ForensicConcept: Transferable Forensic Concepts for AIGI Detection
Pith reviewed 2026-06-27 22:39 UTC · model grok-4.3
The pith
ForensicConcept extracts explicit forensic concepts from detectors and transfers them across backbones using diffusion alignment for better AIGI detection on unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
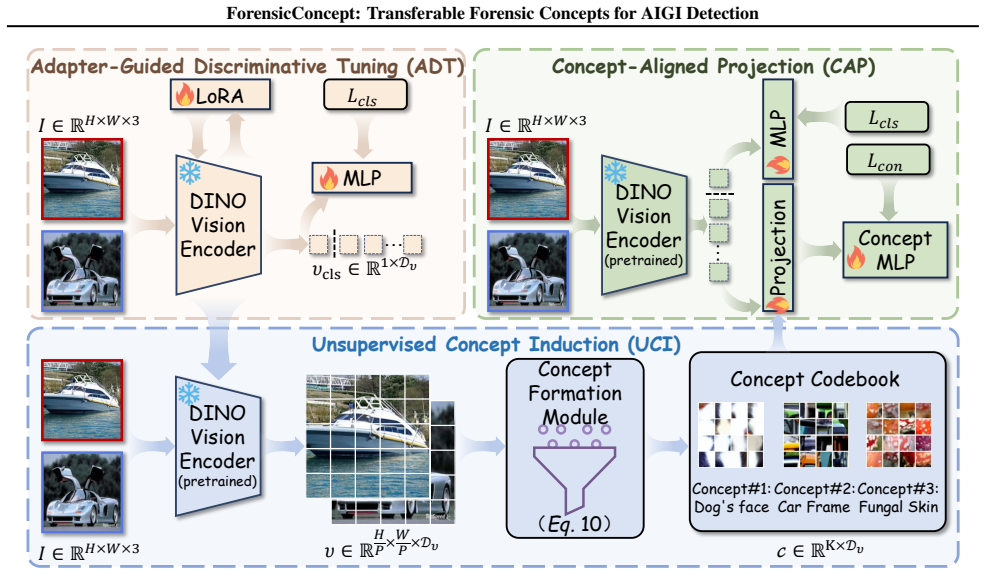
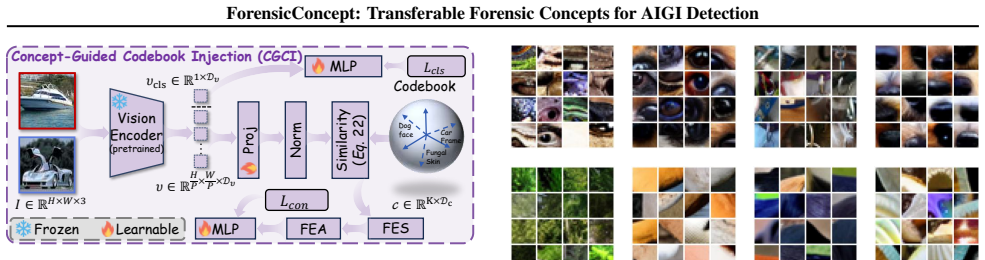
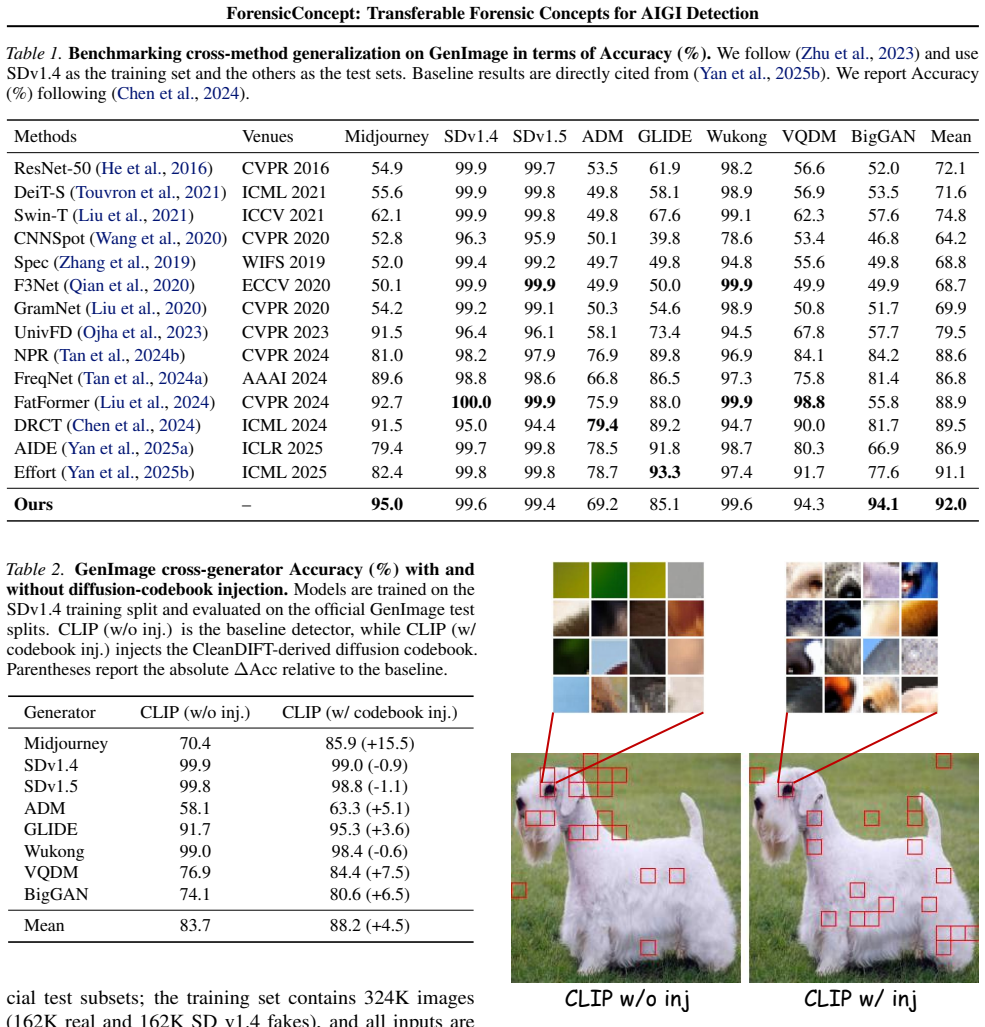
