Accelerating Reproducible Research in Synthetic EHR Generation
Pith reviewed 2026-06-27 22:36 UTC · model grok-4.3
The pith
A unified pipeline standardizes data handling, training and evaluation for synthetic EHR generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a lightweight, end-to-end benchmarking framework for reproducible synthetic EHR evaluation, organized as a unified pipeline spanning data ingestion, standardized model training, and architecture-agnostic evaluation. Our current implementation targets the generation of longitudinal ICD diagnosis codes and is built on the community-maintained PyHealth library. We reimplement and unify strong baselines (MedGAN, CorGAN, PromptEHR, HALO) under full ICD-9 vocabulary granularity, and add a lightweight GPT-2 baseline. We contribute a rigorous, architecture-agnostic privacy-utility evaluation suite that applies identically to GAN- and transformer-based generators, and report bootstrapped
What carries the argument
The unified pipeline that standardizes data ingestion, model training, and architecture-agnostic privacy-utility evaluation.
If this is right
- Head-to-head comparisons become possible between GAN-based and transformer-based generators using identical metrics and confidence intervals.
- Long-tailed performance shortfalls on rare diagnosis codes can be measured consistently across models.
- The engineering effort to add and test a new generator drops because data loading and evaluation are already standardized.
- Bootstrapped intervals provide a uniform way to judge whether one model outperforms another on privacy or utility.
- The same pipeline can be extended to modalities beyond diagnosis codes without rewriting evaluation code.
Where Pith is reading between the lines
- The framework could become a shared testbed that lets the community track progress on synthetic EHR generation the way image or language benchmarks do.
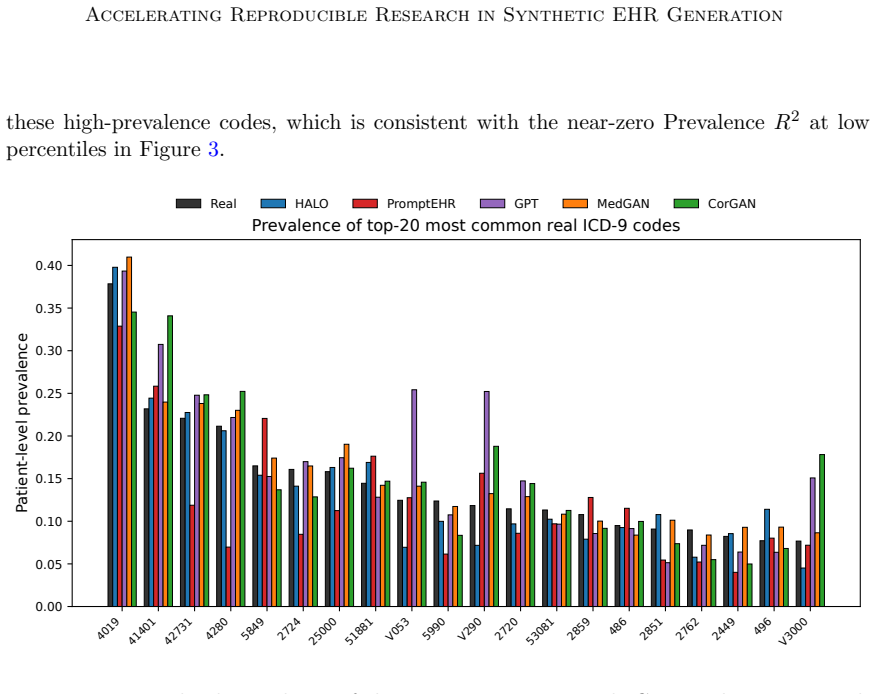
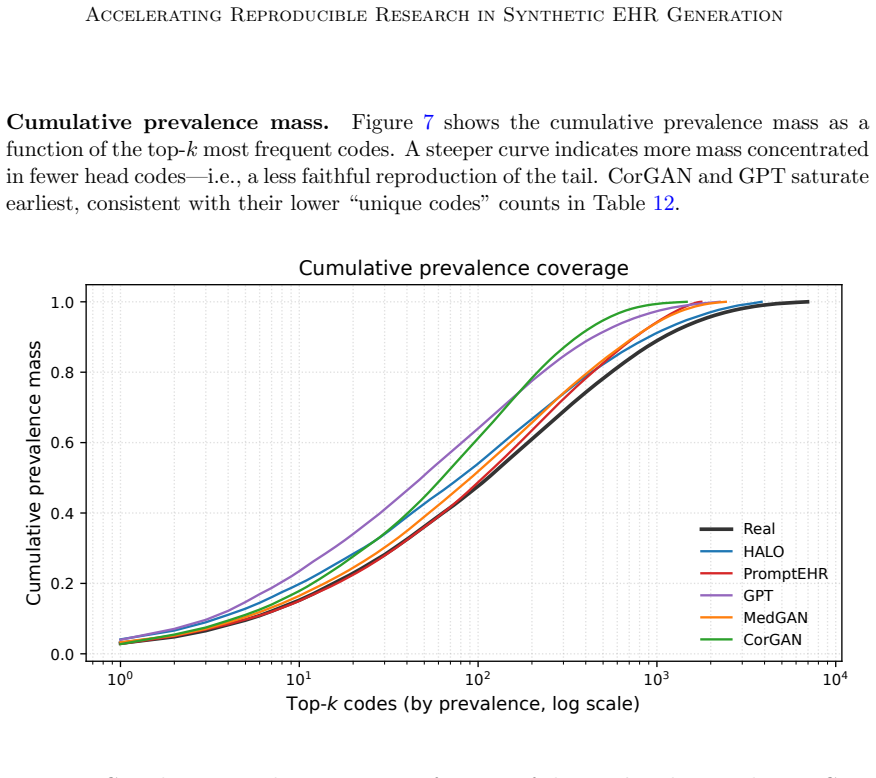
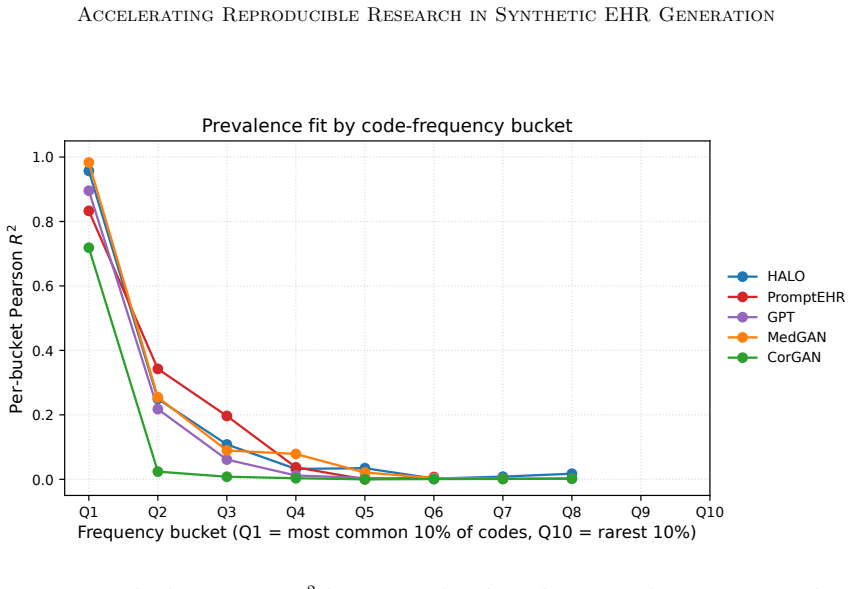
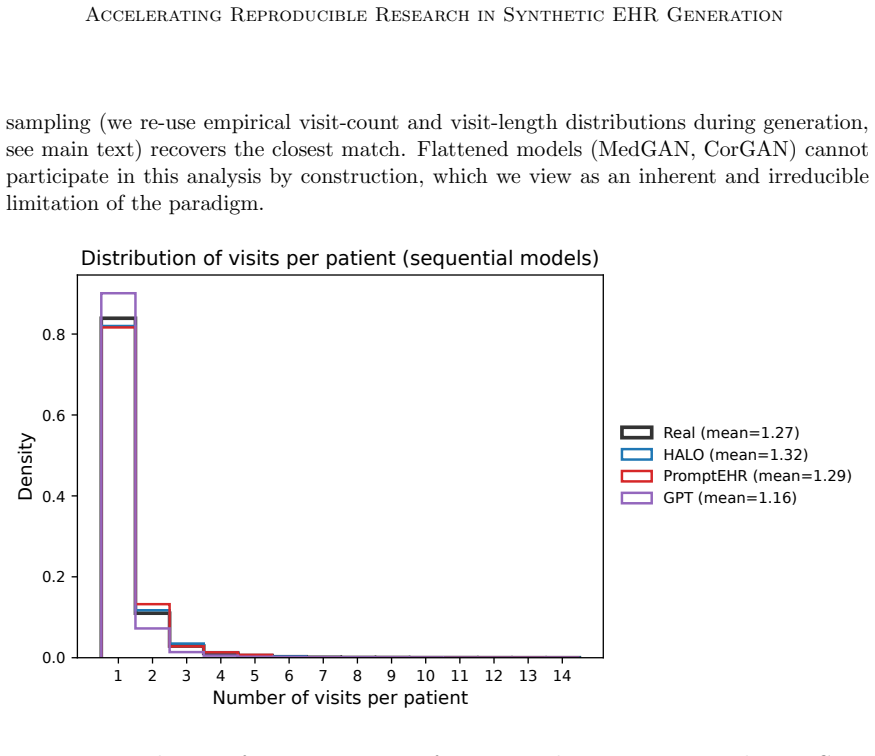
- If rare-code performance remains weak under this standardized setup, it points to a deeper limitation in current sequence generators rather than implementation differences.
