GuideCAD: A Lightweight Multimodal Framework for 3D CAD Model Generation via Prefix Embedding
Pith reviewed 2026-06-27 22:45 UTC · model grok-4.3
The pith
GuideCAD turns image embeddings into prefix embeddings so a pretrained LLM can generate 3D CAD construction sequences with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
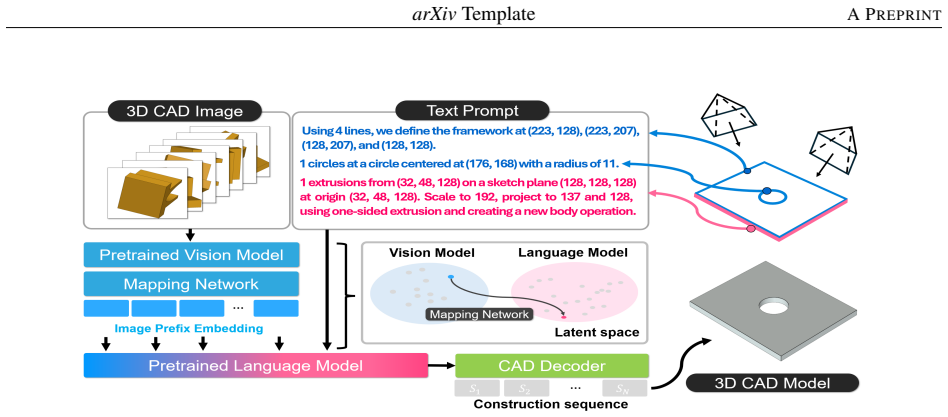
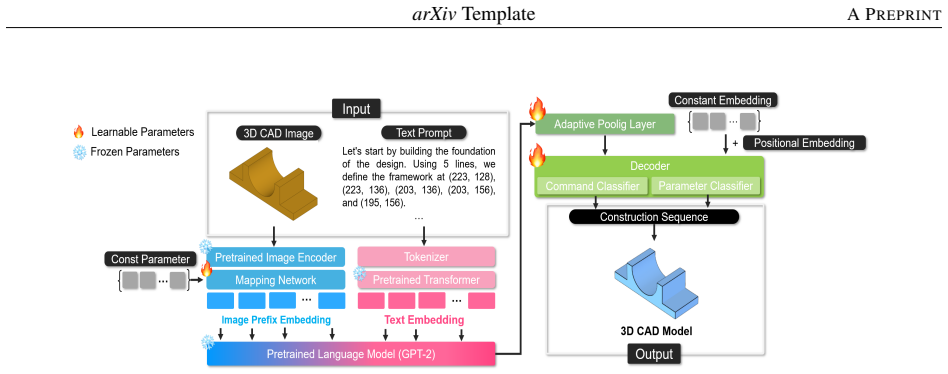
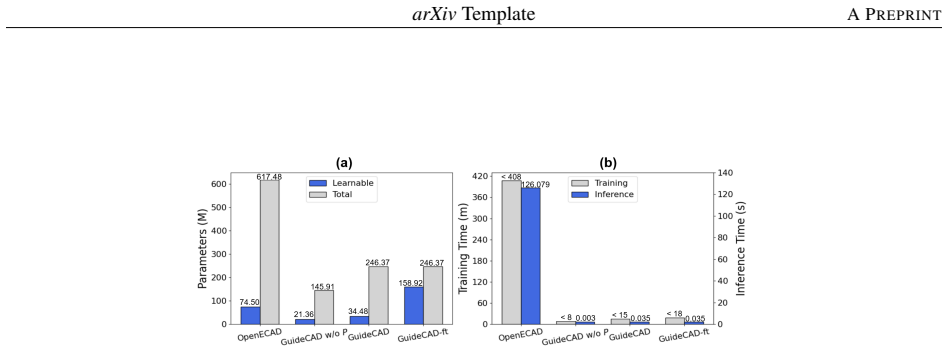
By mapping image embeddings to prefix embeddings, GuideCAD lets a pretrained large language model integrate visual and textual cues to predict 3D CAD construction sequences, yielding comparably high-quality models while using approximately four times fewer parameters and twice the training efficiency of fine-tuning approaches.
What carries the argument
The mapping network that converts image embeddings into prefix embeddings for integration with textual information inside the pretrained LLM.
If this is right
- Multimodal CAD generation becomes feasible on hardware with limited memory or compute budgets.