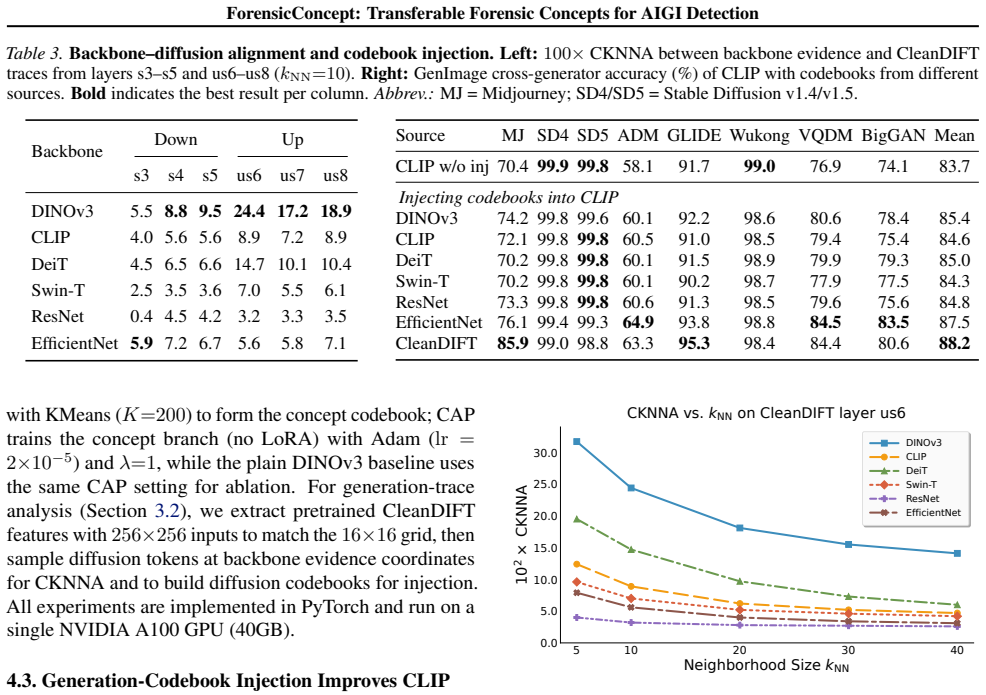
ForensicConcept localizes critical patches with Transformer attribution, clusters them into a compact concept codebook, applies concept-aligned projection for auditable readouts, and injects diffusion-derived concepts from CleanDIFT into target backbones; this produces consistent accuracy gains on GenImage, GAN-family, and Chameleon while CKNNA neighborhood consistency predicts transfer success and explains backbone differences.