- Applying the pipeline to data from multiple hospitals could expose whether models overfit to the training site's coding patterns.
- A GPT-2 baseline succeeding here would suggest that general-purpose language models warrant more attention as starting points for medical sequence generation.
Load-bearing premise
The reimplementations of MedGAN, CorGAN, PromptEHR, and HALO under full ICD-9 granularity faithfully reproduce the behavior of the original published models.
What would settle it
Running the original published code for any of the reimplemented baselines on the same dataset and obtaining substantially different metric values from those produced inside the unified framework.
Figures
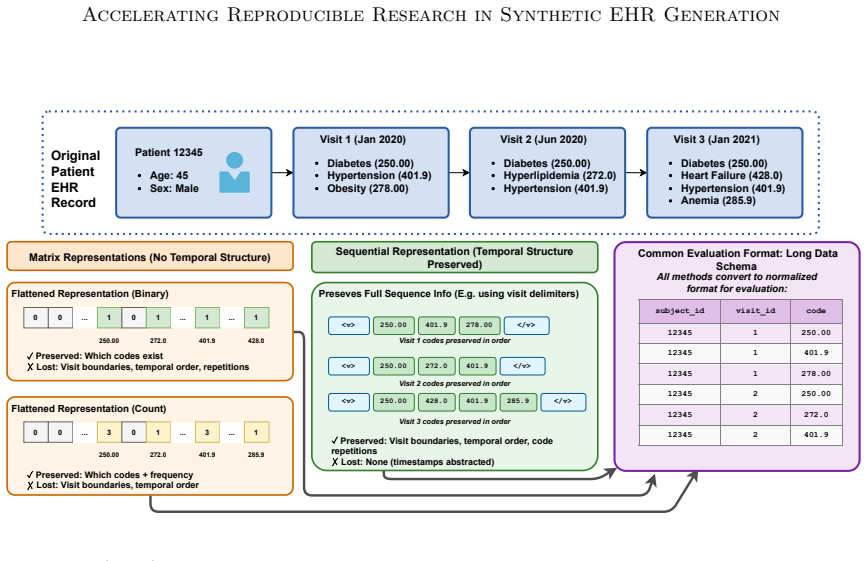
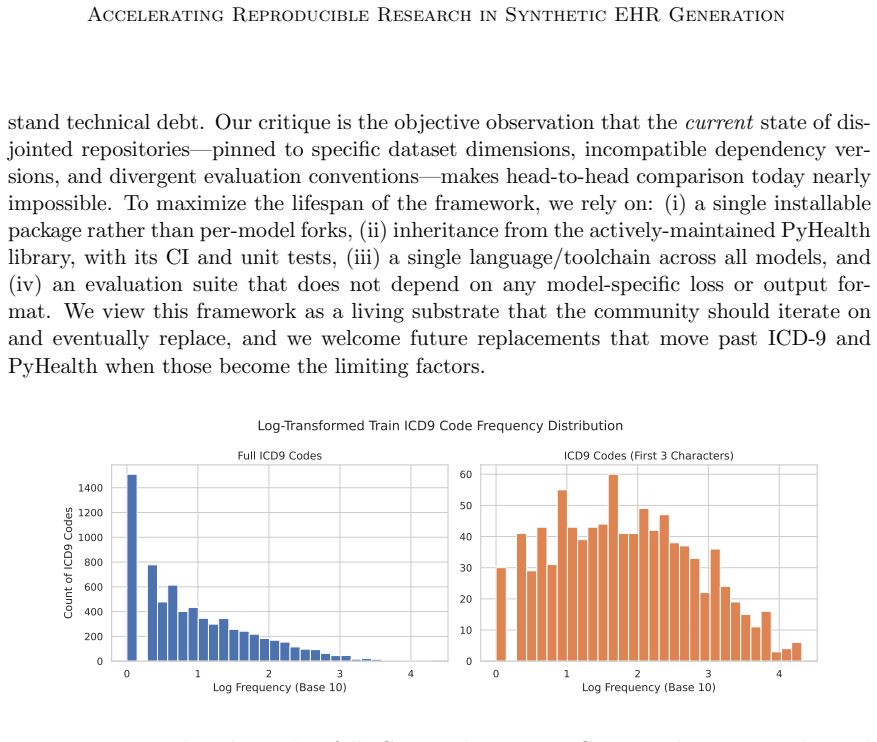
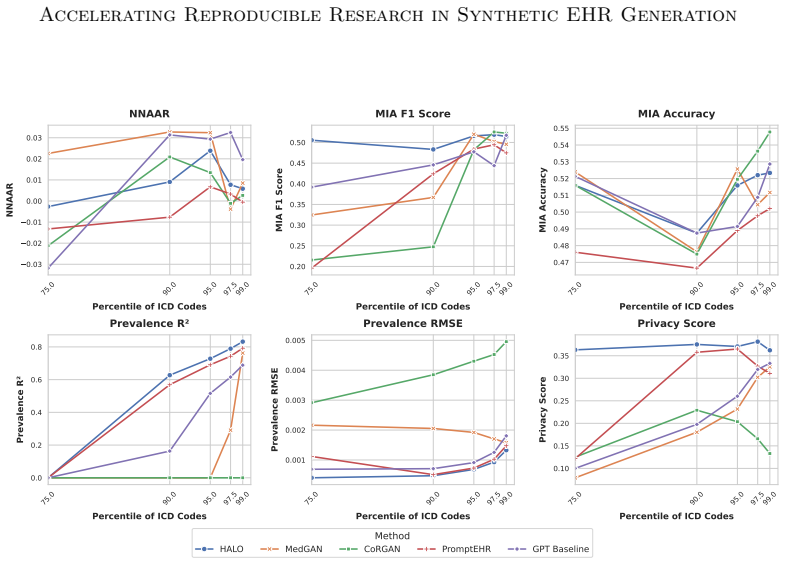