- Pretrained language models can be adapted for structured 3D output tasks without retraining the entire model.
- Construction-sequence prediction extends language-model capabilities to produce executable CAD programs directly from images and text.
- The released text-image dataset enables supervised training of other lightweight sequence generators for CAD.
Where Pith is reading between the lines
- The same prefix-mapping pattern could be tested on non-CAD 3D tasks such as mesh or voxel generation from sketches.
- Lower parameter counts open the possibility of running the generator inside interactive design tools on consumer GPUs.
- Extending the input to include additional modalities such as spoken instructions would require only changes to the mapping stage.
Load-bearing premise
Converting image embeddings to prefix embeddings via the mapping network lets the pretrained LLM integrate visual and textual information to predict accurate CAD construction sequences.
What would settle it
A controlled run in which the mapping network is removed or replaced by random prefixes, after which CAD model quality and sequence accuracy show no measurable drop compared with the full GuideCAD pipeline.
Figures

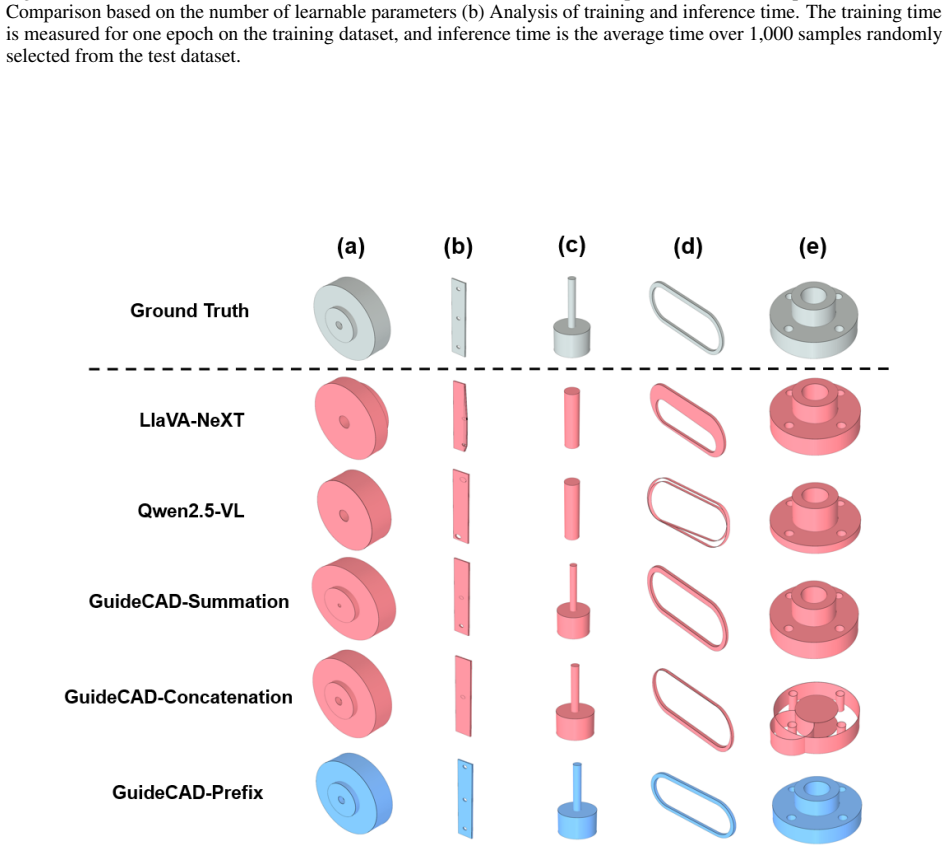
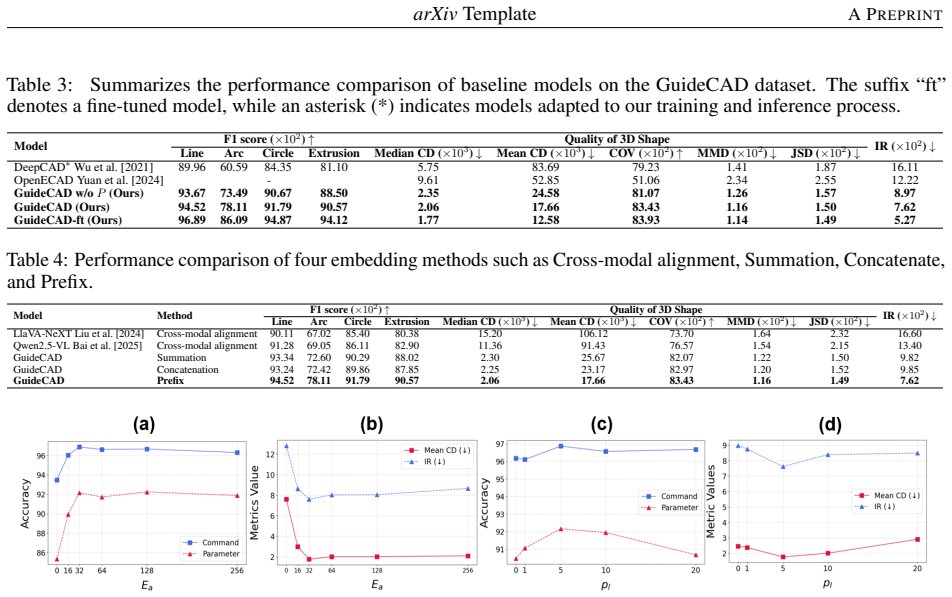
read the original abstract
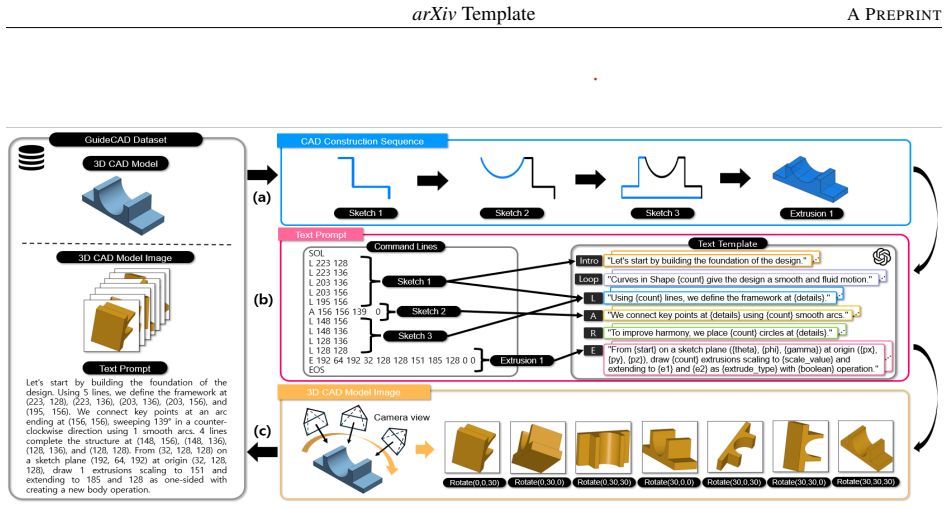
Multi-modal approaches used for 3D CAD generation require substantial computational resources, necessitating efficient training. To address this, we propose GuideCAD, which leverages semantically rich visual-textual representations having only a small number of trainable parameters to generate 3D CAD models. Specifically, GuideCAD uses a mapping network that converts image embeddings into prefix embeddings, enabling a pretrained large language model to integrate visual and textual information. As a result, a transformer-based decoder predicts the construction sequence using the