What carries the argument
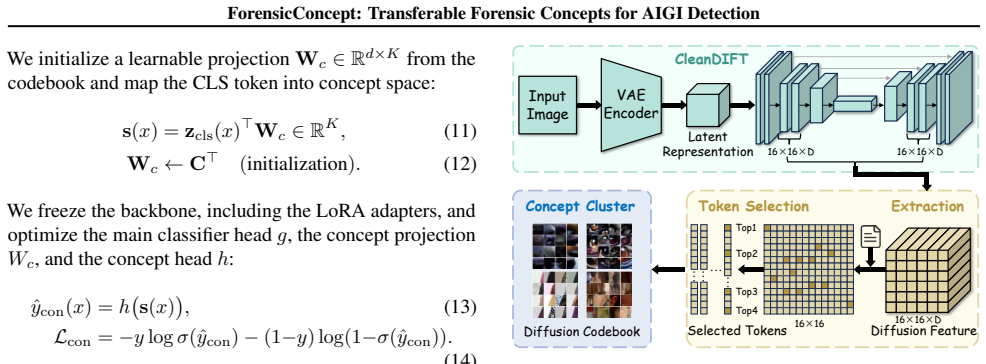
The concept codebook with concept codebook injection, using CleanDIFT as generation-trace reference and CKNNA to quantify neighborhood-structure alignment between backbone and diffusion representations.
Load-bearing premise
DINO representations guide diffusion generation and show concept-level correspondence with diffusion features, allowing CleanDIFT to act as a reliable reference for concept transfer.
What would settle it
A new experiment measuring whether CKNNA scores between backbones and CleanDIFT still predict transfer gains after testing on generators where DINO-diffusion concept correspondence is shown to break.
Figures





















read the original abstract
AI-generated image detectors achieve high accuracy on in-distribution data but often fail on unseen generators. A key obstacle to understanding this failure is the black-box nature of current detectors: they do not reveal which evidence drives their decisions. We propose ForensicConcept, a framework that extracts explicit forensic concepts from detectors and enables their transfer across backbones. Our method localizes decision-critical patches via Transformer attribution, clusters them into a compact concept codebook, and uses a concept-aligned projection to produce auditable evidence readouts. Motivated by prior studies showing that DINO representations can guide diffusion generation and exhibit concept-level correspondence with diffusion features, we introduce a generation-trace reference based on CleanDIFT diffusion features and quantify backbone-trace alignment via neighborhood-structure consistency (CKNNA). We further propose concept codebook injection to transfer diffusion-derived concepts into target backbones. Experiments on GenImage, GAN-family, and Chameleon benchmarks show consistent improvements over prior methods. We also find that CKNNA alignment predicts transfer effectiveness, providing a principled explanation for why some backbones yield more transferable forensic evidence than others.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ForensicConcept, a framework for extracting explicit forensic concepts from AIGI detectors to improve transferability across backbones. It localizes decision-critical patches via Transformer attribution, clusters them into a compact concept codebook, and employs a concept-aligned projection for auditable evidence. Motivated by DINO-diffusion correspondence, it introduces CleanDIFT as a generation-trace reference, quantifies alignment via CKNNA (neighborhood-structure consistency), and uses concept codebook injection for transfer. Experiments on GenImage, GAN-family, and Chameleon benchmarks report consistent improvements over prior methods, with the additional finding that CKNNA alignment predicts transfer effectiveness.
Significance. If the reported gains hold under rigorous controls and CKNNA is shown to be an independent predictor rather than a post-hoc descriptor, the work could meaningfully advance interpretable AIGI detection by moving beyond black-box classifiers toward explicit, transferable forensic concepts. The emphasis on auditable readouts and a metric linking backbone alignment to transfer success is a constructive direction; no machine-checked proofs or fully parameter-free derivations are claimed, but the empirical focus on multiple benchmarks is a strength if the results prove robust.
major comments (2)
- [Abstract (motivation paragraph)] Abstract (motivation paragraph): The assumption that DINO representations guide diffusion generation and exhibit concept-level correspondence with diffusion features (justifying CleanDIFT as a reliable generation-trace reference) is load-bearing for the entire reference-based pipeline; the manuscript should provide explicit empirical validation or direct citations to the prior studies invoked, rather than relying on the high-level motivation statement.