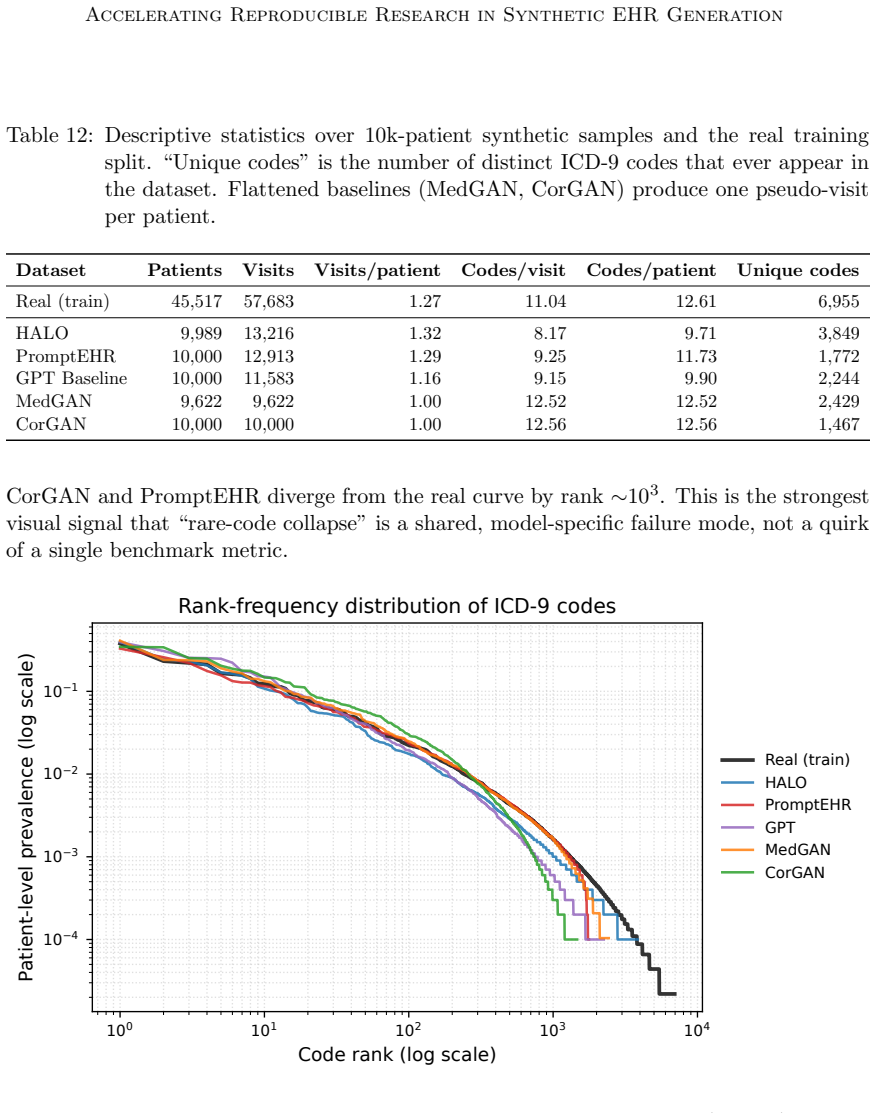

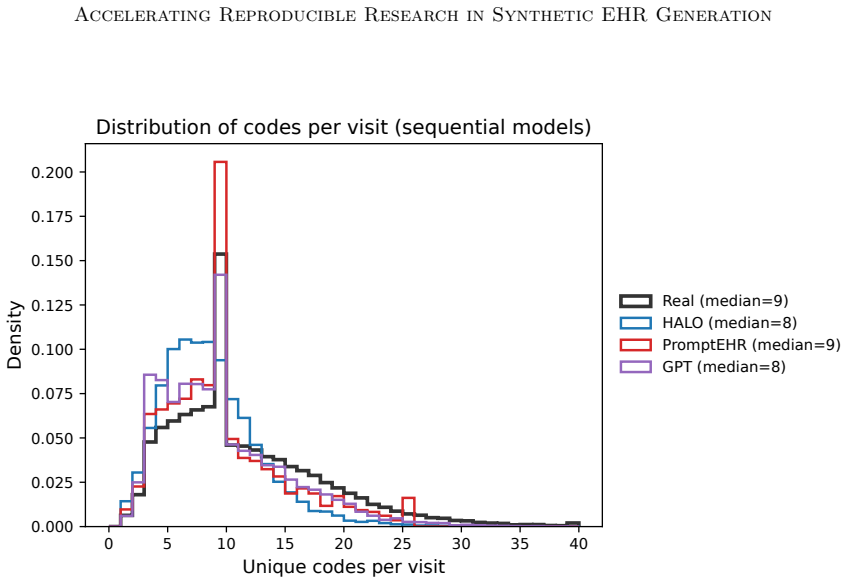
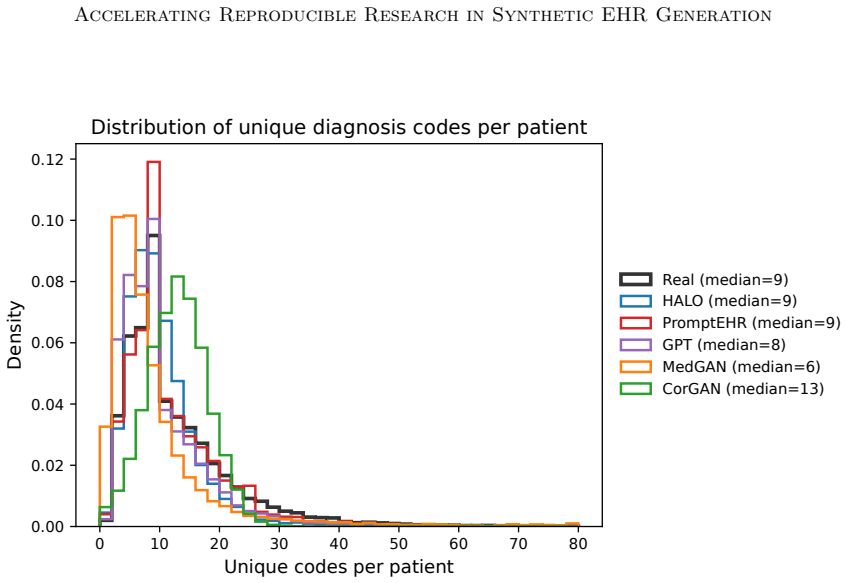
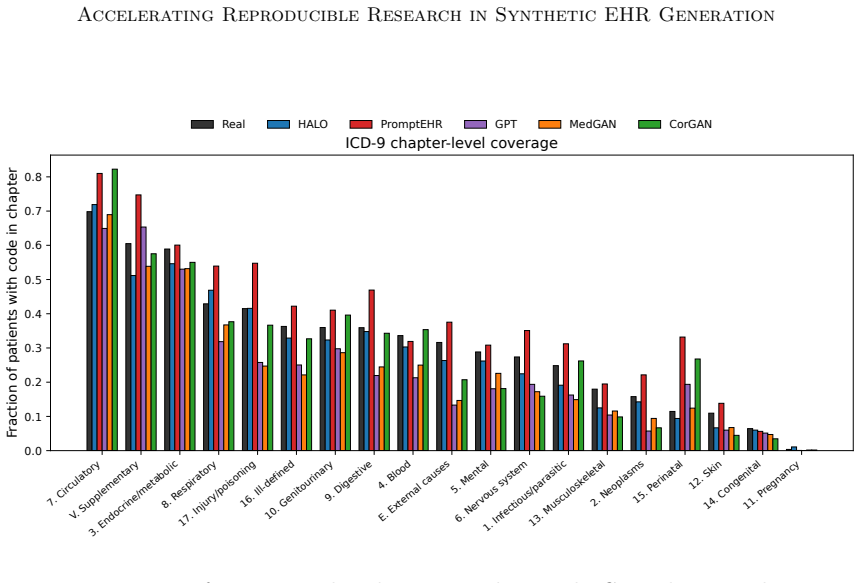
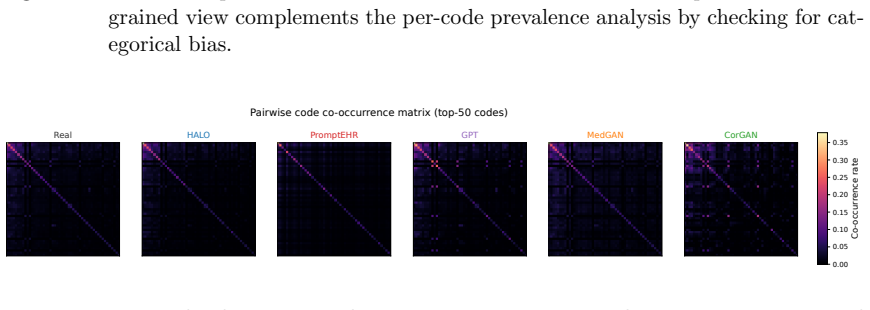
read the original abstract
The generation of high-fidelity synthetic Electronic Health Records (EHR) is crucial for advancing medical research while preserving patient privacy. However, head-to-head comparison of existing generative models is hindered by disjointed codebases, incompatible data loaders, conflicting library dependencies, and inconsistent evaluation protocols. To address these gaps, we introduce a lightweight, end-to-end benchmarking framework for reproducible synthetic EHR evaluation, organized as a unified pipeline spanning data ingestion, standardized model