absorbed or decaying. This is a necessary condition for a small insertion-layer perturbation to affect downstream outputs; it is expected in deep residual networks but not guaranteed—a perturbation orthogonal to the directions that subsequent layers amplify...
-
[30]
saved is indistinguishable from a fresh draw
Cross-benchmark stability (the main finding).The shape of the per-layer divergence curve is essentially identical across the four benchmarks for each backbone. The representation shift TA- LAN induces is a property of the model variant, not of the prompt distribution. This distinguishes the TALAN intervention from prompt-dependent noise: a random or data-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.