- [Results section on CKNNA] Results section on CKNNA (likely around the transfer-effectiveness experiments): CKNNA is presented simultaneously as a quantification tool for backbone-trace alignment and as a predictor of transfer success; it must be clarified whether the predictive relationship is validated on held-out generators or data splits independent of the transfer experiments used to compute the alignments, to rule out circularity in the explanatory claim.
minor comments (2)
- [Notation and Methods] Ensure all acronyms (e.g., CKNNA, CleanDIFT) are expanded on first use in the main text and that the concept codebook injection procedure is described with sufficient algorithmic detail for reproducibility.
- [Experiments] Figure captions and tables reporting benchmark results should include error bars or statistical significance tests to support the claim of 'consistent improvements.'
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (motivation paragraph)] Abstract (motivation paragraph): The assumption that DINO representations guide diffusion generation and exhibit concept-level correspondence with diffusion features (justifying CleanDIFT as a reliable generation-trace reference) is load-bearing for the entire reference-based pipeline; the manuscript should provide explicit empirical validation or direct citations to the prior studies invoked, rather than relying on the high-level motivation statement.
Authors: We agree that the motivation for CleanDIFT would benefit from greater specificity. The current text references prior studies on DINO-diffusion correspondence at a high level. In the revised manuscript we will add the direct citations to the relevant works establishing this correspondence and include a short empirical validation (e.g., qualitative feature-map comparisons on a small held-out set) in the supplementary material to make the justification explicit rather than implicit. revision: yes
-
Referee: [Results section on CKNNA] Results section on CKNNA (likely around the transfer-effectiveness experiments): CKNNA is presented simultaneously as a quantification tool for backbone-trace alignment and as a predictor of transfer success; it must be clarified whether the predictive relationship is validated on held-out generators or data splits independent of the transfer experiments used to compute the alignments, to rule out circularity in the explanatory claim.
Authors: We appreciate the concern regarding potential circularity. The CKNNA alignments were computed on a disjoint set of generators and data splits that were not used to evaluate transfer effectiveness. We will revise the results section to explicitly state the independence of the splits, report the exact partitioning procedure, and add a sentence confirming that the predictive relationship was assessed on held-out generators. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces ForensicConcept as an empirical framework: it extracts concepts via attribution and clustering, defines CKNNA as a neighborhood-consistency metric for alignment, and reports that this metric correlates with observed transfer gains on held-out benchmarks. No equation or procedure is shown to define one quantity in terms of the other by construction, nor does any central claim reduce to a self-citation chain or a fitted parameter renamed as a prediction. The DINO-CleanDIFT correspondence is cited from prior external studies rather than derived internally. The reported improvements and correlation are therefore falsifiable against external data and do not collapse into the inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
Advances in neural information processing systems , volume=
Genimage: A million-scale benchmark for detecting ai-generated image , author=. Advances in neural information processing systems , volume=
-
[6]
for now , author=
CNN-generated images are surprisingly easy to spot... for now , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards universal fake image detectors that generalize across generative models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
Proceedings of the 3rd ACM International Workshop on Multimedia AI against Disinformation , pages=
SIDBench: A Python framework for reliably assessing synthetic image detection methods , author=. Proceedings of the 3rd ACM International Workshop on Multimedia AI against Disinformation , pages=
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dire for diffusion-generated image detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
Luo, Yunpeng and Du, Junlong and Yan, Ke and Ding, Shouhong , booktitle=. Lare\^
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
European conference on computer vision , pages=
Discovering transferable forensic features for cnn-generated images detection , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[13]
Advances in neural information processing systems , volume=
Emergent correspondence from image diffusion , author=. Advances in neural information processing systems , volume=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cleandift: Diffusion features without noise , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Forty-first International Conference on Machine Learning , year=
Position: The platonic representation hypothesis , author=. Forty-first International Conference on Machine Learning , year=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Raising the bar of ai-generated image detection with clip , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
International Conference on Learning Representations , volume=
A sanity check for ai-generated image detection , author=. International Conference on Learning Representations , volume=
-
[18]
Forty-first International Conference on Machine Learning , year=
Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images , author=. Forty-first International Conference on Machine Learning , year=
-
[19]
The Thirteenth International Conference on Learning Representations , year=
Enhancing Pre-trained Representation Classifiability can Boost its Interpretability , author=. The Thirteenth International Conference on Learning Representations , year=
-
[20]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[21]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Quantifying attention flow in transformers , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Transformer interpretability beyond attention visualization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[24]