training, and architecture-agnostic evaluation. Our current implementation targets the generation of longitudinal ICD diagnosis codes -- the most commonly studied modality in this literature -- and is built on the community-maintained PyHealth library. We reimplement and unify strong baselines (MedGAN, CorGAN, PromptEHR, HALO) under full ICD-9 vocabulary granularity, and add a lightweight GPT-2 baseline from the general-purpose sequence-modeling literature. We contribute a rigorous, architecture-agnostic privacy-utility evaluation suite that applies identically to GAN- and transformer-based generators, and report bootstrapped confidence intervals across all metrics. We further analyze the poor long-tailed performance of existing models and discuss the extensibility of our framework beyond diagnosis codes. By lowering the engineering barrier to running, extending, and evaluating under a single pipeline, we introduce a starting point for community-driven reproducibility and benchmarking synthetic EHR models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a lightweight end-to-end benchmarking framework for reproducible synthetic EHR evaluation. The framework unifies data ingestion, standardized training of generative models (reimplementations of MedGAN, CorGAN, PromptEHR, HALO at full ICD-9 granularity, plus a GPT-2 baseline), and an architecture-agnostic evaluation suite for privacy and utility metrics with bootstrapped confidence intervals. It is built on PyHealth and targets longitudinal ICD diagnosis codes, while analyzing long-tailed performance and discussing extensibility.