visual-textual embeddings in order to generate the 3D CAD model. For experimental evaluation, we construct a new dataset, referred to as GuideCAD, which consists of text-image pairs. Each pair includes a text prompt that represents a 3D CAD construction sequence and its corresponding 3D CAD image. Our experimental results show that GuideCAD generates comparably high-quality 3D CAD models while using approximately four times fewer parameters and achieving twice the training efficiency compared to fine-tuning approaches. We have released the source code and dataset for our method at: https://github.com/mskimS2/GuideCAD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GuideCAD, a lightweight multimodal framework for generating 3D CAD models. It employs a mapping network to convert image embeddings into prefix embeddings, enabling a pretrained LLM to integrate visual and textual information; a transformer decoder then predicts the CAD construction sequence. The authors introduce a new text-image dataset (also named GuideCAD) and claim that the approach produces comparably high-quality outputs while using ~4× fewer parameters and achieving 2× training efficiency relative to fine-tuning baselines. Code and data are released.
Significance. If the efficiency and quality claims are supported by detailed, reproducible metrics and ablations, the work would demonstrate a practical route to resource-efficient multimodal CAD generation that avoids full LLM fine-tuning. The public release of code and dataset is a positive factor for verification.
major comments (2)
- [Experimental evaluation] The central claim of comparable quality with 4× fewer parameters and 2× training efficiency is stated in the abstract and experimental evaluation summary, yet no quantitative metrics, error bars, dataset statistics, baseline implementation details, or specific numbers are supplied. This absence prevents verification of the headline result.