International conference on machine learning , pages=
Concept bottleneck models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[25]
Advances in neural information processing systems , volume=
This looks like that: deep learning for interpretable image recognition , author=. Advances in neural information processing systems , volume=
-
[26]
The Thirteenth International Conference on Learning Representations , year=
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
The Fourteenth International Conference on Learning Representations , year=
Diffusion Transformers with Representation Autoencoders , author=. The Fourteenth International Conference on Learning Representations , year=
-
[28]
arXiv preprint arXiv:2512.17909 (2025) 3, 4
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing , author=. arXiv preprint arXiv:2512.17909 , year=
-
[29]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[30]
Advances in neural information processing systems , volume=
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability , author=. Advances in neural information processing systems , volume=
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
International conference on machine learning , pages=
Training data-efficient image transformers & distillation through attention , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
2019 IEEE international workshop on information forensics and security (WIFS) , pages=
Detecting and simulating artifacts in gan fake images , author=. 2019 IEEE international workshop on information forensics and security (WIFS) , pages=. 2019 , organization=
2019
-
[35]
European conference on computer vision , pages=
Thinking in frequency: Face forgery detection by mining frequency-aware clues , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Global texture enhancement for fake face detection in the wild , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Forgery-aware adaptive transformer for generalizable synthetic image detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Orthogonal Subspace Decomposition for Generalizable
Zhiyuan Yan and Jiangming Wang and Peng Jin and Ke-Yue Zhang and Chengchun Liu and Shen Chen and Taiping Yao and Shouhong Ding and Baoyuan Wu and Li Yuan , booktitle=. Orthogonal Subspace Decomposition for Generalizable. 2025 , url=
2025
-
[41]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[42]
arXiv preprint arXiv:2311.12397 , year=
Patchcraft: Exploring texture patch for efficient ai-generated image detection , author=. arXiv preprint arXiv:2311.12397 , year=
-
[43]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Visualizing and understanding patch interactions in vision transformer , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , publisher=
2023
-
[44]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[45]
Prentice Hall , year=
Algorithms for clustering data , author=. Prentice Hall , year=
-
[46]
Pattern recognition letters , volume=
Data clustering: 50 years beyond K-means , author=. Pattern recognition letters , volume=. 2010 , publisher=
2010
-
[47]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[48]
International conference on machine learning , pages=
Efficientnet: Rethinking model scaling for convolutional neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[49]
Dinov3 , author=. arXiv preprint arXiv:2508.10104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Forty-first International Conference on Machine Learning , year=
Outlier-aware slicing for post-training quantization in vision transformer , author=. Forty-first International Conference on Machine Learning , year=
-
[52]
International Journal of Computer Vision , volume=
An information theory-inspired strategy for automated network pruning , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
2025
-
[53]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Hrseg: High-resolution visual perception and enhancement for reasoning segmentation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[54]
Visual Intelligence , volume=
Towards reliable deepfake detection from uncertainty calibration perspective , author=. Visual Intelligence , volume=. 2025 , publisher=
2025
-
[55]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Zooming in on fakes: A novel dataset for localized AI-generated image detection with forgery amplification approach , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Diffusionfake: Enhancing generalization in deepfake detection via guided stable diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Stealthdiffusion: Towards evading diffusion forensic detection through diffusion model , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[58]
Proceedings of the AAAI conference on artificial intelligence , volume=
Domain general face forgery detection by learning to weight , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[59]
Proceedings of the AAAI conference on artificial intelligence , volume=
Dual contrastive learning for general face forgery detection , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[60]
European conference on computer vision , pages=
An information theoretic approach for attention-driven face forgery detection , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[62]
The Fourteenth International Conference on Learning Representations , year=
Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play? , author=. The Fourteenth International Conference on Learning Representations , year=
-
[63]
International conference on machine learning , pages=
Leveraging frequency analysis for deep fake image recognition , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[64]
2022 IEEE International Conference on Image Processing (ICIP) , pages=
Fusing global and local features for generalized ai-synthesized image detection , author=. 2022 IEEE International Conference on Image Processing (ICIP) , pages=. 2022 , organization=
2022
-
[65]
European conference on computer vision , pages=
Detecting generated images by real images , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning on gradients: Generalized artifacts representation for gan-generated images detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.