Significance. If the reimplementations are faithful and the framework sees community adoption, the work could meaningfully lower the engineering barrier to reproducible benchmarking in synthetic EHR generation. The architecture-agnostic evaluation protocol and use of bootstrapped CIs represent concrete strengths that would support fairer cross-model comparisons if validated.
major comments (2)
- [Reimplementation of baselines] The central claim of a meaningful unified benchmarking pipeline rests on the assumption that the reimplementations of MedGAN, CorGAN, PromptEHR, and HALO at full ICD-9 granularity faithfully recover the original models' behavior. The manuscript supplies no side-by-side metric tables or numerical comparisons against the performance numbers reported in the source papers for these models. This verification step is load-bearing; without it, observed differences in the new evaluation suite cannot be attributed to model properties rather than implementation drift or vocabulary changes.
- [Evaluation and results] The abstract states that bootstrapped confidence intervals are reported across all metrics and that the poor long-tailed performance of existing models is analyzed, yet the manuscript text contains no tables, figures, or numerical results demonstrating these outputs. This absence leaves the evaluation suite without direct evidence of its operation or findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the manuscript's scope while committing to revisions that strengthen the presentation of results and verification.
read point-by-point responses
-
Referee: [Reimplementation of baselines] The central claim of a meaningful unified benchmarking pipeline rests on the assumption that the reimplementations of MedGAN, CorGAN, PromptEHR, and HALO at full ICD-9 granularity faithfully recover the original models' behavior. The manuscript supplies no side-by-side metric tables or numerical comparisons against the performance numbers reported in the source papers for these models. This verification step is load-bearing; without it, observed differences in the new evaluation suite cannot be attributed to model properties rather than implementation drift or vocabulary changes.
Authors: We agree that explicit verification would strengthen confidence in the reimplementations. The originals often employ different preprocessing pipelines, vocabulary granularities, and train/test splits, which complicates direct numerical matching. Our primary contribution is the unified pipeline under consistent conditions rather than exact replication of prior numbers. In revision we will add a supplementary table with available side-by-side metrics from our reimplementations versus the source papers (where setups permit), together with a discussion of any discrepancies and a pointer to the open-source code for independent inspection. revision: yes
-
Referee: [Evaluation and results] The abstract states that bootstrapped confidence intervals are reported across all metrics and that the poor long-tailed performance of existing models is analyzed, yet the manuscript text contains no tables, figures, or numerical results demonstrating these outputs. This absence leaves the evaluation suite without direct evidence of its operation or findings.
Authors: We acknowledge the referee's observation. The current manuscript version emphasizes the framework design and leaves the concrete numerical demonstration of the evaluation suite implicit. In the revised manuscript we will insert the missing tables and figures that report bootstrapped confidence intervals for all privacy and utility metrics, along with the long-tailed performance analysis, ensuring they are explicitly referenced from the abstract and methods sections. revision: yes
Circularity Check
No circularity: engineering framework paper with no derivations, fits, or self-referential predictions
full rationale
The manuscript introduces a unified benchmarking pipeline and reimplementations of existing models (MedGAN, CorGAN, PromptEHR, HALO) plus a GPT-2 baseline, together with an architecture-agnostic evaluation suite. No mathematical derivations, parameter-fitting steps, uniqueness theorems, or predictive claims appear in the provided text. The contribution is a software artifact whose correctness is intended to be verified externally via adoption and community use rather than by internal reduction to fitted inputs or self-citations. Consequently the derivation chain is empty and the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guyon and A
I. Guyon and A. Elisseeff. An Introduction to Variable and Feature Selection. JMLR
-
[2]
Guyon and C
I. Guyon and C. Aliferis and A. Elisseeff , title =
-
[3]
JMIR medical informatics , volume=
Mapping ICD-10 and ICD-10-CM codes to phecodes: workflow development and initial evaluation , author=. JMIR medical informatics , volume=. 2019 , publisher=
2019
-
[4]
Scientific data , volume=
MIMIC-III, a freely accessible critical care database , author=. Scientific data , volume=. 2016 , publisher=
2016
-
[5]
MIMIC-III clinical database.PhysioNet, September 2016