- [Method / architecture description] The parameter-efficiency argument rests on the mapping network successfully translating image embeddings into prefix tokens that the frozen LLM can use with text to drive accurate CAD sequence prediction. The architecture description states that this conversion occurs, but the manuscript provides no ablation, embedding analysis, or failure-case study to confirm the integration step is functionally effective.
minor comments (2)
- The dataset and method share the name 'GuideCAD'; a distinct dataset name would reduce potential confusion.
- All reported comparisons should include exact numerical values, standard deviations, and clear descriptions of the fine-tuning baselines and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will revise the manuscript to provide stronger empirical support for the claims.
read point-by-point responses
-
Referee: [Experimental evaluation] The central claim of comparable quality with 4× fewer parameters and 2× training efficiency is stated in the abstract and experimental evaluation summary, yet no quantitative metrics, error bars, dataset statistics, baseline implementation details, or specific numbers are supplied. This absence prevents verification of the headline result.
Authors: We acknowledge that the abstract states the efficiency claims at a high level. The full experimental section reports comparative results, but to enable direct verification we will expand it with explicit quantitative metrics (parameter counts, training time per epoch, quality scores), error bars from repeated runs, dataset statistics (sample counts, splits, prompt distributions), and precise baseline implementation details (hyperparameters, hardware). The already-released code and dataset will support reproducibility of these numbers. revision: yes
-
Referee: [Method / architecture description] The parameter-efficiency argument rests on the mapping network successfully translating image embeddings into prefix tokens that the frozen LLM can use with text to drive accurate CAD sequence prediction. The architecture description states that this conversion occurs, but the manuscript provides no ablation, embedding analysis, or failure-case study to confirm the integration step is functionally effective.
Authors: The current description explains the mapping network's role but lacks supporting analysis. We will add an ablation study isolating the mapping network, quantitative embedding similarity metrics between image and prefix tokens, and a short discussion of observed failure modes to demonstrate that the prefix integration is effective for CAD sequence prediction. revision: yes
Circularity Check
No circularity in empirical architecture proposal
full rationale
The paper proposes an empirical multimodal framework (mapping network + prefix embeddings into frozen LLM + transformer decoder) validated on a new dataset with efficiency comparisons. No equations, first-principles derivations, or predictions appear that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Claims rest on experimental outcomes rather than internal redefinitions, making the work self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2022 , howpublished =
SolidWorks , title =. 2022 , howpublished =
2022
-
[2]
2022 , note =
FreeCAD , title =. 2022 , note =
2022
-
[3]
2022 , howpublished =
Siemens , title =. 2022 , howpublished =
2022
-
[4]
Text2CAD: Generating Sequential CAD Designs from Beginner-to-Expert Level Text Prompts , volume =
Khan, Mohammad Sadil and Sinha, Sankalp and Uddin, Talha and Stricker, Didier and Ali, Sk Aziz and Afzal, Muhammad Zeshan , booktitle =. Text2CAD: Generating Sequential CAD Designs from Beginner-to-Expert Level Text Prompts , volume =
-
[5]
OpenECAD: An efficient visual language model for editable 3D-CAD design , journal =
Zhe Yuan and Jianqi Shi and Yanhong Huang , keywords =. OpenECAD: An efficient visual language model for editable 3D-CAD design , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.cag.2024.104048 , url =
-
[6]
2024 , eprint=
CAD-MLLM: Unifying Multimodality-Conditioned CAD Generation With MLLM , author=. 2024 , eprint=
2024
-
[7]
Generating CAD Code with Vision-Language Models for 3D Designs , volume =
Alrashedy, Kamel and Tambwekar, Pradyumna and Zaidi, Zulfiqar Haider and Langwasser, Megan and Xu, Wei and Gombolay, Matthew , booktitle =. Generating CAD Code with Vision-Language Models for 3D Designs , volume =
-
[8]
2024 , eprint=
Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geometry , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