Johnson, Alistair and Pollard, Tom and Mark, Roger , title =. 2016 , month = sep, note =. doi:10.13026/C2XW26 , url =
-
[6]
Machine learning for healthcare conference , pages=
Generating multi-label discrete patient records using generative adversarial networks , author=. Machine learning for healthcare conference , pages=. 2017 , organization=
2017
-
[7]
, author=
CorGAN: Correlation-Capturing Convolutional Generative Adversarial Networks for Generating Synthetic Healthcare Records. , author=. FLAIRS , pages=
-
[8]
Journal of the American Medical Informatics Association , volume=
Generating synthetic electronic health record data: a methodological scoping review with benchmarking on phenotype data and open-source software , author=. Journal of the American Medical Informatics Association , volume=. 2025 , publisher=
2025
-
[9]
Nature communications , volume=
Synthesize high-dimensional longitudinal electronic health records via hierarchical autoregressive language model , author=. Nature communications , volume=. 2023 , publisher=
2023
-
[10]
arXiv preprint arXiv:2410.20626 , year=
Tabdiff: a mixed-type diffusion model for tabular data generation , author=. arXiv preprint arXiv:2410.20626 , year=
-
[11]
arXiv preprint arXiv:2504.07566 , year=
Diffusion Transformers for Tabular Data Time Series Generation , author=. arXiv preprint arXiv:2504.07566 , year=
-
[12]
International conference on machine learning , pages=
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[13]
2004 , publisher=
International Statistical Classification of Diseases and related health problems: Alphabetical index , author=. 2004 , publisher=
2004
-
[14]
NPJ digital medicine , volume=
DRG-LLaMA: tuning LLaMA model to predict diagnosis-related group for hospitalized patients , author=. NPJ digital medicine , volume=. 2024 , publisher=
2024
-
[15]
0 definitions manual , author=
Icd-10-CM/Pcs ms-drg v37. 0 definitions manual , author=. 2019 , publisher=
2019
-
[16]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[17]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Huggingface's transformers: State-of-the-art natural language processing , author=. arXiv preprint arXiv:1910.03771 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[18]
AMIA Annual Symposium Proceedings , volume=
Simulants: Synthetic clinical trial data via subject-level privacy-preserving synthesis , author=. AMIA Annual Symposium Proceedings , volume=
-
[19]
An interpretable data augmentation framework for improving generative modeling of synthetic clinical trial data , year =
Shafquat, Afrah and Mezey, Jason and Beigi, Mandis and Sun, Jimeng and Gao, Andy and Aptekar, Jacob W , booktitle=. An interpretable data augmentation framework for improving generative modeling of synthetic clinical trial data , year =
-
[20]
1996 , note =
Health Insurance Portability and Accountability Act of 1996 , howpublished =. 1996 , note =
1996
-
[21]
International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) , year =
-
[22]
Journal of the American Medical Informatics Association , volume=
Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record , author=. Journal of the American Medical Informatics Association , volume=. 2018 , publisher=
2018
-
[23]
EHRDiff: Exploring realistic EHR synthesis with diffusion models , author=. arXiv preprint arXiv:2303.05656 , year=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ConSequence: synthesizing logically constrained sequences for electronic health record generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
NPJ digital medicine , volume=
EHR-Safe: generating high-fidelity and privacy-preserving synthetic electronic health records , author=. NPJ digital medicine , volume=. 2023 , publisher=
2023
-
[26]
Journal of the American Medical Informatics Association , volume=
Reliable generation of privacy-preserving synthetic electronic health record time series via diffusion models , author=. Journal of the American Medical Informatics Association , volume=. 2024 , publisher=
2024
-
[27]
2016 IEEE international conference on data science and advanced analytics (DSAA) , pages=
The synthetic data vault , author=. 2016 IEEE international conference on data science and advanced analytics (DSAA) , pages=. 2016 , organization=
2016
-
[28]
2026 , month =
Synthetic Data Metrics , organization =. 2026 , month =
2026
-
[29]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Pyhealth: A deep learning toolkit for healthcare applications , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[30]
arXiv preprint arXiv:2310.09656 , year=
Mixed-type tabular data synthesis with score-based diffusion in latent space , author=. arXiv preprint arXiv:2310.09656 , year=
-
[31]
2022 , eprint=
PromptEHR: Conditional Electronic Healthcare Records Generation with Prompt Learning , author=. 2022 , eprint=
2022
-
[32]
ICLR 2024 Workshop on Learning from Time Series For Health , pages=
Medical event data standard (meds): Facilitating machine learning for health , author=. ICLR 2024 Workshop on Learning from Time Series For Health , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.