Query2CAD: Generating CAD models using natural language queries , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
GenCAD: Image-Conditioned Computer-Aided Design Generation with Transformer-Based Contrastive Representation and Diffusion Priors , author=. 2025 , eprint=
2025
-
[11]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[12]
Language Models are Unsupervised Multitask Learners , url =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , biburl =. Language Models are Unsupervised Multitask Learners , url =. OpenAI , keywords =
-
[13]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Wu, Rundi and Xiao, Chang and Zheng, Changxi , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
2021
-
[15]
Nash, Charlie and Ganin, Yaroslav and Eslami, S. M. Ali and Battaglia, Peter , booktitle =. 2020 , volume =
2020
-
[16]
Pointer Networks , volume =
Vinyals, Oriol and Fortunato, Meire and Jaitly, Navdeep , booktitle =. Pointer Networks , volume =
-
[17]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year=
Engineering Sketch Generation for Computer-Aided Design , author=. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year=
2021
-
[18]
SketchGen: Generating Constrained CAD Sketches , volume =
Para, Wamiq and Bhat, Shariq and Guerrero, Paul and Kelly, Tom and Mitra, Niloy and Guibas, Leonidas J and Wonka, Peter , booktitle =. SketchGen: Generating Constrained CAD Sketches , volume =
-
[19]
2024 , eprint=
LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models , author=. 2024 , eprint=
2024
-
[20]
2024 , url=
Xueyang Li and Yu Song and Yunzhong Lou and Xiangdong Zhou , booktitle=. 2024 , url=
2024
-
[21]
International Conference on Machine Learning , pages=
SkexGen: Autoregressive Generation of CAD Construction Sequences with Disentangled Codebooks , author =. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[22]
Zhou, Shengdi and Tang, Tianyi and Zhou, Bin , title =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , articleno =. 2023 , isbn =. doi:10.24963/ijcai.2023/200 , abstract =
-
[23]
ContrastCAD: Contrastive Learning-Based Representation Learning for Computer-Aided Design Models , year=
Jung, Minseop and Kim, Minseong and Kim, Jibum , journal=. ContrastCAD: Contrastive Learning-Based Representation Learning for Computer-Aided Design Models , year=
-
[24]
Brep2Seq: A dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models , volume =
Zhang, Shuming and Guan, Zhidong and Jiang, Hao and Ning, Tao and Wang, Xiaodong and Tan, Pingan , year =. Brep2Seq: A dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models , volume =. Journal of Computational Design and Engineering , doi =
-
[25]
Proceedings of the 40th International Conference on Machine Learning , year=
Hierarchical Neural Coding for Controllable CAD Model Generation , author=. Proceedings of the 40th International Conference on Machine Learning , year=
-
[26]
Ma, Weijian and Xu, Minyang and Li, Xueyang and Zhou, Xiangdong , title =. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management , pages =. 2023 , isbn =. doi:10.1145/3583780.3614982 , abstract =
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Khan, Mohammad Sadil and Dupont, Elona and Ali, Sk Aziz and Cherenkova, Kseniya and Kacem, Anis and Aouada, Djamila , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Ma, Weijian and Chen, Shuaiqi and Lou, Yunzhong and Li, Xueyang and Zhou, Xiangdong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[29]
Computer-Aided Design as Language , volume =
Ganin, Yaroslav and Bartunov, Sergey and Li, Yujia and Keller, Ethan and Saliceti, Stefano , booktitle =. Computer-Aided Design as Language , volume =
-
[30]
2024 , eprint=
Constructing Mechanical Design Agent Based on Large Language Models , author=. 2024 , eprint=
2024
-
[31]
CadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches
Wu, Sifan and Khasahmadi, Amir Hosein and Katz, Mor and Jayaraman, Pradeep Kumar and Pu, Yewen and Willis, Karl and Liu, Bang. CadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches. Computer Vision -- ECCV 2024. 2025
2024
-
[32]
2022 , doi =
Thomas Paviot , title =. 2022 , doi =
2022
-
[33]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, Xiang Lisa and Liang, Percy. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.353
-
[34]
2021 , eprint=
ClipCap: CLIP Prefix for Image Captioning , author=. 2021 , eprint=
2021
-
[35]
AAAI , year =
Wang, Xilin and Zheng, Jia and Hu, Yuanchao and Zhu, Hao and Yu, Qian and Zhou, Zihan , title =. AAAI , year =
-
[36]
Guo, Haoxiang and Liu, Shilin and Pan, Hao and Liu, Yang and Tong, Xin and Guo, Baining , title =. ACM Trans. Graph. , month = jul, articleno =. 2022 , issue_date =. doi:10.1145/3528223.3530078 , abstract =
-
[37]
Li, Changjian and Pan, Hao and Bousseau, Adrien and Mitra, Niloy J. , title =. ACM Trans. Graph. , month = jul, articleno =. 2022 , issue_date =. doi:10.1145/3528223.3530133 , abstract =
-
[38]
Vitruvion: A Generative Model of Parametric
Ari Seff and Wenda Zhou and Nick Richardson and Ryan P Adams , booktitle=. Vitruvion: A Generative Model of Parametric. 2022 , url=
2022
-
[39]
Lambourne, Joseph George and Willis, Karl and Jayaraman, Pradeep Kumar and Zhang, Longfei and Sanghi, Aditya and Malekshan, Kamal Rahimi , title =. SIGGRAPH Asia 2022 Conference Papers , articleno =. 2022 , isbn =. doi:10.1145/3550469.3555424 , abstract =
-
[40]
arXiv preprint arXiv:2401.15563 , year=
BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry , author=. arXiv preprint arXiv:2401.15563 , year=
-
[41]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[42]
2022 , eprint=
Point-E: A System for Generating 3D Point Clouds from Complex Prompts , author=. 2022 , eprint=
2022
-
[43]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Ilya Loshchilov and Frank Hutter , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[44]
Diamos and Erich Elsen and David Garc
Paulius Micikevicius and Sharan Narang and Jonah Alben and Gregory F. Diamos and Erich Elsen and David Garc. Mixed Precision Training , booktitle =. 2018 , url =
2018
-
[45]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Koch, Sebastian and Matveev, Albert and Jiang, Zhongshi and Williams, Francis and Artemov, Alexey and Burnaev, Evgeny and Alexa, Marc and Zorin, Denis and Panozzo, Daniele , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[46]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[47]
Wang, Xuan and Wang, Guanhong and Chai, Wenhao and Zhou, Jiayu and Wang, Gaoang , title =. Pattern Recognition and Computer Vision: 6th Chinese Conference, PRCV 2023, Xiamen, China, October 13–15, 2023, Proceedings, Part VII , pages =. 2023 , isbn =. doi:10.1007/978-981-99-8540-1_31 , abstract =
-
[48]
European Conference on Computer Vision (ECCV) , year=
Visual Prompt Tuning , author=. European Conference on Computer Vision (ECCV) , year=
-
[49]
2024 , eprint=
CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs , author=. 2024 , eprint=
2024
-
[50]
arXiv preprint arXiv:2412.14042 , year=
CAD-Recode: Reverse Engineering CAD Code from Point Clouds , author=. arXiv preprint arXiv:2412.14042 , year=
-
[51]
Prefix Embeddings for In-context Machine Translation
Sia, Suzanna and Duh, Kevin. Prefix Embeddings for In-context Machine Translation. Proceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Volume 1: Research Track). 2022
2022
-
[52]
P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
Liu, Xiao and Ji, Kaixuan and Fu, Yicheng and Tam, Weng and Du, Zhengxiao and Yang, Zhilin and Tang, Jie. P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.8
-
[53]
arXiv preprint arXiv:2302.07120 , year=
PrefixMol: Target-and Chemistry-aware Molecule Design via Prefix Embedding , author=. arXiv preprint arXiv:2302.07120 , year=
-
[54]
, title =
Paszke, Adam et al. , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , address =
2019
-
[55]
ICCV , year=
Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images , author=. ICCV , year=
-
[56]
Yang, Bo and Rosa, Stefano and Markham, Andrew and Trigoni, Niki and Wen, Hongkai , journal=. 2019 , volume=. doi:10.1109/TPAMI.2018.2868195 , url =
-
[57]
Camba and Manuel Contero and Pedro Company , keywords =
Jorge D. Camba and Manuel Contero and Pedro Company , keywords =. Parametric CAD modeling: An analysis of strategies for design reusability , journal =. 2016 , issn =. doi:https://doi.org/10.1016/j.cad.2016.01.003 , url =
-
[58]
The Eleventh International Conference on Learning Representations , year=
Preserving Pre-trained Features Helps Calibrate Fine-tuned Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[59]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[60]
2024 , eprint=
TinyLLaVA: A Framework of Small-scale Large Multimodal Models , author=. 2024 , eprint=
2024
-
[61]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[62]
Zhanwei Zhang and Shizhao Sun and Wenxiao Wang and Deng Cai and Jiang Bian , booktitle=. Flex. 2025 , url=
2025
-
[63]
arXiv preprint arXiv:2502.13923 , year=
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.